【Vision-Language】VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
链接:https://arxiv.org/pdf/2111.02358.pdf
简介
首先我们做一些背景介绍,什么是vision-language?
众所周知,目前人工智能涉及一个领域叫:多模态学习。简单而言,这个领域研究的重点在于如何将两种不同的东西联系起来,一起学习知识。比如:
- 不同媒介:图像和文字,视频和语音
- 不同语言:汉语和英语
因此 vision-language(VL)就是研究视觉与语言的联系,比如:给一张图片让计算机生成一段描述文字(图像描述生成,Image Caption);给一张图片让计算机回答问题(视觉推理,Visual Reasoning)。
由于近年来Computer Vision(计算机视觉) 和 Natural Language Processing (自然语言处理) 利用机器学习发展迅猛,因此VL作为CV+NLP的领域也收到了巨大关注。
近年来,预训练-微调 模型在CV和NLP取得了惊人的成果,在VL领域也当然有所建树。
VL预训练模型从大规模的图像-文本对中学习通用的跨模态表示。主要方法有:图像-文本匹配、图像-文本对比学习、masked region classification/feature regression、word-region/patch alignment和掩码语言建模。
这些方法都是啥呢?简单介绍一下:
- 图像-文本匹配:度量一幅图像和一段文本的相似性
- 图像-文本对比学习:将样例与与它语义相似的例子(正样例)和与它语义不相似的例子(负样例)进行对比,希望通过设计模型结构和对比损失,使语义相近的例子对应的表示在表示空间更接近,语义不相近的例子对应的表示距离更远,以达到类似聚类的效果。
- masked region classification/feature regression:将一些感兴趣区域(RoI,Region of Interest) 遮盖,让计算机预测被遮盖的RoI标签/特征。
- word-region/patch alignment:将文本的Token与图像的RoI进行匹配。
- 掩码语言建模:比如BERT。
从模型结构上来说,有两种结构占据主流:
- 双编码器结构dual-encoder:2个encoder分别对图像和文本进行编码,然后对2个embedding计算余弦相似度。优点:适合检索任务,善于检索大量的文本与图片。缺点:余弦相似度的信息量太少,不能处理复杂的VL任务,比如视觉推理。
- 特征融合编码器fusion encoder:通过对所有图像-文本对编码,将图像和文本的representation都融合起来,通常使用多层Transformer。优点:善于解决分类问题。缺点:因为要encode所有图像-文本对,时间复杂度大,不善于解决检索问题。
那么一个直觉的想法是:能不能融合这两个架构的优点呢?
本文正是出于对此的思考,提出了统一视觉语言预训练模型(VLMo)。VLMo可以作为双编码器去做检索任务,也可以作为融合编码器去做分类任务。
VLMo的核心是Mixture-of-Modality-Experts(MOME) Transformer,就是将Transformer的前馈网络替换成了针对不同任务的网络(称为模态专家),在处理具体任务时,可以切换到相应的专家。
专家处理的是每个任务特有的知识,相应的,我们还要有一个机制来处理VL的普遍知识。因此,作者引入了跨模态共享的self-attention。
具体来说,MOME Transformer包含三个模态专家,即图像编码视觉专家、文本编码语言专家和图像-文本融合视觉语言专家。
模型可以使用切换机制和共享参数机制来实现不同的目的:文本编码器、图像编码器和图像-文本融合编码器。
在预训练阶段,VLMo会在在图像-文本对比学习、图像-文本匹配和掩码语言建模三个预训练任务上共同训练。流程:
- 首先,利用BEIT中提出的遮盖图像建模,让MOME的视觉专家和self-attention只在图像数据上进行预训练;
- 然后,利用掩码语言建模,只让语言专家在文本数据上进行预训练。
- 最后,利用该模型来初始化视觉语言的预训练。
预训练结束后就可以在特定任务上微调了。
针对检索任务,VLMo可以调整成双编码器结构;针对分类任务,VLMo可以调整成特征融合编码器结构。
作者将VLMo运用于视觉语言检索和分类任务。实验结果表明;
- 在检索任务上,VLMo比融合编码器的性能更好,同时推理速度要快得多。但不如双编码器。
- 在视觉问答(VQA)和视觉推理的自然语言(NLVR2)方面,VLMo取得了SOTA的结果。
VLMo

