综述论文阅读”A survey on contrastive self-supervised learning“(Technologies2020)
论文标题
A survey on contrastive self-supervised learning
论文作者、链接
作者:Jaiswal, Ashish and Babu, Ashwin Ramesh and Zadeh, Mohammad Zaki and Banerjee, Debapriya and Makedon, Fillia
链接:Technologies | Free Full-Text | A Survey on Contrastive Self-Supervised Learning
Introduction逻辑(论文动机&现有工作存在的问题)
深度学习在很多智能系统中表现出色:图像分类,目标检测,图像分割,行为识别,自然语言处理(NLP)——有监督的学习往往需要大量的人力对数据进行标注——无监督学习可以在没有人工标注的情况下对自己进行监督——生成对抗方法(GAN),学习潜在的特征表达,任务诸如:图像上色,图像修补,拼图问题,超分辨率,视频帧预测,音频虚拟化——生成对抗方法有两个主要面对的问题:(1)非收敛性模型参数振荡很大,很少收敛,(b)鉴别器太成功了,导致生成器网络无法产生类真伪样本,导致学习无法继续(当然,生成器和鉴别器之间需要适当的同步,以防止鉴别器收敛和生成器发散。)
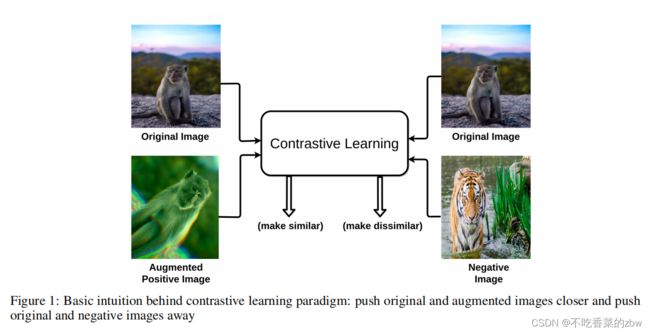
与生成模型不同,对比学习如图1所示,目标是将相似的样本聚集起来,将不同的样本推远——用相似性尺度去衡量两个嵌入之间的远近

对比学习的训练过程如图2所示,原样本的增广版本视为一个正样本,然后剩下的样本都视为负样本——训练过程就是学习区别正负样本的过程——训练完可以得到高质量的特征表示,然后将这些特征可以用于迁移学习或是直接用到下游任务
代理任务Pretext Tasks
代理任务是自监督任务,是学习使用伪标签表示数据的重要策略。伪标签是根据数据本身自动生成的。大多数代理任务分为以下几类:颜色转换,几何转换,基于内容的任务,基于跨通道的任务
颜色转换

如图4所示,颜色变换涉及图像中颜色层次的基本调整,比如:模糊,颜色扭曲,灰度。在代理任务中,模型的任务是识别相似的图片并且复原他们的颜色
几何转换

如图5所示,几何变换是一种空间变换,其中图像的几何位置被修改,而不改变其实际像素信息,包括:缩放,随机裁剪,翻转(水平,垂直)。原始图片被视为是一个全局视图,转换后的图片被视为是一个局部视图
基于内容Context-Based
拼图任务Jigsaw puzzle

拼图任务是通过训练一个编码器,识别打乱的图块的正确位置
基于帧的顺序Frame order based
这种方法适用于穿越时间的数据。理想的应用场景是用于传感数据或是视频数据。一个视频里包含大量有语义相关的帧,这意味着时间上相邻的帧相关性更高。还原帧的顺序的过程中,模型可以学习到有用的视觉信息。在这个任务中,正序的视频是正样本,乱序的视频是负样本。类似地,其他可能的方法包括从较长的视频中随机抽样两个相同长度的视频片段或对每个视频片段应用空间增强,然后任务目标是使用对比损失来训练模型,使来自同一视频的片段排列得更近,而来自不同视频的片段在嵌入空间中被推开。
未来预测Future prediction

常用策略是预测未来的信息,一般用于时序数据,根据过去的数据预测未来的高维信息。利用强大的自回归模型对潜在空间中的信息进行汇总,产生了如图7所示的上下文潜在表征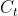 。在预测未来信息时,目标(未来)和上下文被编码成一个紧凑的分布式向量表示,最大限度地保留了原始信号的互信息。
。在预测未来信息时,目标(未来)和上下文被编码成一个紧凑的分布式向量表示,最大限度地保留了原始信号的互信息。
视图预测View Prediction(Cross modal-based)
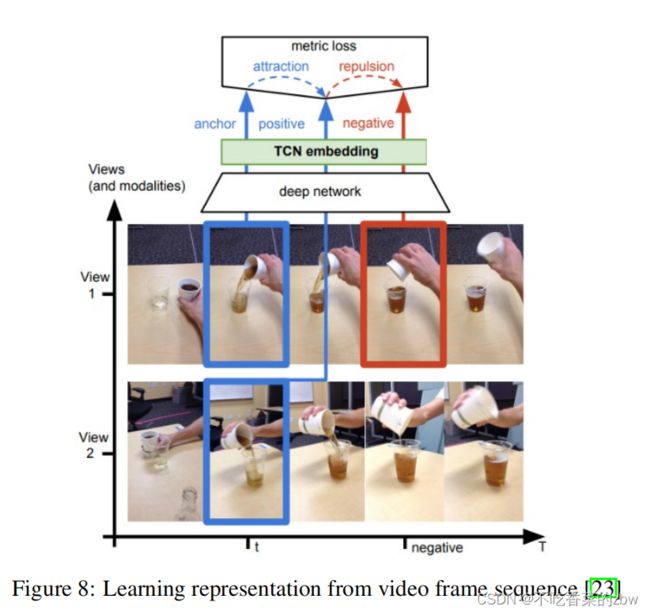
视图预测倾向于在同一个场景下的视图的不同数据,同一个时刻下的同一个对象的不同视图为正样本。模型通过尝试同时识别不同角度的帧之间的相似特征,并试图找出序列中随后出现的帧之间的差异来进行学习。
判断正确的代理任务Identifying the right pre-text task

