可形变注意力机制的总结
综述
非常容易理解,这个机制的诞生。既然有可形变卷积,且表现出不错的效果,自然就会产生可形变注意力机制。可形变卷积更多是卷积每一个部分的偏移,可形变注意力是patch的大小和整体位置的改变。从整体上说可形变注意力在算力上影响并不大,因为位置的预测基本上是和整体任务分离的(不全是比如人脸位置定位),patch位置和大小一般是由一个线性连接层直接得到。
另外一件事,纯注意力机制+可形变注意力并没有出现。
文章
patch的位置和大小其实是可形变注意力机制的核心问题。
目前看到的带有“自定义patch位置和大小的论文”有(未完待续):
- Stand-Alone Inter-Frame Attention in Video Models CVPR2022 动作识别中的一部分机制
- Vision Transformer with Deformable Attention CVPR2021 形变注意力机制
- DPT: Deformable Patch-based Transformer for Visual Recognition ACM MM 2021 形变注意力机制
- Deformable DETR: Deformable Transformers for End-to-End Object Detection ICLR2021 加速DETR训练
- Sparse Local Patch Transformer for Robust Face Alignment and Landmarks Inherent Relation Learning CVPR2022 定位人脸
代码
这一部分主要集中于可形变注意力机制的patch位置是怎么生成的:
DPT: Deformable Patch-based Transformer for Visual

内容部分
这篇文章的程序有几个特点:
- 可学习的位置和patch大小
- plug&play 在PVT结构上进行的逐层改变,计算量增加小
“DePatch can adjust the position and scale of each patch based on the input image”
代码部分
主体结构没有改变主要是patch_embed的方式不同
x, (H, W) = self.patch_embed2(x)
if isinstance(x, tuple):
aux_results.append(x[1])
x = x[0]
x = x + self.pos_embed2
x = self.pos_drop2(x)
for blk in self.block2:
x = blk(x, H, W)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
patch_embed方式,第一阶段不变形后三个阶段变形。box_coder是个函数,怎么裁剪patch指定的形状。
Simple_DePatch用来使用box_coder把每个patch裁剪成指定形状。
def _build_patch_embeds(embed_dims, img_size, Depatch):
patch_embeds=[]
for i in range(4):
inchans = embed_dims[i-1] if i>0 else 3
in_size = img_size // 2**(i+1) if i>0 else img_size
patch_size = 2 if i > 0 else 4
if Depatch[i]:
box_coder = pointwhCoder(input_size=in_size, patch_count=in_size//patch_size, weights=(1.,1.,1.,1.), pts=3, tanh=True, wh_bias=torch.tensor(5./3.).sqrt().log())
patch_embeds.append(
Simple_DePatch(box_coder, img_size=in_size, patch_size=patch_size, patch_pixel=3, patch_count=in_size//patch_size,
in_chans=inchans, embed_dim=embed_dims[i], another_linear=True, use_GE=True, with_norm=True))
else:
patch_embeds.append(
PatchEmbed(img_size=in_size, patch_size=patch_size, in_chans=inchans,
embed_dim=embed_dims[i]))
return patch_embeds
box_coder代码如下:根据送入坐标和长宽生成裁剪框返回裁剪的坐标位置
def forward(self, pts, model_offset=None):
assert model_offset is None
if self.wh_bias is not None:
print(pts.shape)
pts[:, :, 2:] = pts[:, :, 2:] + self.wh_bias
self.boxes = self.decode(pts)
points = self.meshgrid(self.boxes)
return points
Simple_DePatch代码如下:其中self.act是一个gelu层,offsetpredictor是一个线性层输入是输入为dim输出为4(位置+大小)。最后按照位置信息做一个自注意力。
@torch.cuda.amp.autocast(enabled=False)
def forward(self, x, model_offset=None):
if x.dim() == 3:
B, H, W = x.shape[0], self.img_size, self.img_size
assert x.shape[1] == H * W
x = x.view(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
B, C, H, W = x.shape
img = x
print('img:',img.shape)
x = self.patch_embed(x)
print('patch_embed:',x.shape)
if self.another_linear:
pred_offset = self.offset_predictor(self.act(x))
print('pred_offset:',pred_offset.shape)
else:
pred_offset = x.contiguous()
return self.get_output(img, pred_offset, model_offset), (self.patch_count, self.patch_count)
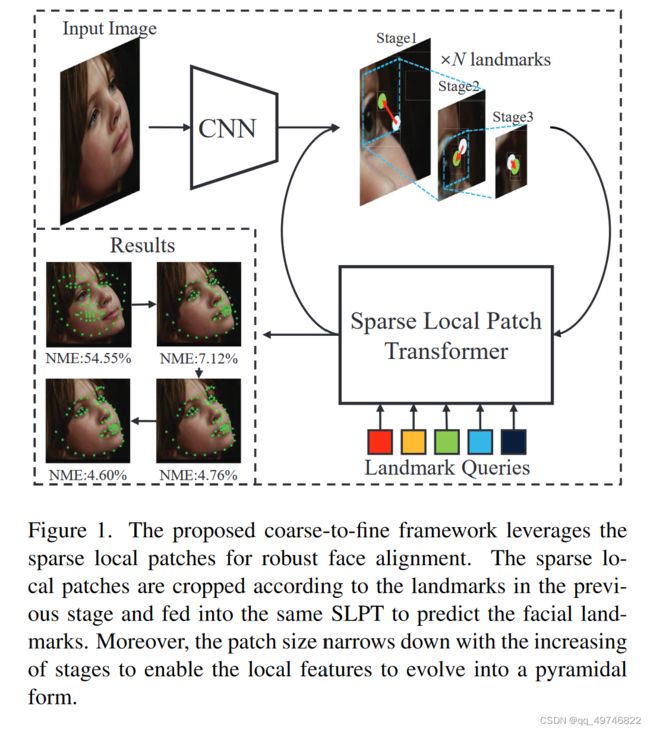
Sparse Local Patch Transformer for Robust Face Alignment and Landmarks Inherent Relation Learning
内容部分
这是一篇标注人脸landmark的文章,这篇的特点比较明显:
- 点的位置是注意力patch的位置
- 根据点所在patch得出landmark移动位置。
代码部分
三个迭代,从最初默认值开始。每一个迭代过程如下
- 第一步得到锚点、框的大小和初始点的位置
- 第二部根据锚点切割特征图 interpolation部分(自己写了一个双线性插值)
- 把7x7特征图用一个卷积卷成1x1然后做注意力机制得到新的初始点位置和旧位置的偏差值。
# stage_1
ROI_anchor_1, bbox_size_1, start_anchor_1 = self.ROI_1(initial_landmarks.detach())
ROI_anchor_1 = ROI_anchor_1.view(bs, self.num_point * self.Sample_num * self.Sample_num, 2)
ROI_feature_1 = self.interpolation(feature_map, ROI_anchor_1.detach()).view(bs, self.num_point, self.Sample_num,
self.Sample_num, self.d_model)
# torch.Size([1, 98, 7, 7, 256])
ROI_feature_1 = ROI_feature_1.view(bs * self.num_point, self.Sample_num, self.Sample_num,
self.d_model).permute(0, 3, 2, 1)
#torch.Size([98, 256, 7, 7])
transformer_feature_1 = self.feature_extractor(ROI_feature_1).view(bs, self.num_point, self.d_model)
offset_1 = self.Transformer(transformer_feature_1)
offset_1 = self.out_layer(offset_1)
landmarks_1 = start_anchor_1.unsqueeze(1) + bbox_size_1.unsqueeze(1) * offset_1
output_list.append(landmarks_1)
Vision Transformer with Deformable Attention
内容部分
和第一个DPT一样,移动范围有限制,结构比较简单,且没有大小信息。
将未经偏置的patches作为q,对q中每个patch做偏移预测,用这个偏移生成k和v,之后做注意力运算。

偏置网络网络实现为两个具有非线性激活的卷积模块,如图2(b)所示。首先对输入特征进行5,5深度卷积以捕获局部特征。然后采用GELU激活和1x1卷积得到二维偏移量。同样值得注意的是,为了减轻所有位置的强制移位,在1x1卷积中的偏差被降低了。得到这个偏置后用双线性插值来得到k和v。
代码部分
q = self.proj_q(x)
q_off = einops.rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)
offset = self.conv_offset(q_off) # B * g 2 Hg Wg
Hk, Wk = offset.size(2), offset.size(3)
n_sample = Hk * Wk
offset是相对位移(大家好像都用相对位移)。生成offset的和之前的transformer、linear不同用的是卷积。
self.conv_offset = nn.Sequential(
nn.Conv2d(self.n_group_channels, self.n_group_channels, kk, stride, kk//2, groups=self.n_group_channels),
LayerNormProxy(self.n_group_channels),
nn.GELU(),
nn.Conv2d(self.n_group_channels, 2, 1, 1, 0, bias=False)
)
Stand-Alone Inter-Frame Attention in Video Models

文章内容
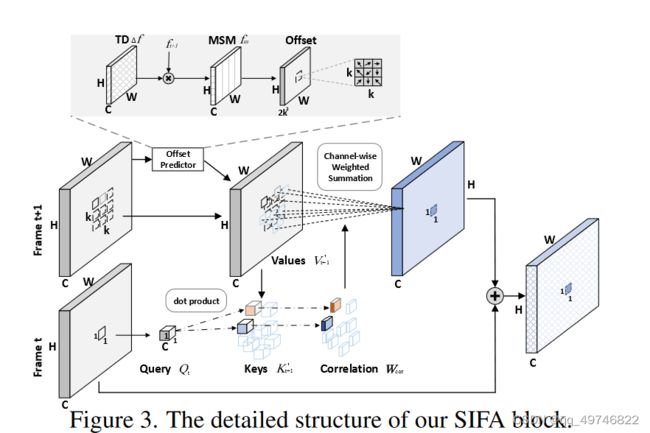
这篇文章是一篇视频动作识别的论文,和之前的图像分类文章不同。从结构来说它做的是将当前帧的patch(作为Q)和下一帧的八邻域patches(作为K和V)之间做一个注意力。这个九个patches根据offset predictor 预测做的注意力和原位置做注意力的相加。
另外一个特点就是是以通用图像识别骨干网络(resnet)作为主干网络的。
代码部分
导入模型注册模型过程比较难看,可以直接看/model/c2d_sifa_resnet.py
这个帧间关系的模块用在了resnet的倒数三个layer。
x_origin = self.layer4(x)
x_dual = self.maxpool_dual(x) #两帧抽一帧
x_dual = self.layer4_dual(x_dual) #抽一帧之后再来resnet_layer
x_g_origin = self.pool(x_origin)
x_g_dual = self.pool_dual(x_dual)
x_g_origin = self.drop(x_g_origin)
x_g_dual = self.drop_dual(x_g_dual)
x1_origin = self.fc(x_g_origin)
x1_dual = self.fc_dual(x_g_dual)
return [x1_origin, x1_dual]

(看的恶心死我了,清华是什么世界二流大学啊。)
out_tmp是运动图,通过运动图求偏置。这个偏置是2kk个位移。
corre_weight做一个带偏置的注意力
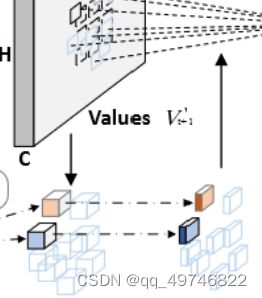
out_agg是融合,详细代码在下面:
# insert the aggregate block
out_tmp = out.clone()
out_tmp[:,:,1:,:,:] = out_tmp[:,:,:-1,:,:]
out_tmp = (torch.sigmoid(out - out_tmp) * out) + out # [sig(f_{t}-f_{t-1})*f_{t}]*f_{t}
offset = self.conv_offset(out_tmp)
corre_weight = self.def_cor(out, offset)
out_agg = self.def_agg(out, offset, corre_weight)
mask = torch.ones(out.size()).cuda()
mask[:,:,-1,:,:] = 0
mask.requires_grad = False
