transformer ViT DERT
1 transformer
Attention Is All You Need https://arxiv.org/abs/1706.03762 NLP 机器翻译
具有全局语义特征提取融合及并行计算的特点。
1.1 整体模型结构
是一个encoder--decoder的结构,最核心的是attention模块。
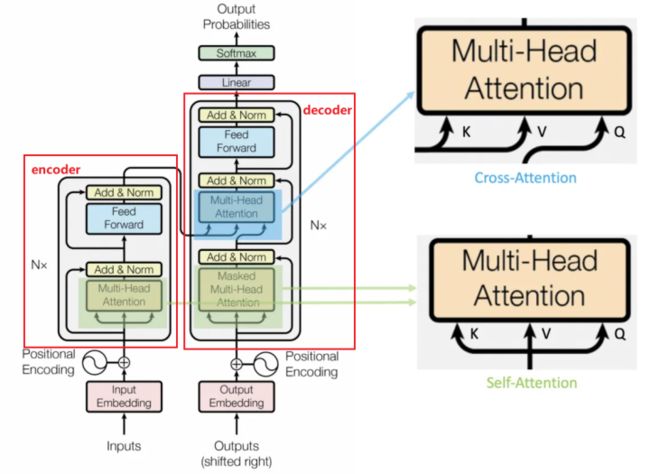
Transformer 中有两种注意力机制,self-attention 和 cross-attention。主要区别是query Q 的来源。
self attention 可以看作是原始特征域中的特征增强器,而 cross attention 则可以被视为跨域解码器。
1.2 Attention计算
并行计算,全局attention
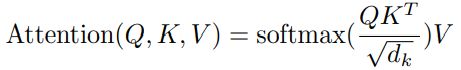

1.3 Position Embedding
在NLP中它是为了保持输入序列中单词顺序,这个向量决定了当前词的位置。
在CV领域就代表图像Patch的空间位置以及Patch之间的相互关系。图片天然是有强几何信息。
通常有两种位置编码方式: 一种通过训练学习 Position Embedding 向量,即是个可学习更新的向量; 一种使用编码公式来计算得到 Position Embedding向量,这种方式的编码值不变。 正余弦函数位置编码公式
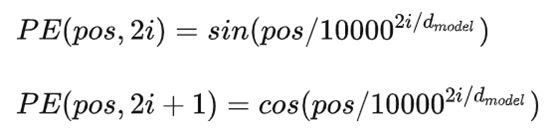
给定词语的位置pos,就可以把它编码成d_model维的向量,即与输入单词向量大小一致,两者相加作为encoder的输入。
2 ViT Vision Transformer
An image is worth 16x16 words: Transformers for image recognition at scale https://arxiv.org/abs/2010.11929
ViT使用Transformer self attention机制,对图片编码得到全局特征融合的高级语义特征,实现图像分类任务。 其中没有使用CNN,相当于把Transformer encoder当作一个backbone。
ViT的结构
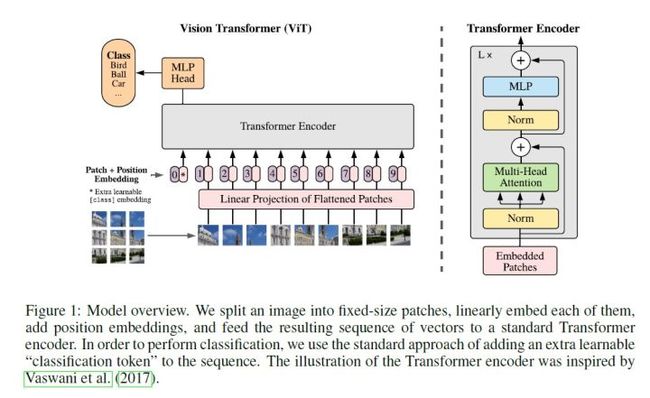
ViT可以分为以下几个步骤
1) patch embedding:将图片切分为固定大小的patch,每个patch通过线性投影固定长度的向量。设置一个特殊字符cls的可学习向量编码。 通过patch embedding将一个2d视觉问题转化为了一个1d序列问题。
2) position embedding:给每个patch embedding加上position embedding,以保留patch间的位置关系。
3) transformer encoder:将上面向量输入给标准的Transformer encoder,使用self-attention,encoder有多层。
4) MLP head:将特殊token 'cls' 对应的编码输出向量送入分类head,得到分类结果。
3 DETR
End-to-End Object Detection with Transformers https://arxiv.org/abs/2005.12872
DETR是第一篇将Transformer应用到目标检测的算法,是端到端的,无需anchor,无需nms后处理。 DETR是一个Encoder-Decoder结构的算法,它的骨干网络是一个卷积网络来提特征,Encoder和Decoder则是两个基于Transformer的结构,输出层则是MLP全连接层预测目标类别及其bbox。训练过程中,使用匈牙利匹配来分配正负样本计算loss。
1. 网络结构
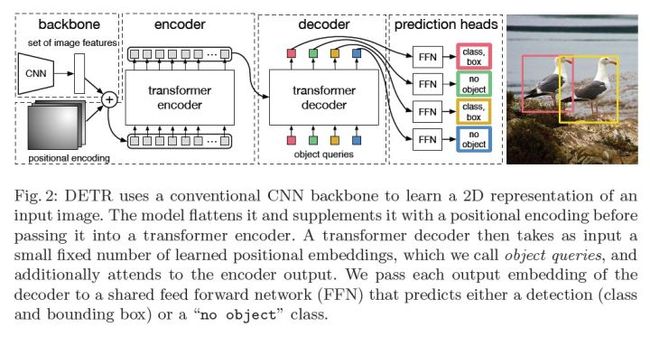
1.1 骨干网络 backbone是卷积网络,输出是下采样后的image features,维度为C×H×W。
1.2 Transformer编码器 image features具有2维空间位置关系,位置编码pos_x ,pos_y 拼接到一起,与features对应位置相加。 将image features 转换为序列数据,数据维度是 C×(HW) ,相当于HW个输入向量序列。 编码器使用的是self-attention 自注意力机制。
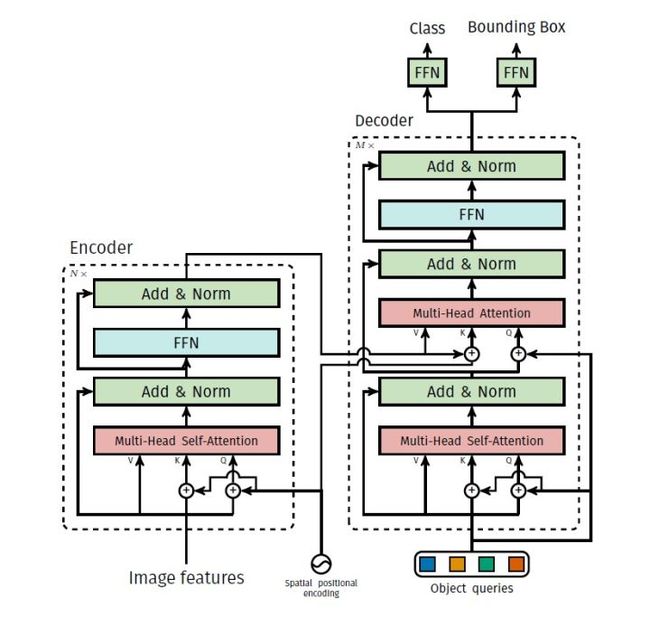
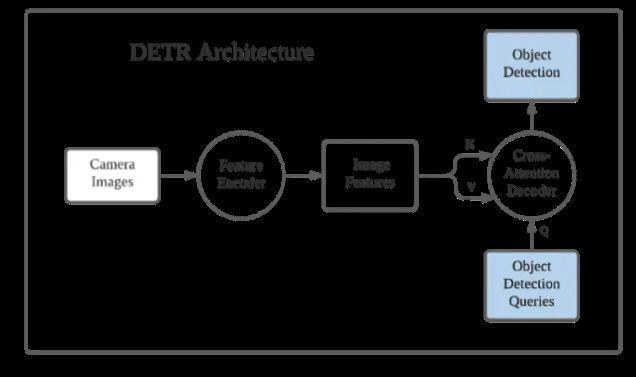
1.3 Transformer解码器
解码器有两个输入,一个是Encoder输出的特征,另外一个是object queries。
object queries 是预定义的N个可学习的query向量,DeTR默认 N=100 ,一张图像最多会被检测出100个物体。 它作用类似于基于CNN的目标检测算法中的anchor,不过,在这里它是一个可学习自适应更新的adaptive anchor。
Decoder里包含两个Attention模块:
第一个是self-attention,它的输入就是我们预定义的N个可学习的object queries,它们之间通过self-attention交互融合,尽量让每个query关注不同的检测目标,避免检测重复目标。
第二个是cross-attention,Q来自于第一个self-attention的输出,K和V来自于Encoder的输出features,让Q自适应的查询features中的有用信息,每个object query关注不同的目标信息。 解码器最终输出N个decoder output features,代表要检测的N个objects。
1.4 MLP预测头
预测头是多层全连接,每个Object query通过预测头预测目标的bounding box和类别。 N个Object query并行预测,得到 N个检测结果。
2. Loss
object queries预测出来N个检测框predicate bboxes,与ground-truth bboxes之间利用匈牙利算法进行二分图匹配,找到使得cost最小的最优匹配,并计算classification loss和bbox regression loss。
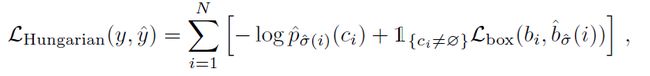
3. DETR的亮点
DETR的最大亮点就在于其基于query的解码来做检测的思路,非常具有启发性,相当于开拓了一个全新的思路,影响了后续很多的基于transformer的目标检测工作,Deformable DETR,DAB-DETR,DN-DETR,DINO,DETR3D。 就如同当初YOLO的出现。