《精通Python爬虫框架Scrapy》
精通Python爬虫框架Scrapy
- 1. 简介(略)
- 2. 理解HTML和XPath
-
- 2.1 HTML、DOM树表示以及XPath
-
- 2.1.1 URL
- 2.1.2 HTML文档
- 2.2 使用XPath
-
- 2.2.1 有用的XPath语句
- 2.2.2 使用Chrome获取Xpath表达式
- 2.2.4 XPath语句常用规则
- 3. 爬虫基础
-
- 3.1 安装Scrapy
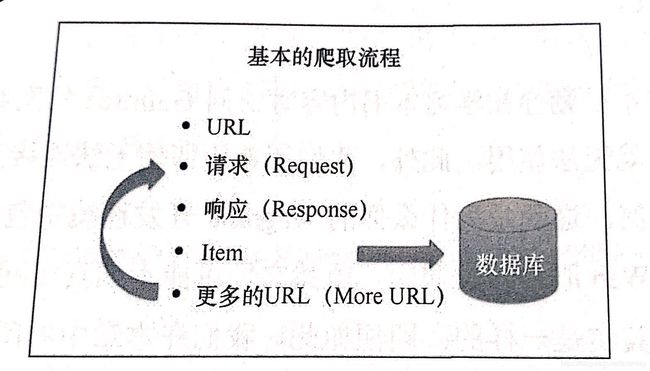
- 3.2 UR2IM——基本抓取流程
-
- 3.2.1 URL
- 3.2.2 请求和响应
- 3.2.3 Item
- 3.3 一个Scrapy项目
-
- 3.3.1 声明item
- 3.3.2 编写爬虫
- 3.3.3 填充item
- 3.3.4 保存文件
- 3.3.5 清理——item装载器与管理字段
1. 简介(略)
2. 理解HTML和XPath
2.1 HTML、DOM树表示以及XPath
2.1.1 URL
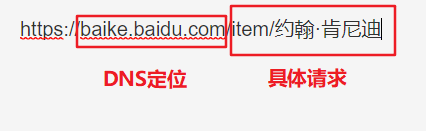
如下图,URL分为两个部分:
- DNS(域名系统)定位到服务器
- 使服务器理解具体的请求(此处为约翰肯尼迪的百度百科网页)
2.1.2 HTML文档
服务器读取URL请求后,大多时候会回应一个HTML文档
浏览器使用Ctrl+U,可直接看到HTML源代码
几个基本概念
标签:如和
元素:起始标签(如
)和结束标签(如
)之间的部分属性:如标签中的href属性
2.2 使用XPath
在开发者工具中使用控制台,使用 x 函 数 ( 如 x函数(如 x函数(如x(’//h1’)对应h1标签)选择html元素
2.2.1 有用的XPath语句
| 语句 | 作用 |
|---|---|
| //+元素 | 获得任意位置的该元素,当多个“//”一起使用的时候,有前后分层关系 |
| /@+属性 | 获取元素中的属性 |
| /元素[属性=值] | 返回特定属性 |
| /元素[contains(属性,模糊值)] | 模糊匹配,包含 |
| /元素[not(contains(属性,模糊值))] | 模糊匹配,不包含 |
| /元素[starts-with(属性,模糊值)] | 模糊匹配,以……开头 |
| /text() | 只返回文本 |
| //img/@src | 返回图片的url |
| /* | 返回层级所有元素 |
| /following-sibling::div | 选择某元素之后的所有div元素 |
2.2.2 使用Chrome获取Xpath表达式
使用chrome时,在html元素右键选择copy xpath

2.2.4 XPath语句常用规则
- 避免使用数组索引(数值)
- class属性常常会发生变化,并没有那么好用
- 有意义的面向数据的类要比具体的或面向布局的类更好
- ID通常是最靠谱的
3. 爬虫基础
3.1 安装Scrapy
pip安装Scrapy
pip install scrapy
pip升级Scrapy
pip install --upgrade Scrapy
3.2 UR2IM——基本抓取流程
3.2.1 URL
使用scrapy shell可进行简单请求
scrapy shell -s USER_AGENT="Mozilla/5.0" https://gumtree.com
使用–pdb参数启用交互式调试
scrapy shell --pdb https://gumtree.com
3.2.2 请求和响应
打印响应的前50个字符
response.body[:50]
3.2.3 Item
SEO,是搜索引擎优化的缩写,即通过优化网站代码、内容和出入站链接的流程,实现提供给搜索引擎的最佳方式
XPath的索引都是从1开始的,而非从0开始
Scrapy的XPath需要使用extract方法提取文本数组,同时可以使用re()方法进行正则匹配
In [10]: response.xpath('//*[@id="content"]/p[11]/text()').extract()
Out[10]: ['学习 100 多个 JavaScript 实例!']
