SSD网络模型详解
一、主干网络为VGG16

步骤理解
下面算一下每一层的像素值计算:
输入:300 * 300 * 3
conv3-64(卷积核的数量)----------------------------------------kernel size:3 stride:1 padding:1
像素:(300 + 2 * 1 – 1 * (3 - 1)- 1 )/ 1 + 1=300 ---------------------输出尺寸:300 * 300 * 64
参数: (3 * 3 * 3)* 64 =1728
conv3-64-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素: (300 + 2 * 1 – 2 - 1)/ 1 + 1=300 ---------------------输出尺寸:300 * 300 * 64
参数: (3 * 3 * 64) * 64 =36864
pool2 ----------------------------------------------------------------kernel size:2 stride:2 padding:0
像素: (300 - 2)/ 2 = 112 ----------------------------------输出尺寸:150 * 150 * 64
参数: 0
conv3-128(卷积核的数量)--------------------------------------------kernel size:3 stride:1 padding:1
像素: (150 + 2 * 1 - 2 - 1) / 1 + 1 = 150 -------------------输出尺寸:150 * 150 * 128
参数: (3 * 3 * 64) * 128 =73728
conv3-128------------------------------------------------------------kernel size:3 stride:1 padding:1
像素: (150 + 2 * 1 -2 - 1) / 1 + 1 = 150 ---------------------输出尺寸:150 * 150 * 128
参数: (3 * 3 * 128) * 128 =147456
pool2------------------------------------------------------------------kernel size:2 stride:2 padding:0
像素: (150 - 2) / 2 + 1=75 ----------------------------------输出尺寸:75 * 75 * 128
参数:0
conv3-256(卷积核的数量)----------------------------------------------kernel size:3 stride:1 padding:1
像素: (75 + 2 * 1 - 2 - 1)/ 1+1=75 -----------------------------输出尺寸:75 * 75 * 256
参数:(3 * 3* 128)*256=294912
conv3-256-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素: (75 + 2 * 1 - 2 - 1) / 1 + 1=75 --------------------------输出尺寸:75 * 75 * 256
参数:(3 * 3 * 256) * 256=589824
conv3-256------------------------------------------------------------ kernel size:3 stride:1 padding:1
像素: (75 + 2 * 1 - 2 - 1) / 1 + 1=75 -----------------------------输出尺寸:75 * 75 * 256
参数:(3 * 3 * 256)*256=589824
pool2------------------------------------------------------------------kernel size:2 stride:2 padding:0
像素:(75 - 2) / 2 + 1 = 38-------------------------------------输出尺寸: 38 * 38 * 256
参数:0
conv3-512(卷积核的数量)------------------------------------------kernel size:3 stride:1 padding:1
像素:(38 + 2 * 1 - 2 - 1) / 1 + 1=38 ----------------------------输出尺寸:38 * 38 * 512
参数:(3 * 3 * 256) * 512 = 1179648
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(38 + 2 * 1 - 2 - 1) / 1 + 1=38 ----------------------------输出尺寸:38 * 38 * 512
参数:(3 * 3 * 512) * 512 = 2359296
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(38 + 2 * 1 - 2 - 1) / 1 + 1=38 ------------输出尺寸:38 * 38 * 512第一个预测特征层
***Conv_4_3 第一个预测特征层
参数:(3 * 3 * 512) * 512 = 2359296
pool2------------------------------------------------------------------ kernel size:2 stride:2 padding:0
像素:(38 - 2) / 2 + 1=19 -------------------------------------输出尺寸:19 * 19 * 512
参数: 0
conv3-512(卷积核的数量)----------------------------------------------kernel size:3 stride:1 padding:1
像素:(19 + 2 * 1 - 2 - 1) / 1 + 1=19 ---------------------------输出尺寸:19 * 19 * 512
参数:(3 * 3 * 512) * 512 = 2359296
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(19 + 2 * 1 - 2 - 1) / 1 + 1=19 ---------------------------输出尺寸:19 * 19 * 512
参数:(3 * 3 * 512) * 512 = 2359296