对代理任务的选择,取决于需要处理的问题。虽然出现了大量的对比学习算法,但是如何选择一个合适的代理任务仍然是一个问题。并且,代理任务的选择极大程度影响模型最后的性能结果。代理任务的主要目标是,使得模型对这些转换保持不变同时区别其他的数据点。但是,通过这种增广而引入的偏见可能是一把双刃剑,因为每一次增广都鼓励转换的不变性,这种不变性在某些情况下是有益的,在另一些情况下是有害的。比如,在图像识别中,旋转可能是有益的,但是可能对下有任务是有害的。相似的是,基于颜色的代理任务可能在图9这种精细的分类任务中无效。
在其他的情况下,除了旋转,其他的数据增广比如放缩或是改变比率可能对代理任务是不合时宜的,因为它们产生易于检测的视觉伪影。当目标数据集中的图像是由颜色纹理构成的时,旋转效果不佳,如图10所示
NLP中的代理任务
(本人不做NLP,略过)
结构Architectures
对比学习依赖于负样本的数量来生成高质量的特征表示。这个过程可以视为是一个字典查询任务,有时一整个训练集都是字典,有时是训练集的子集是字典。结构主要分成4种,如图11所示

端到端学习
端到端学习的模型是一种基于梯度下降的复杂学习系统,倾向于使用大的batch-size来聚集大数量的负样本。除了原本的图片及其增广的视图,batch内的其他图片都视为负样本。使用了两种编码器:查询编码器(Query encoder,Q)和键编码器(Key encoder,K),如图11(a)所示。这两个编码器是不同的,在训练过程中通过反向传播来端到端的更新参数。使用一个对比损失来训练这两个编码器,对每一个样本生成有区别的特征表达,使得正样本拉近负样本远离。Q是在原始样本上训练的,K是在增广视图上训练的。Q与K生成的特征记为q,k,通过相似性尺度来计算q和k的相似性。大多数使用余弦相似性来计算相似性尺度。
Memory Bank的使用
端到端的方法往往因为要在显存中存放大量的负样本,对batch-szie的要求比较高,对设备的要求高,于是可以通过使用memory bank来解决这些问题。
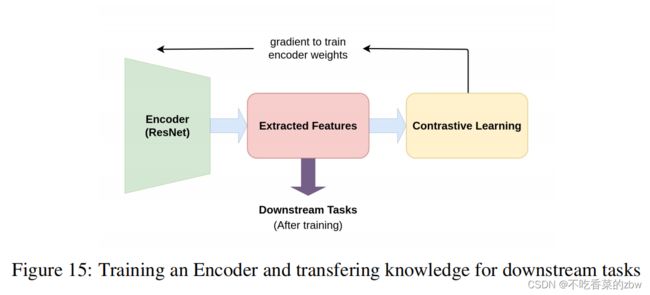
Memory Bank:维护memory bank的主要目标是聚集大量的样本特征,在训练过程中当成负样本来使用。为此,创建一个字典来保存和更新最近的训练轮次中的样本点的特征嵌入。memory bank(M)包含对每一个样本I的特征表达![]() ,这个表达
,这个表达![]() 是在每一个训练轮次根据特征表达的指数值平均移动的。使得memory bank可以代替负样本
是在每一个训练轮次根据特征表达的指数值平均移动的。使得memory bank可以代替负样本
memory bank中的特征是根据最新学到的特征进行更新的,所以样本的键(key)对编码器的多个步骤都非常重要。PIRL通过memory bank学习到不错的特征表达,如图13所示

但是维护memory bank其实也是一个复杂的任务,更新memory bank中的特征的计算代价可能是非常高昂的
Momentum Encoder的使用
为了解决memory bank的缺点,用momentum encoder代替memory bank。momentum encoder生成一个有编码后的键值构成的队列字典,最新的mini-batch的特征入队,最老的mini-batch的特征出队。字典键在训练过程中由batch中的一组数据样本动态定义。momentum encoder与Q编码器参数共享,如图11(c)所示。momentum encoder不进行反向传播,而是根据Q编码器的参数进行更新,公式如下:

其中,![]() 是动量参数。只有参数
是动量参数。只有参数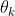 是通过反向传播更新的。动量更新使得比
是通过反向传播更新的。动量更新使得比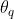 更新的更加平滑。于是,虽然队列中的键是通过不同的编码器进行编码的(在不同的mini-batch轮次中的编码器参数不一样),但是编码器之间的差异会比较小。
更新的更加平滑。于是,虽然队列中的键是通过不同的编码器进行编码的(在不同的mini-batch轮次中的编码器参数不一样),但是编码器之间的差异会比较小。
momentum encoder的优点是不用训练两个独立的分支,而且计算开销比memory bank小
对特征表达进行聚类
上面的三种方法主要是使用相似性尺度来保持正样本拉近,负样本推远。还有一种方法通过聚类将相似的特征聚集起来

如图14所示,SwAV不仅使得样本对靠近,而且从聚类层面上将相似的特征聚集起来。在基于实例的学习中,每个样本都被视为一个数据集中独立的类。这使得它在将输入样本与原始样本所属的同类中的其他样本进行比较时不可靠。比如,假设在训练batch中有一张猫的照片,所有其他图片都被视为负样本,当将其他猫的图片视为负样本的时候便出现问题了。这种情况下,会致使模型学习两个猫的图片作为不相似的负样本。这个问题通过聚类的方法隐式地解决了。
编码器
encoder将输入样本映射到潜在空间中。图15反映了encoder在自监督学习中的作用。没有有效特征提取,一个分类模型可能很难学习如何区分不同的类。大部分对比学习模型使用ResNet作为主干网络,其中ResNet-50应用最为广泛。
在编码器中,某一个具体的层的输出通过池化得到一个单维的向量,没有使用上\下采样。有实验表明,编码器最后一层提取到的特征比前面的层提取到的特征更好。还有研究用ResNet作为编码器,然后通过网络加一个平均池化层得到特征,然后用一个浅层的MLP(1层)将特征映射到潜空间,然后在潜空间上应用对比损失。
训练
对于编码器的训练,通过一个代理任务来为反向传播计算对比损失。核心思想是使得相似的实例靠近,不相似的实例推远,实现方法是通过计算两个嵌入之间的相似性尺度,常用余弦相似性,公式如下:

对比学习通过Noise Contrastive Estimation (NCE)损失函数对向量进行比较,如下:

其中 是原始样本,
是原始样本,![]() 代表正样本,
代表正样本,![]() 代表负样本,
代表负样本, 是温度参数。
是温度参数。![]() 可以是任何相似性函数,不过常用余弦相似性。NCE的最初想法是执行非线性逻辑回归,区分观测数据和一些人为产生的噪声。
可以是任何相似性函数,不过常用余弦相似性。NCE的最初想法是执行非线性逻辑回归,区分观测数据和一些人为产生的噪声。
如果负样本的数量变大,则使用NCE的变种,成为InfoNCE,如下:

其中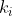 代表负样本。
代表负样本。
与其他深度学习方法相似,对比学习也有多种优化器optimizer可以使用。随机梯度下降(SGD),Adam都是常用的优化器。SGD还有一种随着时间变化参数的变种,还有动量SGD。
在大batch-size的情况下,用SGD来训练可能会导致不稳定,于是利用Layer-wise Adaptive Rate Scaling (LARS)优化器,带余弦学习率。LARS对每一层的学习率都不一样,并且更新的幅度是基于权重准则,以更好地控制学习率。此外,使用余弦学习率涉及到SGD的周期性热重启,在每次重启中,学习率初始化为某个值,并计划随着时间的推移而降低。
下游任务

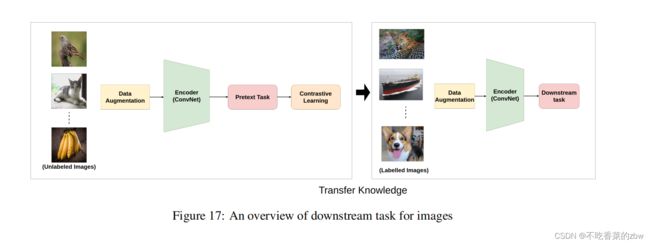
卷积核可视化以及特征图

本节,编码器的第一层是以自监督对比学习方式训练以及有监督的方式训练的。根据编码器中不同层级的注意力图用来评估一个方法使用奏效。有效性基于输入中观察到的激活区域,如图18
Benchmarks
略过
NLP中的对比学习
略过
未来发展方向
缺乏理论基础
训练方法高度依赖于训练过程中选择的代理任务。需要对模型有更多的理论分析
对于数据增广和代理任务的选择
很难直接比较这些对比学习方法来选择能够在任何数据集上产生最佳结果的特定任务和转换
合适的负样本
负样本引入了大量特定于训练集的超参数,并且很难推广到其他数据集。