《Improving Language Understanding by Generative Pre-Training》论文笔记
引言
GPT(Generative Pre-Training) 受到 《Semi-Supervised Sequence Learning》与《Universal Language Model Fine-tuning for Text Classification》的启发,采用“预训练 + Fine-tune” 两阶段的方式,在不降低模型效果的基础上,以统一的模型结构处理不同的NLP任务,并有效地降低有监督学习对标注数据的依赖。
预训练阶段
GPT 采用 Transformer Decoder 做标准语言模型任务,给定长度为 N N N 的输入序列 U = u 1 , u 2 , . . . . . . , u n U = {u_1, u_2, ......, u_n} U=u1,u2,......,un ,最大如下似然:
L 1 = ∑ i = 1 N l o g P ( u t ∣ u 1 , . . . . . . , u t − 1 ; θ ) L1 = \sum_{i=1}^NlogP(u_t|u_1, ......,u_{t-1}; \theta) L1=i=1∑NlogP(ut∣u1,......,ut−1;θ)
具体计算过程如下:

Fine-Tune阶段
给定输入序列 x 1 , x 2 , . . . , x m x_1, x_2, ..., x_m x1,x2,...,xm 与对应的标签 y y y,
P ( y ∣ x 1 , x 2 , . . . , x n ) = s o f t m a x ( h m n w c ) P(y|x_1, x_2, ..., x_n) = softmax(h_m^n w_c) P(y∣x1,x2,...,xn)=softmax(hmnwc)
其中 h m n h_m^n hmn 表示 Decoder 最后一层第 m m m个元素对应的向量, w c w_c wc 是全连接层的学习参数。目标损失为:
L 2 = ∑ x , y l o g P ( y ∣ x 1 , x 2 , . . . , x n ) L_2 = \sum_{x, y} logP(y|x_1, x_2, ..., x_n) L2=x,y∑logP(y∣x1,x2,...,xn)
论文中指出,在Fine-Tune时,如果将语言模型作为辅助任务,有助于模型加速收敛、以及提高模型泛化能力,因此目标损失为 L = L 2 + λ ∗ L 1 L = L2 + \lambda * L1 L=L2+λ∗L1,一般取 λ = 0.5 \lambda = 0.5 λ=0.5。
GPT在下游各种任务的Fine-Tune策略如下图所示:
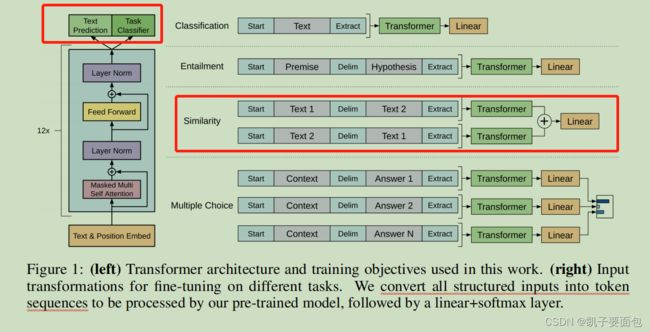
注意,对于“语义相似度”任务,有两种输入顺序,这种方式在GPT中是有效的,但在BERT是无效的,因为BERT采用的是全注意力。