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(19 + 2 * 1 - 2 - 1) / 1 + 1=19 ---------------------------输出尺寸:19 * 19 *512 ***Conv_5_3
参数:(3 * 3 * 512) * 512 = 2359296
以上对应VGG16网络虚线以左的部分
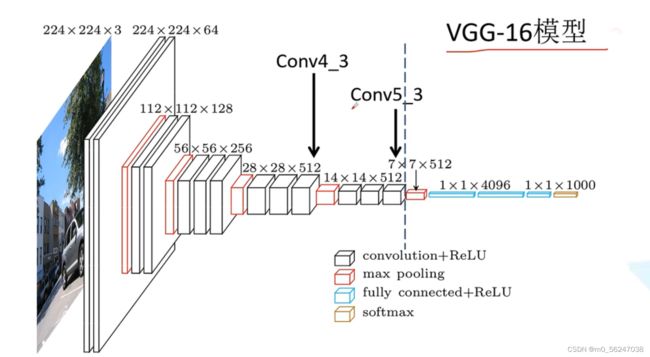
pool2------------------------------------------------------------------kernel size:3 stride:1 padding:1
***注意这里的池化层将原VGG16模型的kernel size:2 stride:2 padding:0变为了kernel size:3 stride:1 padding:1
像素:19 +2-2-1 / 1 + 1=19 ----------------------------------------输出尺寸:19 * 19 * 512
参数:0

conv3-1024-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(19 + 2 * 1 - 2 - 1) / 1 + 1=19 ---------------------------输出尺寸:19 * 19 * 1024
参数:(3 * 3 * 512) * 1024 = 4718592
得到Conv6(FC6)
conv1-1024-------------------------------------------------------------kernel size:1 stride:1 padding:0
像素:(19 + 0 - 0 - 1) / 1 + 1=19 ----------输出尺寸:19 * 19 *1024 第二个预测特征层
参数:(1 * 1 * 1024) * 1024 = 1048576
得到Conv7(FC7) 第二个预测特征层
--------------------------------------从这里往前都是VGG的结构--------------------------------------------
'''
该代码用于获得VGG主干特征提取网络的输出。
输入变量i代表的是输入图片的通道数,通常为3。
300, 300, 3 -> 300, 300, 64 -> 300, 300, 64 -> 150, 150, 64 -> 150, 150, 128 -> 150, 150, 128 -> 75, 75, 128 ->
75, 75, 256 -> 75, 75, 256 -> 75, 75, 256 -> 38, 38, 256 -> 38, 38, 512 -> 38, 38, 512 -> 38, 38, 512 -> 19, 19, 512 ->
19, 19, 512 -> 19, 19, 512 -> 19, 19, 512 -> 19, 19, 512 -> 19, 19, 1024 -> 19, 19, 1024
38, 38, 512的序号是22
19, 19, 1024的序号是34
'''
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512]
def vgg(pretrained = False):
layers = []
in_channels = 3
for v in base:
if v == 'M': #最大池化
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C': #开启ceil_mode的最大池化
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else: #卷积加激活函数
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
# 19, 19, 512 -> 19, 19, 512
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) #步距为1的最大池化,不会进行高和宽的压缩
# 19, 19, 512 -> 19, 19, 1024
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
# 19, 19, 1024 -> 19, 19, 1024
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6, nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)] #conv6,conv7卷积后都跟有激活函数
model = nn.ModuleList(layers)
if pretrained:
state_dict = load_state_dict_from_url("https://download.pytorch.org/models/vgg16-397923af.pth", model_dir="./model_data")
state_dict = {k.replace('features.', '') : v for k, v in state_dict.items()}
model.load_state_dict(state_dict, strict = False)
return model
if __name__ == "__main__":
net = vgg()
for i, layer in enumerate(net): # i对应的是层名称,layer对应的是层结构
print(i, layer)打印vgg各层,21层对应的是预测特征层1,33层对应的是预测特征层2
0 Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
1 ReLU(inplace=True)
2 Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
3 ReLU(inplace=True)
4 MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
5 Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
6 ReLU(inplace=True)
7 Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
8 ReLU(inplace=True)
9 MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
10 Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
11 ReLU(inplace=True)
12 Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
13 ReLU(inplace=True)
14 Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
15 ReLU(inplace=True)
