kaggle实战之Titanic - Machine Learning from Disaster
很多小伙伴在学习完数据分析和机器学习之后想找一些项目进行实战训练,不仅可以巩固自己的知识,还可以学习到新的技能来扩展自己的技能树。kaggle、天池、DF、DC等等都是一些很不错的竞赛学习网站,特别是kaggle和天池含金量很高,如果你能够在这两个竞赛中取得一个不错的成绩那么在面试中是一个很大的加分项。这些网站不仅可以锻炼自己的竞赛水平,而且可以学习到很多实用的算法和方法,如当我们使用RF、GBDT时,别人已经用lightgbm和xgboost大杀四方。当然这两个非常厉害算法后续也会推出使用方法。

在第一次对数据分析时,很多人面对这些数据都会无从下手,不知道问题的切入点在哪里。我们就从kaggle上经典的Titanic项目来进行一个简单的分析。这个项目的是需要我们通过他给的数据集来预测哪种人更容易存活,这便是我们分析的切入点。再对数据清洗之后选取数据集中的目标特征,然后选择合适的算法进行预测,最后将预测结果上传至kaggle得到自己的排名。
竞赛流程如下:
问题建模--->数据探索--->特征工程--->模型训练--->模型融合
在拿到数据集后第一件事就是问题建模,同时完成baseline的pipeline搭建。接下里可以考虑评价指标,分类问题指标包括AUC、ROC、f1-score、准确率、召回率等等,一般前三个用的比较多;回归指标则有平均绝对误差、均方误差、均方根误差等。大家用的模型基本上都是一样的,参数无非就是那么几个,所以特征工程对于模型的精确度则是尤为重要。数据和特征决定了机器学习的上限,而算法只是为了逼近这个算法而已,由此可以见特征工程的重要性。
说了这么多,相信大家心里已经有了一个基本的思路,我们现在就来对Titanic数据集进行分析。

1.拿到数据集之后我们先大概观察一下数据,看看哪些特征是我们想要的。
import pandas as pd
train = pd.read_csv('t_train.csv')
train.head()
还好这些特征并不是很多,如果一个数据集特征非常的多的话并且自己又不知道使用哪些数据,如果挨个试的话太费事费力了,此时我们则可以采用自动化特征选择来判断每一个特征的作用从而更好的帮助我们进行选择合适的特征。(因为titanic数据集的特征很少,我们可以选取所有的特征)
train.info()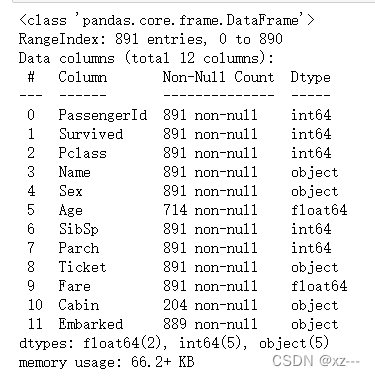
现在我们可以清楚的看到数据集的详细情况,如长度、特征的属性等待。
2.在了解数据之后,我们应该进行数据预处理,查看数据集的完整性。
train.isnull().sum() 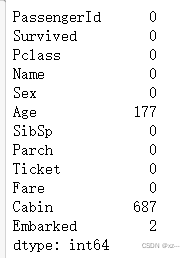
现在可以看到Age和Cabin这两列有缺失,那我们想办法给他补齐。
train['Age'].fillna(train['Age'].mean(), inplace=True)
train.isnull().sum()
同样,如果你觉得通过数字展示数据过于单调,我们也可以通过使用数据可视化这个方法。
missing = train.isnull().sum()
missingg = missing[missing>0]
missing.sort_values(inplace=True)
for i, j in enumerate(missing):
plt.text(i, j, str(j), ha='center')
missing.plot.bar()
如图所示,我们就可以清晰得看到哪些特征拥有缺失值,因为Embarked缺失值数量过少,可能在图表中不能显示 ,因此我们选择在bar图上添加数字来提醒我们。
对数据填补之后我们发现Age列已经被填补完成。有人会问了为什么Cabin列没有被填充?是因为Cabin列是分类特征,我们需要将他转化为连续特征只有才可以进行填充。分类转换为连续特征推荐使用get_dummies()或onehotencoder。
姓名、机票、PassengerId这些特征在我们主管判断对于模型没有什么用,所以应当选择将其删除掉,Survived特征列要作为我们的label,所以我们选择保留下来,
train.drop(['PassengerId', 'Name', 'Ticket'], axis=1, inplace=True)
train.head()
操作结束之后我们来查看去除之后的结果,符合我们的预期。
现在对Sex、Cabin、Embarked这些分类变量转换为连续值,可以使用OneHotEncoder也可以是get_dummies。
X_train_dummies = pd.get_dummies(train)
X_train_dummies.head()
现在已经将数据变换成了我们想要的。
那如果数据中特征非常之多,我们应该如何选取呢?在这里我是用单变量统计进行特征选择。
还有基于模型的特征选择、迭代特征选择等方法。
X_train_dummies = pd.get_dummies(train)
X_train_dummies.head()
y_dummies = X_train_dummies.columns
from sklearn.feature_selection import SelectPercentile
select = SelectPercentile(percentile=60)
select.fit(X_train_dummies, y)
X_dummies = select.transform(X_train_dummies)
y_dummies[select.get_support()] 
这些便是我们要选择的特征,因为该数据集特征很少,所以我们也可以将特征全部选取。
3.建立模型
数据处理完成之后,我们便可以根据数据建立模型。
未完待续