动态场景下的语义SLAM的简单实现(基于YOLOv5目标检测)
动态场景下的语义SLAM的简单实现
感谢这篇博客在前期给了我一点方向:https://blog.csdn.net/ns2942826077/article/details/103723018
一、前言
之前保研结束,就直接跟着研究生导师开始做毕设,毕设题目是动态场景下的语义SLAM。
我提交给本科这边的毕设要求有三点:
1、基于ORB-SLAM2,结合双目相机数据集构建出稠密点云地图和八叉树地图;
2、基于YOLO等目标检测算法,检测出图像的语义信息并分辨出图像中动态物体和静态物体,并剔除动态物体;
3、构建物体级别的路标并辅助定位,并结合语义信息构建环境的稀疏语义路标点地图;
第一点的实现网上应该有挺多类似的开源代码或者博客,不再赘述(其实是怕讲太多了毕业论文会被查重到自己)
本文主要做的是第二点,第三点之后做好了再来更新
二、代码
代码还是放在了百度云,因为我目前也还在修改中,会有一些的奇奇怪怪的文件,不必理会就是。(什么,你不知道哪些是奇奇怪怪的文件,那就继续往下看吧)
链接:https://pan.baidu.com/s/1nDwrOgntZ4T8jAUPpInlNg
提取码:d5m0
2021.12.9更新
偶然看了下百度云链接的下载次数,发现下载的挺多的

而百度云的下载速度确实有点拉跨,我研究了一下git的上传功能(终于!!已经想研究这个半年了),把这个代码传到了github上
链接: https://github.com/JinYoung6/orbslam_addsemantic.
之前有好多小伙伴咨询我关于深入学习语义SLAM的路线,最近我找到一个不错的课程,是深蓝学院的,有进阶需求的小伙伴可以看一看呀! https://www.shenlanxueyuan.com/channel/VHkEvKQSnh/detail
三、整体逻辑
1、整体是基于ORBSLAM2改的啦,再次膜拜大佬们。
2、ORB2的一个默认假设是环境中大部分物体的静态的,因此他就大大方方的提取所有的特征点,然后进行匹配。但是呢,环境中还是会有很多动态的物体,这些特征点匹配上了的话会导致位姿估计错误,没匹配上呢可能会导致跟踪失败。(移动机器人心理:说的就是你们,可恶的人类,你们动来动去的让我迷路了啦!)为了解决这个问题,移动机器人们想出了两个办法:一是消灭所有人类以及所有会动的东西(唔 这还挺有难度的,过几年再干吧),另一个办法就是借助人类目前研究的正火热的深度学习的方法,把动态物体识别出来,不去使用他们的特征点不就完事了。
3、目前已经有了挺多的使用深度学习方法剔除动态点来帮助SLAM的方法,比如有著名的DS-SLAM、DynaSLAM等。但是呢,它们这两个的办法都是把SLAM和语义分割识别相结合的(好吧,使用语义分割还是好处很大的,可以更精确的选中动态物体,不至于浪费静态的点),但是但是它们的运行速度大大降低了,运算成本太高了。于是我使用YOLO目标检测的方法进行动态特征点剔除。
4、我把物体分为三类,高动态、中等动态、低动态(直接认为静态)。只有在特征点处于高动态物体框内,又不处于低动态物体框内时才会把特征点给剔除 。(主要是YOLO框太大了,如果把框内全剔除的话太亏了)
高动态物体主要就是人,又不是在玩木头人游戏,正常场景中的人都是会动的;
低动态物体是电脑、冰箱这种正常人不太会去让它移动的东西;
中动态则是椅子、书本、键盘鼠标这种容易被移动的东西,还有汽车这种静止时一动不动,运动时乱动的东西。