In [11]: response.xpath('//*[@id="content"]/p[11]/text()').re('[.0-9]+')
Out[11]: ['100']
xpath()和css()返回的Selector对象是可以被串联起来的
3.3 一个Scrapy项目
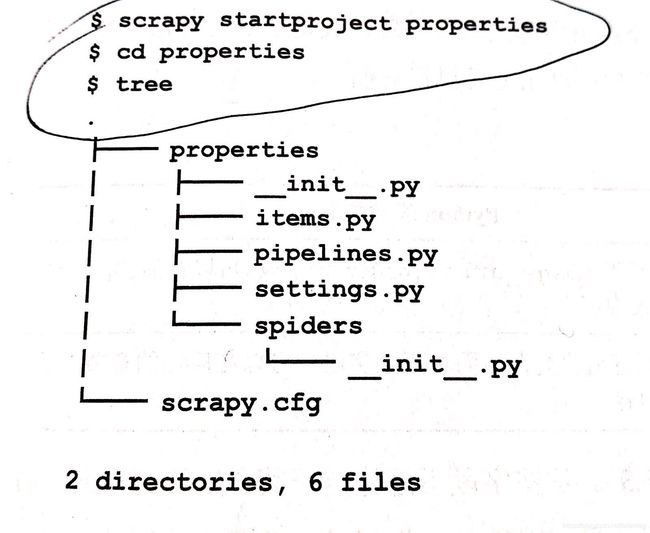
创建Scrapy项目
scrapy startproject properties(项目名称)
cd properties #进入项目根目录
tree #查看项目结构
3.3.1 声明item
| 可计算字段 | Python表达式 |
|---|---|
| images | 图像管道将会基于image_url自动填充该字段 |
| location | 地理编码管道将会在后面填充该字段 |
| 管理字段 | Python表达式 |
|---|---|
| url | response.url |
| project | self.settings.get(‘BOT_NAME’) |
| spider | self.name |
| server | socket.gethostname() |
| date | datetime.datetime.now() |
from scrapy.item import Item,Field
class TestProjectItem(Item):
# Primary Fields
title = Field()
content = Field()
# Caculated Fields 可计算字段
images = Field()
location = Field()
# Housekeeping Fields 管理字段
url = Field()
project = Field()
spider = Field()
server = Field()
date = Field()
3.3.2 编写爬虫
在spider文件夹自动创建一个默认爬虫“basic.py”
scrapy genspider basic web
自动生成的basic爬虫如下

根据需求修改后:
import scrapy
class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['web']
#网址
start_urls = ['https://www.runoob.com/js/js-tutorial.html']
#Xpath爬虫部分
def parse(self, response):
self.log("title:%s" % response.xpath("//div[@id='content']/h1/text()").extract())
self.log("content:%s" % response.xpath("//*[@class='tutintro']/p/text()").extract())
使用scrapy crawl命令运行爬虫
scrapy crawl basic
使用scrapy parse命令解析任意相似URL
scrapy parse --spider=basic https://www.runoob.com/r/r-tutorial.html
3.3.3 填充item
在basic.py中引入items.py中的TestProjectItem模块并实例化
import scrapy
#引入模块
from test_project.items import TestProjectItem
class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['web']
start_urls = ['https://www.runoob.com/js/js-tutorial.html']
def parse(self, response):
#实例化
item = TestProjectItem()
item['title'] = response.xpath("//div[@id='content']/h1/text()").extract()
item['content'] = response.xpath("//*[@class='tutintro']/p/text()").extract()
3.3.4 保存文件
scrapy爬虫结果可保存为json、csv、xml等格式
scrapy crawl basic -o items.json
cat items.json
3.3.5 清理——item装载器与管理字段
使用ItemLoader可以取代extract()和xpath()
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose
from properties.items import PropertiesItem
class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['web']
start_urls = ['http://web/']
start_urls = (
'https://www.gumtree.com/flats-houses/london',
)
def parse(self, response):
l = ItemLoader(item=PropertiesItem(), response=response)
l.add_xpath('title', '//*[@itemprop="name"][1]/text()',
MapCompose(str.strip, str.title))
return l.load_item()
| 处理器 | 功能 |
|---|---|
| Join() | 把多个结果连接在一起 |
| MapCompose(unicode.strip) | 去除首尾的空白符 |
| MapCompose(unicode.strip,unicode.title) | 与MapCompose(unicode.strip)相同,不过还会使结果按照标题格式 |
| MapCompose(float) | 将字符串转为数值 |
| MapCompose(lambda i : i.replace(’,’,’’),float) | 将字符串转为数值,并忽略可能存在的‘,’字符 |
| MapCompose(lambda i : urlparse.urljoin(response.url,i)) | 以response.url为基础,将URL相对路径转化为URL绝对路径 |