AI硬件部署方案
- 深度学习为什么需要显卡计算?
- 计算能力
GPU 是为大规模的并行运算而优化;
GPU 上则更多的是运算单元(整数、浮点的乘加单元,特殊运算单元等等); GPU 往往拥有更大带宽的显存,因此在大吞吐量的应用中也会有很好的性能。
比较 GPU 和 CPU ,就是比较它们两者如何处理任务。如下图所示, CPU 使用几个核心处理单元去优化串行顺序任务,而 GPU 的大规模并行架构拥有数以千计的更小、更高效的处理单元,用于处理多个并行小任务。
CPU 拥有复杂的系统指令,能够进行复杂的任务操作和调度,两者是互补关系,而不能相互代替。

Cpu只有4个核心并行工作GPU拥有256个核心进行工作
从下图可以看出GPU(图像处理器,Graphics Processing Unit)和CPU(中央处理器,Central Processing Unit)在设计上的主要差异在于GPU有更多的运算单元(如图中绿色的ALU),而Control和Cache单元不如CPU多,这是因为GPU在进行并行计算的时候每个运算单元都是执行相同的程序,而不需要太多的控制。Cache单元是用来做数据缓存的,CPU可以通过Cache来减少存取主内存的次数,也就是减少内存延迟(memory latency)。GPU中Cache很小或者没有,因为GPU可以通过并行计算的方式来减少内存延迟。因此CPU的Cahce设计主要是实现低延迟,Control主要是通用性,复杂的逻辑控制单元可以保证CPU高效分发任务和指令。所以CPU擅长逻辑控制,是串行计算,而GPU擅长高强度计算,是并行计算。
。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已。而CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生。
可以看出GPU加速是通过大量线程并行实现的,因此对于不能高度并行化的工作而言,GPU就没什么效果了。而CPU则是串行操作,需要很强的通用性,主要起到统管和分配任务的作用。

- 吞吐量
Cpu与GPU的关系也如同小轿车与大货车的关系。比如一项任务,要把一堆货物从北京搬运到广州。 CPU(跑车〉可以快速地把数据(货物〉从内存读入 RAM 中,然而 GPU (大卡车〉装货的速度就好慢了。不过后面才是重点, CPU (跑车)把这堆数据(货物)从北京搬运到广州|需要来回操作很多次,也就是往返京广线很多次,而 GPU (大卡车)只需要一 次就可以完成搬运(一次可以装载大量数据进入内存)。换言之, CPU 擅长操作小的内存块,而 GPU 则擅长操作大的内存块 。 CPU 集群大概可以达到 50GB/s 的带宽总量,而等量的 GPU 集群可以达到 750GB/s 的带宽量。


而实际生产生活,训练只是节假日,数据处理才是每天的柴米油盐。每周解压几千万数据,处理几千万图片,这都是经常性的。
二、所以显卡选择最重要,各大厂商如何选择?
本地运算首选英伟达GPU,不仅大多数深度学习库都对英伟达GPU提供最佳支持,而且英伟达的社区支持好,这意味着,如果你使用NVIDIA GPU出错时,非常容易找到支持,你将会找到自己程序的支持和建议,它在深度学习上的支持度比AMD好很多;云计算首选谷歌TPU,它的性价比超过亚马逊AWS和微软Azure。
因为准备基于CUDA计算(并行计算框架,只能在NVIDIA的GPU上运行),所以优先选择Nvida系列的。在英伟达产品系列中,有消费领域的GeForce系列,有专业绘图领域的Quadro系列,有高性能计算领域的Tesla系列,如何选择?
有论文研究,太高的精度对于深度学习的错误率是没有提升的,而且大部分的环境框架都只支持单精度,所以双精度浮点计算是不必要,Tesla系列都去掉了。从显卡效能的指标看,CUDA核心数要多,GPU频率要快,显存要大,带宽要高。
英伟达官方说明在GPU算力高于5.0时,可以用来跑神经网络。
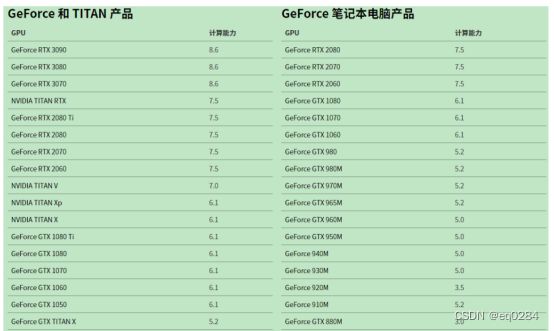

性能最佳的GPU:RTX 3090
性价比高的高端GPU:RTX 3080,RTX 2080
性价比高的低端GPU:GTX 1080Ti,GTX 1080,,GTX 1070,GTX 1070 TI,GTX 1060
我使用的数据集> 400GB:RTX 3080 TI或RTX 3080
我使用的数据集> 250GB:RTX 2080 TI或RTX 2080
我有一点钱:GTX 1060(6GB)
我几乎没有钱:GTX 1050 TI(4GB)或CPU(原型)+AWS/TPU(培训)
我做Kaggle:GTX 1060(6GB)用于原型,AWS进行最终训练;使用FASTAI库(PyTorch)
我是一个有竞争力的计算机视觉研究者:GTX 2080 TI;2019升级到RTX TITAN
我是一个研究者:RTX 3080 TI或GTX 10XX-RTX TITAN——检查当前模型的内存需求
我想构建一个GPU集群:这真的很复杂,你可以在这里得到一些想法
我开始深度学习,我对此很深入:从GTX 1060(6GB)或便宜的GTX 1070或GTX 1070 Ti开始,如果你能找到的话。根据你接下来选择的领域(创业、研究、应用深度学习)卖出你的GPU并买一些性能更强的东西
我想尝试深度学习,但我并不深入:GTX 1050 TI(4或2GB)
需要多个GPU吗?
需要多个GPU,对于卷积神经网络,在2/3/4GPU,可以预期得到1.9x/2.8x/3.5x的加速,GPU数量越多,计算越快,训练也就越快。
三、其他硬件配置如何选择
VRAM (显存):
显存大小决定了我们的网络模型能不能执行,大型的卷积神经网络会使用超过8G以上的显存。
cpu:
Tensorflow(可能还有其他DL框架)对英特尔CPU(MKL等的使用)有一些优化。所以推荐使用英特尔CPU。因为主要使用显卡进行cuda计算,因此对CPU的要求并不是很高,频率越高、线程数越多越好,一般最低要求cpu核心数大于显卡个数。其中一个制约因素:cpu的最大PCI-E 通道数。每张显卡占用16条PCI-E 通道才能达到最大性能,而单cpu最大支持40条PCI-E ,也就是即使有4个PCI-E x16接口,只能最多达到2路x16加一路x8,插上的显卡不能发挥全部性能。不过,主板芯片组其实也可以扩充一部分PCI-E 通道。(x99主板可以扩宽2.0的8lanes,z170可以扩充3.0的20lanes)
备注:PCI-E 是计算机高带宽传输总线的标准接口。
主板:
前面提到了cpu提供的pcie通道数的限制,如果要使用多块显卡,就需要主板提供额外的pcie通道,一般只有服务器级别的主板才会提供扩展pcie通道如x99、x299等主板,但是使用此类主板必须搭配具有该接口的服务器级cpu(xeon系列、i7 7900x以上、i9系列等),如果不需要三块以上的显卡,使用cpu提供的40条pcie即可。
电源:
一个显卡的功率接近150-300W,四显卡建议电源在1200W以上,为了以后扩展,或选择1600W的电源。
内存:
深度学习需要大量数据,中间计算过程也会临时储存大量数据,一般要求具有显存2~3倍的内存,32G或64G乃至更高。内存频率越高越好。
硬盘:
深度学习需要大量数据,和较快的访问速度,一般使用一个较大的固态硬盘作为系统盘和训练数据仓储盘,另外使用hdd机械硬盘作为仓储盘。建议使用512G以上nVME固态硬盘搭配几TB Hdd作为储存空间。
四、下面给出一套参考配置:
| 硬件 |
型号 |
数量 |
价格(天猫) |
| CPU |
I9-12900k |
1 |
7099 |
| GPU |
NVIDIA GTX 2080 |
2 |
19998 |
| 主板 |
Asus/华硕 WS X299 PRO工作站主板 |
1 |
3799 |
| 内存 |
海盗船 复仇者32g * 2条DDR4 3600Mhz 64G内存 |
2 |
2269 |
| 机箱 |
海盗船 AIR 540 |
1 |
949 |
| SSD |
三星 980 PRO 512M 250G |
1 |
499 |
| HDD |
西部数据4T SATA 6 GB/s 7200转256M企业硬盘 |
1 |
1449 |
| 散热 |
海盗船H400i-V2双排240mm水冷散热器 |
1 |
859 |
| 电源 |
EVGA 1600 G 1600 T2额定1600W |
1 |
3299 |
| 显示器键盘鼠标 |
要求不多 |
3 |
800 |
| 合计 |
41020 |