5、总结:大致思路就是先把图片进行目标检测,得到动态物体框,再把结果给ORBSLAM2,让它不要去使用动态物体的特征点。
(由于水平有限,目前这版代码是先在YOLOv5检测得到检测结果以后,再把结果文本文件拿来让ORB去跑。害,还不会python和c++的接口怎么写)
(检测结果储存在ORB_SLAM2_AddSemantic/detect_result/数据集/detect_result 下面)
(编译方法参照orb2的编译方法,运行方法已经存在运行命令文件里面了)
四、代码修改
我修改的地方或者其他我看着可能可以修改的地方都有 //*** 这样的标注,可以直接在文件搜索然后定位到我修改过的地方。
1、添加了Object类
主要用来储存每帧中的物体框和物体类别,在Frame中有Object的指针,因此可以每来一个帧就刷新一次Object类。
2、修改了Frame类
1、加了两个判断函数,判断特征点是否在高动态物体框内,是否在低动态物体框内。
2、对所有未去畸的特征点mvKeys做了个判定,如果特征点被认为是动态物体的,则把特征点坐标改为(-1,-1),而后它就会在之后的校正图像形变的程序里被剔除。
3、修改了Tracking类
改变了GrabImageRGBD函数,在传入参数里加上了检测框。
4、改了System类
System::TrackRGBD函数的传入参数里加上了物体框
5、改了rgb_tum
添加了读取物体框的函数
6、改了FrameDrawer类
还是添加了Object类,使得显示图像可以画出物体框。
大概就是以上这些啦,还有的话应该问题不大了,还有问题可以评论区留言。
五、结果展示
嘿嘿,终于到了结果展示的时候了。
(1)把动态点标红: 可以看到左边的小帅哥右手边的电脑上的特征点是会被提取出来的,虽然这些特征点在小帅哥的物体框内

(2)动态点被剔除的结果:(干净了许多)
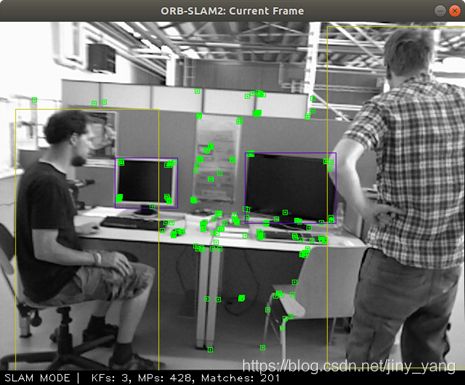
说了这么多,那么这个程序的实际运行效果怎么样呢??


1、在TUM_fr3_walking_xyz数据集中的测试结果表明这个程序的精度已经超过DS-SLAM啦,和DynaSLAM还有点差距。
2、在w_halfsphere数据集则被DS-SLAM和DynaSLAM吊打,哈哈哈,这很正常,毕竟我写程序时一直参考的数据集就是walking_xyz,看起来我这个程序的泛用性不行,毕竟策略太简单了一些。(开了周会之后,老师的建议是可以结合显著性检测的方法,来把动态物体检测框缩小,我觉得还是很可行的,但是还是先把毕设做完先。)
3、当然我的程序速度肯定是要远远快于DS和Dyna的。我用的可是一阶段目标检测算法YOLOv5,他们的都是语义分割算法。完全不是一个量级的速度。
就这样。溜~~~
更新:此篇文章还有后续的一篇,把语义检测线程和slam线程进行了并行,达到了实时运行的效果:
yolov5和orbslam2结合的实现方法 [使用UNIX域socket实现python和c++通信]
由于后续有好多同学在评论区评论问题或者私信我好多问题,我最近建了个QQ群用于slam初学者的相互学习交流,有需要的可以进一下,当然如果有大佬愿意进群帮忙一起解答当然是更好的!
群号-674274872,咱们悄悄的加,别被csdn发现了(之前的二维码截图还被查了。。)
有好多同学运行代码的时候遇到了段错误的问题,感谢群友的分享,这边有一个解决方式,贴出来放到这了。
