大数据课程综合实验案例:网站用户行为分析
大数据课程综合实验案例
-
- 1 案例简介
-
- 1.1 案例目的
- 1.2 适用对象
- 1.3 时间安排
- 1.4 预备知识
- 1.5 硬件要求
- 1.6 软件工具
- 1.7 数据集
- 1.8 案例任务
- 1.9 实验步骤
- 2 本地数据上传到数据仓库Hive
-
- 2.1 实验数据集的下载
- 2.2 数据集的预处理
-
- (1)删除文件第一行记录,即字段名称
- (2)对字段进行预处理
- (3)导入数据库
- 3 Hive数据分析
-
- 3.1 操作Hive
- 3.2 简单查询分析
- 3.3 查询条数统计分析
- 3.4 关键字条件查询分析
-
- 3.4.1 以关键字的存在区间为条件的查询
- 3.4.2 关键字赋予给定值为条件,对其他数据进行分析
- 3.5 根据用户行为分析
-
- 3.5.1 查询一件商品在某天的购买比例或浏览比例
- 3.5.2 查询某个用户在某一天点击网站占该天所有点击行为的比例(点击行为包括浏览,加入购物车,收藏,购买)
- 3.5.3 给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id
- 3.6 用户实时查询分析
- 4 Hive、MySQL、HBase数据互导
-
- 4.1 准备工作
- 4.2 使用Java API将数据从Hive导入MySQL
- 4.3 查看MySQL中user_action表数据
- 4.4 使用HBase Java API把数据从本地导入HBase中
-
- 4.4.1 启动Hadoop集群、HBase服务
- 4.4.2 数据准备
- 4.4.3 编写数据导入程序
- 4.4.4 数据导入
- 5 利用R进行数据可视化分析
-
- 5.1 安装R
- 5.2 可视化分析
1 案例简介
大数据课程实验案例:网站用户行为分析,由厦门大学数据库实验室团队开发,旨在满足全国高校大数据教学对实验案例的迫切需求。本案例涉及数据预处理、存储、查询和可视化分析等数据处理全流程所涉及的各种典型操作,涵盖Linux、MySQL、Hadoop、HBase、Hive、Sqoop、R、Eclipse等系统和软件的安装和使用方法。案例适合高校(高职)大数据教学,可以作为学生学习大数据课程后的综合实践案例。通过本案例,将有助于学生综合运用大数据课程知识以及各种工具软件,实现数据全流程操作。各个高校可以根据自己教学实际需求,对本案例进行补充完善。
1.1 案例目的
熟悉Linux系统、MySQL、Hadoop、HBase、Hive、Sqoop、R、Eclipse等系统和软件的安装和使用;
了解大数据处理的基本流程;
熟悉数据预处理方法;
熟悉在不同类型数据库之间进行数据相互导入导出;
熟悉使用R语言进行可视化分析;
熟悉使用Elipse编写Java程序操作HBase数据库。
1.2 适用对象
高校(高职)教师、学生
大数据学习者
1.3 时间安排
本案例可以作为大数据入门级课程结束后的“大作业”,或者可以作为学生暑期或寒假大数据实习实践基础案例,完成本案例预计耗时7天。
1.4 预备知识
需要案例使用者,已经学习过大数据相关课程(比如入门级课程《大数据技术原理与应用》),了解大数据相关技术的基本概念与原理,了解Windows操作系统、Linux操作系统、大数据处理架构Hadoop的关键技术及其基本原理、列族数据库HBase概念及其原理、数据仓库概念与原理、关系型数据库概念与原理、R语言概念与应用。
不过,由于本案例提供了全部操作细节,包括每个命令和运行结果,所以,即使没有相关背景知识,也可以按照操作说明顺利完成全部实验。
1.5 硬件要求
本案例在集群环境下完成。
1.6 软件工具
本案例所涉及的系统及软件
Linux系统(Ubuntu16.04或14.04或18.04)
MySQL(版本无要求)
Hadoop(3.0以上版本)
HBase(1.1.2或1.1.5,HBase版本需要和Hadoop版本兼容)
Hive(1.2.1,Hive需要和Hadoop版本兼容,不要安装Hive3.0以上版本)
R(版本无要求)
Eclipse(版本无要求)
不需要Sqoop,因为Sqoop无法支持Hadoop3.0以上版本
1.7 数据集
网站用户购物行为数据集2000万条记录。
1.8 案例任务
安装Linux操作系统
安装关系型数据库MySQL
安装大数据处理框架Hadoop
安装列族数据库HBase
安装数据仓库Hive
安装Sqoop
安装R
安装Eclipse
对文本文件形式的原始数据集进行预处理
把文本文件的数据集导入到数据仓库Hive中
对数据仓库Hive中的数据进行查询分析
使用Java API将数据从Hive导入MySQL
使用Java API将数据从MySQL导入HBase
使用HBase Java API把数据从本地导入到HBase中
使用R对MySQL中的数据进行可视化分析
1.9 实验步骤
步骤零:实验环境准备
步骤一:本地数据集上传到数据仓库Hive
步骤二:Hive数据分析
步骤三:Hive、MySQL、HBase数据互导
步骤四:利用R进行数据可视化分析
2 本地数据上传到数据仓库Hive
本节介绍数据集的下载、数据集的预处理和导入数据库。
2.1 实验数据集的下载
本案例采用的数据集为user.zip,包含了一个大规模数据集raw_user.csv(包含2000万条记录),和一个小数据集small_user.csv(只包含30万条记录)。小数据集small_user.csv是从大规模数据集raw_user.csv中抽取的一小部分数据。之所以抽取出一少部分记录单独构成一个小数据集,是因为,在第一遍跑通整个实验流程时,会遇到各种错误,各种问题,先用小数据集测试,可以大量节约程序运行时间。等到第一次完整实验流程都顺利跑通以后,就可以最后用大规模数据集进行最后的测试。
在个人电脑中打开百度云网盘页面进行数据集的下载:https://pan.baidu.com/s/1nuOSo7B 。在个人电脑终端使用scp将个人电脑中的数据集上传到服务器/home/hadoop/Download路径。

下面需要把user.zip进行解压缩,我们需要首先建立一个用于运行本案例的目录bigdatacase,请执行以下命令:
sudo mkdir bigdatacase
//这里会提示你输入当前用户(本教程是hadoop用户名)的密码
//下面给hadoop用户赋予针对bigdatacase目录的各种操作权限
sudo chown -R hadoop:hadoop ./bigdatacase
cd bigdatacase
//下面创建一个dataset目录,用于保存数据集
mkdir dataset

//下面就可以解压缩user.zip文件
cd ~/Download
unzip user.zip -d /usr/local/bigdatacase/dataset
cd /usr/local/bigdatacase/dataset
ls

现在你就可以看到在dataset目录下有两个文件:raw_user.csv和small_user.csv。

我们执行下面命令取出前面5条记录看一下:

可以看出,每行记录都包含5个字段,数据集中的字段及其含义如下:
user_id(用户id)
item_id(商品id)
behaviour_type(包括浏览、收藏、加购物车、购买,对应取值分别是1、2、3、4)
user_geohash(用户地理位置哈希值,有些记录中没有这个字段值,所以后面我们会用脚本做数据预处理时把这个字段全部删除)
item_category(商品分类)
time(该记录产生时间)
2.2 数据集的预处理
(1)删除文件第一行记录,即字段名称
raw_user和small_user中的第一行都是字段名称,我们在文件中的数据导入到数据仓库Hive中时,不需要第一行字段名称,因此,这里在做数据预处理时,删除第一行。
cd /usr/local/bigdatacase/dataset
//下面删除raw_user中的第1行
sed -i '1d' raw_user.csv //1d表示删除第1行,同理,3d表示删除第3行,nd表示删除第n行
//下面删除small_user中的第1行
sed -i '1d' small_user.csv
//下面再用head命令去查看文件的前5行记录,就看不到字段名称这一行了
head -5 raw_user.csv
head -5 small_user.csv

(2)对字段进行预处理
下面对数据集进行一些预处理,包括为每行记录增加一个id字段(让记录具有唯一性)、增加一个省份字段(用来后续进行可视化分析),并且丢弃user_geohash字段(后面分析不需要这个字段)。
下面我们要建一个脚本文件pre_deal.sh,请把这个脚本文件放在dataset目录下,和数据集small_user.csv放在同一个目录下:
cd /usr/local/bigdatacase/dataset
vim pre_deal.sh
上面使用vim编辑器新建了一个pre_deal.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行pre_deal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行pre_deal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
srand();
id=0;
Province[0]="山东";Province[1]="山西";Province[2]="河南";Province[3]="河北";Province[4]="陕西";Province[5]="内蒙古";Province[6]="上海市";
Province[7]="北京市";Province[8]="重庆市";Province[9]="天津市";Province[10]="福建";Province[11]="广东";Province[12]="广西";Province[13]="云南";
Province[14]="浙江";Province[15]="贵州";Province[16]="新疆";Province[17]="西藏";Province[18]="江西";Province[19]="湖南";Province[20]="湖北";
Province[21]="黑龙江";Province[22]="吉林";Province[23]="辽宁"; Province[24]="江苏";Province[25]="甘肃";Province[26]="青海";Province[27]="四川";
Province[28]="安徽"; Province[29]="宁夏";Province[30]="海南";Province[31]="香港";Province[32]="澳门";Province[33]="台湾";
}
{
id=id+1;
value=int(rand()*34);
print id"\t"$1"\t"$2"\t"$3"\t"$5"\t"substr($6,1,10)"\t"Province[value]
}' $infile > $outfile

使用awk可以逐行读取输入文件,并对逐行进行相应操作。其中,-F参数用于指出每行记录的不同字段之间用什么字符进行分割,这里是用逗号进行分割。处理逻辑代码需要用两个英文单引号引起来。 $infile是输入文件的名称,我们这里会输入raw_user.csv,$outfile表示处理结束后输出的文件名称,我们后面会使用user_table.txt作为输出文件名称。
在上面的pre_deal.sh代码的处理逻辑部分,srand()用于生成随机数的种子,id是我们为数据集新增的一个字段,它是一个自增类型,每条记录增加1,这样可以保证每条记录具有唯一性。我们会为数据集新增一个省份字段,用来进行后面的数据可视化分析,为了给每条记录增加一个省份字段的值,这里,我们首先用Province[]数组用来保存全国各个省份信息,然后,在遍历数据集raw_user.csv的时候,每当遍历到其中一条记录,使用value=int(rand()*34)语句随机生成一个0-33的整数,作为Province省份值,然后从Province[]数组当中获取省份名称,增加到该条记录中。
substr($6,1,10)这个语句是为了截取时间字段time的年月日,方便后续存储为date格式。awk每次遍历到一条记录时,每条记录包含了6个字段,其中,第6个字段是时间字段,substr($6,1,10)语句就表示获取第6个字段的值,截取前10个字符,第6个字段是类似”2014-12-08 18″这样的字符串(也就是表示2014年12月8日18时),substr($6,1,10)截取后,就丢弃了小时,只保留了年月日。
另外,在
print id”\t”\$1″\t”\$2″\t”\$3″\t”\$5″\t”substr(\$6,1,10)”\t”Province[value]
这行语句中,我们丢弃了每行记录的第4个字段,所以,没有出现$4。我们生成后的文件是“\t”进行分割,这样,后续我们去查看数据的时候,效果让人看上去更舒服,每个字段在排版的时候会对齐显示,如果用逗号分隔,显示效果就比较乱。
最后,保存pre_deal.sh代码文件,退出vim编辑器。
下面就可以执行pre_deal.sh脚本文件,来对raw_user.csv进行数据预处理,命令如下:
cd /usr/local/bigdatacase/dataset
bash ./pre_deal.sh small_user.csv user_table.txt
可以使用head命令查看生成的user_table.txt,不要直接打开,文件过大,会出错,下面查看前10行数据:
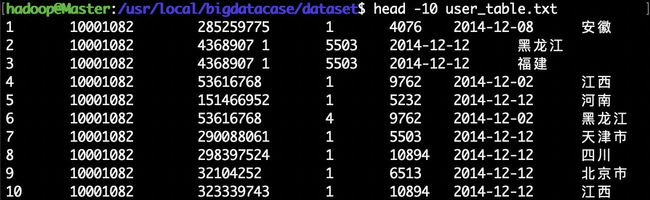
(3)导入数据库
下面要把user_table.txt中的数据最终导入到数据仓库Hive中。为了完成这个操作,我们会首先把user_table.txt上传到分布式文件系统HDFS中,然后,在Hive中创建一个外部表,完成数据的导入。
- a.启动HDFS
HDFS是Hadoop的核心组件,因此,需要使用HDFS,必须安装Hadoop。这里假设你已经安装了Hadoop,安装目录是“/usr/local/hadoop”。
下面,请登录Linux系统,打开一个终端,执行下面命令启动Hadoop:
cd /usr/local/hadoop
./sbin/start-all.sh
然后,执行jps命令看一下当前运行的进程:

说明hadoop启动成功。
- b.把user_table.txt上传到HDFS中
现在,我们要把Linux本地文件系统中的user_table.txt上传到分布式文件系统HDFS中,存放在HDFS中的“/bigdatacase/dataset”目录下。
首先,请执行下面命令,在HDFS的根目录下面创建一个新的目录bigdatacase,并在这个目录下创建一个子目录dataset,如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /bigdatacase/dataset
然后,把Linux本地文件系统中的user_table.txt上传到分布式文件系统HDFS的“/bigdatacase/dataset”目录下,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -put /usr/local/bigdatacase/dataset/user_table.txt /bigdatacase/dataset
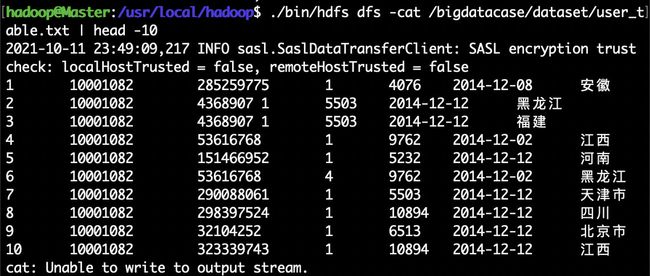
下面可以查看一下HDFS中的user_table.txt的前10条记录,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -cat /bigdatacase/dataset/user_table.txt | head -10
- c.在Hive上创建数据库
这里假设你已经完成了Hive的安装,并且使用MySQL数据库保存Hive的元数据。本教程安装的是Hive2.1.0版本,安装目录是“/usr/local/hive”。
下面,请在Linux系统中,再新建一个终端。因为需要借助于MySQL保存Hive的元数据,所以,请首先启动MySQL数据库:
sudo service mysql start //可以在Linux的任何目录下执行该命令
由于Hive是基于Hadoop的数据仓库,使用HiveQL语言撰写的查询语句,最终都会被Hive自动解析成MapReduce任务由Hadoop去具体执行,因此,需要启动Hadoop,然后再启动Hive。由于前面我们已经启动了Hadoop,所以,这里不需要再次启动Hadoop。下面,在这个新的终端中执行下面命令进入Hive:
cd /usr/local/hive
./bin/hive //启动Hive
下面,我们要在Hive中创建一个数据库dblab,命令如下:
hive> create database dblab;
hive> use dblab;
- d.创建外部表
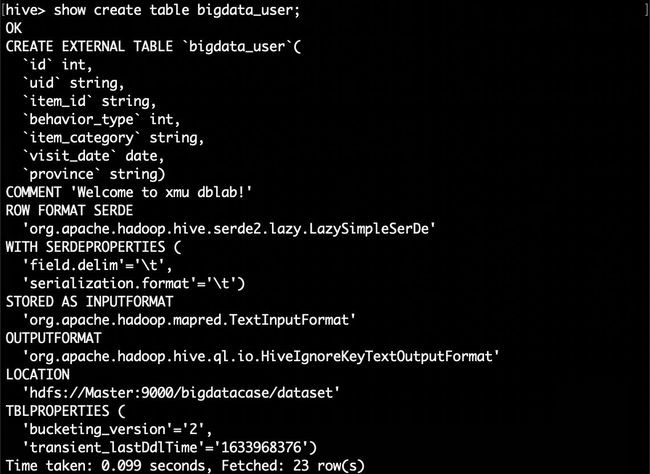
这里我们要在数据库dblab中创建一个外部表bigdata_user,它包含字段(id, uid, item_id, behavior_type, item_category, date, province),请在hive命令提示符下输入如下命令:
hive> CREATE EXTERNAL TABLE dblab.bigdata_user(id INT,uid STRING,item_id STRING,behavior_type INT,item_category STRING,visit_date DATE,province STRING) COMMENT 'Welcome to xmu dblab!' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/bigdatacase/dataset';
- e.查询数据
上面已经成功把HDFS中的“/bigdatacase/dataset”目录下的数据加载到了数据仓库Hive中,我们现在可以使用下面命令查询一下:
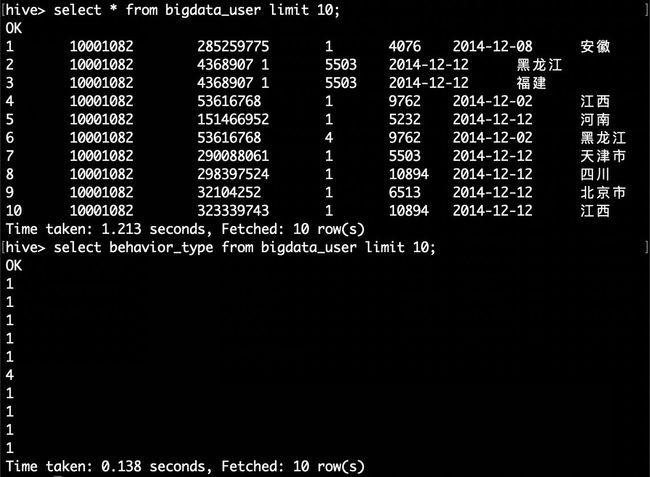
hive> select * from bigdata_user limit 10;
hive> select behavior_type from bigdata_user limit 10;
3 Hive数据分析
3.1 操作Hive
在“hive>”命令提示符状态下执行下面命令:
hive> use dblab; //使用dblab数据库
hive> show tables; //显示数据库中所有表。
hive> show create table bigdata_user; //查看bigdata_user表的各种属性;
执行结果如下:

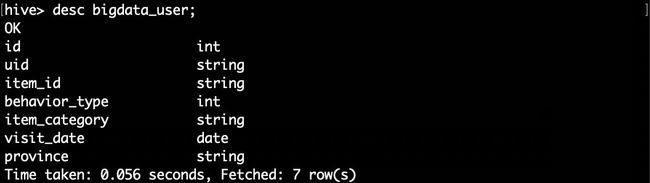
可以执行下面命令查看表的简单结构:
hive> desc bigdata_user;
3.2 简单查询分析
先测试一下简单的指令:
hive> select behavior_type from bigdata_user limit 10;//查看前10位用户对商品的行为

如果要查出每位用户购买商品时的多种信息,输出语句格式为 select 列1,列2,….,列n from 表名;
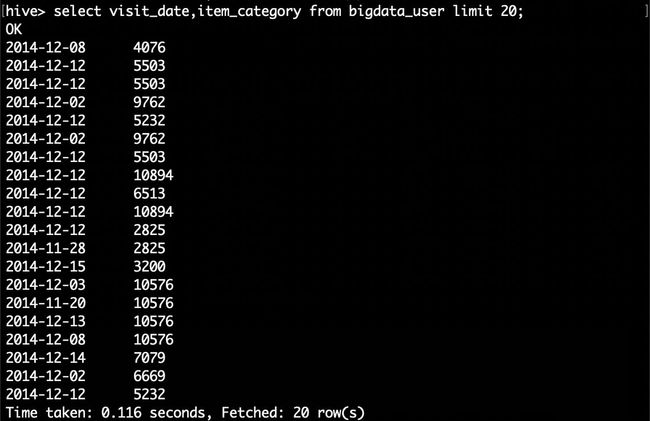
比如我们现在查询前20位用户购买商品时的时间和商品的种类
hive> select visit_date,item_category from bigdata_user limit 20;
有时我们在表中查询可以利用嵌套语句,如果列名太复杂可以设置该列的别名,以简化我们操作的难度,以下我们可以举个例子:
hive> select e.bh, e.it from (select behavior_type as bh, item_category as it from bigdata_user) as e limit 20;
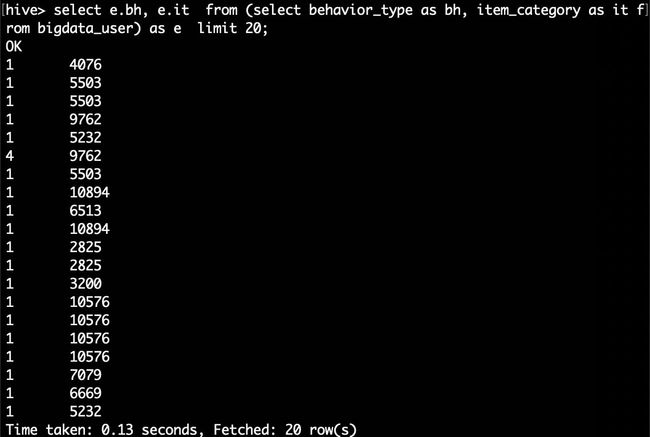
这里简单的做个讲解,behavior_type as bh ,item_category as it就是把behavior_type 设置别名 bh ,item_category 设置别名 it,FROM的括号里的内容我们也设置了别名e,这样调用时用e.bh,e.it,可以简化代码。
3.3 查询条数统计分析
经过简单的查询后我们同样也可以在select后加入更多的条件对表进行查询,下面可以用函数来查找我们想要的内容。
(1)用聚合函数count()计算出表内有多少条行数据
hive> select count(*) from bigdata_user;//用聚合函数count()计算出表内有多少条行数据
(2)在函数内部加上distinct,查出uid不重复的数据有多少条
下面继续执行操作:
hive> select count(distinct uid) from bigdata_user;//在函数内部加上distinct,查出uid不重复的数据有多少条
(3)查询不重复的数据有多少条(为了排除客户刷单情况)
hive>select count(*) from (select uid,item_id,behavior_type,item_category,visit_date,province from bigdata_user group by uid,item_id,behavior_type,item_category,visit_date,province having count(*)=1)a;
3.4 关键字条件查询分析
3.4.1 以关键字的存在区间为条件的查询
使用where可以缩小查询分析的范围和精确度,下面用实例来测试一下。
(1)查询2014年12月10日到2014年12月13日有多少人浏览了商品
hive>select count(*) from bigdata_user where behavior_type='1' and visit_date<'2014-12-13' and visit_date>'2014-12-10';
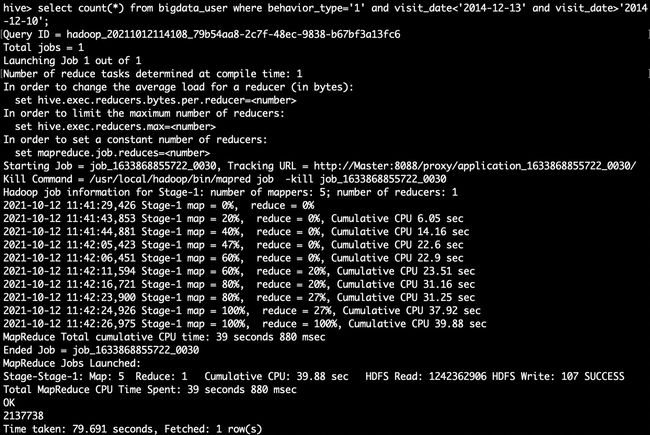
(2)以月的第n天为统计单位,依次显示第n天网站卖出去的商品的个数
hive> select count(distinct uid), day(visit_date) from bigdata_user where behavior_type='4' group by day(visit_date);
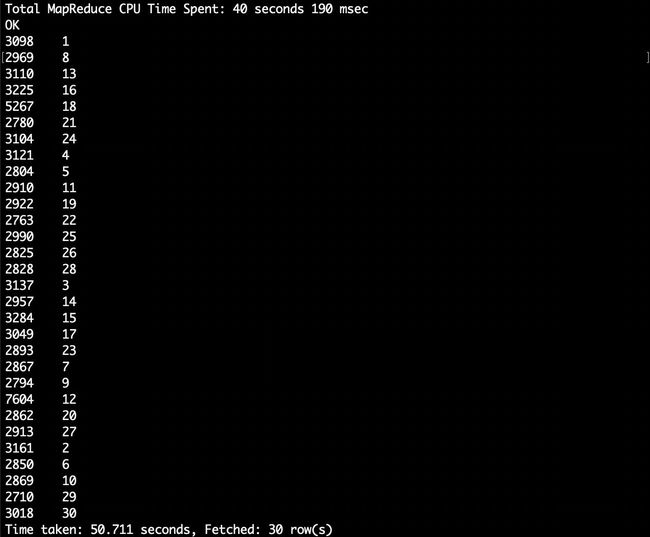
3.4.2 关键字赋予给定值为条件,对其他数据进行分析
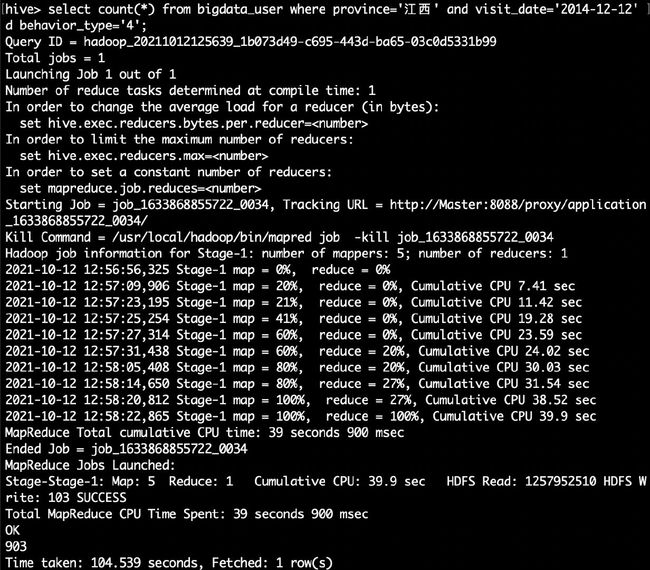
取给定时间和给定地点,求当天发出到该地点的货物的数量
hive> select count(*) from bigdata_user where province='江西' and visit_date='2014-12-12' and behavior_type='4';
3.5 根据用户行为分析
原始数据集过大,一下实验均使用small_dataset。
3.5.1 查询一件商品在某天的购买比例或浏览比例
hive> select count(*) from bigdata_user where visit_date='2014-12-11'and behavior_type='4';//查询有多少用户在2014-12-11购买了商品
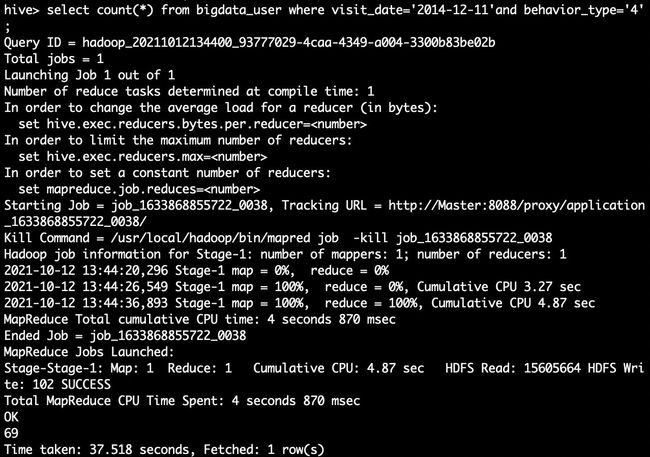
hive> select count(*) from bigdata_user where visit_date ='2014-12-11';//查询有多少用户在2014-12-11点击了该店

根据上面语句得到购买数量和点击数量,两个数相除即可得出当天该商品的购买率。
3.5.2 查询某个用户在某一天点击网站占该天所有点击行为的比例(点击行为包括浏览,加入购物车,收藏,购买)
hive> select count(*) from bigdata_user where uid=10001082 and visit_date='2014-12-12';//查询用户10001082在2014-12-12点击网站的次数
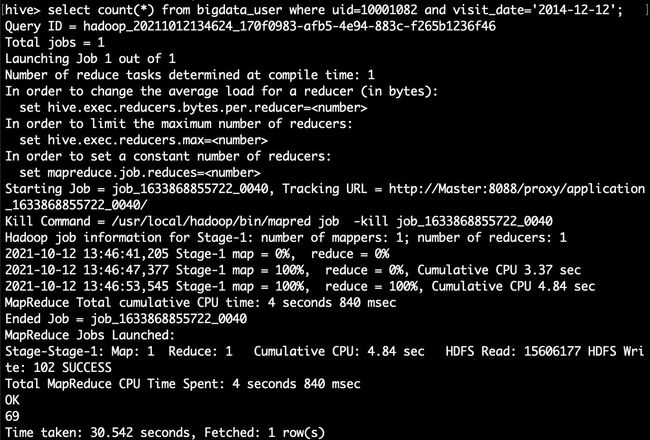
hive> select count(*) from bigdata_user where visit_date='2014-12-12';//查询所有用户在这一天点击该网站的次数
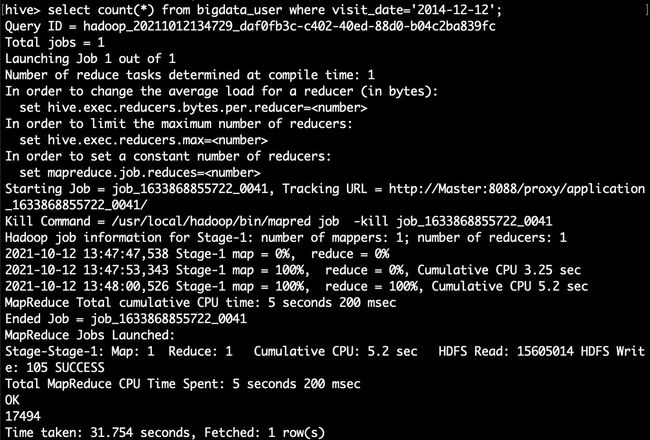
上面两条语句的结果相除,就得到了要要求的比例。
3.5.3 给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id
hive> select uid from bigdata_user where behavior_type='4' and visit_date='2014-12-12' group by uid having count(behavior_type='4')>5;//查询某一天在该网站购买商品超过5次的用户id
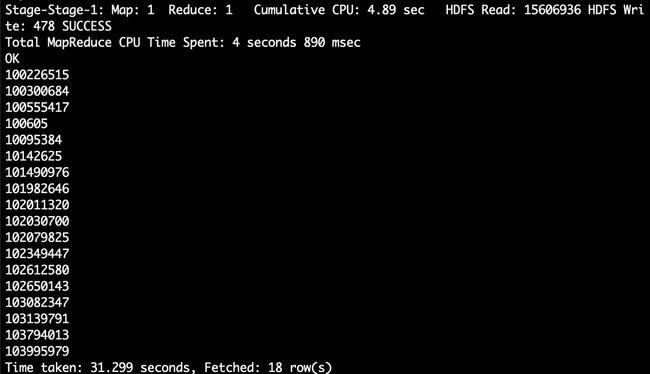
3.6 用户实时查询分析
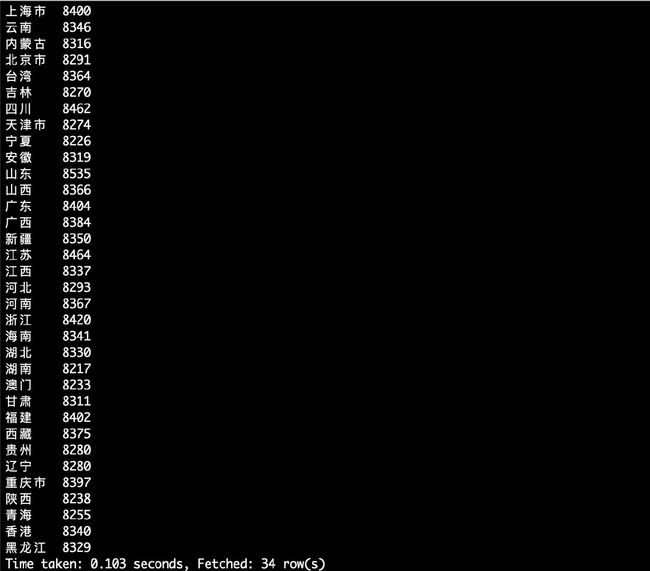
某个地区的用户当天浏览网站的次数
hive> create table scan(province STRING,scan INT) COMMENT 'This is the search of bigdataday' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;//创建新的数据表进行存储
hive> insert overwrite table scan select province,count(behavior_type) from bigdata_user where behavior_type='1' group by province;//导入数据
hive> select * from scan;//显示结果
4 Hive、MySQL、HBase数据互导
4.1 准备工作
本教程需要安装Hive、MySQL、HBase。在前面的第一个步骤中,我们在安装Hive的时候就已经一起安装了MySQL(因为我们采用MySQL来存储Hive的元数据),所以,现在你只需要再安装HBase。
Hive预操作
如果你还没有启动Hive,请首先启动Hive。
请登录Linux系统(本教程统一采用hadoop用户名登录系统),然后,打开一个终端。
本教程中,Hadoop的安装目录是“/usr/local/hadoop”,Hive的安装目录是“/usr/local/hive”。
因为需要借助于MySQL保存Hive的元数据,所以,请首先启动MySQL数据库,请在终端中输入下面命令:
service mysql start //可以在Linux的任何目录下执行该命令
由于Hive是基于Hadoop的数据仓库,使用HiveQL语言撰写的查询语句,最终都会被Hive自动解析成MapReduce任务由Hadoop去具体执行,因此,需要启动Hadoop,然后再启动Hive。
下面,继续执行下面命令启动进入Hive:
cd /usr/local/hive
./bin/hive //启动Hive
然后,在“hive>”命令提示符状态下执行下面命令:
1、创建临时表user_action
hive> create table dblab.user_action(id STRING,uid STRING, item_id STRING, behavior_type STRING, item_category STRING, visit_date DATE, province STRING) COMMENT 'Welcome to XMU dblab! ' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
这个命令执行完以后,Hive会自动在HDFS文件系统中创建对应的数据文件。

2、将bigdata_user表中的数据插入到user_action(执行时间:10秒左右)
在第二个步骤——Hive数据分析中,我们已经在Hive中的dblab数据库中创建了一个外部表bigdata_user。下面把dblab.bigdata_user数据插入到dblab.user_action表中,命令如下:
hive> INSERT OVERWRITE TABLE dblab.user_action select * from dblab.bigdata_user;
请执行下面命令查询上面的插入命令是否成功执行:
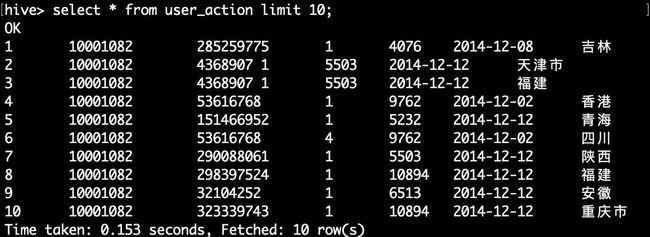
hive>select * from user_action limit 10;
4.2 使用Java API将数据从Hive导入MySQL
1、启动Hadoop集群、MySQL服务
前面我们已经启动了Hadoop集群和MySQL服务。这里请确认已经按照前面操作启动成功。
2、将前面生成的临时表数据从Hive导入到 MySQL 中,包含如下四个步骤。
(1)登录 MySQL
请在Linux系统中新建一个终端,执行下面命令:
sudo mysql –u root –p
为了简化操作,本教程直接使用root用户登录MySQL数据库,但是,在实际应用中,建议在MySQL中再另外创建一个用户。
执行上面命令以后,就进入了“mysql>”命令提示符状态。
(2)创建数据库
mysql> show databases; #显示所有数据库
mysql> create database dblab; #创建dblab数据库
mysql> use dblab; #使用数据库

请使用下面命令查看数据库的编码:
mysql>show variables like "char%";
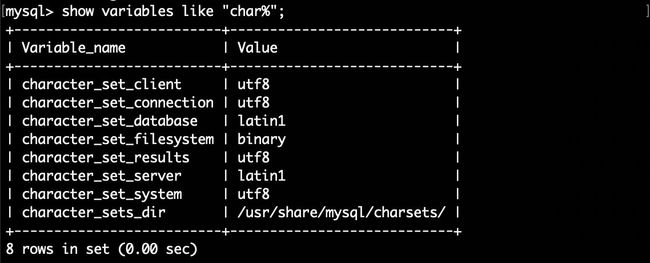
请确认当前编码为utf8,否则无法导入中文,请参考Ubuntu安装MySQL及常用操作修改编码http://dblab.xmu.edu.cn/blog/install-mysql/ 。
下面是笔者电脑上修改了编码格式后的结果:

