最短路径算法
前言

本篇文章我将向大家介绍求解最短路径的三种经典算法——Dijkstra 算法,Bellman-Ford 算法以及 Floyd-Warshall 算法。
Dijkstra 算法
最短路径
最短路径问题是图论研究领域中的一个经典算法问题,旨在寻找图中两节点之间的最短路径。

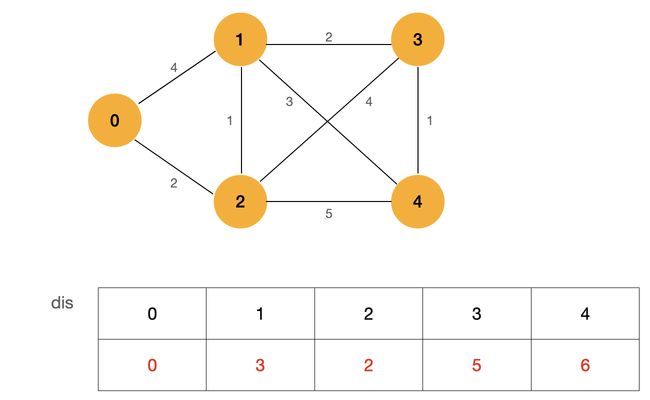
譬如上图为一个无向有权图,节点 0 到节点 3 的最短路径为 :
0 -> 2 -> 1 -> 3
其路径长度为:5。
研究最短路径算法具有哪些意义呢?或者说最短路径算法可以解决哪些问题?
我们知道,在生活中,地铁是我们重要的出行工具之一。当我们在地铁售票处或是软件上输入了出发地与目的地后,手机软件就会给我们一个耗费最小或时间最短的最佳出行方案,导航软件这个功能的实现实际上就是一个最短路径算法的具体应用。
研究最短路径算法旨在解决出行问题,旅游问题,工程耗费等问题,在计算机科学,运筹学,地理信息科学中都具有重大意义。
Dijkstra 算法
Dijkstra 算法是求解单源最短路的经典算法之一,是由荷兰计算机科学家 Dijkstra 在 1956 年发明的算法。
使用 Dijkstra 算法的前提条件是图中不能有负权边。在我介绍完 Dijkstra 算法的思路以后,相信大家也就能够明白,为什么图中不能包含负权边是 Dijkstra 算法的前置条件了。不过这一个前置条件并不会影响我们求解的绝大部分问题,譬如拿上面的求解耗费最小的地铁线路来举例,如果图中的每一条边的权值代表从一个节点到另一个节点耗费的金额,那么这个金额的大小一定是大于 0 的。所以说, Dijkstra 算法即便不能处理带有负权边的图,但其仍然能够解决最短路径这个研究领域中的绝大部分问题。
接下来,我们来看一下 Dijkstra 算法的具体思路:

上图中,源点为 0,表格 dis 表示的是从源点到各点的最短路径。因为最开始我们并不知道源点到各点的最短路径是多少,所以初始值我们使用 ∞ ∞ ∞ 来表示,而源点到源点的最短路径则已经确定,其值为 0。
我们从源点开始,找到了源点相邻的节点(1,2),边 0-1 的权为 4,边 0-2 的权为 2,因为他们的值要比当前的 dis 数组中的值还要小,所以我们更新 dis 数组,将 dis[1] 更新为 4,dis[2] 更新为 2,而剩余的节点的权仍然保持为 ∞ ∞ ∞ 。此时,我们可以确定,当前这些未确定最短路的节点中,值最小的就是从源到该点的最短路。
这么说可能比较绕,我们通过图来直观地看一下这个过程:
首先找到已经确定最短路的节点,在图中就是我使用黄色标注出来的节点 0。然后更新未确定最短路的所有节点,蓝色节点表示我更新的节点。

最后,这些未确定最短路的节点中,路径最短的就是从源点到该点的最短路。

如上图中,dis[2] 的值最小,所以我们可以确定从源点 0 到节点 2 的最短路径为 dis[2]。
这一论点该如何证明呢?
Dijkstra 算法的本质是贪心(greedy algorithm),需要严格的数学归纳法证明,在这里我就不使用数学推导这种方式来证明了,感兴趣的朋友们可以自行搜索一下 【 Dijkstra’s algorithm: proof of correctness】。
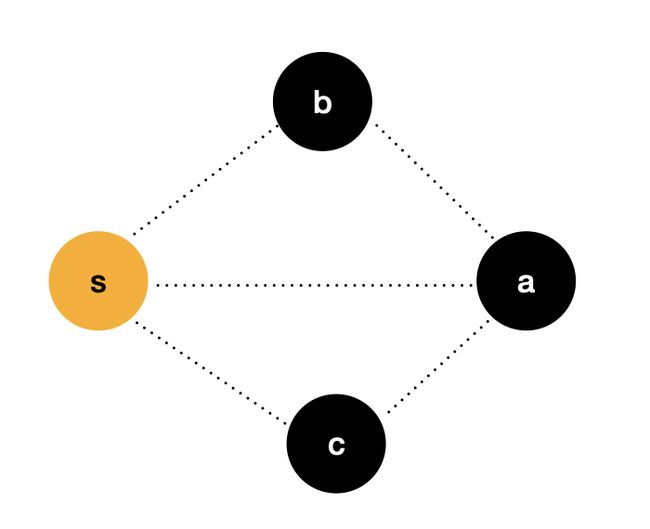
我们使用一种较为容易理解的方式来证明该想法。上图中,源点 s s s 到节点 a a a 这条边的权记作 d i s [ a ] dis[a] dis[a],相同地,源点 s s s 到节点 b b b 和 c c c 这两条边的权记作 d i s [ b ] dis[b] dis[b] 和 d i s [ c ] dis[c] dis[c]。
已知, d i s [ a ] > d i s [ b ] dis[a] > dis[b] dis[a]>dis[b], d i s [ a ] > d i s [ c ] dis[a] > dis[c] dis[a]>dis[c],如果该图不存在负权边,那么我就一定可以确定, d i s [ a ] dis[a] dis[a] 为源点 s s s 到节点 a a a 的最短路径。
所以,我们可以确定 Dijkstra 算法的这种思想是正确的,并且我们也间接地证明了,为什么 Dijkstra 算法的前置条件为图中不能含有负权边。
接下来,我们就继续沿用这种思想,继续模拟这个过程:
首先,我们通过已经确定最短路的节点更新 dis 数组。在这里,我们可以看到 dis[1] 更新为 3,这一步的操作也叫松弛操作或放松操作(Relaxation),松弛这个名词可以理解为,我们选择使用了较长的“距离”来作为两节点之间的最短路径,可以看到,节点 0 和 节点 1 之间的最短路并不是两节点之间的边,而是 0-2-1 这一条路径。

我们从当前这些未确定最短路的节点中,确定值最小的节点:

重复上述的过程,我们就可以得到源点 0 到图中所有的节点的最短路径了:
Dijkstra 算法的代码实现
Dijkstra 算法的 Java 代码如下,因为代码当中我已经标明了详细的注释,所以就不对该程序一一解释了。另外因为本文的篇幅有限,所以测试代码的链接我会在文章最后给出,而测试用例与代码这部分的内容也就不在这里赘述了。
Dijkstra
import java.util.Arrays;
public class Dijkstra {
private WeightedGraph G;
private int s;
private int[] dis;
private boolean[] visited;
public Dijkstra(WeightedGraph G, int s) {
this.G = G;
// 判断源点 s 的合法性
if (s < 0 || s >= G.V())
throw new IllegalArgumentException("vertex" + s + "is invalid");
this.s = s;
// 对 dis 数组进行初始化
dis = new int[G.V()];
Arrays.fill(dis, Integer.MAX_VALUE);
dis[s] = 0;
visited = new boolean[G.V()];
// Dijkstra 算法的流程
// 1. 找到当前没有访问的最短路节点
// 2. 确认这个节点的最短路就是当前大小
// 3. 根据这个节点的最短路大小,寻找这个节点相邻的节点并更新其他节点的路径长度
while (true) {
int curdis = Integer.MAX_VALUE;
int cur = -1;
// 1. 找到未访问的最小的节点
for (int v = 0; v < G.V(); v++)
if (!visited[v] && dis[v] < curdis) {
curdis = dis[v];
cur = v;
}
// 如果 cur == -1 表示所有流程结束,跳出循环
if (cur == -1) break;
// 2. 确认这个节点的最短路就是当前大小,并更新 visited
visited[cur] = true;
// 3. 根据这个节点的最短路大小,寻找这个节点相邻的节点并更新其他节点的路径长度
