Sklearn中不同的数据抽样验证方式
这里记录以下import语句的前4个抽样方法:
from sklearn.model_selection import (train_test_split,
KFold,
StratifiedKFold,
StratifiedShuffleSplit,
ShuffleSplit,
GroupShuffleSplit,
GroupKFold,
TimeSeriesSplit)
1. 普通交叉随机抽样验证:train_test_split():
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
2. K折交叉抽样验证:KFold():
如下为,4折交叉验证,这4份都是互不相交的,等比例的。
参数含义:
1.n_split: 将数据集切分成n_split等份。
2.shuffle: 在切分n_split等份之前是否打乱。
3.4.random_state: 随机种子。当shuffle=True才有用,设置一样的random_state可以保持抽样到的数据一样。
kf = KFold(n_splits=2)
for train_index, test_index in kf.split(X):
#得到的train_index, test_index是索引
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]

3. 分层K折抽样验证:StratifiedKFold():
StratifiedKFold分层采样,用于交叉验证:与KFold最大的差异在于,StratifiedKFold方法是根据标签中不同类别占比来进行拆分数据的,可以使各个分组中各类别比例与原始样本中各类别的比例保持一致。

参数含义:
1.n_split: 将每个类别切分成n_split等份。
2.shuffle: 在切分n_split等份之前是否打乱。
3.4.random_state: 随机种子。当shuffle=True才有用,设置一样的random_state可以保持抽样到的数据一样。
skf = StratifiedKFold(n_splits=2)
for train_index, test_index in skf.split(X, y):
#得到的train_index, test_index是索引
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
4. 分层随机抽样验证:StratifiedShuffleSplit():
StratifiedKFold和ShuffleSplit的最大不同就是,StratifiedKFold进行n_split划分,每次的划分数据都不会重复,而ShuffleSplit的会有重复的;
分层抽样StratifiedKFold和ShuffleSplit都可以使各个分组中各类别比例与原始样本中各类别的比例保持一致。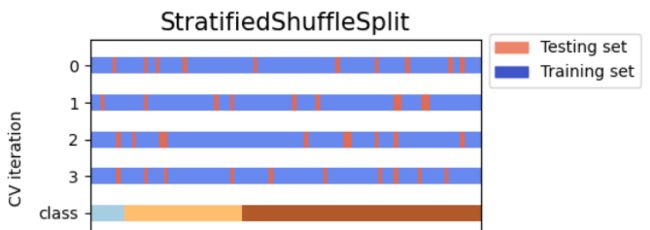
参数含义:
1.n_split: 进行n_split次抽样。
2.test_size: 设置每次抽样中各类别的测试集所占比例。
3.train_size: 与test_size互补。
4.random_state: 随机种子,设置一样的random_state可以保持抽样到的数据一样。
sss = StratifiedShuffleSplit(n_splits=5, test_size=0.5, random_state=0)
for train_index, test_index in sss.split(X, y):
#得到的train_index, test_index是索引
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
指标验证方式:
上面的验证方式可以通过每次在for循环里进行训练集来训练,测试集来测试各种指标。
还可用这种方式:cross_val_score()
参数含义:
1.x
2.y
3.scoring:指定测试指标,链接: https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
4.cv:默认是5折交叉验证。如果是int, 则为分层K折抽样StratifiedKFold()。也可是一个已经切分好的数据集的索引。
也可传入一个split对象。
5.等等还有一些参数…具体看手册
from sklearn.model_selection import cross_val_score
clf = svm.SVC(kernel='linear', C=1)
cv = KFold(n_splits=3)
scores = cross_val_score(clf, iris.data, iris.target, cv=cv, scoring='recall_micro')
#因为不是2分类问题,不能直接用recall,可以用'micro', 'macro', 'weighted'这3种
#'micro':通过先计算总体的TP,FN和FP的数量,再计算recall
#'macro':分布计算每个类别的recall,然后做平均(各类别recall的权重相同)
#weighted:分布计算每个类别的recall,在计算均值时乘以各类别数据所占的权重
Reference: https://scikit-learn.org/stable/modules/classes.html