kettle-实现增量数据定时及服务器部署
kettle 按时间增量数据同步脚本
1、数据库中最大时间为需要同步的最小时间,根据这个时间戳获取到待同步的数据,同时可手动设置需要同步的时间段数据
(修改etl表 中时间戳字段即可)
2、如果两个表数据对比,出现差异数据,例如新增数据、待更新数据、待删除数据后,该程序会自动识别标记,
并根据标记 对目标表数据进行增删改操作
3、存在两处缺点,1、增加时间段数据补录功能 2、增加自动识别缺失数据补录功能
详细流程如下
前言
Kettle`对一张业务表数据(500万条数据以上)进行实时(10秒)同步,采用了时间戳增量回滚同步的方法。
1. 时间戳增量回滚同步
在源数据表中有一个字段会记录数据的新增或修改时间,可以通过它对数据在时间维度上进行排序。通过中间表记录每次更新的时间戳,在下一个同步周期时,通过这个时间戳同步该时间戳以后的增量数据。这是时间戳增量同步。
我们可以通过在每次同步时,把时间戳往前回滚一段时间,从而同步一定时间段内的删除操作。这就是时间戳增量回滚同步,
同时可更具字段控制是否启动项目脚本运行。
说明:
- 源数据表 需要被同步的数据表
- 目标数据表 同步至的数据表
- 中间表 存储时间戳的表
2. 作业流程
- 开始组件
- 建时间戳中间表
- 获取中间表的时间戳,并设置为全局变量
- 检查字段中的值,判断是否启动程序运行
- 删除目标表中时间戳及时间戳以后的数据
- 抽取两个数据表的时间戳及时间戳以后的数据进行比对,并根据比对结果进行删除、新增或修改操作
- 更新时间戳
- 完成
3. 创建作业
作业的最终截图如下:

3.1 创建作业和DB连接
打开Spoon工具,新建作业,然后在左侧主对象树DB连接中新建DB连接。创建连接并测试通过后可以在左侧DB连接下右键共享出来。因为在单个作业或者转换中新建的DB连接都是局域数据源,在其他转换和作业中是不能使用的,即使属于同一个作业下的不同转换,所以需要把他们共享,这样DB连接就会成为全局数据源,不用多次编辑。
3.2 建时间戳中间表
创建etl数据同步表,表字段包含 id(唯一主键)、time_stamp(数据同步时间)、update_time(数据更新时间)、
startup_status(任务启动状态 0启动 1暂停)、data_flow(数据流方向)、remark(备注)
1、id(唯一主键)字段判断任务的唯一标识
2、time_stamp字段插入初始的时间戳字段。因为该作业在生产环境是循环调用的,该步骤在每一个同步周期中都会调用,所以在建表时需要判断该表是否已经存在,如果不存在才建表。
3、update_time(数据更新时间) 最新的数据同步时间
4、startup_status(任务启动状态 0启动 1暂停),可控制脚本是否正常运行
SQL代码和组件配置截图如下:
建表语句:
create table if not EXISTS dc_tools_etl_all_data_temp (id varchar(256) primary key , time_stamp timestamp);
INSERT INTO dc_tools_etl_all_data_temp(id,time_stamp,update_time,startup_status,data_flow,remark)VALUES
('dwd_air_hourly_station_air_data','2021-10-25 11:00:00',now(),0,'ODS-DWD','DWD') ON conflict(id) DO UPDATE SET id = 'dwd_air_hourly_station_air_data'


我把该作业时间戳的ID设为唯一标识,同时也方便查找对应的表同步,在接下来的步骤中也是通过这个ID查询我们想要的时间戳
3.3获取时间戳并设为变量
新建一个转换,在转换中使用表输入和设置变量两个组件
3.3.1表输入
SQL代码和组件配置截图如下
在Kettle中设置的变量都是字符串类型,为了便于比较。我在SQL语句把查出的时间戳进行了格式转换
同时也查看任务的启停状态,如果设置为 1 则为停止状态,设置变量的时候就设置为error
SELECT
case when startup_status = 0 then to_char(time_stamp , 'YYYY-MM-DD hh24:mi:ss')
when startup_status = 1 then 'error'
end as time_stamp
from dc_tools_etl_all_data_temp where id='dwb_air_hourly_city_air_forecast_data'


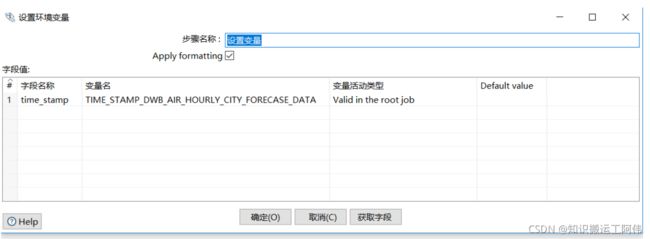
3.3.2设置变量
变量活动类型可以为该变量设置四种有效活动范围,分别是JVM、该Job、父Job和祖父Job
3.4检查字段的值
该步骤是确定是否启动此任务运行,如果变量设置不包含error 证明此项任务被暂停,就别pass掉

