Person_reID_baseline_pytorch 源码解析之 prepare.py
源码解析之数据处理
- 1. prepare.py 脚本的运行效果
- 2. prepare.py 脚本的作用
-
- 2.1 ImageFolder 的使用
- 2.2 Market 1501 数据集重构
- 3. prepare.py 源码解析
-
- 3.1 train_all 代码
- 3.2 文件处理函数
- 3.3 train_val 代码
- 参考文献
prepare.py 是用来处理数据的一个脚本,本文将从脚本的运行效果,脚本的作用以及脚本源码等方面对脚本 prepare.py 进行解析。
1. prepare.py 脚本的运行效果
在进行源码解析前,先来看下 prepare.py 脚本的运行效果。
从官网下载到的 Market 1501 数据集结构如下图所示。主要包括测试集、训练集、query 集 和 multi-query 集(gt_bbox)。

运行 prepare.py 脚本后,数据集的结构将发生改变,生成新的适用于 pytorch 框架的数据集。数据集的内容并没有发生改变,只是数据集的分布结构发生了改变。
新建一个名为 pytorch 的文件夹,作为重构数据集的根目录,pytorch 格式的 Market 1501 数据存储在这个文件夹下。其中,train_all 是重构后的训练全集,包括 训练集 bounding_box_train 的所有图片;gallery 集包含了测试集 bounding_box_test 的所有图片;query 集和之前相同,包含了所有待测行人的图片;train 和 val 则是训练集 bounding_box_train 的两个子集, val 中包含了所有训练集行人 ID 类别的第一张图片,train 则包含了 bounding_box_train 剩余的行人图片。

2. prepare.py 脚本的作用
运行 prepare.py 脚本后,数据集的结构发生了变化。那么为什么要执行 prepare.py 脚本呢?为什么要改变数据集的结构呢?
因为我们希望更加方便地将数据集载入网络模型。数据集一般以图片形式保存,网络训练时则需要转换为 numpy 格式或者 tensor 格式载入网络,进行深度学习网络模型训练。使用深度学习框架提供的一些数据处理的高级 API 将极大简化上述数据处理过程。当然,使用这些 API 也需要满足一些前提条件。
baseline 中就使用了 pytorch 框架的高级数据处理 API。 torchvision.datasets.ImageFolder 是 pytorch 框架下的一个通用的数据加载器,可以方便地生成 pytorch 支持的数据集格式。使用 ImageFolder 的前提条件就是将数据集组织成要求的结构。下面来进一步了解 ImageFolder 。
2.1 ImageFolder 的使用
从 torchvision 中导入 datasets 后,就可以使用 ImageFolder API 了。
from torchvision import datasets, transforms
dset = datasets.ImageFolder(root='root_path', transform=None, loader=default_loader)
API 参数说明:
- root 指数据集存放的根目录
- transform 指对图片进行的图像变换(增强)
- loader 指数据集的加载方式,一般为默认参数,不进行设置
要想使用 torchvision.datasets.ImageFolder ,需要按照以下格式将图片组织成数据集。
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
root 为数据集的根目录,dog 或 cat 是数据集图片的类别。也就是说图片需要按照类别存储在以分类为名称的文件夹下。
2.2 Market 1501 数据集重构
baseline 中用到的数据子集主要包括测试集、训练集、query 集 和 multi-query 集(gt_bbox)。下面以训练集为例,说明数据集的重构过程。
重构前,训练集 bounding_box_train 里面全是行人图片。
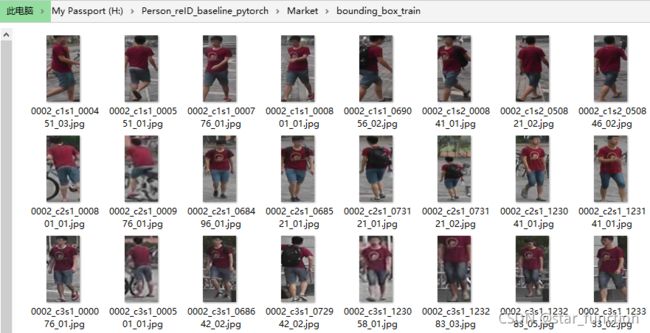
为了使用 ImageFolder API,需要将训练集 bounding_box_train 重新组织成如下结构。 其中 train_all 是新的训练集的根目录,0002 是行人 ID(类别),0002_c1s1_000451_03.jpg 是行人图片。
train_all/0002/0002_c1s1_000451_03.jpg
train_all/0002/0002_c1s1_000551_01.jpg
train_all/0002/0002_c1s1_000776_01.jpg
...
train_all/0007/0007_c1s6_028546_01.jpg
train_all/0007/0007_c1s6_028546_04.jpg
...
train_all/0010/0010_c1s6_027271_05.jpg
train_all/0010/0010_c1s6_027296_01.jpg
...
重构后,行人依照行人 ID 被存储在不同的类别文件夹下。train_all 文件夹是训练数据集的根目录, 0002 文件夹为行人类别。
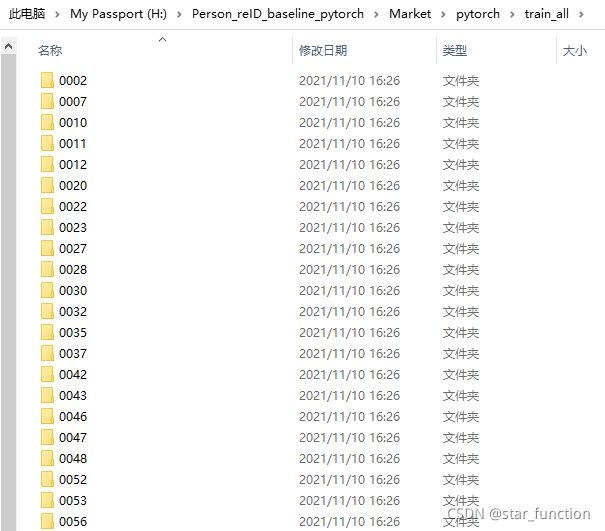
0002 文件夹下存储着 ID 为 0002 的所有行人图片。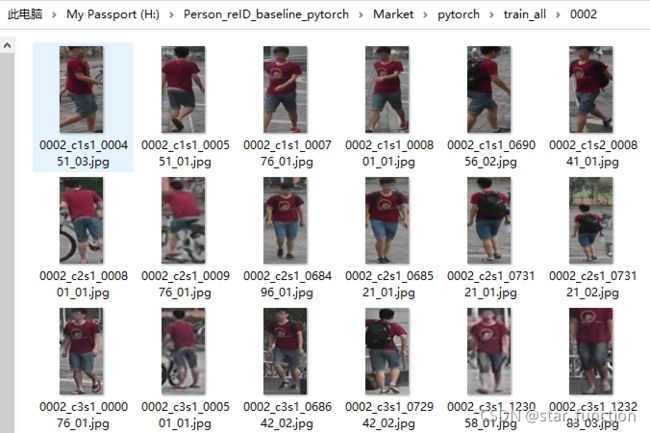
3. prepare.py 源码解析
将 Market 1501 数据集组织成 pytorch 框架支持的数据集格式,就可以调用 pytorch 数据处理 API - torchvision.datasets.ImageFolder 了。
那么问题来了,怎样才能将数据集重构成要求的格式呢?
prepare.py 脚本就是用于完成数据集重构的,执行 prepare.py 脚本就可以了。
下面,我们通过源码解析来看看 prepare.py 是如何实现数据集重构的。
其实,train_all、train_val、 gallery、query 和 multi-query 的处理代码是大致相同的,因此就以 train_all 和 train_val 部分的代码进行解析。
3.1 train_all 代码
train_all 部分的代码主要实现的逻辑是将原来的训练集 bounding_box_train 中的图片,按照行人 ID 类别存储到对应的类别文件夹中,并将所有类别文件夹放入一个名为 train_all 的文件夹下。当然,最终 train_all 文件夹也要放到重构后数据集的根目录 pytorch 中。
#---------------------------------------
#train_all
// download_path 是原始 Market 1501 数据集的存放位置
download_path = 'Market'
train_path = download_path + '/bounding_box_train'
train_save_path = download_path + '/pytorch/train_all'
if not os.path.isdir(train_save_path):
os.mkdir(train_save_path)
for root, dirs, files in os.walk(train_path, topdown=True):
for name in files:
// 如果不是 jpg 文件则跳过
if not name[-3:]=='jpg':
continue
// 分离 ID 号
ID = name.split('_')
src_path = train_path + '/' + name
dst_path = train_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
// 将图片 copy 到目标文件夹下
copyfile(src_path, dst_path + '/' + name)
这里主要需要解决的问题是,根据行人 ID 将行人图片划分到不同类别的文件夹下。
行人图片的名称中含有 ID 信息,如 0002_c1s1_000451_03.jpg 就是 ID 为 0002 的行人图片。因此通过行人名称即可将行人分入对应行人 ID 的文件夹中。
3.2 文件处理函数
处理过程中主要用到了以下文件处理函数:
- os.path.isdir(path) :判断path是否为文件夹(目录)
- os.mkdir :创建目录
- os.walk:遍历指定目录下的子目录和文件
for root, dirs, files in os.walk(train_path, topdown=True):
os.walk 将遍历 train_path 下的所有子目录和文件,而且是逐层遍历。
root 为当前根目录,dirs 是当前根目录 root 下的所有子目录,files 是当前根目录下包含的所有文件。需要注意的是,root 目录会逐层下移,扫描它的子目录。Python中os.walk()的使用方法 详细地解释了 os.walk() 函数的使用,给出了下面的例子

