python爬虫之scrapy框架(二)————scrapy框架的实际运用
一、使用Scrapy框架进行编程
1、创建爬虫:
Scrapy genspider 爬虫名 目标网站的域名

2、爬虫的主体函数:
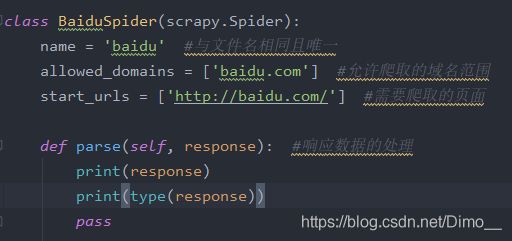
3、运行爬虫:
运行命令:scrapy crawl 爬虫名称
二、Scrapy Selectors的表达式机制:
1、Scrapy Selectors表达式机制基于xpath和CSS
2、Scrapy Selectors的四个基本方法:
(1)xpath():传入xpath表达式,返回该表达式所对应的所有节点的selector list列表。
(2)css():传入CSS表达式,返回该表达式所对应的所有节点的selector list列表。
(3)extract():序列化该节点为unicode字符串并返回list。
(4)re():根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
3、Selector选择器的使用方法:
(1)语法:
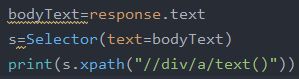
(2)返回结果:
![]()
三、Scrapy框架将数据存储到items结构中
1、确认爬取到的数据
用css()函数获取response对象中所需要的内容:
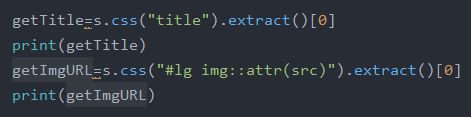
输出的结果:

2、在items.py文件的BaiduspiderItem()函数中加入想要存储的数据

3、在爬虫主文件中声明要在items中加入的数据
导入items.py文件对应的BaiduspiderItem()函数:
![]()
声明要在items中加入的数据:
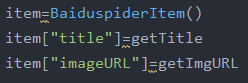
四、Scrapy框架将数据存储文件中
1、在items.py文件对应的BaiduspiderItem()函数中返回需要的参数
创建__str__函数,将本函数中需要存储在文件中的参数返回:

2、在pipelines.py文件中导入items.py文件对应的BaiduspiderItem()函数
![]()
3、通过isinstance()函数来判断从items.py中得到的参数item是否为BaiduspiderItem类型。
使用__str__()函数将需要存储的数据转换为字符串型
最后通过open的方法写入文件中
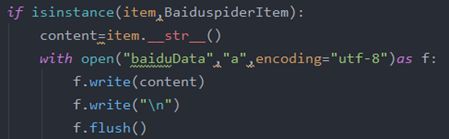
4、在爬虫主文件中通过yield返回所有的item
![]()
5、在爬虫的setting文件中声明pipeline的优先级

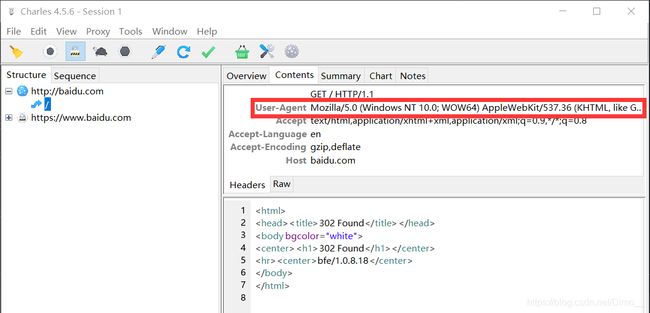
七、运用Charles抓取当前发送的请求进行伪装
1、正常用Scrapy访问网站时可以发现User-Agent无法进行伪装:

2、设置User-Agent伪装自己:
(1)在middlewares.py中引入UserAgentMiddleware包:
![]()
(2)在middlewares.py中创建一个BaiduUserAgentmiddleware类,并在其中定义处理请求的方法process_request,将请求头部的headers属性的User-Agent参数修改成浏览器访问时所使用的User-Agent:

(3)在爬虫的setting文件中声明UserAgent中间件的优先级:

(4)再次用Scrapy访问网站时可以发现User-Agent已经进行了伪装: