ssd网络结构_环境感知技术入门(十二) | 详细解读SSD目标检测框架
一、SSD整体网络结构
SSD 的网络结构如图1所示, 包含基础VGG结构、深度卷积层、边框特征提取网络、PriorBox 生成机制四部分;
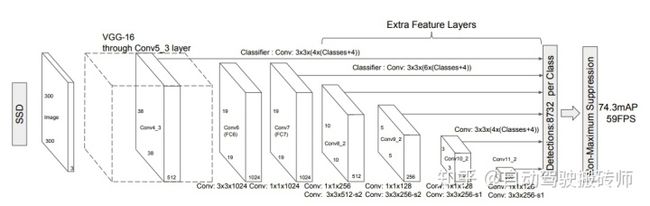
1.1 基础VGG结构

从图2最中我们可以清晰的看到在以VGG16做骨干网络时,在 conv5后丢弃了VGG16中的全连接层改为了1024×3×3和1024×1×1的卷积层。其中 conv4-1卷积层前面的 maxpooling层的 ceil_model=True,使得输出特征图长宽为 38 × 38。还有 conv5-3 后面的一层 maxpooling 层参数为(kernelsize=3,stride=1,padding=1),不进行下采样。然后在 fc7后面接上多尺度提取的另外 4 个卷积层就构成了完整的 SSD 网络。这里 VGG16 修改后的代码如下,来自 ssd.py:
# This function is derived from torchvision VGG make_layers()
# https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
# 调用
if __name__ == "__main__":
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
vgg = nn.Sequential(*vgg(base['300'], 3))1.2 深度卷积层
在VGG16基础上,SSD进一步增加4个深度卷积层(conv8 ~11)用于更高语意的特征提取, 从conv7到conv11卷积后的输出特征图尺寸依次为:19*19, 10*10, 5*5, 3*3, 1*1
# Extra layers added to VGG for feature scaling
def add_extras(cfg, i, batch_norm=False):
layers = []
in_channels = i
flag = False
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k + 1],
kernel_size=(1, 3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
return layers
# 调用
if __name__ == "__main__":
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
layers = add_extras(extras['300'], 1024)1.3 边框特征提取网络 Multi-box Layers
SSD一共有6层多尺度提取的网络(第4、7、8、9、10、11六个卷积层得到的特征图),每层分别对 loc 和 conf 进行卷积,得到相应的输出。
def multibox(vgg, extra_layers, cfg, num_classes):
loc_layers = []
conf_layers = []
vgg_source = [21, -2]
for k, v in enumerate(vgg_source):
loc_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * num_classes, kernel_size=3, padding=1)]
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, cfg[k] * num_classes, kernel_size=3, padding=1)]
return vgg, extra_layers, (loc_layers, conf_layers)
# 调用
if __name__ == "__main__":
mbox = {
'300': [4, 6, 6, 6, 4, 4], # number of boxes per feature map location
'512': [],
}
base_, extras_, head_ = multibox(vgg(base[str(size)], 3),
add_extras(extras[str(size)], 1024),
mbox[str(size)], num_classes)1.4 PriorBox 生成机制
(1)SSD从Conv4_3开始,一共提取了6个特征图,其大小分别为 (38,38), (19,19), (10,10), (5,5),(3,3), (1,1),但是每个特征图上设置的先验框数量不同。
(2)先验框的设置,包括尺度和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:
其中:
m指特征图个数,但是为5,因为第一层(Conv4_3)是单独设置的;
Sk表示先验框大小相对于图片的比例;
Smin和Smax表示比例的最小值与最大值,paper里面取0.2和0.9。补充说明:
先验框的长宽比一般设置为:
根据面积和长宽比可得先验框的宽度和高度:
默认情况下,每个特征图会有一个
每个单元的先验框的中心点分布在各个单元的中心,即:
class PriorBox(object):
"""
1、计算先验框,根据feature map的每个像素生成box;
2、框的中个数为: 38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732
3、 cfg: SSD的参数配置,字典类型
"""
def __init__(self, cfg):
super(PriorBox, self).__init__()
self.img_size = cfg['img_size']
self.feature_maps = cfg['feature_maps']
self.min_sizes = cfg['min_sizes']
self.max_sizes = cfg['max_sizes']
self.steps = cfg['steps']
self.aspect_ratios = cfg['aspect_ratios']
self.clip = cfg['clip']
self.version = cfg['name']
self.variance = cfg['variance']
def forward(self):
mean = [] #用来存放 box的参数
# 遍多尺度的 map: [38, 19, 10, 5, 3, 1]
for k, f in enumerate(self.feature_maps):
# 遍历每个像素
for i, j in product(range(f), repeat=2):
# k-th 层的feature map 大小
f_k = self.img_size/self.steps[k]
# 每个框的中心坐标
cx = (i+0.5)/f_k
cy = (j+0.5)/f_k
'''
当 ratio==1的时候,会产生两个 box
'''
# r==1, size = s_k, 正方形
s_k = self.min_sizes[k]/self.img_size
mean += [cx, cy, s_k, s_k]
# r==1, size = sqrt(s_k * s_(k+1)), 正方形
s_k_plus = self.max_sizes[k]/self.img_size
s_k_prime = sqrt(s_k * s_k_plus)
mean += [cx, cy, s_k_prime, s_k_prime]
'''
当 ratio != 1 的时候,产生的box为矩形
'''
for r in self.aspect_ratios[k]:
mean += [cx, cy, s_k * sqrt(r), s_k / sqrt(r)]
mean += [cx, cy, s_k / sqrt(r), s_k * sqrt(r)]
# 转化为 torch
boxes = torch.tensor(mean).view(-1, 4)
# 归一化,把输出设置在 [0,1]
if self.clip:
boxes.clamp_(max=1, min=0)
return boxes
# 调用
if __name__ == "__main__":
# SSD300 CONFIGS
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'img_size': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
box = PriorBox(voc)1.5 SSD整体网络结构
结合了前面介绍的魔改后的 VGG16,还有 Extra Layers,还有生成 Anchor 的 Priobox 策略,我们可以 写出 SSD 的整体结构如下(代码在 ssd.py):
class SSD(nn.Module):
"""Single Shot Multibox Architecture
The network is composed of a base VGG network followed by the
added multibox conv layers. Each multibox layer branches into
1) conv2d for class conf scores
2) conv2d for localization predictions
3) associated priorbox layer to produce default bounding
boxes specific to the layer's feature map size.
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
Args:
phase: (string) Can be "test" or "train"
size: input image size
base: VGG16 layers for input, size of either 300 or 500
extras: extra layers that feed to multibox loc and conf layers
head: "multibox head" consists of loc and conf conv layers
"""
def __init__(self, phase, size, base, extras, head, num_classes):
super(SSD, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.cfg = (coco, voc)[num_classes == 21]
self.priorbox = PriorBox(self.cfg)
self.priors = Variable(self.priorbox.forward(), volatile=True)
self.size = size
# SSD network
self.vgg = nn.ModuleList(base)
# Layer learns to scale the l2 normalized features from conv4_3
self.L2Norm = L2Norm(512, 20)
self.extras = nn.ModuleList(extras)
self.loc = nn.ModuleList(head[0])
self.conf = nn.ModuleList(head[1])
if phase == 'test':
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 0, 200, 0.01, 0.45)
def forward(self, x):
"""
Applies network layers and ops on input image(s) x.
Args:
x: input image or batch of images. Shape: [batch,3,300,300].
Return:
Depending on phase:
test:
Variable(tensor) of output class label predictions,
confidence score, and corresponding location predictions for
each object detected. Shape: [batch,topk,7]
train:
list of concat outputs from:
1: confidence layers, Shape: [batch, num_priors, num_classes]
2: localization layers, Shape: [batch, num_priors, 4]
3: priorbox layers, Shape: [num_priors, 4]
"""
sources = list()
loc = list()
conf = list()
# apply vgg up to conv4_3 relu
for k in range(23):
x = self.vgg[k](x)
s = self.L2Norm(x)
sources.append(s)
# apply vgg up to fc7
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)
# apply extra layers and cache source layer outputs
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
# apply multibox head to source layers
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # conf preds
self.priors.type(type(x.data)) # default boxes
)
else:
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
return output
def build_ssd(phase, size=300, num_classes=21):
if phase != "test" and phase != "train":
print("ERROR: Phase: " + phase + " not recognized")
return
if size != 300:
print("ERROR: You specified size " + repr(size) + ". However, " +
"currently only SSD300 (size=300) is supported!")
return
base_, extras_, head_ = multibox(vgg(base[str(size)], 3),
add_extras(extras[str(size)], 1024),
mbox[str(size)], num_classes)
return SSD(phase, size, base_, extras_, head_, num_classes)二、损失函数
整个损失函数:
其中:
N 是先验框的正样本数量;
c 为类别置信度预测值;
l 为先验框的所对应边界框的位置预测值;
g 为ground truth的位置参数。2.1 hard negative mining[1] 思想:
针对所有batch的confidence,按照置信度误差进行降序排列,取出前top_k个负样本。[2] 步骤:
- Reshape所有batch中的conf
batch_conf = conf_data.view(-1, self.num_classes) - 置信度误差越大,实际上就是预测背景的置信度越小,越表现为困难样本。
- 把所有conf进行logsoftmax处理(均为负值),预测的置信度越小,则logsoftmax越小,取绝对值,则
|logsoftmax|越大,降序排列-logsoftmax,取前top_k的负样本。
[3] 详细分析:
这里借用logsoftmax的思想:
为了防止数值溢出,可以把问题转化为:
上述变换的关键在于,我们引入了一个不牵涉log或exp函数的常数项c。
现在我们只需为 c 选择一个在所有情形下有效的良好的值,结果发现,
因此,可以把排序的函数定义为:
2.2 先验框匹配策略
两条原则:
(1) 对于图片中的每个 ground truth,找到和它 IOU 最大的先验框(IOU可能小于阈值0.5),该先验框与其匹配,这样可以保证每个 ground truth一定与某个 prior 匹配;
(2) 对于剩余的未匹配的先验框,若某个 ground truth 和它的 IOU 大于某个阈值 (一般设为 0.5),那么改 prior 和这个 ground truth,剩下没有匹配上的先验框都是负样本 (可能出现多个prior匹配同一个ground truth);
代码实现如下,来自 layers/box_utils.py:
def intersect(box_a, box_b):
"""
We resize both tensors to [A,B,2] without new malloc:
[A,2] -> [A,1,2] -> [A,B,2]
[B,2] -> [1,B,2] -> [A,B,2]
Then we compute the area of intersect between box_a and box_b. Args:
box_a: (tensor) bounding boxes, Shape: [A,4].
box_b: (tensor) bounding boxes, Shape: [B,4].
Return:
(tensor) intersection area, Shape: [A,B].
"""
A = box_a.size(0)
B = box_b.size(0)
# 右下角,选出最小值
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
# 左上角,选出最大值
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
# 负数用 0 截断,为 0 代表交集为 0
inter = torch.clamp((max_xy - min_xy), min=0)
return inter[:, :, 0] * inter[:, :, 1]
def jaccard(box_a, box_b):
"""
Compute the jaccard overlap of two sets of boxes. The jaccard overlap
is simply the intersection over union of two boxes. Here we operate on
ground truth boxes and default boxes.
E.g.:
A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
Args:
box_a: (tensor) Ground truth bounding boxes, Shape: [num_objects,4]
box_b: (tensor) Prior boxes from priorbox layers, Shape: [num_priors,4]
Return:
jaccard overlap: (tensor) Shape: [box_a.size(0), box_b.size(0)]
"""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2]-box_a[:, 0]) *
(box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2]-box_b[:, 0]) *
(box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
union = area_a + area_b - inter
# [A,B]
return inter / union
# 输入包括IoU阈值、真实边框位置、预选框、方差、真实边框类别
# 输出为每一个预选框的类别,保存在conf_t中,对应的真实边框位置,保存在loc_t中
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
"""Match each prior box with the ground truth box of the highest jaccard
overlap, encode the bounding boxes, then return the matched indices
corresponding to both confidence and location preds.
Args:
threshold: (float) The overlap threshold used when mathing boxes.
truths: (tensor) Ground truth boxes, Shape: [num_obj, 4].
priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
variances: (tensor) Variances corresponding to each prior coord,
Shape: [num_priors, 4].
labels: (tensor) All the class labels for the image, Shape: [num_obj].
loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
idx: (int) current batch index
Return:
The matched indices corresponding to 1)location and 2)confidence preds.
"""
# 注意这里truth是最大最小值形式的,而prior是中心点与长宽形式
# 求取真实框与预选框的IoU
overlaps = jaccard(
truths,
point_form(priors)
)
9
# (Bipartite Matching)
# [1, num_objects] best prior for each ground truth
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
# 将每一个真实框对应的最佳PriorBox的IoU设置为2
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
best_prior_idx.squeeze_(1)
best_prior_overlap.squeeze_(1)
# 将每一个truth对应的最佳box的overlap设置为2
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # ensure best prior
# TODO refactor: index best_prior_idx with long tensor
# ensure every gt matches with its prior of max overlap
# 保证每一个truth对应的最佳box,该box要对应到这个truth上,即使不是最大iou
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
# 每一个prior对应的真实框的位置
matches = truths[best_truth_idx] # Shape: [num_priors,4]
# 每一个prior对应的类别
conf = labels[best_truth_idx] + 1 # Shape: [num_priors]
# 如果一个PriorBox对应的最大IoU小于0.5,则视为负样本
conf[best_truth_overlap < threshold] = 0 # label as background
# 进一步计算定位的偏移真值
loc = encode(matches, priors, variances)
loc_t[idx] = loc # [num_priors,4] encoded offsets to learn
conf_t[idx] = conf # [num_priors] top class label for each prior2.3 损失函数完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from vgg_backbone import voc
from box_utils import match, log_sum_exp
class MultiBoxLoss(nn.Module):
def __init__(self, num_classes, overlap_thresh, neg_pos, use_gpu=False):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes
self.threshold = overlap_thresh
self.negpos_ratio = neg_pos
self.variance = voc['variance']
def forward(self, pred, targets):
'''
Args:
pred: A tuple, 包含 loc(编码钱的位置信息), conf(类别), priors(先验框);
loc_data: shape[b, M, 4];
conf_data: shape[b, M, num_classes];
priors: shape[M, 4];
targets: 真实的boxes和labels,shape[b, num_objs, 5];
'''
loc_data, conf_data, priors = pred
batch = loc_data.size(0) #batch
num_priors = priors[:loc_data.size(1), :].size(0) # 先验框个数
# 获取匹配每个prior box的 ground truth
# 创建 loc_t 和 conf_t 保存真实box的位置和类别
loc_t = torch.Tensor(batch, num_priors, 4)
conf_t = torch.LongTensor(batch, num_priors)
for idx in range(batch):
truths = targets[idx][:, :-1].detach() # ground truth box信息
labels = targets[idx][:, -1].detach() # ground truth conf信息
defaults = priors.detach() # priors的 box 信息
# 匹配 ground truth
match(self.threshold, truths, defaults,
self.variance, labels, loc_t, conf_t, idx)
# use gpu
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
pos = conf_t > 0 # 匹配中所有的正样本mask, shape[b, M]
# Localization Loss,使用 Smooth L1
# shape[b,M]-->shape[b,M,4]
pos_idx = pos.unsqueeze(2).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1,4) # 预测的正样本box信息
loc_t = loc_t[pos_idx].view(-1,4) # 真实的正样本box信息
loss_l = F.smooth_l1_loss(loc_p, loc_t) # Smooth L1 损失
'''
Target;
下面进行hard negative mining
过程:
1、 针对所有batch的conf,按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列;
2、 负样本的label全是背景,那么利用log softmax 计算出logP,
logP越大,则背景概率越低,误差越大;
3、 选取误差交大的top_k作为负样本,保证正负样本比例接近1:3;
'''
# shape[b*M, num_classes]
batch_conf = conf_data.view(-1, self.num_classes)
# 使用logsoftmax,计算置信度,shape[b*M, 1]
conf_logP = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# hard Negative Mining
conf_logP = conf_logP.view(batch, -1) # shape[b, M]
conf_logP[pos] = 0 # 把正样本排除,剩下的就全是负样本,可以进行抽样
# 两次sort排序,能够得到每个元素在降序排列中的位置idx_rank
_, index = conf_logP.sort(1, descending=True)
_, idx_rank = index.sort(1)
# 抽取负样本
# 每个batch中正样本的数目,shape[b,1]
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio * num_pos, max= pos.size(1)-1)
neg = idx_rank < num_neg # 抽取前top_k个负样本,shape[b, M]
# shape[b,M] --> shape[b, M, num_classes]
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
# 提取出所有筛选好的正负样本(预测的和真实的)
conf_p = conf_data[(pos_idx + neg_idx).gt(0)].view(-1, self.num_classes)
conf_target = conf_t[(pos + neg).gt(0)]
# 计算conf交叉熵
loss_c = F.cross_entropy(conf_p, conf_target)
# 正样本个数
N = num_pos.detach().sum().float()
loss_l /= N
loss_c /= N
return loss_l, loss_c
# 调试代码使用
if __name__ == "__main__":
loss = MultiBoxLoss(21, 0.5, 3)
p = (torch.randn(1,100,4), torch.randn(1,100,21), torch.randn(100,4))
t = torch.randn(1, 10, 4)
tt = torch.randint(20, (1,10,1))
t = torch.cat((t,tt.float()), dim=2)
l, c = loss(p, t)
# 随机randn,会导致g_wh出现负数,此时结果会变成 nan
print('loc loss:', l)
print('conf loss:', c)三、 L2 正则化
VGG16的conv4_3 特征图的大小为38×38,网络层靠前,方差比较大需要加一个 L2 标准化,以保证和后面的检测层差异不是很大。L2标准化的公式如下:
同时,这里还要注意的是如果简单的对一个layer的输入进行L2标准化就会改变该层的规模,并且会减慢学习速度,因此这里引入了一个缩放系数
class L2Norm(nn.Module):
def __init__(self,n_channels, scale):
super(L2Norm,self).__init__()
self.n_channels = n_channels
self.gamma = scale or None
self.eps = 1e-10
# 将一个不可训练的类型 Tensor 转换成可以训练的类型 parameter
self.weight = nn.Parameter(torch.Tensor(self.n_channels))
self.reset_parameters()
def reset_parameters(self):
init.constant_(self.weight, self.gamma)
def forward(self, x):
norm = x.pow(2).sum(dim=1, keepdim=True).sqrt() + self.eps
x = torch.div(x, norm)
out = self.weight.unsqueeze(0).unsqueeze(2).unsqueeze(3).expand_as(x) * x
return out
# 代码测试
if __name__ == "__main__":
x = torch.randn(1, 512, 38, 38)
l2norm = L2Norm(512, 20)
out = l2norm(x)
print('L2 norm :', out.shape)
'''
输出:
L2 norm : torch.Size([1, 512, 38, 38])
'''四、位置信息编解码
预测和真实的边界框是有一个转换关系的,具体如下:
- 先验框位置
- 真实框位置
-
用于调整检测值
4.1 编码
得到预测框相对于default box的偏移量
def encode(matched, priors, variances):
'''
将来至于priorbox的差异编码到ground truth box中
Args:
matched: 每个prior box 所匹配的ground truth,
Shape[M, 4],坐标(xmin, ymin, xmax, ymax)
priors: 先验框box, shape[M, 4],坐标(cx, cy, w, h)
variances: 方差,list(float)
'''
# 编码中心坐标cx, cy
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]
# shape[M,2]
g_cxcy /= (priors[:, 2:] * variances[0])
# 防止出现log出现负数,从而使loss为 nan
eps = 1e-5
# 编码宽高w, h
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
# shape[M,2]
g_wh = torch.log(g_wh + eps) / variances[1]
