CROSSFORMER: A VERSATILE VISION TRANSFORMER BASED ON CROSS-SCALE ATTENTION
CrossFormer:A Versatile vision transformer Based on cross-scale attention
(一种基于跨尺度注意力的多功能视觉transformer)
(浙江大学、哥伦比亚大学、腾讯数据平台)
Abstract
Transformers在处理视觉任务方面取得了很大进展。然而,现有的vision transformer仍然不具备一种对视觉输入很重要的能力:在不同尺度的特征之间建立注意力。造成这一问题的原因有两方面:(1)各层的输入嵌入是等尺度的,没有跨尺度特征;(2)一些vision transformers牺牲了嵌入的小尺度特征,以降低自我注意模块的成本。为了弥补这一缺陷,我们提出了跨尺度嵌入层(CEL)和长短距离注意(LSDA)。特别是,CEL将每个嵌入与不同尺度的多个patch混合在一起,为模型提供了跨尺度嵌入。LSDA将自我注意模块分成短距离和长距离两个模块,既降低了成本,又保留了小尺度和大尺度的嵌入特征。通过这两个设计,我们实现了跨尺度的关注。此外,我们还提出了vision transformer的动态位置偏差,使流行的相对位置偏差适用于可变尺寸的图像。在这些模块的基础上,我们构建了我们的视觉架构CrossFormer。实验表明,CrossFormer在几个典型的视觉任务,特别是目标检测和分割方面优于其他转换器。代码已经发布:https://github.com/cheerss/CrossFormer
Introduction
Transformer(V Aswani等人,2017年;Devlin等人,2019年;Brown等人,2020年)在自然语言处理(NLP)方面取得了巨大成功。得益于它的自我注意模块,Transformer天生就具有建立远程依赖的能力,这对许多视觉任务也很重要。因此,已经进行了大量的研究(Dosovitski等人,2021;Touvron等人,2021;Wang等人,2021)来探索基于transformer的视觉体系结构。
transformers需要一系列嵌入(例如,单词嵌入)作为输入。为了使其适应视觉任务,大多数现有的vision transformers(Dosovitski等人,2021年;Touvron等人,2021年;Wang等人,2021年;Liu等人,2021b)通过将图像分割成相等大小的块来产生嵌入。例如,一幅224×224的图像可以被分割成大小为4×4的56×56块,然后这些块通过线性层投影成为嵌入序列。在transformer内部,自我关注模块可以在任何两个嵌入之间建立依赖关系。不幸的是,vanilla(初始的)自我注意的存储和计算成本对于视觉任务来说太大了(Dosovitski等人,2021年;Touvron等人,2021年),因为视觉嵌入的序列长度比NLP长得多。因此,许多替代品(Wang等人,2021;Liu等人,2021b;Lin等人,2021)被提出以更低的成本近似vanilla(初始的)自我注意模块。
虽然上述工作取得了一定的进展,但现有的vision transformers仍然存在一个制约其性能的问题–未能在不同尺度的特征之间建立关注度,而这种能力对于视觉任务来说是非常重要的。例如,一幅图像通常包含许多不同尺度的对象,建立它们之间的关系需要跨尺度的注意机制。此外,一些任务,如实例分割,需要大规模(粗粒度)特征和小规模(细粒度)特征之间的交互。现有的vision transformers无法处理这些情况的原因有两个:(1)嵌入序列是由大小相等的块生成的,因此同一层中的嵌入只具有单一尺度的特征。(2)在自我注意模块内部,相邻嵌入的键/值经常被合并(Wang等人,2021;Chu等人,2021),以降低成本。因此,即使嵌入同时具有小尺度和大尺度特征,合并操作也会丢失每个单个嵌入的小尺度(细粒度)特征,从而使跨尺度注意力失效。
为了解决这个问题,我们共同设计了嵌入层和自我注意模块如下:(1)跨尺度嵌入层(CEL)-紧随Wang等人(2021),我们的transformer也采用了金字塔结构,这自然会将模型分成多个阶段。CEL出现在每个阶段的开始处。它接收上一阶段的输出(或图像)作为输入,采样具有不同尺度(例如,4×4、8×8等)的多个核的patch。然后,每个嵌入都是通过投影和连接这些patch来构建的,而不是只使用一个单一比例的。(2)长短距离注意(LSDA)-我们还提出了一种替代vanilla(初始的)自我注意的方法,但为了保留小尺度特征,嵌入(以及它们的键/值)不会合并。相反,我们将自我注意模块分为短距离注意(SDA)和长距离注意(LDA)。SDA建立相邻嵌入之间的依赖关系,而LDA负责远离彼此的嵌入之间的依赖关系。LSDA还降低了自我注意模块的成本,但与其他模块不同的是,LSDA既不损害小规模的特征,也不损害大规模的特征,因此可以关注跨尺度的交互。
此外,相对位置偏差(RPB)(Shaw等人,2018年)是vision transformer的一种有效位置表征。然而,它仅适用于输入图像/组大小固定的情况,这不适用于像物体检测这样的多任务。为了使算法更加灵活,我们引入了动态位置偏置(DPB)训练模块,它接受两个嵌入的距离作为输入,并输出它们的位置偏差。该模块在训练阶段进行了端到端的优化,代价可以忽略不计,但使RPB适用于不同的图像/组大小。
我们建议的每个模块都可以用大约十行代码来实现。在此基础上,我们构造了四种大小不一的多功能视觉转换器CrossFormer。在四个典型的视觉任务(即图像分类、对象检测和实例/语义分割)上的实验表明,CrossFormers在所有这些任务上都优于以往的视觉转换器,特别是密集预测任务(对象检测和实例/语义分割)。我们认为这是因为图像分类只关注一个对象和大尺度特征,而密集预测任务更多地依赖于跨尺度关注。
值得一提的是,我们的贡献如下:
- 我们提出了跨尺度嵌入层(CEL)和长短距离注意(LSDA),弥补了以往体系结构在构建跨尺度注意方面的不足。
- 提出了动态位置偏置模块(DPB),使相对位置偏置更加灵活,适用于不同的图像大小或组大小。
- 构造了几个不同大小的CrossFormer,并通过对四个典型视觉任务的充分实验验证了它们的有效性。
Background
Vision Transformers
受自然语言处理的transformers的启发,研究人员为视觉任务设计了vision transformer,以利用其巨大的注意机制。特别是,ViT(Dosovitski等人,2021年)和DeiT(Touvron等人,2021年)将原始transformer转移到视觉任务,实现了令人印象深刻的准确性。后来,PVT(Wang等人,2021年)、HVT(Pan等人,2021年)、Swin(Liu等人,2021b)等将金字塔结构引入变压器,大大减少了模型后续层的patch数量。它们还将transformer扩展到其他任务,如对象检测和分割(Wang等人,2021年;Liu等人,2021b)。
Self-attention and Its Variants(自注意机制和它的变体)
作为transformers的核心,自我注意模块的计算和存储开销为O(N2),其中N为嵌入序列的长度。虽然这样的成本对于图像分类是可以接受的,但对于具有大得多的输入图像(例如,对象检测和分割)的其他任务则不是这种情况。为了解决这个问题,Swin(Liu et al.,2021b)限制了对局部区域的注意,放弃了远程依赖。PVT(Wang等人,2021年)和Twin(Chu等人,2021年)使相邻嵌入共享相同的键/值,以降低成本。同样,其他vision transformer(Chen等人,2021a;Zhang等人,2021b;Wu等人,2021年)也采用分而治之的方法,以较低的成本接近vanilla(初始的)自我注意。限制了局部地区的注意力,放弃了异地依赖。
Position representations
transformer是组合不变的,也就是说,打乱输入嵌入不会改变transformer的输出。然而,嵌入的位置也包含重要信息。为了使该模型意识到这一点,提出了许多不同的嵌入位置表示(Vaswani等人,2017;Dosovitski等人,2021),其中相对位置偏差(RPB)(Shaw等人,2018年)就是其中之一。对于RPB,每对嵌入都会在它们的注意力上添加一个偏差,这表示它们之间的相对距离。在以前的工作中,RPB被证明比其他位置表征对视觉任务更有效(Liu等人,2021b;Chen等人,2021b)。
CrossFormer
CrossFormer的整体架构如图1所示。继(Wang等人,2021年;Liu等人,2021b;Lin等人,2021年)之后,CrossFormer也采用了金字塔结构,这自然地将模型分为四个阶段。每个阶段由一个跨尺度嵌入层(CEL)和几个CrossFormer block组成。CEL接收上一阶段的输出(或图像)作为输入,并生成跨尺度嵌入。在这个过程中,CEL(第一阶段除外)将金字塔结构的嵌入次数减少到四分之一,而将其维数增加了一倍。然后,在CEL之后放置几个CrossFormer块(包含LSDA和DPB)。在特定任务的最后阶段之后,紧随其后的是专门的头部(例如,分类头部)。

图1:(a)用于分类的CrossFormer架构。输入大小为H0×W0,每个阶段的特征地图大小显示在顶部。第一阶段由CEL和ni个CrossFormer块组成。单元中的数字表示使用过的内核的大小。(b)两个连续的CrossFormer区块的内部结构SDA和LDA交替出现在不同的区块中。
Cross-Scale Embedding Layer(CEL)
跨尺度嵌入层用于生成每个阶段的输入嵌入。图2以第一个CEL为例,它位于Stage-1之前。它接收一幅图像作为输入,使用四个不同大小的内核对patch进行采样。四个内核的步长保持相同,以便它们生成相同数量的嵌入。正如我们在图2中看到的,每四个相应的patch具有相同的中心但不同的比例。这四个patch将被投影并连接为一个嵌入。在实际应用中,采样和投影过程可以通过四层卷积来实现。

对于跨尺度嵌入,一个问题是如何设置每个尺度的投影尺寸。考虑到较大的核更容易导致较大的计算量,我们对较大的核使用较低的维数,而对较小的核使用较高的维数。图2在其子表中提供了具体的分配规则,并给出了一个128维的示例。与平均分配维数相比,我们的方案节省了大量的计算开销,但不会明显影响模型的性能。其他阶段中的跨比例嵌入层的工作方式与此类似。如图1所示,阶段2/3/4中的CEL使用两个内核(2×2和4×4)。步长设置为2×2,以将嵌入次数减少到四分之一(相较于步长为1x1来说)。
CrossFormer Block
每个CrossFormer模块由短距离注意(SDA)或长距离注意(LDA)模块和多层感知器(MLP)组成。特别是,如图1(b)所示,SDA和LDA交替出现在不同的块中,动态位置偏置(DPB)在SDA和LDA中都适用于嵌入的位置表示。此外,在块中使用残差连接。
LONG SHORT DISTANCE ATTENTION (LSDA)
我们将自我注意模块分为两部分:短距离注意(SDA)和长距离注意(LDA)。对于SDA,每个G×G相邻嵌入被分组在一起。图3(a)给出了当G=3时的例子。对于输入大小为S×S的LDA,以固定间隔I对嵌入进行采样。例如,在图3(b)(I=3)中,所有具有红边的嵌入属于一组,而具有黄色边框的嵌入属于另一组。LDA的组高度/宽度计算为G=S/I,在本例中为G=3。在对嵌入进行分组后,SDA和LDA都在每个组中使用了普通的自我注意模块。结果,自我注意模块的存储和计算成本从O(S4)降低到O(S2G2)。
在图3(b)中,我们绘制了两个嵌入的组件patch。由此可见,两个嵌入体的小比例patch是不相邻的,没有大比例patch的帮助很难判断它们之间的关系。因此,如果这两个嵌入仅由小规模的patch构建,将很难在它们之间建立依赖关系。相反,相邻的大型patch提供了足够的上下文来链接这两个嵌入。因此,在大规模patch的引导下,远程跨尺度的关注变得更容易、更有意义。(解释一下,图3(b)中右侧的猫咪patch,如果只有最上面的两个patch,无法确定它们之间的相对位置关系,但是有了中间和下面的patch,我们就知道了最上面的两个patch是相邻的两个大patch中的一部分。)
我们在附录(A.1)中提供了LSDA的伪代码。基于普通多头自关注,LSDA只需10行代码即可实现。此外,只使用reshape和permute操作,不会产生额外的计算成本。

Dynamic Position Bias(DPB)
相对位置偏差(Relative Position Bias,RPB)通过增加嵌入对象注意力的偏差来表示嵌入对象的相对位置。正式地说,LSDA与RPB的注意力图变成了:
![]()
其中Q、K、V∈RG2×D分别表示自我注意模块中的query、key、value,√d是常量归一化子。B∈RG2×G2是RPB矩阵。在前人的工作(刘等,2021b)中,Bi,j=ˆB∆xij,∆yij,其中ˆB是一个固定大小的矩阵,(∆xij,∆yij)是第i个和第j个嵌入之间的坐标距离。很明显,在(∆xij,∆yij)超过ˆB的大小的情况下,图像/组的大小受到限制(也就是说,图像/组的大小不能超过^B的大小)。相反,我们提出了一种称为DPB的基于mlp的模块来动态地产生相对位置偏差,即,
![]()
DPB的结构如图3(c)所示。其非线性变换由三个带有层归一化(Ba等人,2016)和RELU(Nair&Hinton,2010)的完全连通的层组成。DPB的输入维度为2,即(∆xij,∆yij),中间层的维度设置为D/4,其中D是嵌入的维度。DPB是一个与整个模型一起优化的可培训模块。它可以处理任何图像/组大小,而无需担心(∆xij,∆yij)的界限。
在附录(A.2)中,我们证明了当图像/组大小固定时,DPB等价于相对位置偏差。在这种情况下,我们可以在测试阶段将训练好的DPB转换为相对位置偏差。我们还给出了当图像/组大小可变(由于B∈RG2×G2,在正常情况下复杂度为O(G4))时DPB的一个有效的O(G2)实现。
Variants of CrossFormer
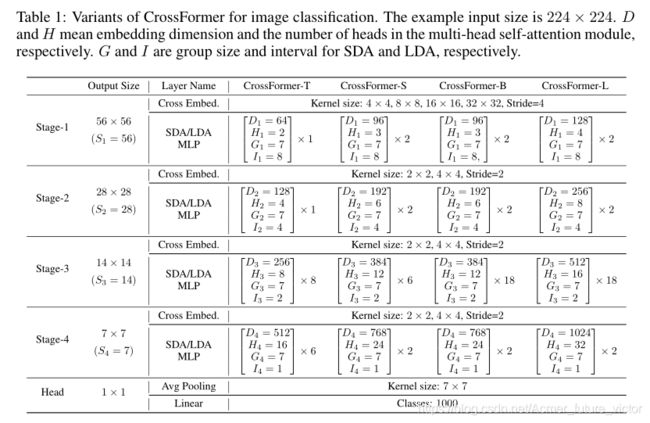
表1列出了CrossFormer用于图像分类的四个变体(-T、-S、-B和-L,分别代表极小、小、基础和大)的详细配置。为了重用预先训练的权重,用于其他任务的模型使用与分类相同的主干,除了它们可能使用不同的G和I。具体地说,除了与分类相同的配置外,我们还使用G1=G2=14、I1=16和I2=8测试检测/分割模型的前两个阶段,以适应更大的图像。具体架构载于附录(A.3)。值得注意的是,组大小(即G和I)不影响权重张量的形状,因此在ImageNet上预先训练的主干可以直接在其他任务上进行微调,即使它们使用不同的(G,I)。
表1:用于图像分类的CrossFormer变体。示例输入大小为224×224。D和H分别表示多头注意模块的嵌入维数和头数。G和I分别是SDA和LDA的组大小和间隔。
Experiments
在图像分类、目标检测、实例分割、语义分割等方面进行了实验。为了进行公平的比较,我们尽可能地对其他vision transformers保持相同的数据增强和训练设置。比较的算法都是竞争性视vision transformer,包括DeiT(Touvron等人,2021年)、PVT(Wang等人,2021年)、T2T-ViT(袁等人,2021年)、TNT(han等人,2021年)、CViT(Chen等人,2021a)、Twin(Chu等人,2021年)、Swin(Liu等人,2021b)、NesT(Zhang等人,2021b)、CVT。2021年)、TransCNN(Liu等人,2021a)、Shuffle(Huang等人,2021年)、BoTNet(Srinivas等人,2021年)和RegionViT(Chen等人,2021b)。
Image Classification
Experimental Settings
分类实验是使用ImageNet(Russakovsky等人,2015)数据集进行的。模型在1.28M训练图像上进行训练,并在50K验证图像上进行测试。使用与其他vision transformer相同的训练设置。特别是,我们使用AdamW(Kingma&Ba,2015)优化器训练300个epoch,使用余弦衰减学习率调度器,并使用20个epoch的线性预热。batch size为1024个,拆分在8个V100 GPU上。使用0.001的初始学习率和0.05%的权重衰减率。此外,对于CrossFormer-T、CrossFormer-S、CrossFormer-B、CrossFormer-L,我们分别使用0.1、0.2、0.3、0.5的丢弃路径速率。此外,类似于Swin(Liu等人,2021b)、RandAugment(Cubuk等人,2020)、Mixup(Zhang等人,2018)、CutMix(Yun等人,2019年)、随机擦除(钟等人,2020)和随机深度(Huang等人,2016)被用于数据增强。
Results
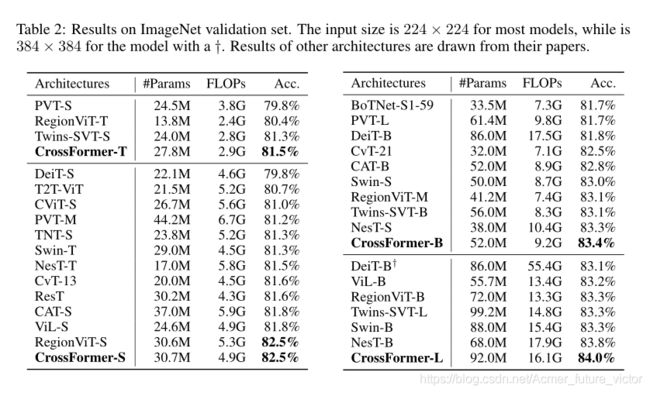
结果如表2所示。正如我们可以看到的那样,CrossFormer在相似的参数和FLOPs的情况下达到了最高的准确率。特别是,与流行的DeiT(Touvron等人,2021年)、PVT(Wang等人,2021年)和Swin(Liu等人,2021b)相比,我们在小模型上的准确率至少高出1.2%。此外,尽管RegionViT在小型模型上与我们达到了相同的准确率(82.5%),但在大型模型上比我们低0.7%(84.0%对83.3%)。
Object Detection and instance segmentation
Experimental settings
目标检测和实例分割的实验都是使用COCO 2017数据集(Lin等人,2014)进行的,该数据集包含118K训练图像和5K验证图像。我们使用基于MMDetect的(Chen等人,2019年)RetinaNet(Lin等人,2020年)和Mask-RCNN(He等人,2017年)作为对象检测或实例分割的头部。对于这两个任务,主干都使用在ImageNet上预先训练的权重进行初始化。检测/分割模型在8个V100GPU上以batch size为16进行训练,并使用初始学习率为1×10−4的adamW优化器。在前人工作的基础上,我们采用了1×训练方案,即对模型进行12个epoch的训练,对图像的短边调整到800像素。
Results
结果放在表3中。正如我们可以看到的那样,排在第二位的体系结构随着实验的进行而变化,也就是说,这些体系结构可能在一个任务中表现良好,但在另一个任务中表现不佳。相比之下,我们在任务(检测和分割)和两个模型大小(小的和基本的)上都优于所有其他人。此外,当扩展模型时,CrossFormer相对于其他体系结构的性能增益会增加,这表明CrossFormer具有更高的潜力。