for (int w : G.adj(cur))
if (!visited[w] && dis[cur] + G.getWeight(cur, w) < dis[w])
dis[w] = dis[cur] + G.getWeight(cur, w);
}
}
public boolean isConnected(int v) {
if (v < 0 || v >= G.V())
throw new IllegalArgumentException("vertex" + s + "is invalid");
return visited[v];
}
public int dis(int v) {
if (v < 0 || v >= G.V())
throw new IllegalArgumentException("vertex" + s + "is invalid");
return dis[v];
}
}
我们分析一下该算法的时间复杂度。该算法的外层为一个 while 循环,内层则是遍历了图中的每一个顶点,while 循环的终止条件为每一个节点的最短路径都被确定,所以该算法的时间复杂度为 O ( V 2 ) O(V^2) O(V2),其中 V V V 为该图的顶点的个数。
大家思考一下,这样一个 Dijkstra 算法是否有优化的空间呢?其实不难发现,我们的算法类中,找到图中未访问的最小的节点这个操作每次都要遍历图的所有节点,这一步骤是可以进行优化的,通常在贪心的问题中,优化的策略就是使用优先队列。
优先队列与 Pair 类
优先队列(Priority Queue)是一种特殊的队列,在优先队列中每个元素都有各自的优先级,优先级最高的元素最先得到服务;优先级相同的元素按照其在优先队列中的顺序得到服务。而优先队列往往使用堆这种数据结构来实现。
在 Java 语言中,优先队列的默认实现是最小堆,我们可以使用自定义比较器来规定优先队列每个元素的优先级。
在我们的 Dijkstra 这个算法类中,优先队列中的元素应该维护 cur 以及 curdis 这两个信息,并且优先队列应该按照 curdis 从小到大的顺序进行排序。
我们很自然地想到自定义一个类,该类维护两个变量 cur 以及 curdis;然后我们让该类实现 Comparable 接口,并在 compareTo 方法中定义我们的比较逻辑。
在这里,我向大家推荐使用 JDK 中自带的 com.sun.tools.javac.util 包下的 Pair 类。
Pair
public class Pair<A, B> {
public final A fst;
public final B snd;
public Pair(A var1, B var2) {
this.fst = var1;
this.snd = var2;
}
public String toString() {
return "Pair[" + this.fst + "," + this.snd + "]";
}
public boolean equals(Object var1) {
return var1 instanceof Pair && Objects.equals(this.fst, ((Pair)var1).fst) && Objects.equals(this.snd, ((Pair)var1).snd);
}
public int hashCode() {
if (this.fst == null) {
return this.snd == null ? 0 : this.snd.hashCode() + 1;
} else {
return this.snd == null ? this.fst.hashCode() + 2 : this.fst.hashCode() * 17 + this.snd.hashCode();
}
}
public static <A, B> Pair<A, B> of(A var0, B var1) {
return new Pair(var0, var1);
}
}
我们将 Pair.fst 用来存储 cur 的信息,将 Pair.snd 用来存储 curdis 的信息。使用优先队列简化后的 Dijkstra 算法类如下:
Dijkstra_2
import java.util.Arrays;