16 MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
17 Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
18 ReLU(inplace=True)
19 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
20 ReLU(inplace=True)
21 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
22 ReLU(inplace=True)
23 MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
24 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
25 ReLU(inplace=True)
26 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
27 ReLU(inplace=True)
28 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
29 ReLU(inplace=True)
30 MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
31 Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
32 ReLU(inplace=True)
33 Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
34 ReLU(inplace=True)
conv1-256-------------------------------------------------------------kernel size:1 stride:1 padding:0
像素:(19 + 0 - 0 - 1) / 1 + 1=19 ---------------------------输出尺寸:19 * 19 * 256
参数:(1 * 1 * 1024) * 256 = 262144
conv3-512-------------------------------------------------------------kernel size:3 stride:2 padding:1
像素:(19 + 2 * 1 - 2 - 1) / 2 + 1=10 ------输出尺寸:10 * 10 * 512 第三个预测特征层
参数:(3 * 3 * 256) * 512 = 1179648
得到Conv8-2 第三个预测特征层
conv1-128-------------------------------------------------------------kernel size:1 stride:1 padding:0
像素:(10 + 0 - 0 - 1) / 1 + 1=10 ---------------------------输出尺寸:10 * 10 * 128
参数:(1 * 1 * 512) * 128 = 65536
conv3-256-------------------------------------------------------------kernel size:3 stride:2 padding:1
像素:(10 + 2 * 1 - 2 - 1) / 2 + 1=5 ------输出尺寸:5 * 5 *256 第四个预测特征层
参数:(3 * 3 * 128) * 256 = 294912
得到Conv9-2 第四个预测特征层
conv1-128-------------------------------------------------------------kernel size:1 stride:1 padding:0
像素:(5 + 0 - 0 - 1) / 1 + 1=5 ---------------------------输出尺寸:5 * 5 * 128
参数:(1 * 1 * 256) * 128 = 32768
conv3-256-------------------------------------------------------------kernel size:3 stride:1 padding:0
像素:(5 + 0 - 2 - 1) / 1 + 1=3 ------输出尺寸:3 * 3 *256 第五个预测特征层
参数:(3 * 3 * 128) * 256 = 294912
得到Conv10-2 第五个预测特征层
conv1-128-------------------------------------------------------------kernel size:1 stride:1 padding:0
像素:(3 + 0 - 0 - 1) / 1 + 1=3 ---------------------------输出尺寸:3 * 3 * 128
参数:(1 * 1 * 256) * 128 = 32768
conv3-256-------------------------------------------------------------kernel size:3 stride:1 padding:0
像素:(3 + 0 - 2 - 1) / 1 + 1=1 ------输出尺寸:1 * 1 *256 第六个预测特征层
参数:(3 * 3 * 128) * 256 = 294912
得到Conv11-2 第六个预测特征层
def add_extras(in_channels, backbone_name): # 构建额外卷积层(预测特征层)
layers = []
if backbone_name == 'vgg':
# Block 6
# 19,19,1024 -> 19,19,256 -> 10,10,512 预测特征层3
layers += [nn.Conv2d(in_channels, 256, kernel_size=1, stride=1)] #通过1*1卷积降低通道数,减少运算量
layers += [nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)] #获得特征层10,10,512
# Block 7
# 10,10,512 -> 10,10,128 -> 5,5,256 预测特征层4
layers += [nn.Conv2d(512, 128, kernel_size=1, stride=1)] #通过1*1卷积降低通道数,减少运算量
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)] #获得特征层5,5,256
# Block 8
# 5,5,256 -> 5,5,128 -> 3,3,256 预测特征层5
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)] #通过1*1卷积降低通道数,减少运算量
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)] #获得特征层3,3,256
# Block 9
# 3,3,256 -> 3,3,128 -> 1,1,256 预测特征层6
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)] #通过1*1卷积降低通道数,减少运算量
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)] #获得特征层1,1,256
return nn.ModuleList(layers)SSD整体网络结构(VGG16)
class SSD300(nn.Module):
def __init__(self, num_classes, backbone_name, pretrained = False):
super(SSD300, self).__init__()
self.num_classes = num_classes
if backbone_name == "vgg":
self.vgg = add_vgg(pretrained) #对应vgg主干网络
self.extras = add_extras(1024, backbone_name) #对应四个额外添加层
self.L2Norm = L2Norm(512, 20)
mbox = [4, 6, 6, 6, 4, 4]
loc_layers = []
conf_layers = []
backbone_source = [21, -2]
#---------------------------------------------------#
# 在add_vgg获得的特征层里
# 第21层和-2层对应预测特征层38, 38, 512和19, 19, 1024
# 分别是conv4-3(38,38,512)和conv7(19,19,1024)的输出
# 第21层和-2层可以用来进行回归预测和分类预测。
# k=0,v=21;k=1,v=-2; self.vgg[v].out_channels代表vgg中第v层的out_channels
for k, v in enumerate(backbone_source): #可获取前两个预测特征层
# 回归预测结果,输出通道数为mbox[k] * 4
loc_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
# 分类预测结果,输出通道数为mbox[k] * num_classes
conf_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
#-------------------------------------------------------------#
# 在add_extras获得的特征层里
# 第1层、第3层、第5层、第7层可以用来进行回归预测和分类预测(注意是从零开始数的)。
# shape分别为(10,10,512), (5,5,256), (3,3,256), (1,1,256)
# [1::2]代表从第2个元素起,步长为2取元素;也就是取第1、3、5、7层
# enumerate(self.extras[1::2], 2)后面这个2表示k从2开始
# k=2对应extras的第一层,k=3对应extras的第三层,k=4对应extras的第五层,k=5对应extras的第七层
# v.out_channels分别表示extras的第1、3、5、7层的out_channels
for k, v in enumerate(self.extras[1::2], 2): #每隔两个卷积获得预测特征层,可获取后四个预测特征层
# 回归预测结果,输出通道数为mbox[k] * 4
loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
# 分类预测结果,输出通道数为mbox[k] * num_classes
conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
self.loc = nn.ModuleList(loc_layers)
self.conf = nn.ModuleList(conf_layers)
self.backbone_name = backbone_name
def forward(self, x): #正向传播过程
#---------------------------#
# x是300,300,3
#---------------------------#
sources = list()
loc = list()
conf = list()
#---------------------------#
# 获得conv4_3的内容
# shape为38,38,512
#---------------------------#
if self.backbone_name == "vgg":
for k in range(23): #循环vgg网络的前22层,也就是获取对应38,38,512特征层
x = self.vgg[k](x)
#---------------------------#
# conv4_3的内容
# 需要进行L2标准化
#---------------------------#
s = self.L2Norm(x) #进行L2标准化
sources.append(s) #加入sources
#---------------------------#
# 获得conv7的内容
# shape为19,19,1024
#---------------------------#
if self.backbone_name == "vgg":
for k in range(23, len(self.vgg)): #获取19,19,1024特征层
x = self.vgg[k](x)
sources.append(x) #加入sources
#-------------------------------------------------------------#
# 在add_extras获得的特征层里
# 因为是从第0层开始算的,所以我们需要获取第1,3,5,7层
# 第1层、第3层、第5层、第7层可以用来进行回归预测和分类预测
# shape分别为(10,10,512), (5,5,256), (3,3,256), (1,1,256)
#-------------------------------------------------------------#
for k, v in enumerate(self.extras): #获取四个额外预测特征层
x = F.relu(v(x), inplace=True)
if self.backbone_name == "vgg":
if k % 2 == 1: #获取第1层、第3层、第5层、第7层
sources.append(x) #将这四个特征层加入sources
#-------------------------------------------------------------#
# 为获得的6个有效特征层添加回归预测和分类预测
#-------------------------------------------------------------#
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
#-------------------------------------------------------------#
# 进行reshape方便堆叠
#-------------------------------------------------------------#
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
#-------------------------------------------------------------#
# loc会reshape到batch_size, num_anchors, 4
# conf会reshap到batch_size, num_anchors, self.num_classes
#-------------------------------------------------------------#
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
)
return output
在上述六个预测特征层上分别预测不同大小的目标,38 * 38 * 512负责预测相对较小的目标,1 * 1 *256负责预测相对较大的目标
特征层一、五、六,这三个预测特征层采用4个default box
特征层二、三、四,这三个预测特征层采用6个default box

二、主干网络为Resnet50

Resnet50主干网络(只用了layer3及其之前层)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet50(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
class Backbone(nn.Module):
def __init__(self, pretrain_path=None):
super(Backbone, self).__init__()
net = resnet50() #实例化resnet50
self.out_channels = [1024, 512, 512, 256, 256, 256] #对应每个预测特征层的channel
if pretrain_path is not None: #是否传入了与训练模型权重
net.load_state_dict(torch.load(pretrain_path))
# 构建特征提取部分,提取net.children()中0到6层,分别是conv1 bn1 relu maxpool layer1 layer2 layer3
self.feature_extractor = nn.Sequential(*list(net.children())[:7])
# 对feature_extractor中的最后一层也就是conv4_block1中的第一个残差块修改步距
conv4_block1 = self.feature_extractor[-1][0]
# 修改conv4_block1的步距,从2->1
conv4_block1.conv1.stride = (1, 1) #这一行可以不要,因为本来步距就为1
conv4_block1.conv2.stride = (1, 1)
conv4_block1.downsample[0].stride = (1, 1)
def forward(self, x):
x = self.feature_extractor(x)
return x
class SSD300(nn.Module):
def __init__(self, backbone=None, num_classes=21):
super(SSD300, self).__init__()
if backbone is None:
raise Exception("backbone is None")
if not hasattr(backbone, "out_channels"):
raise Exception("the backbone not has attribute: out_channel")
self.feature_extractor = backbone #将backbone赋给变量feature_extractor
self.num_classes = num_classes
# out_channels = [1024, 512, 512, 256, 256, 256] for resnet50
self._build_additional_features(self.feature_extractor.out_channels)
self.num_defaults = [4, 6, 6, 6, 4, 4] #每一个预测特征层上每个网格所生成预测框的数量
location_extractors = [] #位置预测
confidence_extractors = [] #置信度预测
# feature_extractor.out_channels = [1024, 512, 512, 256, 256, 256] for resnet50
for nd, oc in zip(self.num_defaults, self.feature_extractor.out_channels):
# nd is number_default_boxes, oc is output_channel
location_extractors.append(nn.Conv2d(oc, nd * 4, kernel_size=3, padding=1))
confidence_extractors.append(nn.Conv2d(oc, nd * self.num_classes, kernel_size=3, padding=1))
self.loc = nn.ModuleList(location_extractors)
self.conf = nn.ModuleList(confidence_extractors)
self._init_weights() #对额外的添加层结构和预测器进行权重初始化
default_box = dboxes300_coco()
self.compute_loss = Loss(default_box)
self.encoder = Encoder(default_box)
self.postprocess = PostProcess(default_box)
def _build_additional_features(self, input_size): #input_size就是这六个预测特征层的channels
"""
为backbone(resnet50)添加额外的一系列卷积层,得到相应的一系列特征提取器
:param input_size:
:return:
"""
additional_blocks = []