表3:Coco Val 2017上的对象检测和实例分割结果。Swin(Liu等人,2021b)的结果取自Twin(Chu等人,2021年),因为Swin没有在RetinaNet和Mask-RCNN上报告结果。蓝色字体的结果排在第二位。如附录(A.3)所述,具有‡的交叉组合使用与分类模型不同的组大小。

Semantic Segmentation
Experimental Settings
ADE20K(周等人,2017)被用作语义切分的基准。它涵盖了150个语义类别的广泛范围,包括用于训练的20K图像和用于验证的2K图像。与检测模型类似,我们用在ImageNet上预先训练的权重来初始化主干,并以基于MMS监管(贡献者,2020)的语义FPN和UPerNet(肖等人,2018年)作为分割头。对于FPN(Kirillov等人,2019年),我们使用学习率和权重敏感度为1×10−4的AdamW优化器。模型被训练为80K迭代,batch size为16。对于UPernet,我们使用初始学习率为6×10−5,权重衰减为0.01的AdamW优化器,模型被训练为160K迭代。
Results
结果如表4所示。与目标检测类似,CrossFormer在放大模型时表现出比其他算法更大的性能增益。例如,CrossFormer-T的IOU比TwinsSVT-B高1.4%,但CrossFormer-B的IOU比TwinsSVT-L高3.1%。此外,CrossFormer在密集预测任务(如检测和分割)上比在分类上表现出更显著的优势,这表明注意模块中的跨尺度交互对于密集预测任务比对分类更重要。
表4:ADE20K验证集上的语义分割结果。“MS IOU”表示可变输入大小的测试。

Ablation Studies
Cross-scale Embeddings vs. Single-scale Embeddings.
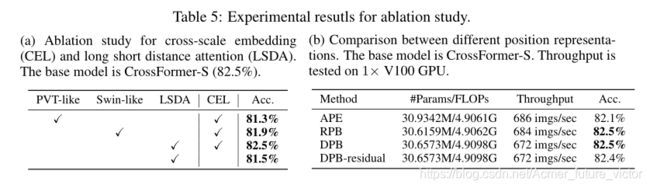
我们通过将所有跨尺度的嵌入层替换为单尺度的嵌入层来进行实验。单尺度嵌入意味着只有一个核(Stage1为4×4,其他Stage为2×2)用于模型中的四个CEL。表5a中的结果表明,跨尺度嵌入获得了很大的性能增益,即它比没有跨尺度嵌入的模型的准确率高0.9%。更多关于CEL的消融研究见附录(B.1)。
LSDA vs. Other Self-attentions
比较了PVT和Swin中使用的两种自关注模块。具体地说,PVT在计算自我注意时牺牲了小范围的信息,而Swin将自我注意限制在局部区域,放弃了远程注意。如表5a所示,与PVT和Swin类自我注意机制相比,我们的准确率至少高出0.6%。结果表明,长短距离的自我注意最有利于提高模型的绩效。
DPB vs. Other Position Representations
我们比较了绝对位置嵌入(APE)、相对位置偏差(RPB)和DPB之间模型的参数、FLOP、吞吐量和精度,结果如表5b所示。DPB-residual表示具有残差连接的DPB。DPB和RPB均优于APE,准确率为0.4%。DPB实现了与RPB相同的精确度,但额外成本可以忽略不计,但是,正如我们在前面所描述的,它比RPB更灵活,并且适用于可变图像大小或组大小。此外,DPB中的剩余连接无助于提高模型的性能(82.5%比82.4%)。
Conclusion
我们提出了一种基于transformer的视觉架构,称为CrossFormer。其核心设计包括跨尺度嵌入层和长短距离注意(LSDA)模块。此外,我们提出了动态位置偏差(DPB),使相对位置偏差适用于任何输入大小。实验表明,CrossFormer在几个典型的视觉任务上取得了比其他vision transformer更好的性能。特别是CrossFormer算法在检测和分割方面有了较大幅度的提高,这表明跨尺度嵌入和LSDA对于密集预测视觉任务尤为重要。
A CrossFormer
A.1 LSDA的伪代码
LSDA的伪代码如算法1所示。正如我们所看到的,基于普通的自我注意模块,SDA和LDA都只用10行代码来实现,并且只使用了reshape和permute操作。

A.2 Dynamic Position Bias(DPB)
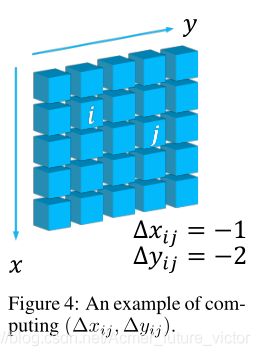
图4给出了在DPB模块中使用G=5计算(∆xij,∆yij)的示例。对于大小为G×G的群体,很容易推导出

因此,在相对位置偏差的激励下,我们构造了矩阵ˆB∈R(2G−1)×(2G−1),其中
![]()
计算ˆB的复杂度为O(G2)。然后,可以从ˆB中提取DPB中的偏置矩阵B,即,
![]()
当图像/组大小(即G)固定时,ˆB和B在测试阶段也将保持不变。因此,我们只需要计算一次ˆB和B,在这种情况下,DPB等同于相对位置偏差。
A.3 用于检测和分割的CROSSFORMER变体
我们针对密集预测任务测试了两个不同的主干。用于密集预测(目标检测、实例分割和语义分割)的CrossFormer的变体如表6所示。除了在前两个阶段使用不同的G和I之外,这些架构与用于图像分类的架构相同。值得注意的是,组大小(即G和I)不会影响权重张量的形状,因此在ImageNet上预先训练的骨干可以直接在其他任务上进行微调,即使他们使用不同的G和I。
表6:用于对象检测和语义/实例分割的基于CrossFormer的主干。示例输入大小为1280×800。D和H分别表示嵌入维度和多头自我注意模块中的头数。G和I分别是SDA和LDA的组大小和间隔。
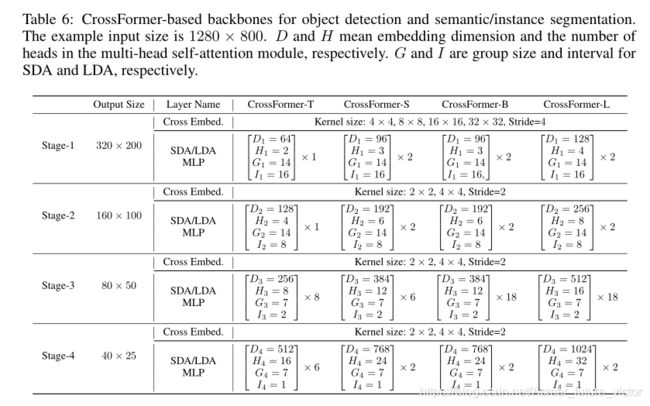
表7:ImageNet验证集的结果。基线模型为CrossFormer-S(82.5%)。我们用不同核大小的CEL进行测试。

B Experiments
B.1 Image Classification
对不同核大小的CEL进行了更多的实验。如表7所示,简单地将核大小从4×4增大到8×8可以带来0.4%的准确率提升,并且跨尺度嵌入获得了最高性能,与单尺度嵌入相比,它们带来了至少0.4%(82.3%比81.9%)的性能提升。
B.2 Object Detection
表8提供了使用RetinaNet和Mask-RCNN作为检测头进行目标检测的更多结果。正如我们所看到的,较小的(G,I)比较大的(G,I)获得更高的AP,但性能增益是微乎其微的。考虑到较大的(G,I)可以节省更多的内存成本,我们认为(G1=14,I1=16,G2=14,I2=8)符合表6中的配置,在性能和成本之间取得了更好的平衡。
表8:Coco Val 2017上的物体检测结果。“Memory”表示torch.cuda.max Memory Allowed()上报的每个GPU分配的内存,‡表示机型使用的是与分类机型不同的(G,I)。

B.3 Semantic Segmentation
与目标检测类似,我们针对语义分割的主干测试了两种不同的(G,I)配置。结果如表9所示。我们可以看到,两种配置的内存开销几乎相同,这与目标检测实验有所不同。此外,当使用语义FPN作为检测头部时,CrossFormer‡在IOU(例如,46.4vs.46.0G)和FLOP(例如,209.8G vs.220.7G)上都显示出优于CrossFormersIOU(例如,46.4vs.46.0Gvs.220.7G)的优势。当使用UPerNet作为分割头时,较小的(G,I)可以获得与目标检测类似的较高性能。
表9:以语义FPN或UPerNet为头部的ADE20K验证集上的语义分割结果。