import java.util.Comparator;
import java.util.PriorityQueue;
public class Dijkstra_2 {
private WeightedGraph G;
private int s;
private int[] dis;
private boolean[] visited;
public Dijkstra_2(WeightedGraph G, int s) {
this.G = G;
// 判断源点 s 的合法性
if (s < 0 || s >= G.V())
throw new IllegalArgumentException("vertex" + s + "is invalid");
this.s = s;
// 对 dis 数组进行初始化
dis = new int[G.V()];
Arrays.fill(dis, Integer.MAX_VALUE);
dis[s] = 0;
visited = new boolean[G.V()];
// Dijkstra 算法的流程
// 1. 找到当前没有访问的最短路节点
// 2. 确认这个节点的最短路就是当前大小
// 3. 根据这个节点的最短路大小,寻找这个节点相邻的节点并更新其他节点的路径长度
PriorityQueue<Pair<Integer, Integer>> pq = new PriorityQueue<>(Comparator.comparingInt(o -> o.snd));
pq.offer(new Pair<>(s, 0));
while (!pq.isEmpty()) {
int cur = pq.poll().fst;
if (visited[cur]) continue;
visited[cur] = true;
for (int w : G.adj(cur))
if (!visited[w] && dis[cur] + G.getWeight(cur, w) < dis[w]) {
dis[w] = dis[cur] + G.getWeight(cur, w);
pq.offer(new Pair<>(w, dis[w]));
}
}
}
public boolean isConnected(int v) {
if (v < 0 || v >= G.V())
throw new IllegalArgumentException("vertex" + s + "is invalid");
return visited[v];
}
public int dis(int v) {
if (v < 0 || v >= G.V())
throw new IllegalArgumentException("vertex" + s + "is invalid");
return dis[v];
}
}
优化后的 Dijkstra 算法的复杂度是多少呢?
优先队列中塞进去的元素个数的上界为图中的边的个数 E E E,而向优先队列出队与入队操作的复杂度为 l o g ( E ) log(E) log(E),所以我们优化后的 Dijkstra 算法的时间复杂度为 O ( E l o g E ) O(ElogE) O(ElogE)。
好啦,关于 Dijkstra 算法的介绍就到这里为止了。我们可以看到,Dijkstra 算法的流程理解起来其实不难,它的思想是一种贪心策略,但是,我们的代码写起来则是有一些复杂。如果认为代码比较难懂的童鞋们,可以先按照思路尝试自己写一下代码,然后就可以更好地理解示例代码每一句话的具体含义了~
Bellman-Ford 算法
上一章节中,我们介绍了 Dijkstra 算法,Dijkstra 算法主要处理的是没有负权边的单源最短路径问题。
那么对于含有负权边的图来说,该如何求解最短路径问题呢?
负权环
我们来看一下这个图:

该图为一个无向带权图,请求出从节点 a 到节点 c 的最短路径。
你可能会说,a -> b -> c 就是节点 a 到节点 c 的最短路,其值为 -2。… 等等,好像不是这么回事。
对于上面这个无向图来说,如果存在负权边,那么似乎是没有最短路的!因为我可以从节点 a 开始出发,无限地围绕着这个环走下去,这样就永远得不到最短路——实际上,完全不需要转圈浪费时间,我们到达节点 b 以后,反复地在 b-c 这条边“刷步数”就可以了:-)。
所以,对于一个无向图来说,存在负权边时,就一定不存在最短路径。其原因就在于负权边会构成负权环,而无向图的负权边自己就是一个负权环。而对于有向图来说,如果存在负权环也不存在最短路径,譬如下图:
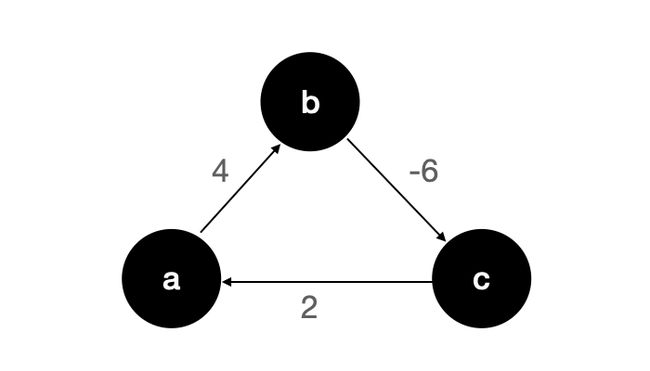
该图是一个有向图,但是存在负权环,我们也无法求得最短路径。
说一个题外话,笔者写到这里想起了一个小故事~
A 和 B 两个国家的国王吵架,A 国王生气了,规定 B 国的 100 元只能兑换 A 国的 90 元;B 国王听闻后也做出规定:A 国的 100 元也只能换 B 国的 90 元。在 A 国,有一个聪敏的家伙,利用这个规则赚到了一笔横财,你知道他是怎么做的嘛?(为啥写完了会觉得自己这么弱智)

闲话说回来。
对于带有负权边的图来说,我们需要对该图进行检测,检测图中是否存在负权环,如果存在负权环,那么该图就一定不存在最短路径。而检测负权环在算法的实现中是非常简单的,我们先来看一下存在负权边时求解最短路径的一个经典算法——Bellman-Ford 算法。
Bellman-Ford 算法
Bellman-Ford 算法的原理就在于松弛操作。

假设, d i s [ v ] dis[v] dis[v] 是从源点 s s s 到节点 v v v 经过边数不超过 k k k 的最短距离。
如果 d i s [ a ] + a b < d i s [ b ] dis[a] + ab < dis[b] dis[a]+ab<dis[b],我们就进行一次松弛操作,更新 d i s [ b ] = d i s [ a ] + a b dis[b] = dis[a] + ab dis[b]=dis[a]+ab;
所以,我们找到了从源点 s s s 到节点 b b b 经过边数不超过 k + 1 k+1 k+1 的最短距离。
同理,如果 d i s [ b ] + b a < d i s [ a ] dis[b] + ba < dis[a] dis[b]+ba<dis[a],我们就进行一次松弛操作,更新 d i s [ a ] = d i s [ b ] + b a dis[a] = dis[b] + ba dis[a]=dis[b]+ba;
这样,我们就找到了从源点 s s s 到节点 a a a 经过边数不超过 k + 1 k+1 k+1 的最短距离。
根据上述理论,我们的 Bellman-Ford 算法流程如下:
- 初始化 dis 数组,
dis[s] = 0,其余的值设置为 ∞ ∞ ∞ - 对所有边进行一次松弛操作,则求出了到所有点,经过边数最多为 1 的最短路
- 对所有边再进行一次松弛操作,则求出了到所有点,经过边数最多为 2 的最短路
- … …
- 对所有边进行 V-1 次松弛操作,则求出了到所有点,经过边数最多为 V-1 的最短路
我们的图只有 V 个顶点,如果不存在负权环,从一个顶点到另外一个顶点最多经过 V-1 条边,所以在我们对所有边进行了 V-1 次松弛操作后,我们就找到了源点到所有点的最短路,并且 Bellman-Ford算法支持存在负权边。
接下来,我们通过一个示例来模拟一下 Bellman-Ford 算法的执行流程,相信通过这个模拟过程,你一定会对 Bellman-Ford 算法有更加深刻的理解:-)
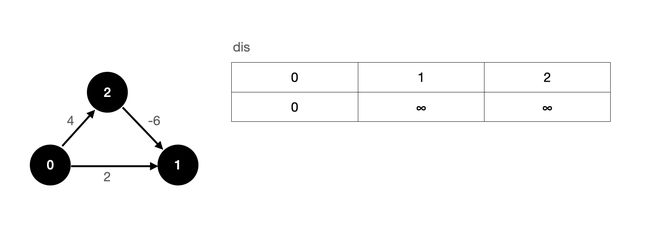
上图为一个有向带权图,我们规定节点 0 为源点,源点到源点的最短路初始值为 0,其余节点则使用 ∞ ∞ ∞ 来表示。
首先,我们对所有边进行一次松弛操作,假设我们先松弛 0-1 这条边,然后松弛 0-2 这条边,最后松弛 2-1 这条边,经过第一次松弛操作后,我们的 dis 数组更新如下:
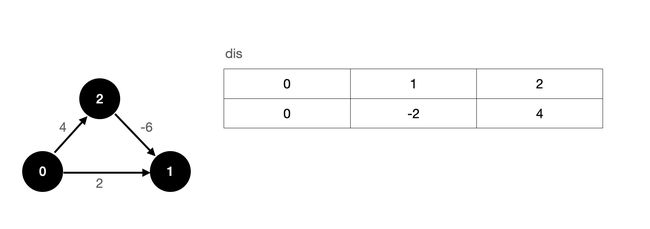
经过第一次松弛操作以后,我们实际上就已经求出了源点到各个顶点的最短路径了。
看上去,我们并不需要 V-1 次松弛操作?是这样么?实际上,V-1 次松弛操作是一个上界,我们完全有可能在小于 V-1 次松弛操作之后就得到结果,但是最坏的情况,我们也只需要 V-1 次松弛操作。
上面的示例中,我们从 0-1 这条边开始松弛,如果换一种思路,从 2-1 这条边开始松弛会是什么结果呢?
