ArcGIS+ENVI实现遥感分类精度评估(分层抽样法)
最近修改论文已经到了最后的关口,但是分类精度评估的方法还需要再修改调整。
我原来的方法是利用ArcGIS建立格网,格网中心点作为我的目视解译点,然后利用ArcGIS收集该点的影像分类结果,再把数据属性导出用python计算混淆矩阵。
被质疑之后我使用了分层抽样法,原理我就不赘述了,通过分层抽样法可以计算出一幅影像每个类别需要的抽样点为多少。
之后在分类影像上每个类别的点随机撒在该类别的位置,再人工目视解译,与影像分类结果一起计算混淆矩阵即可。
我首先尝试了Erdas,首先有着ArcGIS的电脑安装erdas后会出现一定的问题,之后我会再写一篇文章概述。并且最后发现erdas抽样的点很难导入ArcGIS或者有个excel表格这样方便计算混淆矩阵,于是我放弃了。
之后网上搜索到ArcMap 10.4以上版本可以较为方便的,进行分层抽样撒点,但是按照高版本的有风险,我目前用10.2
ArcGIS 10.2没有办法让点能够撒到分类影像上那一类的位置上去,但是我最后发现ENVI可以使用这个功能。
正文如下:----------------------------------------不想看我叙述的可以看这里------------------------------
1.分类
首先我的分类结果是tif影像,1、2、3这些值来表示各个类别,tif不能直接在ENVI中进行抽样撒点,要在ENVI中分类,采用决策树,也就是classification-decision tree,首先先建立一个决策树,注意这是让你选b1的波段,先不要选,之前我选了后来换成别的影像存在错误。保存之后,使用classification-decision tree-execute exiting decision tree,选择之前保存的决策树txt。选择你的分类结果影像,然后就可以得到分类影像。
2.抽样撒点
使用envi的classification-post classification-generate random sample-using ground truth image
之后选择你需要的影像,点确定

之后可以选择类(注意这里我给了一个类别给影像上没有分类的,就是none,可以不选它)
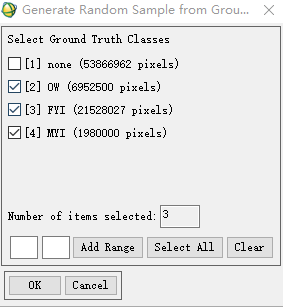
点OK后,选择分层抽样,和diproportionnate,然后点击set class sample sizes,就可以设定每个类别撒多少点了

其他选择不变保存roi
之后打开影像
选择overlay-region of interest,就可以看到生成的点(其实就是roi),注意这里的ROI可能存在之前生成的,不是你这次的,删掉。以下窗口选择,选择File-output roi to shapefile这个,

如下,选择你需要的类别保存即可,基本是全选

3.shapefile获取影像分类点+目视解译
将shp文件在ArcGIS打开,之后选择spatial analysis tools-extraction-extract values to points,选择你的shp文件和影像,最后可以得到一个矢量文件,里面有一栏RASTERVALU属性就是影像的值。
之后只要打开属性表,add field增加新的一列,作为目视解译的结果,然后右键使用栅格计算器,使它等于RASTERVALU这一列即可(这一步是为了减小工作量,当然也可以自己赋值),然后就可以目视解译改这个值啦。
4.计算混淆矩阵
得到目视解译后的点的矢量文件,可以使用python打开shp文件自带的dbf文件(其实就是属性表)计算混淆矩阵和kappa系数即可
代码如下
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import cohen_kappa_score
from sklearn.metrics import precision_recall_fscore_support
from sklearn.metrics import classification_report
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
import pandas
import os
from dbfread import DBF
rootdir = "H:\\result_2_type\\points"
list = os.listdir(rootdir)
colnames = ['OID_', 'RASTERVALU', 'true']
true=[]
result=[]
for i in range(0,len(list)):
if not list[i].endswith(".dbf"):
continue
folder = os.path.join(rootdir,list[i])
print(folder)
table = DBF(folder, encoding='GBK')
df = pandas.DataFrame(iter(table))
result_temp = df['RASTERVALU'].tolist()
true_temp = df['true'].tolist()
score=accuracy_score(true_temp, result_temp)
print('score=',score)
kappa=cohen_kappa_score(true_temp, result_temp)
print('kappa=',kappa)
report=classification_report(true_temp, result_temp,digits=4)
print('report=',report)
true.extend(true_temp)
result.extend(result_temp)