spark第三天(十天)
一.Spark函数详解系列之RDD基本转换
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
Transformation(转换):Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住了数据集的逻辑操作
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作: (1).RDD基本转换 (2).键-值RDD转换 (3).Action操作篇
(a) 其中 RDD基本转换包括以下11中类型
基础转换操作:
1.map(func)
2.flatMap(func)
3.mapPartitions(func)
4.mapPartitionsWithIndex(func)
5.simple(withReplacement,fraction,seed)
6.union(ortherDataset)
7.intersection(otherDataset)
8.distinct([numTasks])
9.cartesian(otherDataset)
10.coalesce(numPartitions,shuffle)
11.repartition(numPartition)
12.glom()
13.randomSplit(weight:Array[Double],seed)
1.map(func):数据集中的每个元素经过用户自定义的函数转换形成一个新的RDD,新的RDD叫MappedRDD
(例1)
| 1 2 3 4 5 6 7 8 9 10 |
|
输出:
2 4 6 8 10 12 14 16 18 20(RDD依赖图:红色块表示一个RDD区,黑色块表示该分区集合,下同)

2.flatMap(func):与map类似,但每个元素输入项都可以被映射到0个或多个的输出项,最终将结果”扁平化“后输出
(例2)
| 1 2 3 4 |
|
输出:
1 1 2 1 2 3 1 2 3 4 1 2 3 4 5如果是map函数其输出如下:
Range(1) Range(1, 2) Range(1, 2, 3) Range(1, 2, 3, 4) Range(1, 2, 3, 4, 5) 
3.mapPartitions(func):类似与map,map作用于每个分区的每个元素,但mapPartitions作用于每个分区工
func的类型:Iterator[T] => Iterator[U]
假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,当在映射的过程中不断的创建对象时就可以使用mapPartitions比map的效率要高很多,比如当向数据库写入数据时,如果使用map就需要为每个元素创建connection对象,但使用mapPartitions的话就需要为每个分区创建connetcion对象
(例3):输出有女性的名字:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
输出:
kpop lucy其实这个效果可以用一条语句完成
| 1 |
|
4.mapPartitionsWithIndex(func):与mapPartitions类似,不同的时函数多了个分区索引的参数
func类型:(Int, Iterator[T]) => Iterator[U]
(例4):将例3橙色的注释部分去掉即是
输出:(带了分区索引)
[0]kpop [1]lucy
5.sample(withReplacement,fraction,seed):以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样
(例5):从RDD中随机且有放回的抽出50%的数据,随机种子值为3(即可能以1 2 3的其中一个起始值)
| 1 2 3 4 5 |
|
6.union(ortherDataset):将两个RDD中的数据集进行合并,最终返回两个RDD的并集,若RDD中存在相同的元素也不会去重
| 1 2 3 4 5 6 |
|
输出:
1 2 3 3 4 57.intersection(otherDataset):返回两个RDD的交集
| 1 2 3 4 5 6 |
|
输出:
3
8.distinct([numTasks]):对RDD中的元素进行去重
| 1 2 3 4 5 |
|
输出:
1 6 9 5 2
9.cartesian(otherDataset):对两个RDD中的所有元素进行笛卡尔积操作
| 1 2 3 4 5 |
|
(1,2)
(1,3)
(1,4)
(1,5)
(2,2)
(2,3)
(2,4)
(2,5)
(3,2)
(3,3)
(3,4)
(3,5) 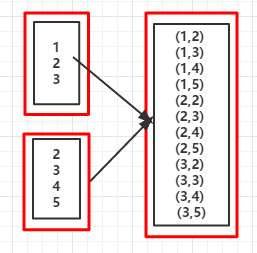
10.coalesce(numPartitions,shuffle):对RDD的分区进行重新分区,shuffle默认值为false,当shuffle=false时,不能增加分区数
目,但不会报错,只是分区个数还是原来的
(例9:)shuffle=false
| 1 2 3 4 |
|
输出:
重新分区后的分区个数:3
//分区后的数据集
List(1, 2, 3, 4)
List(5, 6, 7, 8)
List(9, 10, 11, 12, 13, 14, 15, 16)
(RDD依赖图:coalesce(3,flase))
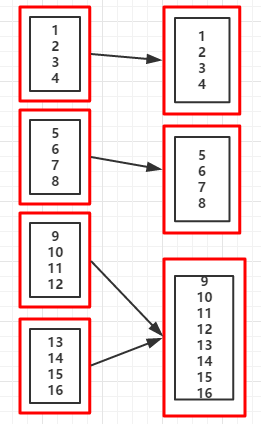
(RDD依赖图:coalesce(3,true))
(例9.1:)shuffle=true
| 1 2 3 4 5 |
|
输出:
重新分区后的分区个数:5
RDD依赖关系:(5) MapPartitionsRDD[4] at coalesce at Coalesce.scala:14 []
| CoalescedRDD[3] at coalesce at Coalesce.scala:14 []
| ShuffledRDD[2] at coalesce at Coalesce.scala:14 []
+-(4) MapPartitionsRDD[1] at coalesce at Coalesce.scala:14 []
| ParallelCollectionRDD[0] at parallelize at Coalesce.scala:13 []
//分区后的数据集
List(10, 13)
List(1, 5, 11, 14)
List(2, 6, 12, 15)
List(3, 7, 16)
List(4, 8, 9) 12.glom():将RDD的每个分区中的类型为T的元素转换换数组Array[T]
| 1 2 3 4 5 |
|
输出:
int[] //说明RDD中的元素被转换成数组Array[Int] 
13.randomSplit(weight:Array[Double],seed):根据weight权重值将一个RDD划分成多个RDD,权重越高划分得到的元素较多的几率就越大
| 1 2 3 4 5 6 7 |
|
输出:
2 4
3 8 9
1 5 6 7 10(b) 其中 RDD基本转换包括以下11中类型
1.mapValus
2.flatMapValues
3.comineByKey
4.foldByKey
5.reduceByKey
6.groupByKey
7.sortByKey
8.cogroup
9.join
10.LeftOutJoin
11.RightOutJoin
1.mapValus(fun):对[K,V]型数据中的V值map操作
(例1):对每个的的年龄加2
| 1 2 3 4 5 6 7 8 9 10 |
|
输出:
(mobin,24)
(kpop,22)
(lufei,25)(RDD依赖图:红色块表示一个RDD区,黑色块表示该分区集合,下同)
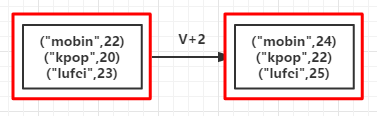
2.flatMapValues(fun):对[K,V]型数据中的V值flatmap操作
(例2):
| 1 2 3 4 |
|
输出:
(mobin,22)
(mobin,male)
(kpop,20)
(kpop,male)
(lufei,23)
(lufei,male)如果是mapValues会输出:
(mobin,List(22, male))
(kpop,List(20, male))
(lufei,List(23, male)) 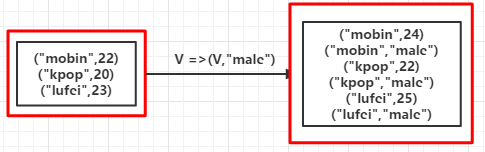
3.comineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)
comineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions)
comineByKey(createCombiner,mergeValue,mergeCombiners)
createCombiner:在第一次遇到Key时创建组合器函数,将RDD数据集中的V类型值转换C类型值(V => C),
如例3:
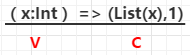
mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner到里的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C,
如例3:

mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值
如例3:

partitioner:使用已有的或自定义的分区函数,默认是HashPartitioner
mapSideCombine:是否在map端进行Combine操作,默认为true
注意前三个函数的参数类型要对应;第一次遇到Key时调用createCombiner,再次遇到相同的Key时调用mergeValue合并值
(例3):统计男性和女生的个数,并以(性别,(名字,名字....),个数)的形式输出
object CombineByKey {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("combinByKey")
val sc = new SparkContext(conf)
val people = List(("male", "Mobin"), ("male", "Kpop"), ("female", "Lucy"), ("male", "Lufei"), ("female", "Amy"))
val rdd = sc.parallelize(people)
val combinByKeyRDD = rdd.combineByKey(
(x: String) => (List(x), 1),
(peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1),
(sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2))
combinByKeyRDD.foreach(println)
sc.stop()
}
}输出:
(male,(List(Lufei, Kpop, Mobin),3))
(female,(List(Amy, Lucy),2))过程分解:
Partition1:
K="male" --> ("male","Mobin") --> createCombiner("Mobin") => peo1 = ( List("Mobin") , 1 )
K="male" --> ("male","Kpop") --> mergeValue(peo1,"Kpop") => peo2 = ( "Kpop" :: peo1_1 , 1 + 1 )
//Key相同调用mergeValue函数对值进行合并
K="female" --> ("female","Lucy") --> createCombiner("Lucy") => peo3 = ( List("Lucy") , 1 )
Partition2:
K="male" --> ("male","Lufei") --> createCombiner("Lufei") => peo4 = ( List("Lufei") , 1 )
K="female" --> ("female","Amy") --> createCombiner("Amy") => peo5 = ( List("Amy") , 1 )
Merger Partition:
K="male" --> mergeCombiners(peo2,peo4) => (List(Lufei,Kpop,Mobin))
K="female" --> mergeCombiners(peo3,peo5) => (List(Amy,Lucy))

4.foldByKey(zeroValue)(func)
foldByKey(zeroValue,partitioner)(func)
foldByKey(zeroValue,numPartitiones)(func)
foldByKey函数是通过调用CombineByKey函数实现的
zeroVale:对V进行初始化,实际上是通过CombineByKey的createCombiner实现的 V => (zeroValue,V),再通过func函数映射成新的值,即func(zeroValue,V),如例4可看作对每个V先进行 V=> 2 + V
func: Value将通过func函数按Key值进行合并(实际上是通过CombineByKey的mergeValue,mergeCombiners函数实现的,只不过在这里,这两个函数是相同的)
例4:
| 1 2 3 4 5 |
|
输出:
(Amy,3)
(Mobin,5)
(Lucy,7)
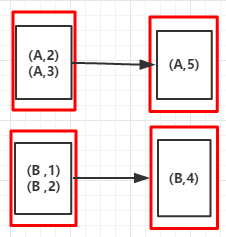
5.reduceByKey(func,numPartitions):按Key进行分组,使用给定的func函数聚合value值, numPartitions设置分区数,提高作业并行度
例5
| 1 2 3 4 5 6 |
|
输出:
(A,5)
(A,4)(RDD依赖图)
6.groupByKey(numPartitions):按Key进行分组,返回[K,Iterable[V]],numPartitions设置分区数,提高作业并行度
例6:
| 1 2 3 4 5 6 |
|
输出:
(B,CompactBuffer(2, 3))
(A,CompactBuffer(1, 2))
以上foldByKey,reduceByKey,groupByKey函数最终都是通过调用combineByKey函数实现的
7.sortByKey(accending,numPartitions):返回以Key排序的(K,V)键值对组成的RDD,accending为true时表示升序,为false时表示降序,numPartitions设置分区数,提高作业并行度
例7:
| 1 2 3 4 5 6 |
|
输出:
(A,1)
(A,2)
(B,2)
(B,3)
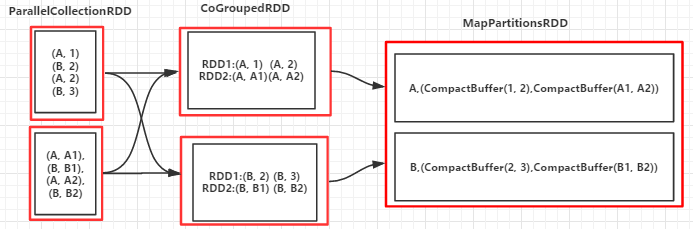
8.cogroup(otherDataSet,numPartitions):对两个RDD(如:(K,V)和(K,W))相同Key的元素先分别做聚合,最后返回(K,Iterator
例8:
| 1 2 3 4 5 6 7 8 |
|
输出:
(B,(CompactBuffer(2, 3),CompactBuffer(B1, B2)))
(A,(CompactBuffer(1, 2),CompactBuffer(A1, A2)))(RDD依赖图)
9.join(otherDataSet,numPartitions):对两个RDD先进行cogroup操作形成新的RDD,numPartitions设置分区数,提高作业并行度
例9
| 1 2 3 4 5 6 7 |
|
输出:
(B,(2,B1))
(B,(2,B2))
(B,(3,B1))
(B,(3,B2))
(A,(1,A1))
(A,(1,A2))
(A,(2,A1))
(A,(2,A2)(RDD依赖图)

10.LeftOutJoin(otherDataSet,numPartitions):左外连接,包含左RDD的所有数据,如果右边没有与之匹配的用None表示,numPartitions设置分区数,提高作业并行度
例10:
| 1 2 3 4 5 6 7 8 |
|
输出:
(B,(2,Some(B1)))
(B,(2,Some(B2)))
(B,(3,Some(B1)))
(B,(3,Some(B2)))
(C,(1,None))
(A,(1,Some(A1)))
(A,(1,Some(A2)))
(A,(2,Some(A1)))
(A,(2,Some(A2)))
11.RightOutJoin(otherDataSet, numPartitions):右外连接,包含右RDD的所有数据,如果左边没有与之匹配的用None表示,numPartitions设置分区数,提高作业并行度
例11:
| 1 2 3 4 5 6 7 8 |
|
输出:
(B,(Some(2),B1))
(B,(Some(2),B2))
(B,(Some(3),B1))
(B,(Some(3),B2))
(C,(None,C1))
(A,(Some(1),A1))
(A,(Some(1),A2))
(A,(Some(2),A1))
(A,(Some(2),A2))
(c) 其中 RDD基本转换包括以下11中类型
本发所讲函数
1.reduce
2.collect
3.count
4.first
5.take
6.top
7.takeOrdered
8.countByKey
9.collectAsMap
10.lookup
11.aggregate
12.fold
13.saveAsFile
14.saveAsSequenceFile
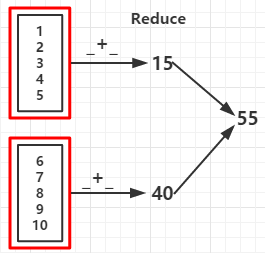
1.reduce(func):通过函数func先聚集各分区的数据集,再聚集分区之间的数据,func接收两个参数,返回一个新值,新值再做为参数继续传递给函数func,直到最后一个元素
2.collect():以数据的形式返回数据集中的所有元素给Driver程序,为防止Driver程序内存溢出,一般要控制返回的数据集大小
3.count():返回数据集元素个数
4.first():返回数据集的第一个元素
5.take(n):以数组的形式返回数据集上的前n个元素
6.top(n):按默认或者指定的排序规则返回前n个元素,默认按降序输出
7.takeOrdered(n,[ordering]): 按自然顺序或者指定的排序规则返回前n个元素
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("reduce")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(1 to 10,2)
val reduceRDD = rdd.reduce(_ + _)
val reduceRDD1 = rdd.reduce(_ - _) //如果分区数据为1结果为 -53
val countRDD = rdd.count()
val firstRDD = rdd.first()
val takeRDD = rdd.take(5) //输出前个元素
val topRDD = rdd.top(3) //从高到底输出前三个元素
val takeOrderedRDD = rdd.takeOrdered(3) //按自然顺序从底到高输出前三个元素
println("func +: "+reduceRDD)
println("func -: "+reduceRDD1)
println("count: "+countRDD)
println("first: "+firstRDD)
println("take:")
takeRDD.foreach(x => print(x +" "))
println("\ntop:")
topRDD.foreach(x => print(x +" "))
println("\ntakeOrdered:")
takeOrderedRDD.foreach(x => print(x +" "))
sc.stop
}
输出结果:
func +: 55 func -: 15 //如果分区数据为1结果为 -53 count: 10 first: 1 take: 1 2 3 4 5 top: 10 9 8 takeOrdered: 1 2 3
8.countByKey():作用于K-V类型的RDD上,统计每个key的个数,返回(K,K的个数)
9.collectAsMap():作用于K-V类型的RDD上,作用与collect不同的是collectAsMap函数不包含重复的key,对于重复的key。后面的元素覆盖前面的元素
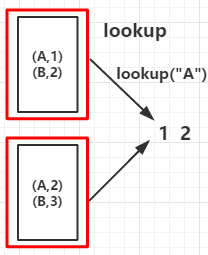
10.lookup(k):作用于K-V类型的RDD上,返回指定K的所有V值
例2:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
输出:countByKey: (B,2)(A,2) collectAsMap: (A,2)(B,3)
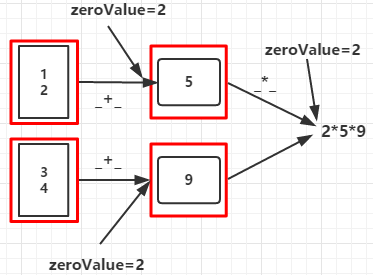
11.aggregate(zeroValue:U)(seqOp:(U,T) => U,comOp(U,U) => U):
seqOp函数将每个分区的数据聚合成类型为U的值,comOp函数将各分区的U类型数据聚合起来得到类型为U的值
| 1 2 3 4 5 6 7 8 |
|
输出:
90
步骤1:分区1:zeroValue+1+2=5 分区2:zeroValue+3+4=9
步骤2:zeroValue*分区1的结果*分区2的结果=90
(RDD依赖图)
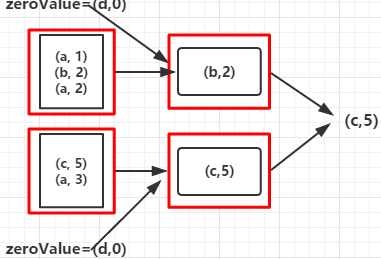
12.fold(zeroValue:T)(op:(T,T) => T):通过op函数聚合各分区中的元素及合并各分区的元素,op函数需要两个参数,在开始时第一个传入的参数为zeroValue,T为RDD数据集的数据类型,,其作用相当于SeqOp和comOp函数都相同的aggregate函数
例3
| 1 2 3 4 5 6 7 8 |
|
输出:
| 1 |
|
其过程如下:
1.开始时将(“d”,0)作为op函数的第一个参数传入,将Array中和第一个元素("a",1)作为op函数的第二个参数传入,并比较value的值,返回value值较大的元素
2.将上一步返回的元素又作为op函数的第一个参数传入,Array的下一个元素作为op函数的第二个参数传入,比较大小
3.重复第2步骤
每个分区的数据集都会经过以上三步后汇聚后再重复以上三步得出最大值的那个元素,对于其他op函数也类似,只不过函数里的处理数据的方式不同而已
(RDD依赖图)
13.saveAsFile(path:String):将最终的结果数据保存到指定的HDFS目录中
14.saveAsSequenceFile(path:String):将最终的结果数据以sequence的格式保存到指定的HDFS目录中