假设我们先松弛 2-1 这条边,然后松弛 0-1 这条边,最后松弛 0-2 这条边,经过第一次松弛操作后,我们的 dis 数组更新如下:

需要注意的是,在松弛 2-1 这条边时,我们会用 ∞ − 6 ∞ - 6 ∞−6 ,其值仍为 ∞ ∞ ∞。
第二次松弛操作后,我们的 dis 数组更新如下:

我们看到,经过了两次对所有边的松弛后,我们也得到了正确解。
那么如何检测负权环呢?
其实很简单,根据 Bellman-Ford 算法,如果我们的图不存在负权环,经过 V-1 次松弛操作后,我们就可以得到源点到各个节点的最短路径了,如果 V-1 次松弛操作后,我们再对所有边进行松弛,各个点的 dis 值是不会发生变化的;而如果图中存在负权环,经过 V-1 轮松弛操作后,再进行松弛操作,dis 数组的每个值仍然会发生变化。
所以在算法的设计上,我们只需要在 V-1 次松弛操作后,再进行一次松弛操作,判断 dis 数组是否发生改变,如果发生了改变,则说明图中存在负权环,即无法求得最短路径。
接下来,让我们看一下 Bellman-Ford 算法的具体实现。
Bellman-Ford 算法的代码实现
Bellman-Ford 算法的 Java 代码如下,代码中标明了详细的注释,我就不再解释了:-)
同样,测试代码的链接会在文章最后给出,测试部分就不在本文中赘述了。
Bellman-Ford
import java.util.Arrays;
public class BellmanFord {
private WeightedGraph G;
private int s;
private int[] dis;
public boolean hasNegativeCycle = false;
public BellmanFord(WeightedGraph G, int s) {
this.G = G;
if (s < 0 || s >= G.V())
throw new IllegalArgumentException("vertex" + s + "is invalid");
this.s = s;
dis = new int[G.V()];
Arrays.fill(dis, Integer.MAX_VALUE);
dis[s] = 0;
// V-1 轮松弛操作
for (int pass = 1; pass < G.V(); pass++) {
for (int v = 0; v < G.V(); v++)
for (int w : G.adj(v))
if (dis[v] != Integer.MAX_VALUE && dis[v] + G.getWeight(v, w) < dis[w])
dis[w] = dis[v] + G.getWeight(v, w);
}
// 再进行一次放松(松弛)操作,判断负权环
for (int v = 0; v < G.V(); v++)
for (int w : G.adj(v))
if (dis[v] != Integer.MAX_VALUE && dis[v] + G.getWeight(v, w) < dis[w])
hasNegativeCycle = true;
}
public boolean isConnected(int v) {
if (v < 0 || v >= G.V())
throw new IllegalArgumentException("vertex" + v + "is invalid");
return dis[v] != Integer.MAX_VALUE;
}
public int dis(int v) {
if (v < 0 || v >= G.V())
throw new IllegalArgumentException("vertex" + v + "is invalid");
if (hasNegativeCycle) throw new RuntimeException("Exist negative cycle");
return dis[v];
}
}
Bellman-Ford 算法的时间复杂度是多少呢?我们需要进行 V-1 轮松弛操作,每一次松弛操作都会遍历图中所有的边,所以,Bellman-Ford 算法的时间复杂度为 O ( V E ) O(VE) O(VE)。可以看到,Bellman-Ford 算法虽然可以解决负权边,但是其整体的复杂度是要差于 Dijkstra 算法的。
Bellman-Ford 算法我就介绍到这里了,接下来我们来看一下本篇文章介绍的最后一个算法——Floyd-Warshall 算法。
Floyd-Warshall 算法
我们在前面介绍了 Dijkstra 与 Bellman-Ford 这两种求解单源最短路径的算法,而本章节介绍的 Floyd-Warshall 算法则是一种用来求解所有点对(任意两点)最短路径的算法。
求解所有点对最短路径有什么意义呢?
如果我们知道图中任意两点的最短路径,我们就可以得到该图中任意两点最短路径的最大值,这个名词术语叫做图的直径。
举一个例子,如果我们的图表示一个互联网的网络系统,节点与节点之间的边表示两个中间站的传输延迟,如何去评价这个网络系统的性能?这个时候,求解图的直径就有着重大的意义。而求解图的直径就需要求解所有点对儿最短路径。
对于 Dijkstra 算法来说,求解单源最短路径的复杂度为 O ( E l o g E ) O(ElogE) O(ElogE),如果求解所有点对最短路径,则需要对图中的每个顶点求解一次单源路径问题,所以,其复杂度为 O ( V E l o g E ) O(VElogE) O(VElogE);而 Bellman-Ford 算法用来分析求解所有点对最短路径的思路也是一样的,其时间复杂度为 O ( V 2 E ) O(V^2E) O(V2E)。
对于 Floyd-Warshall 算法来说,求解所有点对最短路径的时间复杂度为 O ( V 3 ) O(V^3) O(V3),且可以求解负权边,接下来我们来看一下 Floyd-Warshall 算法的具体思路。
因为 Floyd-Warshall 算法中并没有源节点这个概念,或者可以认为对于每个节点来说,都是一个源节点,所以我们使用一个 d i s dis dis数组, d i s [ v ] [ w ] dis[v][w] dis[v][w] 表示顶点 v v v 到顶点 w w w 的最短路径。
d i s dis dis 数组的初始化也非常简单, d i s [ v ] [ v ] dis[v][v] dis[v][v] 的初始值设为 0,如果 d i s [ v ] [ w ] dis[v][w] dis[v][w] 存在一条边,那么就令 d i s [ v ] [ w ] dis[v][w] dis[v][w] 的初始值为节点 v v v 和节点 w w w 这条边的权值 v w vw vw,其余的则以 ∞ ∞ ∞ 来表示。
Floyd-Warshall 算法的伪码如下:
for(int t = 0; t < V; t++)
for(int v = 0; v < V; v++)
for(int w = 0; w < V; w++)
if(dis[v][t] + dis[t][w] < dis[v][w])
dis[v][w] = dis[v][t] + dis[t][w]
这段伪码描述的是一个什么过程呢?

如果节点 v v v 和节点 w w w 之间存在着某个节点 t t t,并且 d i s [ v ] [ t ] + d i s [ t ] [ w ] < d i s [ v ] [ w ] dis[v][t] + dis[t][w] < dis[v][w] dis[v][t]+dis[t][w]<dis[v][w],那么就更新 d i s [ v ] [ w ] 的 值 dis[v][w] 的值 dis[v][w]的值,这一步骤的本质实际上就是松弛操作。那么我们该如何理解 t t t 的含义呢?
