2019: Unified Vision-Language Pre-training for Image Captioning and VQA
摘要
本文提出一个统一的视觉-语言预训练模型,(1)可以用于视觉-语言生成或理解任务的微调;(2)使用一个共享的多层transformer网络编码和解码,与许多编码器和解码器使用单独的模型不同。统一的VLP模型在大量的图像-文本对上进行预训练,使用两个任务进行无监督学习:双向和序列到序列(seq2seq)掩码视觉-语言预测,这两个任务的不同之处仅仅在于预测条件的背景。这是利用共享transformer网络中的特定自注意力掩码来控制的。
一、介绍
视觉语言任务在传统上需要繁琐的特定于任务的特征设计和微调。最近一些关于视觉-语言预训练的模型都不例外地基于transformer的双向编码器表示(BERT),这些模型使用两阶段的训练方案,第一阶段是预训练,基于大量的图像-文本对的模态内或跨模态关系预测掩码单词或图像区域来学习上下文视觉-语言表示;第二阶段,预训练好的模型被微调以适应下游任务。
尽管使用不同的预训练好的模型在下游任务上有显著的提升,然而预训练一个单一的、统一的模型仍然具有挑战性,通过微调使该模型普遍适用于视觉-语言任务生成(如图像标注)和理解(视觉问答)。大多现有的预训练模型要么是仅为理解任务开发的,或设计为混合模型,由多个特定模态的编码器和解码器组成,必须单独训练以支持生成任务。如图1,VideoBERT和CBT只对编码器进行预训练,这导致编码器学习到的跨模态表示和解码器生成所需的表示之间的差异,这可能会损害模型的通用性。本文开发一种新的方法来预训练编码和解码的统一表示,以消除上述差异。此外,我们希望这种统一的表示也能允许更有效的跨任务知识共享,通过消除对不同类型任务的不同模型进行预训练的需要,从而降低开发成本。

为此,我们提出一种统一的编码器解码器模型,称为视觉语言预训练模型,可以对视觉-语言生成和理解任务进行微调。使用一种共享的多层transformer网络进行编码和解码,对大量图像-标注对进行预训练,并对两个无监督视觉-语言预测任务进行优化:双向和序列到序列掩码语言预测。这两个任务的不同在于预测条件的背景。这是通过为共享的transformer网络使用的特定的自注意力掩码来控制的。在双向预测任务中,被预测的掩蔽标注词的上下文由所有图像区域和标注中左右两侧的所有单词组成。在seq2seq任务中,上下文由所有的图像区域和标注中待预测单词左侧的单词组成。
提出的VLP与表1中的基于BERT的模型相比有两个主要优势:首先,VLP统一编码器和解码器,并学习更通用的上下文视觉语言表示,可以更容易地微调视觉语言生成和理解任务,如图像字幕和VQA。其次,统一的预训练过程使得两个不同的视觉语言预测任务有单一的模型架构,即双向和seq2seq,减轻了对不同类型任务的多个预训练模型的需要,而在特定任务指标上没有任何显著的性能损失。
我们观察到,与我们没有使用任何预先训练的模型或只使用预先训练的语言模型(即BERT)的两种情况相比,使用VLP显著加速了特定任务的微调,并导致更好的特定任务的模型,如图1所示。更重要的是,在没有任何附加功能的情况下,我们的模型在所有三个数据集的两个任务上都实现了最先进的结果。

二、相关工作
语言预训练
视觉-语言预训练 ViLBERT和LXMERT都只处理基于理解的任务,并与视觉语言共同注意力模块共享相同的双流BERT框架,以融合来自两个模态的信息。LXMERT只关注特定的问题空间(VQA和视觉推理),当来自下游任务的数据集也在预训练阶段被利用时,泛化能力会进一步降低。VideoBERT处理基于生成的任务和基于理解的任务,但它将视觉编码器和语言解码器分开,只对编码器进行预训练,使解码器未初始化。我们提出一个统一的编码和解码模型,并充分利用了预训练的好处。
图像标注和VQA
三、视觉-语言预训练
视觉-语言Transformer网络 我们的视觉-语言Transformer网络,将Transformer编码器和解码器统一成一个单一的模型,如图2左。模型输入包括类感知区域嵌入、单词嵌入和三个特殊标记嵌入。
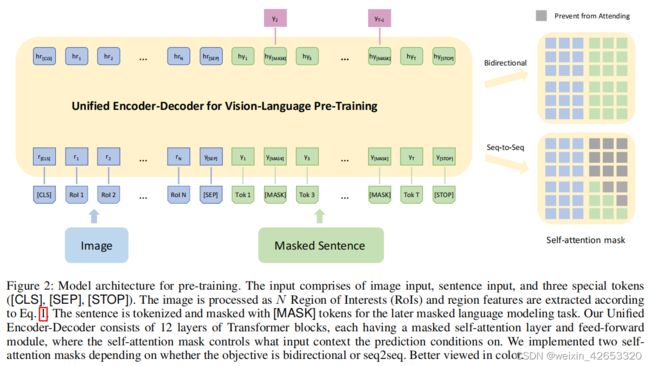
预训练目标 在BERT掩蔽语言建模目标中,15%的输入文本标记首先被替换为特殊的[MASK]标记、随机标记或原始标记,随机的概率分别为80%、10%和10%。然后,在模型输出处,将来自最后一个变压器块的隐藏状态投影到单词的可能性中,其中掩码标记以分类问题的形式被预测。通过这种重建,该模型学习了上下文中的依赖关系,并形成了一个语言模型。我们遵循相同的方案,并考虑两个具体的目标:如BERT中的双向目标(双向)和序列到序列目标(seq2seq),灵感来自于(Dongetal.2019)。
如图2(右)所示,这两个目标之间的唯一差别在于自注意力掩码。用于双向目标的掩码允许视觉模态和语言模态之间不受限制的信息传递;而在seq2seq中,被预测词不能参与将来的单词,即它满足自回归特性。更正式地,我们将第一个transformer块的输入定义为H0=[r[CLS],r1,…,rN,y[SEP],y1,……,yT, y[STOP]]∈Rd×U,U=N+T+3,然后在不同级别的transformer编码为Hl=Transformer(Hl−1),l∈[1,L]。我们进一步定义自注意力掩码为:

为简单起见,我们假设自注意力模块中存在单个注意力头,然后,在Hl−1上的自注意输出可表示为:
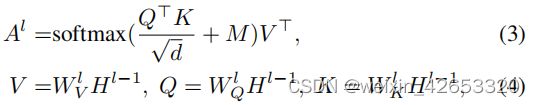
在预训练期间,我们在两个目标之间交替,seq2seq和双向的比例分别由超参数决定。
值得注意的是,在我们的实验中,我们发现将区域类概率纳入区域特征比使用掩码区域分类由更好的性能。因此,我们通过利用掩码语言重建来间接细化视觉表示。我们也选择不像在BERT中那样使用下一个句子预测任务,或者在我们的上下文中预测图像和文本之间的对应关系。
seq2seq推理 与seq2seq训练的方式类似,我们可以直接应用VLP进行序列到序列的推理,以波束搜索的形式。
四、下游任务的微调
视觉问答 我们将VQA定义为一个多标签分类问题,我们关注开放域VQA,其中前k个最常见的答案被选择为答案词汇表,并用作类标签,我们将k设为3129.
微调期间,在[CLS]和[SEP]最后隐藏状态的元素乘积之上学习了多层感知器(Linear+ReLU+Linear+Sigmoid)。我们使用交叉熵损失优化模型输出分数和软答案标签。
五、实验和结果
数据准备 在Conceptual Captions数据集上进行预训练。

六、结论
本文提出一种统一的视觉-语言预训练模型,可以对视觉-语言的生成和理解任务进行微调。该模型基于双向和seq2seq视觉语言预测两个目标,对大量的图像-文本对进行预训练。这两个不同的目标在相同的架构下实现,并且具有参数共享,避免了为不同的下游任务有单独的预训练模型的必要性。在我们的图像字幕和VQA任务的综合实验中,我们证明了大规模的无监督预训练可以显著加快对下游任务的学习速度,并提高模型的准确性。此外,与有单独的预训练模型相比,我们的统一模型结合了从不同的目标,并在所有下游任务上产生轻微的妥协但不错的(SotA)准确性的表示。在我们未来的工作中,我们希望将VLP应用于更多的下游任务,如文本-图像接地和视觉对话。在方法论方面,我们希望看看如何将多任务微调应用于我们的框架,以减轻不同目标之间的干扰。