# shape[M,4]
return torch.cat([g_cxcy, g_wh], 1) 4.2 解码
从预测值
def decode(loc, priors, variances):
'''
对应encode,解码预测的位置信息
'''
boxes = torch.cat((priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
# 转化坐标为 (xmin, ymin, xmax, ymax)类型
boxes = point_form(boxes)
return boxes四、非极大值抑制(NMS)
NMS算法一般是为了去掉模型预测后的多余框,其一般设有一个nms_threshold=0.5,具体的实现思路如下:
- 选取这类box中scores最大的哪一个,它的index记为
,并保留它;
- 计算
boxes[i]与其余的boxes的IOU值; - 如果其
IOU>0.5了,那么就舍弃这个box(由于可能这两个box表示同一目标,所以保留分数高的哪一个) - 从最后剩余的boxes中,再找出最大scores的哪一个,如此循环往复
def nms(boxes, scores, threshold=0.5, top_k=200):
'''
Args:
boxes: 预测出的box, shape[M, 4]
scores: 预测出的置信度,shape[M]
threshold: 阈值
top_k: 要考虑的box的最大个数
Return:
keep: nms筛选后的box的新的index数组
count: 保留下来box的个数
'''
keep = scores.new(scores.size(0)).zero_().long()
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = (x2-x1)*(y2-y1) # 面积,shape[M]
_, idx = scores.sort(0, descending=True) # 降序排列scores的值大小
# 取前top_k个进行nms
idx = idx[:top_k]
count = 0
while idx.numel():
# 记录最大score值的index
i = idx[0]
# 保存到keep中
keep[count] = i
# keep 的序号
count += 1
if idx.size(0) == 1: # 保留框只剩一个
break idx = idx[1:] # 移除已经保存
的index
# 计算boxes[i]和其他boxes之间的iou
xx1 = x1[idx].clamp(min=x1[i])
yy1 = y1[idx].clamp(min=y1[i])
xx2 = x2[idx].clamp(max=x2[i])
yy2 = y2[idx].clamp(max=y2[i])
w = (xx2 - xx1).clamp(min=0)
h = (yy2 - yy1).clamp(min=0)
# 交集的面积
inter = w * h # shape[M-1]
iou = inter / (area[i] + area[idx] - inter)
# iou满足条件的idx
idx = idx[iou.le(threshold)] # Shape[M-1]
return keep, count五、Detection函数
模型进行测试的时候,需要把预测出的loc和conf输入到detect函数进行nms,最后给出相应的结果。
class Detect(Function):
def __init__(self, num_classes, top_k, conf_thresh, nms_thresh):
self.num_classes = num_classes
self.top_k = top_k
self.conf_thresh = conf_thresh
self.nms_thresh = nms_thresh
self.variance = cfg['variance']
def forward(self, loc_data, conf_data, prior_data):
'''
Args:
loc_data: 预测出的loc张量,shape[b,M,4], eg:[b, 8732, 4]
conf_data: 预测出的置信度,shape[b,M,num_classes], eg:[b, 8732, 21]
prior_data: 先验框,shape[M,4], eg:[8732, 4]
'''
batch = loc_data.size(0) # batch size
output = torch.zeros(batch, self.num_classes, self.top_k, 5) # 初始化输出
conf_preds = conf_data.transpose(2,1)
# 解码loc的信息,变为正常的bboxes
for i in range(batch):
# 解码loc
decode_boxes = decode(loc_data[i], prior_data, self.variance)
# 拷贝每个batch内的conf,用于nms
conf_scores = conf_preds[i].clone()
# 遍历每一个类别
for num in range(1, self.num_classes):
# 筛选掉 conf < conf_thresh 的conf
c_mask = conf_scores[num].gt(self.conf_thresh)
scores = conf_scores[num][c_mask]
# 如果都被筛掉了,则跳入下一类
if scores.size(0) == 0:
continue
# 筛选掉 conf < conf_thresh 的框
l_mask = c_mask.unsqueeze(1).expand_as(decode_boxes)
boxes = decode_boxes[l_mask].view(-1, 4)
# nms
ids, count = nms(boxes, scores, self.nms_thresh, self.top_k)
# nms 后得到的输出拼接
output[i, num, :count] = torch.cat((
scores[ids[:count]].unsqueeze(1),
boxes[ids[:count]]), 1)
return output
# 代码测试
if __name__ == "__main__":
detect = Detect(21, 200, 0.01, 0.5)
loc_data = torch.randn(1,8732,4)
conf_data = torch.randn(1,8732,21)
prior_data = torch.randn(8732, 4)
out = detect(loc_data, conf_data, prior_data)
print('Detect output shape:', out.shape)