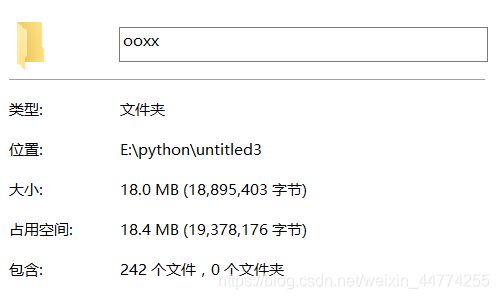
爬虫 ------爬取网页的图片
借鉴: 添加链接描述,并进行部分修改,使之能运行
基于小甲鱼视屏的代码修改:(图片的网址经过了base64加密,因此需要解密才能正常使用):
一般的网页,图片与下一个图片之间,在地址上提现出来就是数字的变化:
第一张的网址为:
![]()
而下一张是:

而视屏中的页面对网址用了base64加密
![]()

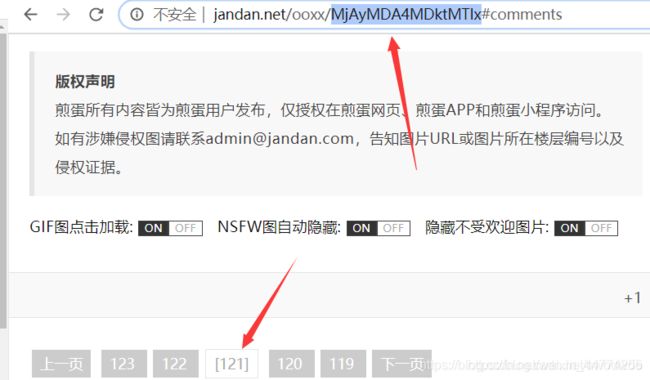
这里的MjAyMDA4MDktMTIx其实就是加密信息:
利用解码可知即是20200809-121
而 121 查看网页的信息:就是当前的第几张图片
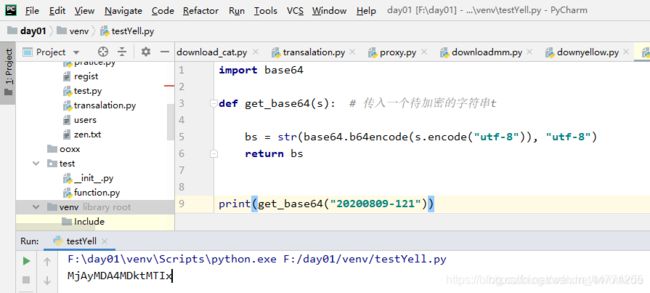
获取当前日期的代码:
import datetime
time = datetime.datetime.now().strftime('%Y%m%d-')
import base64
# 获取经过base64加密后的字母串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs
利用其对20200809-121加密,可得知其结果与网页一样,所以可证网址由base64加密
爬取图片源码如下:
主方法:
1、先创建文件,命名为"ooxx"
2、get_page()函数是这个样子的:返回的是网页的数字部分

def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
3、for i in range(pages): # 只获取前10页的数据是指的获取从当前页面,第一次减0,就是当前页面,第二次减1,就是下一个页面,以此类推,一共是10个页面,page_url:指的是每一页的地址
4、获取page_url:重点
测试:页码为121的页面地址能不能正确获取:
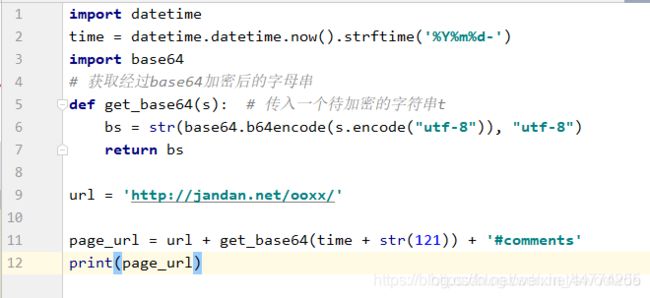
运行结果:

网页地址:
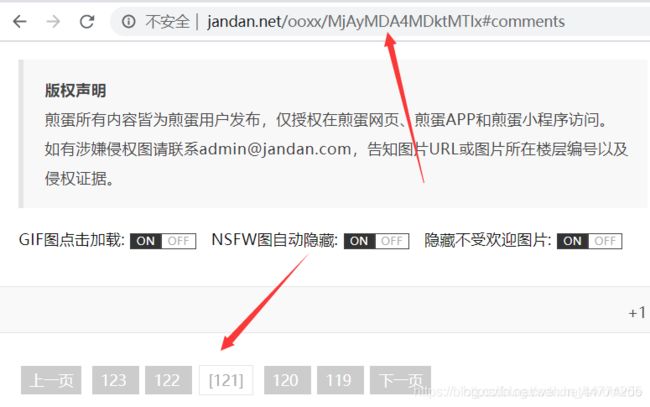
所以找到了页面的地址了,接下来就是获取页面的源代码,并且从源码中获取图片的位置
5、通过网址如何获取 html 页面内容:
设置请求头,目的是使爬从操作,可以拥有电脑的标识
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)#创建request对象,利用request对象访问
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
6、find_imgs 函数:通过html内容获取图片的地址,还没讲正则表达式, 暂时使用find方法
就是获取了img src后面,.jpg 前面的内容。然后设置一个循环,查找出当前页面的所有符合条件的图片,然后保存
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs
7、找到地址下载并且保存
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]#取url最后一段作为名字
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
import base64
import urllib.request
import os
import datetime
time=datetime.datetime.now().strftime("%Y%m%d-")
#得到经过base64加密后的字符串
def get_base64(s): # 传入一个待加密的字符串t
bs = str(base64.b64encode(s.encode("utf-8")), "utf-8")
return bs #因为所要获取的网页是经过base64加密的,因此我们需要利用此来正确访问页面
#打开页面
def url_open(url):
#设置headers,使我们的程序访问看上去像是人为
req=urllib.request.Request(url)
req.add_header('user-AGENT','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
#print(html)
return html
def get_page(url):
#获取当前网页图片是第几张,以此为基准下载图片
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
return html[a:b]
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
a=html.find('img src=')
while(a!=-1):
b=html.find('.jpg',a,a+255)#没找到就会返回-1
if b!=-1:
img_addrs.append('http:'+html[a+9:b+4])#需要加上http:否则获取的地址是无法识别的url
else:
b=a+9
a=html.find('img src=',b)
#用于得到,存放图片地址
#for each in img_addrs:
# print(each)
return img_addrs#需要返回这个地址链表,否则在save_img中无法迭代
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename=each.split('/')[-1]
with open(filename,'wb') as f:
img=url_open(each)
f.write(img)
def download(folder='ooxx',pages=10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num=int(get_page(url))
for i in range(pages): # 只获取前10页的数据
page_num -= i
page_url = url + get_base64(time + str(page_num)) + '#comments'
# 找到当前页面的所有图片
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__=='__main__':
download()
最终成功爬取图片