2022.4.15_ch06-神经网络
- 全连接层:张量实现,层实现
- 神经网络:张量实现,层实现
- 激活函数:Sigmoid,ReLU,LeakyReLU,Tanh
- 输出层设计:[0,1]区间,和为 1;[-1, 1]
- 误差计算:均方差,交叉熵
- 汽车油耗预测实战
神经网络代码://及结果
####1.全连接层####
###张量实现###
mport tensorflow as tf
from matplotlib import pyplot as plt
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
# 创建 W,b 张量
x = tf.random.normal([2,784])
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
# 线性变换
o1 = tf.matmul(x,w1) + b1
# 激活函数
o1 = tf.nn.relu(o1)
o1
###层实现###
x = tf.random.normal([4,28*28])
# 导入层模块
from tensorflow.keras import layers
# 创建全连接层,指定输出节点数和激活函数
fc = layers.Dense(512, activation=tf.nn.relu)
# 通过 fc 类实例完成一次全连接层的计算,返回输出张量
h1 = fc(x)
h1
#上述通过一行代码即可以创建一层全连接层 fc, 并指定输出节点数为 512,
#输入的节点数在fc(x)计算时自动获取, 并创建内部权值张量和偏置张量。
#我们可以通过类内部的成员名 kernel 和 bias 来获取权值张量和偏置张量对象
# 获取 Dense 类的权值矩阵
fc.kernel
# 获取 Dense 类的偏置向量
fc.bias
# 待优化参数列表
fc.trainable_variables
# 返回所有参数列表
fc.variables
####2.神经网络####
###张量实现###
# 隐藏层 1 张量
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
# 隐藏层 2 张量
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros([128]))
# 隐藏层 3 张量
w3 = tf.Variable(tf.random.truncated_normal([128, 64], stddev=0.1))
b3 = tf.Variable(tf.zeros([64]))
# 输出层张量
w4 = tf.Variable(tf.random.truncated_normal([64, 10], stddev=0.1))
b4 = tf.Variable(tf.zeros([10]))
with tf.GradientTape() as tape: # 梯度记录器
# x: [b, 28*28]
# 隐藏层 1 前向计算, [b, 28*28] => [b, 256]
h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256])
h1 = tf.nn.relu(h1)
# 隐藏层 2 前向计算, [b, 256] => [b, 128]
h2 = h1@w2 + b2
h2 = tf.nn.relu(h2)
# 隐藏层 3 前向计算, [b, 128] => [b, 64]
h3 = h2@w3 + b3
h3 = tf.nn.relu(h3)
# 输出层前向计算, [b, 64] => [b, 10]
h4 = h3@w4 + b4
###层实现###
# 导入常用网络层 layers
from tensorflow.keras import layers,Sequential
# 隐藏层 1
fc1 = layers.Dense(256, activation=tf.nn.relu)
# 隐藏层 2
fc2 = layers.Dense(128, activation=tf.nn.relu)
# 隐藏层 3
fc3 = layers.Dense(64, activation=tf.nn.relu)
# 输出层
fc4 = layers.Dense(10, activation=None)
x = tf.random.normal([4,28*28])
# 通过隐藏层 1 得到输出
h1 = fc1(x)
# 通过隐藏层 2 得到输出
h2 = fc2(h1)
# 通过隐藏层 3 得到输出
h3 = fc3(h2)
# 通过输出层得到网络输出
h4 = fc4(h3)
#对于这种数据依次向前传播的网络, 也可以通过 Sequential 容器封装成一个网络大类对象,
#调用大类的前向计算函数一次即可完成所有层的前向计算,使用起来更加方便。
# 导入 Sequential 容器
from tensorflow.keras import layers,Sequential
# 通过 Sequential 容器封装为一个网络类
model = Sequential([
layers.Dense(256, activation=tf.nn.relu) , # 创建隐藏层 1
layers.Dense(128, activation=tf.nn.relu) , # 创建隐藏层 2
layers.Dense(64, activation=tf.nn.relu) , # 创建隐藏层 3
layers.Dense(10, activation=None) , # 创建输出层
])
out = model(x) # 前向计算得到输出
####3.激活函数####
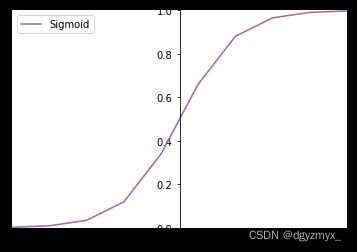
###Sigmoid###
#sigmoid(x)=1/(1+exp(-x))
# 构造-6~6 的输入向量
x = tf.linspace(-6.,6.,10)
x
# 通过 Sigmoid 函数
sigmoid_y = tf.nn.sigmoid(x)
sigmoid_y
def set_plt_ax():
# get current axis 获得坐标轴对象
ax = plt.gca()
ax.spines['right'].set_color('none')
# 将右边 上边的两条边颜色设置为空 其实就相当于抹掉这两条边
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
# 指定下边的边作为 x 轴,指定左边的边为 y 轴
ax.yaxis.set_ticks_position('left')
# 指定 data 设置的bottom(也就是指定的x轴)绑定到y轴的0这个点上
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
set_plt_ax()
plt.plot(x, sigmoid_y, color='C4', label='Sigmoid')
plt.xlim(-6, 6)
plt.ylim(0, 1)
plt.legend(loc=2)
plt.show()
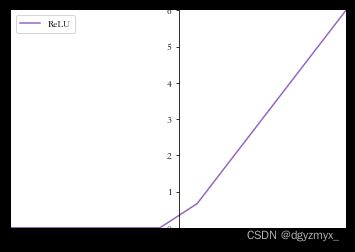
###ReLU###
#relu(x)=max(0,x)
# 通过 ReLU 激活函数
relu_y = tf.nn.relu(x)
relu_y
set_plt_ax()
plt.plot(x, relu_y, color='C4', label='ReLU')