# 使用os.walk扫描目录
import os
for curDir, dirs, files in os.walk("test"):
print("====================")
print("现在的目录:" + curDir)
print("该目录下包含的子目录:" + str(dirs))
print("该目录下包含的文件:" + str(files))

3.3 train_val 代码
train_val 部分代码和 train_all 部分代码大致相同。train_all 代码将生成 train_all 文件夹,包含 bounding_box_train 中的所有训练图片。train_val 代码将生成 train 和 val 两个文件夹,它们是 bounding_box_train 的子集。train 用来训练,val 用来验证,二者都在训练模型过程中使用。选取训练行人 ID 的第一张图片构成 val,剩余训练集图片构成 train。
#---------------------------------------
#train_val
// download_path 是原始 Market 1501 数据集的存放位置
download_path = 'Market'
train_path = download_path + '/bounding_box_train'
train_save_path = download_path + '/pytorch/train'
val_save_path = download_path + '/pytorch/val'
if not os.path.isdir(train_save_path):
os.mkdir(train_save_path)
os.mkdir(val_save_path)
for root, dirs, files in os.walk(train_path, topdown=True):
for name in files:
if not name[-3:]=='jpg':
continue
ID = name.split('_')
src_path = train_path + '/' + name
dst_path = train_save_path + '/' + ID[0]
if not os.path.isdir(dst_path):
os.mkdir(dst_path)
dst_path = val_save_path + '/' + ID[0] #first image is used as val image
os.mkdir(dst_path)
copyfile(src_path, dst_path + '/' + name)
参考文献
- pytorch学习笔记七:torchvision.datasets.ImageFolder使用详解
- PyTorch 中文文档
- Python中os.walk()的使用方法
- 从零开始行人重识别