(3)创建表
下面在MySQL的数据库dblab中创建一个新表user_action,并设置其编码为utf-8:
mysql> CREATE TABLE `dblab`.`user_action` (`id` varchar(50),`uid` varchar(50),`item_id` varchar(50),`behavior_type` varchar(10),`item_category` varchar(50), `visit_date` DATE,`province` varchar(20)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
创建成功后,输入下面命令退出MySQL:
mysql> exit
(4)导入数据(执行时间:20秒左右)
通过JDBC连接Hive和MySQL ,将数据从Hive导入MySQL。通过JDBC连接Hive,需要通过Hive的thrift服务实现跨语言访问Hive,实现thrift服务需要开启hiveserver2。
在Hadoop的配置文件core-site.xml中添加以下配置信息:(目录为/usr/local/hadoop/etc/hadoop/core-site.xml)
<property>
<name>hadoop.proxyuser.hadoop.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hadoop.groupsname>
<value>*value>
property>
开启hadoop以后,在目录/usr/local/hive下执行以下命令开启hiveserver2,并设置默认端口为10000。
cd /usr/local/hive
./bin/hive --service hiveserver2 -hiveconf hive.server2.thrift.port=10000
在出现了几个Hive Session ID=…之后,出现ok,Hive才会真正启动。
启动成功后不要退出,新建一个服务器终端,使用如下命令查看10000号端口是否被占用。
sudo netstat -anp|grep 10000
如图所示,端口10000已被占用,即hiveserver2启动成功。

在个人电脑使用IDEA新建一个maven project。在pom.xml添加以下依赖文件(可能会有多余的,但是无碍)。
<dependencies>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>3.1.2version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>3.1.2version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-metastoreartifactId>
<version>3.1.2version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-commonartifactId>
<version>3.1.2version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-cliartifactId>
<version>3.1.2version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-contribartifactId>
<version>3.1.2version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.26version>
dependency>
dependencies>
在main–>java下新建java文件,命名为HivetoMySQL。内容如下。
import java.sql.*;
import java.sql.SQLException;
public class HivetoMySQL {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
private static String driverName_mysql = "com.mysql.jdbc.Driver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
}catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.exit(1);
}
Connection con1 = DriverManager.getConnection("jdbc:hive2://101.***.***.168:10000/default", "hive", "hive");//101.***.***.168为你自己的服务器ip地址,后两个参数是用户名密码
if(con1 == null)
System.out.println("连接失败");
else {
Statement stmt = con1.createStatement();
String sql = "select * from dblab.user_action";
System.out.println("Running: " + sql);
ResultSet res = stmt.executeQuery(sql);
//InsertToMysql
try {
System.out.println("begin try");
Class.forName(driverName_mysql);
Connection con2 = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/dblab","root","********");//********为root密码
String sql2 = "insert into user_action(id,uid,item_id,behavior_type,item_category,visit_date,province) values (?,?,?,?,?,?,?)";
PreparedStatement ps = con2.prepareStatement(sql2);
while (res.next()) {
ps.setString(1,res.getString(1));
ps.setString(2,res.getString(2));
ps.setString(3,res.getString(3));
ps.setString(4,res.getString(4));
ps.setString(5,res.getString(5));
ps.setDate(6,res.getDate(6));
ps.setString(7,res.getString(7));
ps.executeUpdate();
}
ps.close();
con2.close();
res.close();
stmt.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
con1.close();
}
}
使用IDEA的ssh远程调试服务。

上面程序执行完毕后,在MySQL中进行查询。
select count(*) from user_action;

4.3 查看MySQL中user_action表数据
下面需要再次启动MySQL,进入“mysql>”命令提示符状态:
mysql -u root -p
然后执行下面命令查询user_action表中的数据:
mysql> use dblab;
mysql> select * from user_action limit 10;
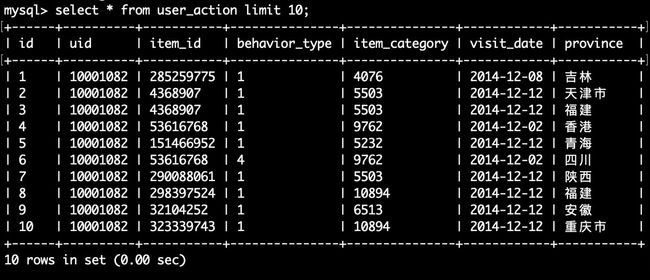
至此,数据从Hive导入MySQL的操作顺利完成。
4.4 使用HBase Java API把数据从本地导入HBase中
4.4.1 启动Hadoop集群、HBase服务
确保启动了hadoop集群和HBase服务。如果没有启动就在Linux系统中打开一个终端。输入以下命令。
cd /usr/local/hadoop
./sbin/start-all.sh
cd /usr/local/hbase
./bin/start-hbase.sh
4.4.2 数据准备
实际上,也可以编写java程序,直接从HDFS中读取数据加载到HBase。但是,这里展示的是如何用Java程序把数据从本地导入HBase中。只要对程序做简单修改,就可以实现从HDFS中读取数据加载到HBase。
将之前的user_action数据从HDFS复制到Linux系统的本地文件系统中,命令如下:
cd /usr/local/bigdatacase/dataset
/usr/local/hadoop/bin/hdfs dfs -get /user/hive/warehouse/dblab.db/user_action .
#将HDFS上的user_action数据复制到本地当前目录,注意'.'表示当前目录
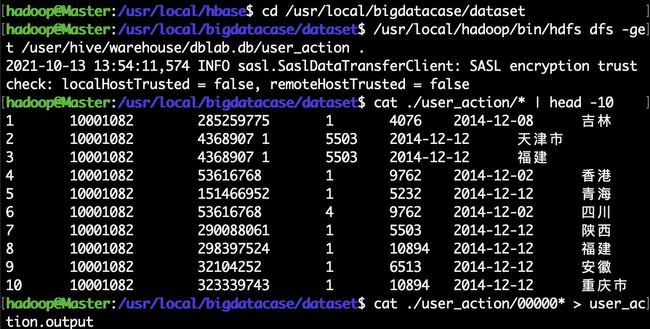
cat ./user_action/* | head -10 #查看前10行数据
cat ./user_action/00000* > user_action.output #将00000*文件复制一份重命名为user_action.output,*表示通配符
head user_action.output #查看user_action.output前10行
4.4.3 编写数据导入程序
这里采用IDEA编写Java程序实现HBase导入功能,具体代码如下:
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class ImportHBase extends Thread {
public Configuration config;
public Connection conn;
public Table table;
public Admin admin;
public ImportHBase() {
config = HBaseConfiguration.create();
// config.set("hbase.master", "master:60000");
// config.set("hbase.zookeeper.quorum", "master");
try {
conn = ConnectionFactory.createConnection(config);
admin = conn.getAdmin();
table = conn.getTable(TableName.valueOf("user_action"));
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
if (args.length == 0) { //第一个参数是该jar所使用的类,第二个参数是数据集所存放的路径
throw new Exception("You must set input path!");
}
String fileName = args[args.length-1]; //输入的文件路径是最后一个参数
ImportHBase test = new ImportHBase();
test.importLocalFileToHBase(fileName);
}
public void importLocalFileToHBase(String fileName) {
long st = System.currentTimeMillis();
BufferedReader br = null;
try {
br = new BufferedReader(new InputStreamReader(new FileInputStream(
fileName)));
String line = null;
int count = 0;
while ((line = br.readLine()) != null) {
count++;
put(line);
if (count % 10000 == 0)
System.out.println(count);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
try {
table.close(); // must close the client
} catch (IOException e) {
e.printStackTrace();
}
}
long en2 = System.currentTimeMillis();
System.out.println("Total Time: " + (en2 - st) + " ms");
}
@SuppressWarnings("deprecation")
public void put(String line) throws IOException {
String[] arr = line.split("\t", -1);
String[] column = {"id","uid","item_id","behavior_type","item_category","date","province"};
if (arr.length == 7) {
Put put = new Put(Bytes.toBytes(arr[0]));// rowkey
for(int i=1;i<arr.length;i++){
put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes(column[i]),Bytes.toBytes(arr[i]));
}
table.put(put); // put to server
}
}
public void get(String rowkey, String columnFamily, String column,
int versions) throws IOException {
long st = System.currentTimeMillis();
Get get = new Get(Bytes.toBytes(rowkey));
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column));
Scan scanner = new Scan(get);
scanner.readVersions(versions);
ResultScanner rsScanner = table.getScanner(scanner);
for (Result result : rsScanner) {
final List<Cell> list = result.listCells();
for (final Cell kv : list) {
System.out.println(Bytes.toStringBinary(kv.getValueArray()) + "\t"
+ kv.getTimestamp()); // mid + time
}
}
rsScanner.close();
long en2 = System.currentTimeMillis();
System.out.println("Total Time: " + (en2 - st) + " ms");
}
}
打包之后发送至服务器,存放在/usr/local/bigdatacase/hbase(如果没有需要新建)。
4.4.4 数据导入
在导入之前,先新建user_action表,新建HBase Shell窗口。
hbase shell(在任意位置输入命令)
启动成功后,就进入了“hbase>”命令提示符状态。
创建表user_action
hbase> create 'user_action', { NAME => 'f1', VERSIONS => 5}
上面命令在HBase中创建了一个user_action表,这个表中有一个列族f1(你愿意把列族名称取为其他名称也可以,比如列族名称为userinfo),历史版本保留数量为5。

下面就可以运行hadoop jar命令运行程序:
/usr/local/hadoop/bin/hadoop jar /usr/local/bigdatacase/hbase/ImportHBase.jar HBaseImportTest /usr/local/bigdatacase/dataset/user_action.output
这个命令大概会执行几分钟左右,执行过程中,屏幕上会打印出执行进度,每执行1万条,对打印出一行信息,所以,整个执行过程屏幕上显示如下信息:

查看HBase中user_action表数据
下面,再次切换到HBase Shell窗口,执行下面命令查询数据:
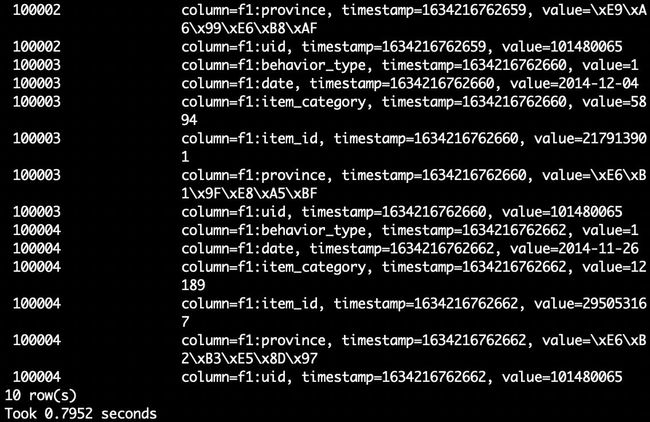
habse> scan 'user_action',{LIMIT=>10} #只查询前面10行
就可以得到类似下面的查询结果了:
5 利用R进行数据可视化分析
5.1 安装R
Ubuntu自带的APT包管理器中的R安装包总是落后于标准版,因此需要添加新的镜像源把APT包管理中的R安装包更新到最新版。
请登录Linux系统,打开一个终端,然后执行下面命令(并注意保持网络连通,可以访问互联网,因为安装过程要下载各种安装文件):
利用vim打开/etc/apt/sources.list文件
sudo vim /etc/apt/sources.list
在文件中添加阿里云的镜像源,把如下文件添加进去。其中xenial是Ubuntu16.04的代号。
deb http://mirrors.aliyun.com/ubuntu/ xenial main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse
退出vim,更新软件源列表
sudo apt-get update
安装R语言
sudo apt-get install r-base
会提示“您希望继续执行吗?[Y/n]”,可以直接键盘输入“Y”,就可以顺利安装结束。
安装结束后,可以执行下面命令启动R:
R

“>”就是R的命令提示符,你可以在后面输入R语言命令。
可以执行下面命令退出R:
>q()
安装依赖库
为了完成可视化功能,我们需要为R安装一些依赖库,包括:RMySQL、ggplot2、devtools和recharts。
RMySQL是一个提供了访问MySQL数据库的R语言接口程序的R语言依赖库。
ggplot2和recharts则是R语言中提供绘图可视化功能的依赖库。
请启动R进入R命令提示符状态,执行如下命令安装RMySQL:
> install.packages('RMySQL')
执行如下命令安装绘图包ggplot2:
install.packages('ggplot2')
安装devtools
install.packages('devtools')
笔者在Ubuntu16.04上执行devtools安装时,出现了错误,笔者根据每次错误的英文提示信息,安装了三个软件libssl-dev、libssh2-1-dev、libcurl4-openssl-dev,安装命令如下:
sudo apt-get install libssl-dev
sudo apt-get install libssh2-1-dev
sudo apt-get install libcurl4-openssl-dev
安装之后重新安装devtools。
下面在R命令提示符下再执行如下命令安装taiyun/recharts:
> devtools::install_github('taiyun/recharts')
至此,工具安装已全部完成。
5.2 可视化分析
以下分析使用的函数方法,都可以使用如下命令查询函数的相关文档。例如:查询sort()函数如何使用
?sort
这时,就会进入冒号“:”提示符状态(也就是帮助文档状态),在冒号后面输入q即可退出帮助文档状态,返回到R提示符状态!
连接MySQL,并获取数据
请在Linux系统中新建另外一个终端,然后执行下面命令启动MySQL数据库:
sudo service mysql start
下面,让我们查看一下MySQL数据库中的数据,请执行下面命令进入MySQL命令提示符状态:
mysql -u root -p
会提示你输入密码,就进入了“mysql>”提示符状态,下面就可以输入一些SQL语句查询数据:
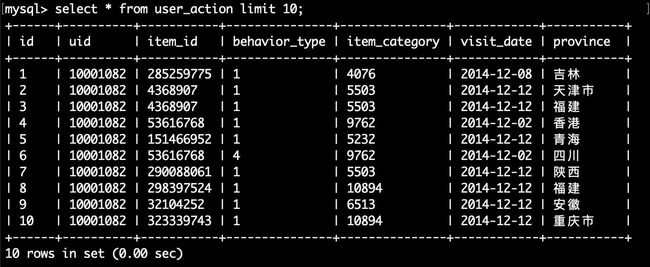
mysql> use dblab;
mysql> select * from user_action limit 10;
这样,就可以查看到数据库dblab中的user_action表的前10行记录,如下:
然后切换到刚才已经打开的R命令提示符终端窗口:
library(RMySQL)
conn <- dbConnect(MySQL(),dbname='dblab',username='root',password='hadoop',host="127.0.0.1",port=3306)
user_action <- dbGetQuery(conn,'select * from user_action')
分析消费者对商品的行为
summary(user_action$behavior_type)
summary() 函数可以得到样本数据类型和长度,如果样本是数值型,我们还能得到样本数据的最小值、最大值、四分位数以及均值信息。
得到结果:

可以看出原来的MySQL数据中,消费者行为变量的类型是字符型。这样不好做比较,需要把消费者行为变量转换为数值型变量
summary(as.numeric(user_action$behavior_type))
得到结果:

接下来用柱状图表示:
library(ggplot2)
ggplot(user_action,aes(as.numeric(behavior_type)))+geom_histogram()
在使用ggplot2库的时候,需要使用library导入库。ggplot()绘制时,创建绘图对象,即第一个图层,包含两个参数(数据与变量名称映射).变量名称需要被包含aes函数里面。ggplot2的图层与图层之间用“+”进行连接。ggplot2包中的geom_histogram()可以很方便的实现直方图的绘制。
由于我们使用ssh远程调试,无法得到图形界面,所以要增加存储图片的步骤。然后传到个人电脑中查看。命令如下:
> setwd('/usr/local/rpictures') #选取储存目录,建议和R工作表分开
> future=paste("fig1",".jpg") #通过paste将文件名和后缀连接起来
> jpeg(file=future)
> ggplot(user_action,aes(as.numeric(behavior_type)))+geom_histogram()
> dev.off()
分析结果如下图:
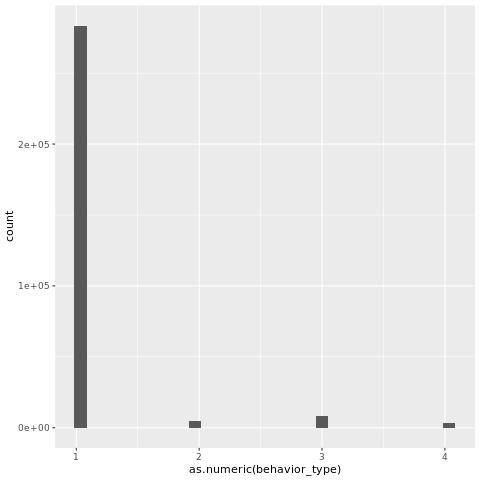
从上图可以得到:大部分消费者行为仅仅只是浏览。只有很少部分的消费者会购买商品。
分析哪一类商品被购买总量前十的商品和被购买总量
temp <- subset(user_action,as.numeric(behavior_type)==4) # 获取子数据集
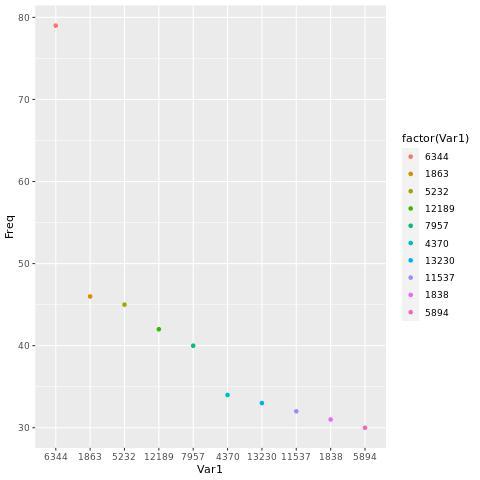
count <- sort(table(temp$item_category),decreasing = T) #排序
print(count[1:10]) # 获取第1到10个排序结果
subset()函数,从某一个数据框中选择出符合某条件的数据或是相关的列.table()对应的就是统计学中的列联表,是一种记录频数的方法.sort()进行排序,返回排序后的数值向量。
得到结果:

结果第一行表示商品分类,该类下被消费的数次。
接下来用散点图表示:
> result <- as.data.frame(count[1:10]) #将count矩阵结果转换成数据框
> setwd('/usr/local/rpictures') #选取储存目录,建议和R工作表分开
> future=paste("fig2",".jpg") #通过paste将文件名和后缀连接起来
> jpeg(file=future)
> ggplot(result,aes(Var1,Freq,col=factor(Var1)))+geom_point()
> dev.off()
通过 as.data.frame() 把矩阵等转换成为数据框.
分析结果如下图:
分析每年的哪个月份购买商品的量最多
从MySQL直接获取的数据中visit_date变量都是2014年份,并没有划分出具体的月份,那么可以在数据集增加一列月份数据。
month <- substr(user_action$visit_date,6,7) # visit_date变量中截取月份
user_action <- cbind(user_action,month) # user_action增加一列月份数据
接下来用柱状图分别表示消费者购买量
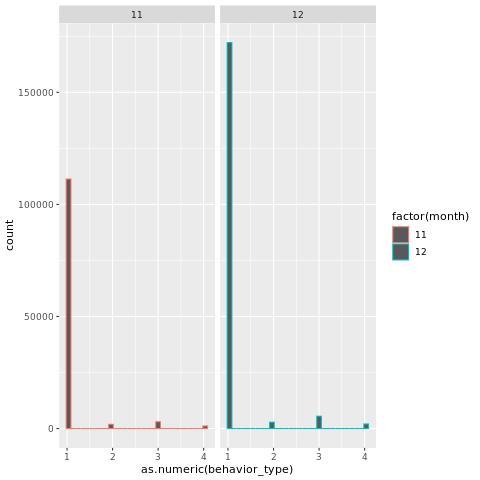
ggplot(user_action,aes(as.numeric(behavior_type),col=factor(month)))+geom_histogram()+facet_grid(.~month)
aes()函数中的col属性可以用来设置颜色。factor()函数则是把数值变量转换成分类变量,作用是以不同的颜色表示。如果不使用factor()函数,颜色将以同一种颜色渐变的颜色表现。 facet_grid(.~month)表示柱状图按照不同月份进行分区。
由于MySQL获取的数据中只有11月份和12月份的数据,所以上图只有显示两个表格。
分析结果如下图:
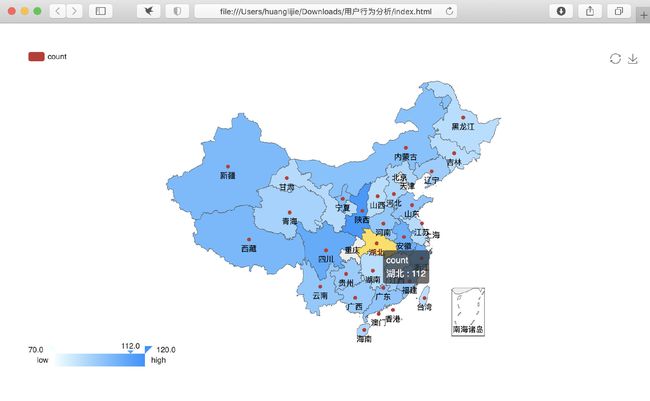
分析国内哪个省份的消费者最有购买欲望
library(recharts)
rel <- as.data.frame(table(temp$province))
provinces <- rel$Var1
x = c()
for(n in provinces){
x[length(x)+1] = nrow(subset(temp,(province==n)))
}
mapData <- data.frame(province=rel$Var1,
count=x, stringsAsFactors=F) # 设置地图信息
eMap(mapData, namevar=~province, datavar = ~count) #画出中国地图
nrow()用来计算数据集的行数。
可能会出现无法显示数字的问题,如下所示。
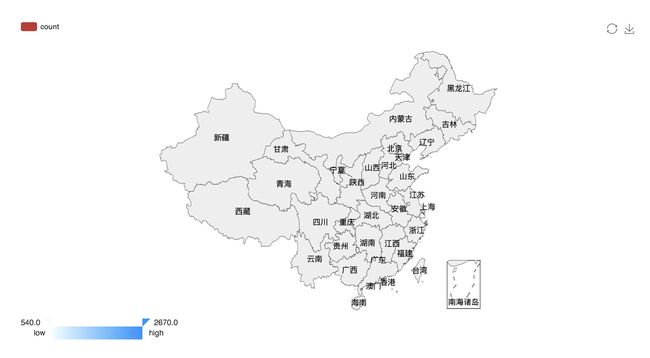
这是因为R语言读取sql数据时,读入中文出现乱码,所以无法正确识别省份。于是需要读取时先在R里对数据库中文编码进行如下设置。
dbSendQuery(conn,'SET NAMES gbk') #设置格式为Gbk
分析结果如下图: