Spark核心编程系列(一)——RDD详解
目录
Spark核心编程系列——RDD详解(一)
RDD概念
RDD与IO之间的关系
RDD的核心属性
RDD执行原理
基础编程
RDD创建
RDD的并行度与分区
参考
Spark核心编程系列——RDD详解(一)
RDD概念
RDD(Resilient Distributed Dataset) 叫做弹性分布式数据集,是Spark中最基本的数据处理模型,也是最小的计算单元。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。它是MapReduce模型的扩展和延伸,但它解决了MapReduce的缺陷:在并行计算阶段高效地进行数据共享。
本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
在 Spark 中,所有的工作都是以操作 RDD 为主,要么是创建 RDD,要么是转换已经存在 RDD 成为新的 RDD,要么在 RDD 上去执行一些操作来得到一些计算结果。
弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
分布式:数据存储在大数据集群不同节点上
数据集:RDD封装了计算逻辑,并不保存数据
数据抽象:RDD是一个抽象类,需要子类具体实现
不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑
可分区、并行计算
RDD与IO之间的关系
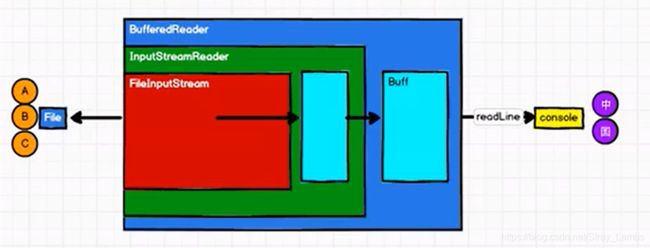
RDD之间的计算原理与IO的输入输出有类似的关系。IO的输入输出其实是将FileInputStream进行装饰模式,外面不断封装包裹其他的类,拓展了其他的功能,例如InputStreamReader、BufferedReader。
RDD的数据只有在调用collect方法时,才会真正的执行业务逻辑操作。之前的封装全部都是功能的扩展。且RDD的数据处理过程当中,与IO流不同的是,IO流存在着Buff缓冲区,而RDD是不保存数据的。

RDD的核心属性


1、分区列表
RDD中的分区,即数据集的基本组成单位,每个分区可以运行在不同节点上;对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度,是实现分布式计算的重要属性。
protected def getPartitions: Arrays[Partition]
/**
* Implemented by subclasses to return the set of partitions in this RDD. This method will only be called once, so it is safe to implement a time-consuming computation in it.
*
* The partitions in this array must satisfy the following property:
* rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }
**/2、分区计算函数
Spark在计算时, 是使用分区函数对每一个分区进行计算,计算逻辑是实现封装好传过来的。
每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。

3、RDD之间的依赖关系
RDD是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个RDD建立依赖关系。
当需求中需要将多个计算模型进行组合时,就需要将多个RDD建立依赖关系;RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。
在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
依赖类型有两种,1、窄依赖:父RDD 的 partition 至多被一个子 RDD partition 依赖(OneToOneDependency,RangeDependency)2、宽依赖:父 RDD 的 partition 被多个子 RDD partitions 依赖(ShuffleDependency)。窄依赖是一对一的关系,所以可以获取到父分区;宽依赖则不行。

4、分区器
RDD的分区函数,即对数据的分区规则。主要有两种分区函数,一个是基于哈希的HashPartitioner(默认),另外一个是基于范围的RangePartitioner。
只有key-value类型的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。
Partitioner函数不但决定了RDD本身的分区数量,也决定了parent RDD Shuffle输出时的分区数量。

5、首选位置(距离近的节点列表)
计算数据的位置 (本地化级别),可以设置数据读取的偏好位置,用来将Task发送给指定的节点,就近原则(节省网络IO)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。

RDD执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。
执行时,需要将计算资源和计算模型进行协调和整合。
Spark框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上,按照指定的计算模型进行数据计算。最后得到计算结果。
RDD是Spark框架中用于数据处理的核心模型,接下来我们看看,在Yarn环境中,RDD的工作原理:
1) 启动Yarn集群环境