plt.xlim(-6, 6)
plt.ylim(0, 6)
plt.legend(loc=2)
plt.show()
###LeakyReLU###
#leakyrelu(x)=(x>=0)?x:px
# 通过 LeakyReLU 激活函数
leakyrelu_y = tf.nn.leaky_relu(x, alpha=0.1)
leakyrelu_y
set_plt_ax()
plt.plot(x, leakyrelu_y, color='C4', label='LeakyReLU')
plt.xlim(-6, 6)
plt.ylim(-1, 6)
plt.legend(loc=2)
plt.show()

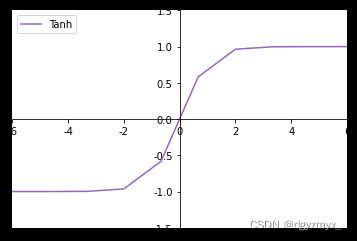
###Tanh###
#tanh(x)=(exp(x)-exp(-x))/(exp(x)+exp(-x))=2*sigmoid(2x)-1
# 通过 tanh 激活函数
tanh_y = tf.nn.tanh(x)
tanh_y
set_plt_ax()
plt.plot(x, tanh_y, color='C4', label='Tanh')
plt.xlim(-6, 6)
plt.ylim(-1.5, 1.5)
plt.legend(loc=2)
plt.show()
####4.输出层设计####
###[0,1]区间,和为 1###
#softmax(zi)=exp(zi)/∑exp(zj)
z = tf.constant([2.,1.,0.1])
# 通过 Softmax 函数
tf.nn.softmax(z)
# 构造输出层的输出
z = tf.random.normal([2,10])
# 构造真实值
y_onehot = tf.constant([1,3])
# one-hot 编码
y_onehot = tf.one_hot(y_onehot, depth=10)
# 输出层未使用 Softmax 函数,故 from_logits 设置为 True
# 这样 categorical_crossentropy 函数在计算损失函数前,会先内部调用 Softmax 函数
loss = tf.keras.losses.categorical_crossentropy(y_onehot,z,from_logits=True)
loss = tf.reduce_mean(loss) # 计算平均交叉熵损失
loss
# 创建 Softmax 与交叉熵计算类,输出层的输出 z 未使用 softmax
criteon = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
loss = criteon(y_onehot,z) # 计算损失
loss
###[-1, 1]###
#tanh(x)=(exp(x)-exp(-x))/(exp(x)+exp(-x))=2*sigmoid(2x)-1
x = tf.linspace(-6.,6.,10)
# tanh 激活函数
tf.tanh(x)
####6.误差计算####
###均方差###
#mse(y,o)=(∑(yi-oi)^2)/dout
#MSE 误差函数的值总是大于等于 0,当 MSE 函数达到最小值 0 时, 输出等于真实标签,此时神经网络的参数达到最优状态。
# 构造网络输出
o = tf.random.normal([2,10])
# 构造真实值
y_onehot = tf.constant([1,3])
y_onehot = tf.one_hot(y_onehot, depth=10)
# 计算均方差
loss = tf.keras.losses.MSE(y_onehot, o)
loss
# 计算 batch 均方差
loss = tf.reduce_mean(loss)
loss
# 创建 MSE 类
criteon = tf.keras.losses.MeanSquaredError()
# 计算 batch 均方差
loss = criteon(y_onehot,o)
loss
###交叉熵###
#H(p||q)=-logoi
#熵H(p||q)取得最小值 0,此时网络输出o与真实标签y完全一致,神经网络取得最优状态。
汽车油耗预测实战代码://及结果
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, losses
def load_dataset():
# 在线下载汽车效能数据集
dataset_path = keras.utils.get_file("auto-mpg.data","http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
# 效能(公里数每加仑),气缸数,排量,马力,重量
# 加速度,型号年份,产地
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names, na_values="?", comment='\t', sep=" ", skipinitialspace=True)
dataset = raw_dataset.copy()
return dataset
dataset = load_dataset()
# 查看部分数据
dataset.head()
dataset = load_dataset()
# 查看部分数据
dataset.head()
# index,MPG,Cylinders,Displacement,Horsepower,Weight,Acceleration,Model Year,Origin
# 0,18.0,8,307.0,130.0,3504.0,12.0,70,1
# 1,15.0,8,350.0,165.0,3693.0,11.5,70,1
# 2,18.0,8,318.0,150.0,3436.0,11.0,70,1
# 3,16.0,8,304.0,150.0,3433.0,12.0,70,1
# 4,17.0,8,302.0,140.0,3449.0,10.5,70,1
def preprocess_dataset(dataset):
dataset = dataset.copy()
# 统计空白数据,并清除
dataset = dataset.dropna()
# 处理类别型数据,其中origin列代表了类别1,2,3,分布代表产地:美国、欧洲、日本
# 其弹出这一列
origin = dataset.pop('Origin')
# 根据origin列来写入新列
dataset['USA'] = (origin == 1) * 1.0
dataset['Europe'] = (origin == 2) * 1.0
dataset['Japan'] = (origin == 3) * 1.0
# 切分为训练集和测试集
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
return train_dataset, test_dataset
train_dataset, test_dataset = preprocess_dataset(dataset)
# 统计数据
sns_plot = sns.pairplot(train_dataset[["Cylinders", "Displacement", "Weight", "MPG"]], diag_kind="kde")