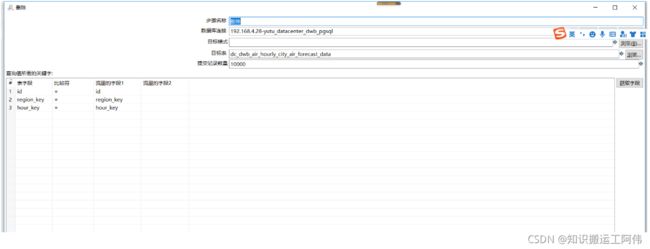
3.5删除目标表中时间戳及时间戳以后的数据
这个步骤可以被废掉,因为后期我加上了数据标志控制增删改
这样做有两个好处:
避免在同步中重复或者遗漏数据。例如当时间戳在源数据表中不是唯一的,上一次同步周期最后一条数据的时间戳是2018-05-25
18:12:12,那么上一次同步周期结束后中间表中的时间戳就会更新为2018-05-25 18:12:12。
如果在下一个同步周期时源数据表中仍然有时间戳为2018-05-25 18:12:12的新数据,那么同步就会出现数据不一致。
采用大于时间戳的方式同步就会遗漏数据,采用等于时间戳的方式同步就会重复同步数据。
增加健壮性 当作业异常结束后,不用做任何多余的操作就可以重启。因为会删除目标表中时间戳及时间戳以后的数据,所以不用担心数据一致性问题
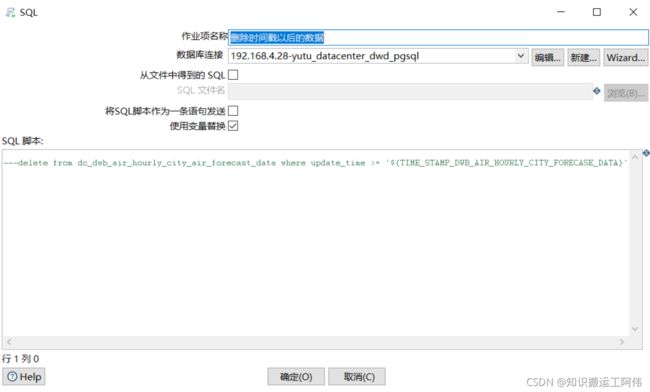
在组件中使用了上一步骤设置的变量,所以必须勾选使用变量替换
delete from dc_dwb_air_hourly_city_air_forecast_data where update_time >= '${TIME_STAMP_DWB_AIR_HOURLY_CITY_FORECASE_DATA}'
3.6 抽取、比对和更新数据
这一步才是真正的数据同步步骤,完成了数据的抽取、比对,并根据不同的比对结果删除、更新、插入或不做任何操作。
此步骤包含了源数据表和目标数据表的数据对比 、字段mapping关系、记录合并、数据表示、数据增加、数据删除、数据修改等
功能。
转换步骤如下:

原始表数据输入查询
SELECT
id,
(SELECT x.region_key from dc_dim_general_administrative_region x where x.is_deleted = 0 and x.history @> (SELECT string_to_array(region_code ,''))::varchar[]) as region_key,
left((to_char(forecast_time,'YYYYMMDDhh24mi')),10)::int as hour_key,
(SELECT x.province_code from dc_dim_general_administrative_region x where x.is_deleted = 0 and x.history @> (SELECT string_to_array(region_code ,''))::varchar[] offset 0 limit 1) as province_code,
(SELECT x.city_code from dc_dim_general_administrative_region x where x.is_deleted = 0 and x.history @> (SELECT string_to_array(region_code ,''))::varchar[] offset 0 limit 1) as city_code,
(SELECT x.district_code from dc_dim_general_administrative_region x where x.is_deleted = 0 and x.history @> (SELECT string_to_array(region_code ,''))::varchar[] offset 0 limit 1) as district_code,
(SELECT x.province_name from dc_dim_general_administrative_region x where x.is_deleted = 0 and x.history @> (SELECT string_to_array(region_code ,''))::varchar[] offset 0 limit 1) as province_name,
(SELECT x.city_name from dc_dim_general_administrative_region x where x.is_deleted = 0 and x.history @> (SELECT string_to_array(region_code ,''))::varchar[] offset 0 limit 1) as city_name,
(SELECT x.district_name from dc_dim_general_administrative_region x where x.is_deleted = 0 and x.history @> (SELECT string_to_array(region_code ,''))::varchar[] offset 0 limit 1) as district_name,
forecast_time as update_time,
predict_time as storage_time,
aqi,
case when 0 < aqi and aqi<= 50 then 1
when 50 < aqi and aqi <= 100 then 2
when 100< aqi and aqi<= 150 then 3
when 150< aqi and aqi<= 200 then 4
when 200< aqi and aqi<= 300 then 5
when 300< aqi and aqi<= 400 then 6
when 400< aqi then 6
ELSE -9999
END as aqi_level
from dc_ods_air_air_forecast_hourly_city_airmaster
where forecast_time >= to_timestamp('${TIME_STAMP_DWB_AIR_HOURLY_CITY_FORECASE_DATA}', 'YYYY-MM-DD hh24:mi:ss') order by aqi_level asc
目标表输出数据查询
SELECT id,region_key,hour_key,province_code,city_code,district_code,province_name,city_name,district_name,update_time,storage_time,aqi, aqi_level,aqi_category,aqi_color
FROM dc_dwb_air_hourly_city_air_forecast_data WHERE update_time >= to_timestamp('${TIME_STAMP_DWB_AIR_HOURLY_CITY_FORECASE_DATA}', 'YYYY-MM-DD hh24:mi:ss')
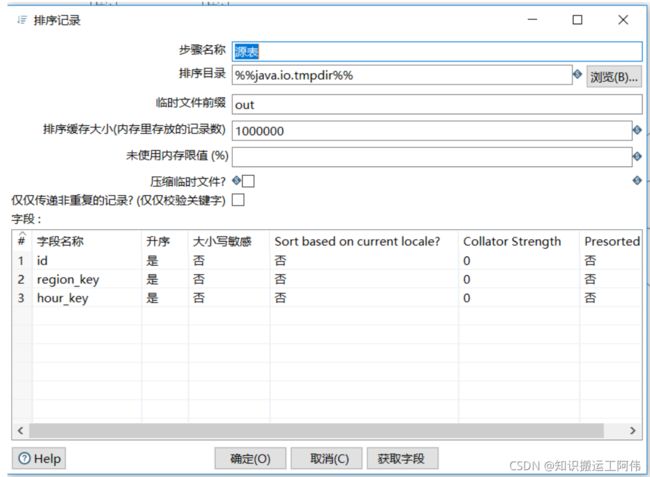
排序记录
原始表输入和目标表输出,sql查询完成后,对两项数据表中对应标志主键key进行排序(排序是为了合并记录使用)
合并记录
对两个表输入查出的数据进行比对,并把比对的结果写进输入流,传递给后面的组件。
比对的结果有四种:
new:增加
changed:修改
deleted:删除
identical:相同
标注字段表示比对结果的字段名,后面有用。关键字段表示比对的字段,在这个作业中我们比较两个的主键`。

switch
该步骤对上一步骤产生的标注字段进行路由,不同的结果路由到不同的步骤。其中目标步骤表示下一步骤的名字。

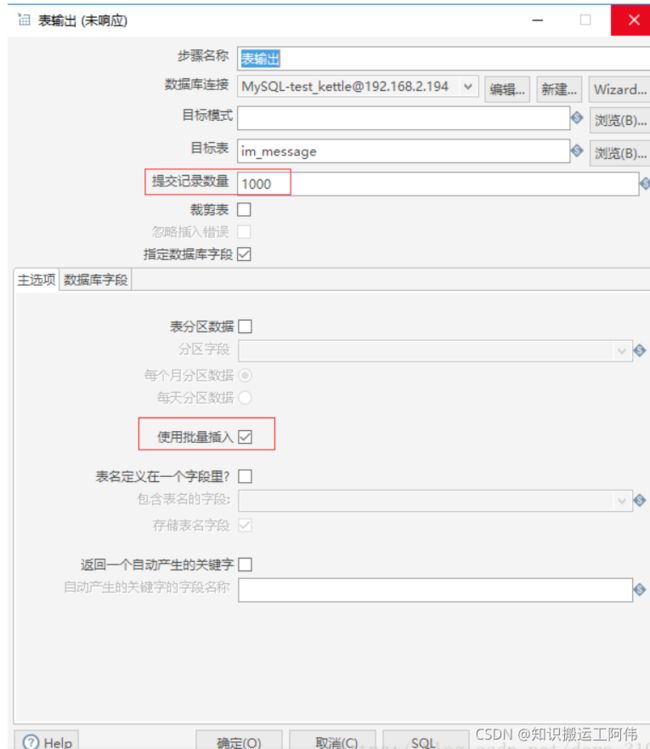
postgresql 批量加载
kettle对postgresql 数据库中数据批量添加/清空组件,但是据网友介绍这个组件性能低下,每秒最多只能同步几百条数据,
为了进一步提升同步效率,我在表输出组件使用了多线程(右键>改变开始复制的数量),使同步速度达到每秒12000条。
Switch组件和表输出组件中间的虚拟组件(空操作)也是为了使用多线程添加的。

更新
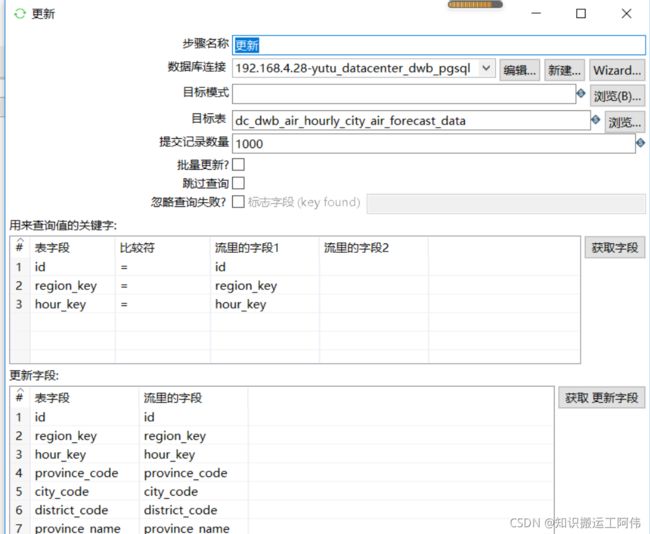
删除
3.7发送邮箱
关于发送邮件组件网上有很多资料,就不多做介绍。特别强调一点,邮箱密码是 单独的授权码,而不是邮箱登录密码。
运行
在开发环境点击Spoon界面左上角三角符号运行作业即可。
在第一次运行时,为了提高同步效率,可以先不创建目标表的索引。在第一此同步完成后,再创建索引。然后在START组件中编辑调度逻辑,再次启动。

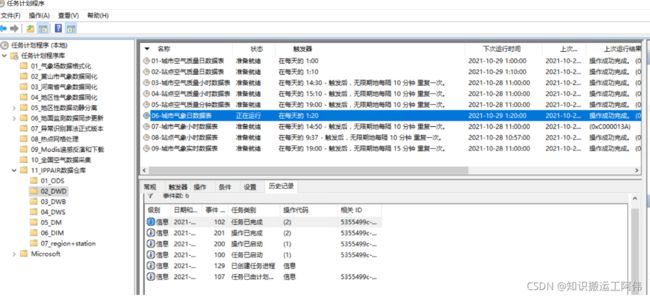
4、widows定时任务
使用bat文件定时,具体查看bat文件代码。
D:
cd D:\date-integration-9\data-integration
kitchen /file E:\sourcecodesvn\yutu_datacenter_etl\DWD\dc_dwd_weather_daily_city_weather_data\job\weather_daily_city_weather_data_airmaster.kjb
/level Detailed E:\sourcecodesvn\yutu_datacenter_etl\DWD\dc_dwd_weather_daily_city_weather_data\logs\dwd_weather_daily_city_dat.log

新建windows定时任务

5、linux下定时任务
使用sh文件定时,,具体查看sh文件代码。
编写sh文件代码
#!/bin/sh
export KETTLE_HOME=/home/kettle/data-integration
export JAVA_HOME=/usr/local/java/jdk1.8.0_251
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH:$KETTLE_HOME
#日志名称
log_name="run_all_$(date "+%Y-%m-%d").log"
#脚本根目录
script_dir=/home/datacenter/DWD
#增量更新表t_bas_aqi
run_command="kitchen.sh -file=${script_dir}/dc_dwd_air_daily_city_air_data_v1/job/air_daily_city_air.kjb -level=Basic >>${script_dir}/logs/${log_name}"
#不管运行oracle-to-mysql.kjb作业有没有成功都需要运行t_bas_aqi的作业
{
kitchen.sh -file=${script_dir}/dc_dwd_air_daily_city_air_data_v1/job/air_daily_city_air.kjb -level=Basic >>${script_dir}/logs/${log_name}
}||{
${run_command}
}&&{
${run_command}
}
ata_v1/job/air_daily_city_air.kjb -level=Basic >> s c r i p t d i r / l o g s / {script_dir}/logs/ scriptdir/logs/{log_name}"
#不管运行oracle-to-mysql.kjb作业有没有成功都需要运行t_bas_aqi的作业
{
kitchen.sh -file= s c r i p t d i r / d c d w d a i r d a i l y c i t y a i r d a t a v 1 / j o b / a i r d a i l y c i t y a i r . k j b − l e v e l = B a s i c > > {script_dir}/dc_dwd_air_daily_city_air_data_v1/job/air_daily_city_air.kjb -level=Basic >> scriptdir/dcdwdairdailycityairdatav1/job/airdailycityair.kjb−level=Basic>>{script_dir}/logs/${log_name}
}||{
${run_command}
}&&{
${run_command}
}