out_shift = out_agg.clone()
out_shift[:,:,:-1,:,:] = out_shift[:,:,1:,:,:]
out = out + out_shift * mask
代码写了一段cuda:核心代码如下:实现了下一帧的n个patch和本帧的patch相乘再乘一个通道权重。
float val = static_cast<float>(0);
const int c_in_start = group_id * c_in_per_defcor;
const int c_in_end = (group_id + 1) * c_in_per_defcor;
if (h_im > -1 && w_im > -1 && h_im < height && w_im < width){
for (int c_in = c_in_start; c_in < c_in_end; ++c_in){
const int former_ptr = (((n_out * channels + c_in) * times + t_former) * height + h_out) * width + w_out;
const int weight_offset = ((c_in * times + t_out) * kernel_h + kh) * kernel_w + kw;
const float* data_im_ptr = data_im + ((n_out * channels + c_in) * times + t_out) * height * width;
float next_val = im2col_bilinear_cuda(data_im_ptr, width, height, width, h_im, w_im);
val += (data_weight[weight_offset] * data_im[former_ptr] * next_val);
}
}
data_out[index] = val;
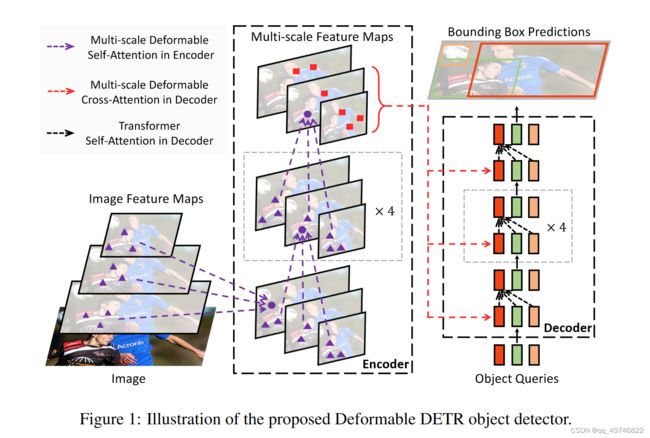
DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
内容部分
这篇文章是一篇目标检测的文章,使用可形变注意力机制的目的是加速训练流程。“We propose the deformable attention module, which attends to a small set of sampling locations(位移) as a pre-filter for prominent key elements out of all the feature map pixels.”大体上就是每个patch做注意力太慢了,先来个位置上的移动,再做注意力。
换句话说就是用偏置把本来应该由注意力机制学到的东西,变成位置直接得到。
代码部分
把每一个分类的特征图取出来,取出来之后的q做一个偏移,把和这个分类有关的位置的patch放到学习到的位置。
N, Len_q, _ = query.shape
N, Len_in, _ = input_flatten.shape
assert (input_spatial_shapes[:, 0] * input_spatial_shapes[:, 1]).sum() == Len_in
value = self.value_proj(input_flatten)
if input_padding_mask is not None:
value = value.masked_fill(input_padding_mask[..., None], float(0))
value = value.view(N, Len_in, self.n_heads, self.d_model // self.n_heads)
sampling_offsets = self.sampling_offsets(query).view(N, Len_q, self.n_heads, self.n_levels, self.n_points, 2)
attention_weights = self.attention_weights(query).view(N, Len_q, self.n_heads, self.n_levels * self.n_points)
attention_weights = F.softmax(attention_weights, -1).view(N, Len_q, self.n_heads, self.n_levels, self.n_points)
偏置的生成。
self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)