VLMo的整体结构和训练流程如上。左边是VLMo的结构,右边是按顺序的三个预训练任务。
我们来逐一介绍。
我们注意到图片和文本要变成embedding才能输入进VLMo。所以首先是如何生成embedding。
Input Representations
我们的数据大部分都是图像-文本对,而VLMo有3个专家,因此对一个图像-文本对,我们将其分别编码为图像embedding、文本embedding和图像-文本embedding。
Image Representations
对于图像表示,将 v ∈ R H × W × C v∈R^{H×W×C} v∈RH×W×C的二维图像分割并reshape为 N = H W / P 2 N = HW /P^2 N=HW/P2个patch, v p ∈ R N × ( P 2 C ) v^p∈R^{N×(P^2C)} vp∈RN×(P2C),其中C为通道数,(H, W)为输入图像的分辨率,(P, P)为每个patch的分辨率。然后将图像patch铺平到向量中,并线性投影以获得patch的embedding。
然后在序列最前端放一个可学习的特殊标记[I_CLS],表示一个图像序列。
最后,将patch的embedding、可学习的一维位置embedding V p o s ∈ R ( N + 1 ) × D V_{pos}∈R^{(N+1)×D} Vpos∈R(N+1)×D和图像类型embedding V t y p e ∈ R D V_{type}∈R^{D} Vtype∈RD相加,得到图像表示:
H 0 v = [ v [ I _ C L S ] , V v i p , . . . , V v N p ] + V p o s + V t y p e H^v_0 = [v_{[I\_CLS]},V v^p_i, . . . , V v^p_N ] + V_{pos} + V_{type} H0v=[v[I_CLS],Vvip,...,VvNp]+Vpos+Vtype,其中 H 0 v ∈ R ( N + 1 ) × D H^v_0∈R^{(N+1)×D} H0v∈R(N+1)×D,线性投影 V ∈ R ( P 2 C ) × D V∈R^{(P^2C)×D} V∈R(P2C)×D。
Text Representations
对于文本表示,通过WordPiece (Wu et al., 2016)将文本的token为subword单元。一个序列开始标记([T_CLS])和一个特殊边界标记([T_SEP])被添加到文本序列中。文本输入表示 H 0 w ∈ R ( M + 2 ) × D H^w_0∈R^{(M+2)×D} H0w∈R(M+2)×D,通过将相应的词embedding、文本位置embedding和文本类型embedding相加,得到:
H 0 w = [ w [ T _ C L S ] , w i , … , w M , w [ T _ S E P ] ] + T p o s + T t y p e H^w_0 = [w_{[T\_CLS]}, w_i,…, w_M, w_{[T\_SEP] }]+ T_{pos} + T_{type} H0w=[w[T_CLS],wi,…,wM,w[T_SEP]]+Tpos+Ttype。
其中,M表示标记化subword单元的长度。
Image-Text Representations
对于图像文本表示,把图像表示和文本表示连起来就行:
H 0 v l = [ H 0 w ; H 0 v ] H^{vl}_0 = [H^w_0 ; H^v_0 ] H0vl=[H0w;H0v]
Mixture-of-Modality-Experts Transformer
正如前文所提到的,MOME Transformer用3个模态专家替换了Transformer的前馈网络:视觉专家(V-FFN)、语言专家(L-FFN)和视觉语言专家(VL-FFN)。针对不同的情况,使用不同的专家来处理任务。
同时,还保留了Transformer的Multi-Head Self-Attention(MSA)来对齐视觉和语言内容:
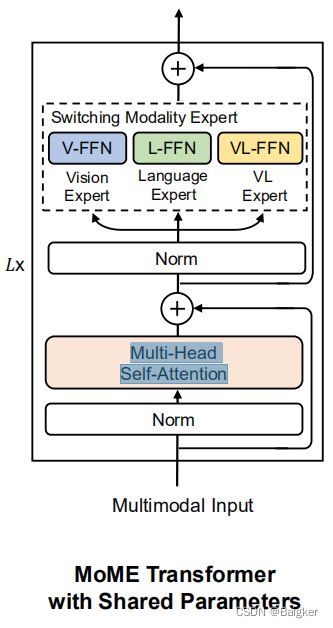
如果输入是仅图像或仅文本向量,则使用视觉专家对图像进行编码,使用语言专家对文本进行编码。
比如下图的VL检索任务,我们分别得到图像和文本的embedding后,计算两者相似度。这就是VLMo的双编码器结构。

如果输入由多种模态的向量组成,如图像-文本对的向量,则使用视觉专家和语言专家在Transformer底层编码各自的模态向量。然后使用视觉语言专家在顶层来捕获更多的模态交互。给定这三种类型的输入向量,就得到了仅图像、仅文本和图像文本上下文化的表示。
比如下图的VL分类任务。这就是VLMo的融合编码器结构。

Stagewise Pre-Training
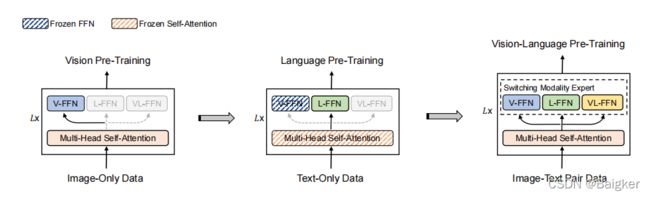
正如前文提到的,VLMo的预训练并非一股脑的一起训练了,而是分阶段的训练。
首先,只使用图像数据对MOME Transformer的视觉专家和注意力模块进行视觉预训练。作者直接利用BEIT的预训练参数来初始化注意模块和视觉专家。
然后,冻结注意力模块和视觉专家的参数,只使用文本数据对语言专家进行语言预训练。
最后,解开冻结,用整个该模型进行VL预训练。
这样做的好处是:与图像-文本对相比,单独的图像和文本的数据更容易收集。而且,图像-文本对的文本数据通常很短而简单,不能让模型学到更一般的文本知识。
通过大量的图像和文本的预训练,模型学到一般的知识,然后再进行VL预训练,将两者的知识进行对齐,从而提高了模型对复杂数据的泛化能力。
实验
Evaluation on Vision-Language Classification Tasks
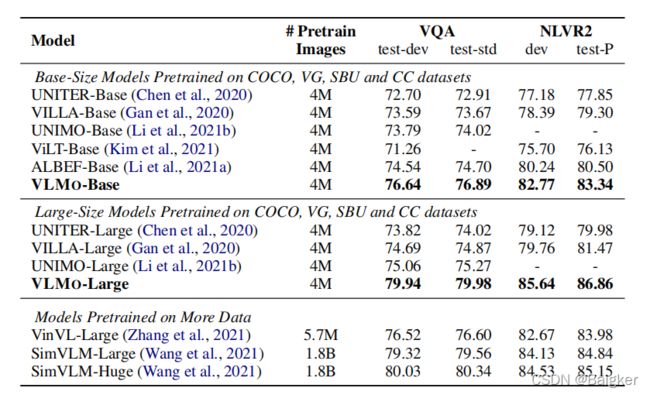
上表展示了在VL分类任务上(VQA和NLVR2),本文方法和SOTA的预训练方法的实验结果。可以看出相同的预训练数据量下,本文的方法能够取得比其他方法更好的性能。
Evaluation on Vision-Language Retrieval Tasks

上表展示了在COCO和Flickr30K数据集上,本文方法和SOTA方法的图文检索实验结果对比。可以看出VLMo能够达到更好的实验结果。
Ablation Studies
Stagewise Pre-Training

上表展示了VLMo在不同阶段预训练设置下的实验结果,可以看出,阶段预训练有效地利用了大规模的仅图像和仅文本语料库,从而改进了视觉语言预训练。
MOME Transformer & Pre-Training Tasks
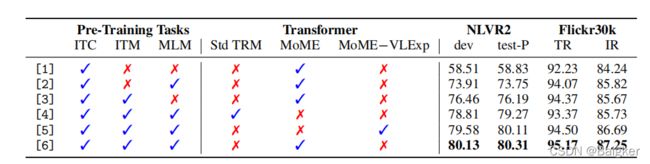
上表展示了VLMo不同结构和预训练任务下的ablation studies结果。