# 查看训练集的输入X的统计数据
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
# index,count,mean,std,min,25%,50%,75%,max
# Cylinders,314.0,5.477707006369426,1.6997875727498222,3.0,4.0,4.0,8.0,8.0
# Displacement,314.0,195.3184713375796,104.33158850796347,68.0,105.5,151.0,265.75,455.0
# Horsepower,314.0,104.86942675159236,38.09621443533366,46.0,76.25,94.5,128.0,225.0
# Weight,314.0,2990.251592356688,843.8985961905663,1649.0,2256.5,2822.5,3608.0,5140.0
# Acceleration,314.0,15.559235668789801,2.789229751888417,8.0,13.8,15.5,17.2,24.8
# Model Year,314.0,75.89808917197452,3.6756424982267455,70.0,73.0,76.0,79.0,82.0
# USA,314.0,0.6242038216560509,0.48510086219560555,0.0,0.0,1.0,1.0,1.0
# Europe,314.0,0.17834394904458598,0.3834130350451088,0.0,0.0,0.0,0.0,1.0
# Japan,314.0,0.19745222929936307,0.3987118306606328,0.0,0.0,0.0,0.0,1.0
def norm(x, train_stats):
"""
标准化数据
:param x:
:param train_stats: get_train_stats(train_dataset)
:return:
"""
return (x - train_stats['mean']) / train_stats['std']
#移动MPG油耗效能这一列为真实标签Y
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
# 进行标准化
normed_train_data = norm(train_dataset, train_stats)
normed_test_data = norm(test_dataset, train_stats)
print(normed_train_data.shape,train_labels.shape)
print(normed_test_data.shape, test_labels.shape)
# (314, 9) (314,)
# (78, 9) (78,)
class Network(keras.Model):
# 回归网络
def __init__(self):
super(Network, self).__init__()
# 创建3个全连接层
self.fc1 = layers.Dense(64, activation='relu')
self.fc2 = layers.Dense(64, activation='relu')
self.fc3 = layers.Dense(1)
def call(self, inputs):
# 依次通过3个全连接层
x = self.fc1(inputs)
x = self.fc2(x)
x = self.fc3(x)
return x
def build_model():
# 创建网络
model = Network()
model.build(input_shape=(4, 9))
model.summary()
return model
model = build_model()
optimizer = tf.keras.optimizers.RMSprop(0.001)
train_db = tf.data.Dataset.from_tensor_slices((normed_train_data.values, train_labels.values))
train_db = train_db.shuffle(100).batch(32)
# Model: "network"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# dense (Dense) multiple 640
# dense_1 (Dense) multiple 4160
# dense_2 (Dense) multiple 65
# =================================================================
# Total params: 4,865
# Trainable params: 4,865
# Non-trainable params: 0
# _________________________________________________________________
def train(model, train_db, optimizer, normed_test_data, test_labels):
train_mae_losses = []
test_mae_losses = []
for epoch in range(200):
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
out = model(x)
loss = tf.reduce_mean(losses.MSE(y, out))
mae_loss = tf.reduce_mean(losses.MAE(y, out))
if step % 10 == 0:
print(epoch, step, float(loss))
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_mae_losses.append(float(mae_loss))
out = model(tf.constant(normed_test_data.values))
test_mae_losses.append(tf.reduce_mean(losses.MAE(test_labels, out)))
return train_mae_losses, test_mae_losses
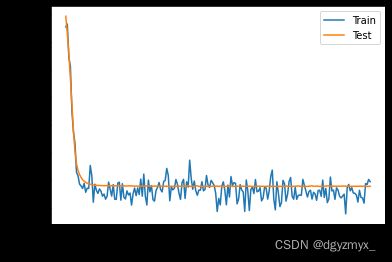
def plot(train_mae_losses, test_mae_losses):
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('MAE')
plt.plot(train_mae_losses, label='Train')
plt.plot(test_mae_losses, label='Test')
plt.legend()
# plt.ylim([0,10])
plt.legend()
plt.show()
train_mae_losses, test_mae_losses = train(model, train_db, optimizer, normed_test_data, test_labels)
plot(train_mae_losses, test_mae_losses)