2) Spark通过申请资源创建调度节点和计算节点

3) Spark框架根据需求将计算逻辑根据分区划分成不同的任务

4) 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
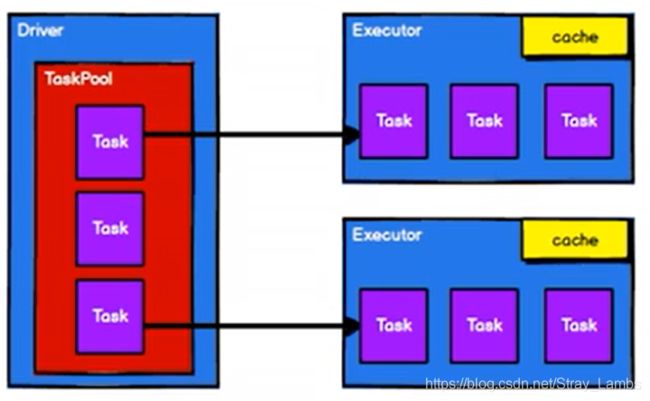
从以上流程可以看出RDD在整个流程中主要用于将逻辑进行封装,并生成Task发送给Executor节点执行计算。
基础编程
RDD创建
在Spark中创建RDD的创建方式可以分为四种:
1) 从集合(内存)中创建RDD
从集合中创建RDD,Spark主要提供了两种方法:parallelize和makeRDD,从源码中我们可以看到,makeRDD其实就是调用了parallelize方法。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// 创建RDD
// 从内存中创建RDD,将内存中集合的数据作为处理的数据源
val seq = Seq[Int](1,2,3,4)
val rdd1: RDD[Int] = sc.parallelize(seq)
val rdd2: RDD[Int] = sc.makeRDD(seq)
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
sc.stop()2) 从外部存储(文件)创建RDD
由外部存储系统的数据集创建RDD包括: 本地的文件系统,所有Hadoop支持的数据集,比如HDFS、HBase等。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName()
val sc = new SparkContext(sparkConf)
// 创建RDD
// 从文件中创建RDD,将文件中的数据作为处理的数据源
// path路径默认以当前环境的根路径为基准。可以写绝对路径,也可以写相对路径
val rdd1: RDD[String] = sc.textFile("xxxx文件路径")
// 路径可以是文件目录,则会获取目录下的所有文件
val rdd2: RDD[String] = sc.textFile("xxxx文件目录")
// 还可以使用通配符或者是分布式存储系统路径,这里就不演示了
// 读取文件的两类函数
// textFile : 以行为单位读取数据,读取的数据都是字符串。如果读取的是多个文件,无法区分数据来自于哪个文件
// wholeTextFile :以文件为单位读取数据,读取的结果表示为元组,第一个元素表示文件路径,第二个元素表示文件内容。可以区分数据来源于哪个文件。
rdd1.collect().foreach(println)
sc.stop()3) 从其他RDD创建
主要通过一个RDD运算完后,再产生新的RDD。一般用的可能不多。
val rdd4=rdd3.map(x=>x+10)
rdd4.foreach(print)4) 直接创建RDD (new)
使用new的方式直接构造RDD,一般由Spark框架自身使用。
RDD的并行度与分区
1、从集合(内存)中创建 RDD时的分区
默认情况下,Spark可以将一个作业切分多个任务后,发送给Executor节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建RDD时指定。记住,这里的并行执行的任务数量,并不是指的切分任务的数量,不要混淆了。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
sparkConf.set("spark.default.parallelism", "5")
val sc = new SparkContext(sparkConf)
// RDD的并行度 & 分区
// makeRDD方法可以传递第二个参数,这个参数表示分区的数量
// 第二个参数可以不传递的,那么makeRDD方法会使用默认值:defaultParallelism(默认并行度)
// scheduler.conf.getInt("spark.default.parallelism", totalCores)
// spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism
// 如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数
val rdd = sc.makeRDD(List(1,2,3,4))
// 将处理的数据保存成分区文件
rdd.saveAsTextFile("output")
sc.stop()分区规则及每个分区内数据的确定:
Spark 核心源码如下:
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
解析:
- 我们可以看到positions()的底层源码解释,传入的是序列的长度和分区的个数,返回值是一个Iterator[(Int, Int)]。
- Iterator中的元素是 (start, end) ,是一个区间,取得是左闭右开,在底层源码中,slice()方法的参数就是对应着(start until end) >>> (def slice(from: Int, until: Int): Repr = {…})
- 而最终每个分区保存的数据就是根据每个分区分配的区间去截取传入的数据源 List中的内容,分析如下:
以第3个测试数据为例:
List(1,2,3,4,5) // 数据
i = 0,1,2 //
length = 5 // 序列的长度
numSlices = 3 // 分区的个数 分别为:part-00,part-01,part-02
对(start, end) 带入公式:
part-00: => (((i * length) / numSlices).toInt, (((i + 1) * length) / numSlices ).toInt) => ( (0*5)/3 , ((0+1)*5)/3) => (0,1) => [0,1) => 1
part-01: => (1,3) => [1,3) => 2,3
part-02: => (3,5) => [3,5) => 4,5
2、spark 读取文件数据的分区
读取文件数据时,数据是按照 Hadoop 文件读取的规则进行切片分区,而切片规则和数
据读取的规则有些差异。而且,如果有多个文件时,将会以文件为单位进行分区计算(类似于Hadoop中的多个文件读取切片操作)。
textFile()可以将文件作为数据处理的数据源,默认也可以设定分区。

其中传入的第二个参数为最小分区数量,真正的分区数量是有可能大于我们传入的参数值的。这是因为Spark读取文件,底层其实使用的就是Hadoop的读取方式,而在这里定义了分区数量的计算方式(可以通过源码发现)。
具体Spark核心源码如下:
先是读取文件,统计文件总的字节数 totalSize,然后根据传进来的参数2,求每个分区需要存储的字节数goalSize,最后 (totalSize / goalSize) 求出实际分区的数量。
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
...
for (FileStatus file: files) {
...
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
...
}
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}举个例子:如果数据源是1,2,3,大小为7字节,且最小分区数为2。
其中,10%是不是很眼熟。其实就是Hadoop当中,切片时底层源码的一个值1.1。如果最后一个切片的大小小于10%,则不会产生新的切片,否则产生新的切片。Spark分区同理。
分区数量的计算方式:
totalSize = 7 // 文件总的字节数
goalSize = 7 / 2 = 3(byte) // 每个分区存储的字节数
// 如果多出来的字节数大于一个分区字节数的10%,则另开一个分区
7 / 3 = 2...1 (1.1) + 1 = 3(分区)确定了分区数量,那么针对数据源中内容,又是如何分配到每个分区的,这里也有它的分配规则:
1、数据以行为单位进行读取
(1) spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,和字节数没有关系。例如一个汉字占2个字节,如果这一行有两个汉字,而每个分区是存储3个字节的,那么在分配到每个分区时,不会根据每个分区能存储的字节数去存储,毕竟此时3个字节不能表示数据源中的两个汉字,所以是一行一行读取的。
2、数据读取时以偏移量为单位,偏移量不会被重复读取,这里偏移量是以1个字节为一个偏移量
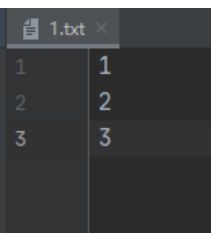
可以看到 1.txt中 是存在换行符的,换行符是2个字节。

所以数据分区的分配计算下(我们此处用@@代替特殊符合),注意这里的区间是是左闭右闭的:
1. 已知 1.txt 有7个字节,则需要3个分区 0,1,2
2. 确定偏移量
数据 偏移量
1@@ => 012
2@@ => 345
3 => 6
3. 数据分区的偏移量范围的计算
分区 每个分区保存的字节数 每个分区保存偏移量范围
part-01 >> 保存3个字节,那么保存的偏移量范围是:[0, 0+3] --> [0, 3] --> 那么对应读取的偏移量有:0123 45 -----> 最终保存的数据 1, 2
part-02 >> 保存3个字节,那么保存的偏移量范围是:[3, 3+3] --> [3, 6] --> 那么对应读取的偏移量有:6 -----> 最终保存的数据 3
part-03 >> 保存1个字节,那么保存的偏移量范围是:[6, 6+1] --> [6, 7] --> 那么对应读取的偏移量有:[] -----> 最终保存的数据 []
4. 解析
0号分区,存放的偏移量范围是0123,而又因为读取文件是一行一行读取,所以45也一起读取了,所以读取的数据是 1,2
1号分区,本应读取偏移量范围是3456,由于上一个分区读取了345,所以只读6,所以读取的数据是 3
2号分区,因为上一步中读了偏移量为6的数据,所以不再读取,所以读取出来为空
参考
https://www.bilibili.com/video/BV11A411L7CK?p=40&spm_id_from=pageDriver
https://blog.csdn.net/To_9426464/article/details/113621392