ICML long talk | 达摩院开源半监督学习框架Dash
一、论文&代码
论文链接:Dash: Semi-Supervised Learningwith DynamicThreolding
开源代码:https://github.com/idstcv/Dash
技术应用:https://modelscope.cn/models/damo/cv_manual_face-liveness_flrgb/summary
二、背景
本文介绍我们被机器学习顶级国际会议ICML 2021接收的long talk (top 3.02%) 论文 “Dash: Semi-Supervised Learning with Dynamic Thresholding”。论文创新性地提出用动态阈值(dynamic threshold)的方式筛选无标签样本进行半监督学习(semi-supervisedlearning,SSL)的方法,我们改造了半监督学习的训练框架,在训练过程中对无标签样本的选择策略进行了改进,通过动态变化的阈值来选择更有效的无标签样本进行训练。Dash是一个通用策略,可以轻松与现有的半监督学习方法集成。实验方面,我们在CIFAR-10,CIFAR-100, STL-10和SVHN等标准数据集上充分验证了其有效性。理论方面,论文从非凸优化的角度证明了Dash算法的收敛性质。
2.1 监督学习(SupervisedLearning)
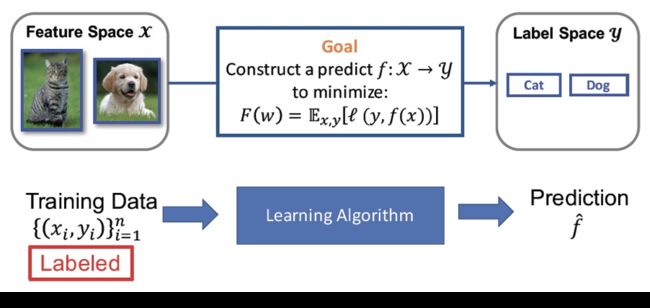
我们知道模型训练的目的其实是学习一个预测函数,在数学上,这可以刻画成一个学习从数据(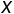 )到标注(
)到标注(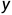 )的映射函数。监督学习就是一种最常用的模型训练方法,其效果的提升依赖于大量的且进行了很好标注的训练数据,也就是所谓的大量带标签数据(
)的映射函数。监督学习就是一种最常用的模型训练方法,其效果的提升依赖于大量的且进行了很好标注的训练数据,也就是所谓的大量带标签数据( )。但是标注数据往往需要大量的人力物力等等,因此效果提升的同时也会带来成本过高的问题。在实际应用中经常遇到的情况是有少量标注数据和大量未标注数据,由此引出的半监督学习也越来越引起科学工作者的注意。
)。但是标注数据往往需要大量的人力物力等等,因此效果提升的同时也会带来成本过高的问题。在实际应用中经常遇到的情况是有少量标注数据和大量未标注数据,由此引出的半监督学习也越来越引起科学工作者的注意。
2.2 半监督学习(Semi-SupervisedLearning)

半监督学习同时对少量标注数据和大量未标注数据进行学习, 其目的是借助无标签数据来提高模型的精度。比如self-training就是一种很常见的半监督学习方法,其具体流程是对于标注数据 学习数据从到的映射,同时利用学习得到的模型对未标注数据预测出一个伪标签
学习数据从到的映射,同时利用学习得到的模型对未标注数据预测出一个伪标签 ,通过对伪标签数据
,通过对伪标签数据 进一步进行监督学习来帮助模型进行更好的收敛和精度提高。
进一步进行监督学习来帮助模型进行更好的收敛和精度提高。
2.3 核心问题

现有的半监督学习框架对无标签数据的利用大致可以分为两种,一是全部参与训练,二是用一个固定的阈值卡出置信度较高的样本进行训练(比如FixMatch)。由于半监督学习对未标注数据的利用依赖于当前模型预测的伪标签,所以伪标签的正确与否会给模型的训练带来较大的影响,好的预测结果有助于模型的收敛和对新的模式的学习,差的预测结果则会干扰模型的训练。所以我们认为:不是所有的无标签样本都是必须的!
三、方法
3.1 Fixmatch训练框架

在引出我们的方法Dash之前,我们介绍一下Google提出的FixMatch算法,一种利用固定阈值选择无标签样本的半监督学习方法。FixMatch训练框架是之前的SOTA解决方案。整个学习框架的重点可以归纳为以下几点:
1、对于无标签数据经过弱数据增强(水平翻转、偏移等)得到的样本通过当前的模型得到预测值
2、对于无标签数据经过强数据增强(RA or CTA)得到的样本通过当前的模型得到预测值
3、把具有高置信度的弱数据增强的结果,通过one hot的方式形成伪标签,然后用和经过强数据增强得到的预测值进行模型的训练。
fixmatch的优点是用弱增强数据进行伪标签的预测,增加了伪标签预测的准确性,并在训练过程中用固定的阈值0.95(对应loss为0.0513) 选取高置信度(阈值大于等于0.95,也就是loss小于等于0.0513)的预测样本生成伪标签,进一步稳定了训练过程。
3.2 Dash训练框架
针对全部选择伪标签和用固定阈值选择伪标签的问题,我们创新性地提出用动态阈值来进行样本筛选的策略。即动态阈值 是随t衰减的
是随t衰减的

式中 是有标签数据在第一个epoch之后loss的平均值,我们选择那些
是有标签数据在第一个epoch之后loss的平均值,我们选择那些 的无标签样本参与梯度回传。下图展示了不同
的无标签样本参与梯度回传。下图展示了不同 值下的阈值的变化曲线。可以看到参数控制了阈值曲线的下降速率。的变化曲线类似于模拟训练模型时损失函数下降的趋势。
值下的阈值的变化曲线。可以看到参数控制了阈值曲线的下降速率。的变化曲线类似于模拟训练模型时损失函数下降的趋势。

下图对比了训练过程中的FixMath和Dash选择的正确样本数和错误样本数随训练进行的变化情况(使用的数据集是cifar100)。从图中可以很清楚地看到,对比FixMatch,Dash可以选取更多正确label的样本,同时选择更少的错误label的样本,从而最终有助于提高训练模型的精度。

我们的算法可以总结为如下Algorithm 1。Dash是一个通用策略,可以轻松与现有的半监督学习方法集成。为了方便,在本文的实验中我们主要将Dash与FixMatch集成。

更多理论证明详见论文。
四、结果
我们在半监督学习常用数据集:CIFAR-10,CIFAR-100,STL-10和SVHN上进行了算法的验证。结果分别如下:
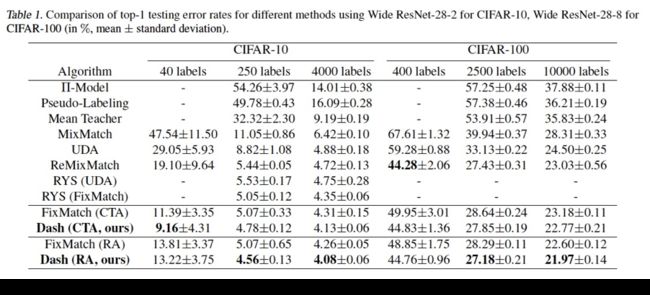
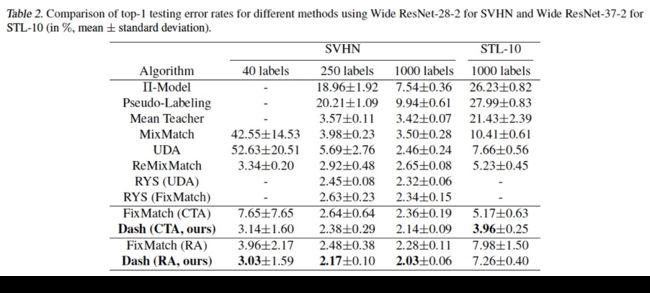
可以看到我们的方法在多个实验设置上都取得了比SOTA更好的结果,其中需要说明的是针对CIFAR-100 400label的实验,ReMixMatch用了data align的额外trick取得了更好的结果,在Dash中加入data align的trick之后可以取得43.31%的错误率,低于ReMixMatch 44.28%的错误率。
五、应用
实际面向任务域的模型研发过程中,该半监督Dash框架经常会被应用到。接下来给大家介绍下我们研发的各个域上的开源免费模型,欢迎大家体验、下载(大部分手机端即可体验):
https://modelscope.cn/models/damo/cv_resnet50_face-detection_retinaface/summary
https://modelscope.cn/models/damo/cv_resnet101_face-detection_cvpr22papermogface/summary
https://modelscope.cn/models/damo/cv_manual_face-detection_tinymog/summary
https://modelscope.cn/models/damo/cv_manual_face-detection_ulfd/summary
https://modelscope.cn/models/damo/cv_manual_face-detection_mtcnn/summary
https://modelscope.cn/models/damo/cv_resnet_face-recognition_facemask/summary
https://modelscope.cn/models/damo/cv_ir50_face-recognition_arcface/summary
https://modelscope.cn/models/damo/cv_manual_face-liveness_flir/summary
https://modelscope.cn/models/damo/cv_manual_face-liveness_flrgb/summary
https://modelscope.cn/models/damo/cv_manual_facial-landmark-confidence_flcm/summary
https://modelscope.cn/models/damo/cv_vgg19_facial-expression-recognition_fer/summary
https://modelscope.cn/models/damo/cv_resnet34_face-attribute-recognition_fairface/summary