t t t 这个循环表达的含义是,每一轮循环求解出中间经过 [ 0... t ] [0...t] [0...t] 这些点的最短路径。
- 赋初始值时,我们只考虑顶点 v v v 和顶点 w w w 不经过任何顶点时的距离;
- 当 t = 0 t = 0 t=0 时,我们考虑的就是,如果顶点 v v v 和顶点 w w w 中间经过了 0 这个顶点后,是否更新了当前的最短路;
- 当 t = 1 t = 1 t=1 时,我们考虑的就是,如果顶点 v v v 和顶点 w w w 中间经过了 [ 0 , 1 ] [0,1] [0,1] 中的顶点后,是否更新了当前的最短路;
- 当 t = V − 1 t = V-1 t=V−1 时,我们考虑的就是,如果顶点 v v v 和顶点 w w w 中间经过了 [ 0... V − 1 ] [0...V-1] [0...V−1] 中的顶点后,是否更新了当前的最短路。
Floyd-Warshall 算法检测负权环的原理和 Bellman-Ford 算法检测负权环的原理是实际上相同的,在算法结束之后,我们只需要遍历一遍图的所有顶点,看 d i s [ v ] [ v ] dis[v][v] dis[v][v] 是否有出现小于 0 的情况即可,如果出现了负值则表示该图中含有负权环。
好啦,Floyd-Warshall 算法的流程便是这样了,我们来看一下具体的代码实现。
Floyd-Warshall 算法的代码实现
Floyd-Warshall
import java.util.Arrays;
public class FloydWarshall {
private WeightedGraph G;
private int[][] dis;
public boolean hasNegativeCycle = false;
public FloydWarshall(WeightedGraph G) {
this.G = G;
dis = new int[G.V()][G.V()];
for (int i = 0; i < G.V(); i++)
Arrays.fill(dis[i], Integer.MAX_VALUE);
for (int v = 0; v < G.V(); v++) {
dis[v][v] = 0;
for (int w : G.adj(v))
dis[v][w] = G.getWeight(v, w);
}
for (int t = 0; t < G.V(); t++)
for (int v = 0; v < G.V(); v++)
for (int w = 0; w < G.V(); w++)
if (dis[v][t] != Integer.MAX_VALUE
&& dis[t][w] != Integer.MAX_VALUE
&& dis[v][t] + dis[t][w] < dis[v][w])
dis[v][w] = dis[v][t] + dis[t][w];
for (int v = 0; v < G.V(); v++)
if (dis[v][v] < 0) hasNegativeCycle = true;
}
public boolean isConnected(int v, int w) {
if (v < 0 || v >= G.V())
throw new IllegalArgumentException("vertex" + v + "is invalid");
if (w < 0 || w >= G.V())
throw new IllegalArgumentException("vertex" + w + "is invalid");
return dis[v][w] != Integer.MAX_VALUE;
}
public int dis(int v, int w) {
if (v < 0 || v >= G.V())
throw new IllegalArgumentException("vertex" + v + "is invalid");
if (w < 0 || w >= G.V())
throw new IllegalArgumentException("vertex" + w + "is invalid");
return dis[v][w];
}
}
可以看到,Floyd-Warshall 算法是一个易读的算法,我们可以很快看出,Floyd-Warshall 算法的复杂度为 O ( V 3 ) O(V^3) O(V3),虽然这个复杂度并没有优于 Dijkstra 算法,但是,Floyd-Warshall 算法却可以检测负权环,用于带有负权边的图,并且其复杂度优于 Bellman-Ford 算法求解所有点对最短路径。
不过,Floyd-Warshall 算法它最大的优点是简洁优美,这里面融汇的是 DP 算法的艺术。
总结
在这一篇文章中,我向你介绍了三种最短路径算法,这三种算法分别是 Dijkstra 算法,Bellman-Ford 算法以及 Floyd-Warshall 算法。
Dijkstra 算法是求解单源最短路径的经典算法,虽然无法求解带有负权边的图,但是 Dijkstra 算法仍然是一个非常有意义的算法,毕竟我们求解的最短路径问题,有很大一部分都是没有负权边的情况。
如果遇到有负权边的最短路径问题时,我们可以选择 Bellman-Ford 算法或 Floyd-Warshall 算法,前者用于解决单源最短路问题,后者则可以解决所有点对最短路问题。
好啦,至此为止,这篇文章就到这里了~欢迎大家关注我的公众号,在这里希望你可以收获更多的知识,我们下一期再见!