# input_size = [1024, 512, 512, 256, 256, 256] for resnet50
middle_channels = [256, 256, 128, 128, 128] #后五个额外添加层中第一个卷积层的channels
# input_ch=[1024, 512, 512, 256, 256]
# output_ch=[512, 512, 256, 256, 256]
for i, (input_ch, output_ch, middle_ch) in enumerate(zip(input_size[:-1], input_size[1:], middle_channels)):
padding, stride = (1, 2) if i < 3 else (0, 1)
layer = nn.Sequential(
# layer1,2,3,4,5中的第一个卷积padding=0, stride=1
nn.Conv2d(input_ch, middle_ch, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_ch),
nn.ReLU(inplace=True),
# layer1,2,3中的第二个卷积padding=1, stride=2;layer4,5中的第二个卷积padding=0, stride=1
nn.Conv2d(middle_ch, output_ch, kernel_size=3, padding=padding, stride=stride, bias=False),
nn.BatchNorm2d(output_ch),
nn.ReLU(inplace=True),
)
additional_blocks.append(layer) #添加进列表additional_blocks = []中
self.additional_blocks = nn.ModuleList(additional_blocks)
def _init_weights(self): #对额外的添加层结构和预测器进行权重初始化
layers = [*self.additional_blocks, *self.loc, *self.conf]
for layer in layers:
for param in layer.parameters():
if param.dim() > 1:
nn.init.xavier_uniform_(param)
# Shape the classifier to the view of bboxes
def bbox_view(self, features, loc_extractor, conf_extractor):
locs = []
confs = []
# f对应每一个预测特征层,l对应每一个Feature Map的location特征预测器,c对应每一个Feature Map的confidence特征预测器
# 通过下面这个for循环,得到了所有预测特征层上的locs和confs回归参数
for f, l, c in zip(features, loc_extractor, conf_extractor):
# [batch, n*4, feat_size, feat_size] -> [batch, 4, -1]
locs.append(l(f).view(f.size(0), 4, -1)) #通过view方法调整格式,-1表示自动推理
# [batch, n*classes, feat_size, feat_size] -> [batch, classes, -1]
confs.append(c(f).view(f.size(0), self.num_classes, -1)) #通过view方法调整格式,-1表示自动推理
# 将locs, confs都在维度2上拼接
locs, confs = torch.cat(locs, 2).contiguous(), torch.cat(confs, 2).contiguous()
return locs, confs
def forward(self, image, targets=None): #正向传播过程
x = self.feature_extractor(image) #conv_4得到的预测特征层38x38x1024
# Feature Map 38x38x1024, 19x19x512, 10x10x512, 5x5x256, 3x3x256, 1x1x256
detection_features = torch.jit.annotate(List[Tensor], []) # [x]
detection_features.append(x) #将Feature Map 38x38x1024加入detection_features中
for layer in self.additional_blocks:
x = layer(x) #将Feature Map 38x38x1024依次通过五个额外添加层
detection_features.append(x) #并把每一层输出添加进detection_features中
# Feature Map 38x38x4, 19x19x6, 10x10x6, 5x5x6, 3x3x4, 1x1x4
locs, confs = self.bbox_view(detection_features, self.loc, self.conf)
# For SSD 300, shall return nbatch x 8732 x {nlabels, nlocs} results
# 38x38x4 + 19x19x6 + 10x10x6 + 5x5x6 + 3x3x4 + 1x1x4 = 8732
if self.training:
if targets is None:
raise ValueError("In training mode, targets should be passed")
# bboxes_out (Tensor 8732 x 4), labels_out (Tensor 8732)
bboxes_out = targets['boxes']
bboxes_out = bboxes_out.transpose(1, 2).contiguous()
# print(bboxes_out.is_contiguous())
labels_out = targets['labels']
# print(labels_out.is_contiguous())
# ploc, plabel, gloc, glabel
loss = self.compute_loss(locs, confs, bboxes_out, labels_out)
return {"total_losses": loss}
# 将预测回归参数叠加到default box上得到最终预测box,并执行非极大值抑制虑除重叠框
# results = self.encoder.decode_batch(locs, confs)
results = self.postprocess(locs, confs)
return results
reference
2.2 SSD源码解析(Pytorch)_哔哩哔哩_bilibili
Pytorch 搭建自己的SSD目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili