用神经网络对胸部X射线正常图像与肺炎图像分类
这只是一次测试小项目,考完研后会更换神经网络框架和优化设置文件。
Prepare training data [====================] 2/2 [100%] in 5.9s (0.34/s)
2022-05-08 19:42:58.982874: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2022-05-08 19:42:58.983034: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Search for train images:
Found 3768 images belonging to 2 classes.
Search for validation images:
Found 942 images belonging to 2 classes.
class names: {'NORMAL': 0, 'PNEUMONIA': 1}
number of classes: 2
2022-05-08 19:43:02.787069: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2022-05-08 19:43:02.787653: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cublas64_11.dll'; dlerror: cublas64_11.dll not found
2022-05-08 19:43:02.788395: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cublasLt64_11.dll'; dlerror: cublasLt64_11.dll not found
2022-05-08 19:43:02.902489: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cusolver64_11.dll'; dlerror: cusolver64_11.dll not found
2022-05-08 19:43:02.903582: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cusparse64_11.dll'; dlerror: cusparse64_11.dll not found
2022-05-08 19:43:02.905606: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudnn64_8.dll'; dlerror: cudnn64_8.dll not found
2022-05-08 19:43:02.906431: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1850] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2022-05-08 19:43:02.909590: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
D:\Mx-yolo\Mx-yolov3_EN_3.0.0\core\python39\lib\site-packages\keras\optimizer_v2\gradient_descent.py:102: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(SGD, self).__init__(name, **kwargs)
471/471 [==============================] - 101s 211ms/step - loss: 11.1850 - acc: 0.8838 - val_loss: 2.3215 - val_acc: 0.9512
D:\Mx-yolo\Mx-yolov3_EN_3.0.0\core\python39\lib\site-packages\keras\optimizer_v2\adam.py:105: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(Adam, self).__init__(name, **kwargs)
Epoch 1/30
471/471 [==============================] - ETA: 0s - loss: 9.1576 - acc: 0.8819
Epoch 1: loss improved from inf to 9.15760, saving model to ./Model_file/Image_classification_alpha_0.75_19-43-02\weights.h5
471/471 [==============================] - 222s 468ms/step - loss: 9.1576 - acc: 0.8819 - val_loss: 0.5189 - val_acc: 0.9756
Epoch 2/30
471/471 [==============================] - ETA: 0s - loss: 2.5153 - acc: 0.9153
Epoch 2: loss improved from 9.15760 to 2.51530, saving model to ./Model_file/Image_classification_alpha_0.75_19-43-02\weights.h5
471/471 [==============================] - 218s 462ms/step - loss: 2.5153 - acc: 0.9153 - val_loss: 1.3249 - val_acc: 0.9034
Epoch 3/30
471/471 [==============================] - ETA: 0s - loss: 1.2310 - acc: 0.9347
Epoch 3: loss improved from 2.51530 to 1.23105, saving model to ./Model_file/Image_classification_alpha_0.75_19-43-02\weights.h5
471/471 [==============================] - 196s 416ms/step - loss: 1.2310 - acc: 0.9347 - val_loss: 0.3976 - val_acc: 0.9427
Epoch 4/30
471/471 [==============================] - ETA: 0s - loss: 0.4517 - acc: 0.9565
Epoch 4: loss improved from 1.23105 to 0.45170, saving model to ./Model_file/Image_classification_alpha_0.75_19-43-02\weights.h5
471/471 [==============================] - 208s 442ms/step - loss: 0.4517 - acc: 0.9565 - val_loss: 0.5312 - val_acc: 0.9289
Epoch 5/30
471/471 [==============================] - ETA: 0s - loss: 1.0089 - acc: 0.9329
Epoch 5: loss did not improve from 0.45170
471/471 [==============================] - 207s 439ms/step - loss: 1.0089 - acc: 0.9329 - val_loss: 1.5443 - val_acc: 0.7665
Epoch 6/30
471/471 [==============================] - ETA: 0s - loss: 0.6576 - acc: 0.9363
Epoch 6: loss did not improve from 0.45170
471/471 [==============================] - 216s 458ms/step - loss: 0.6576 - acc: 0.9363 - val_loss: 0.1552 - val_acc: 0.9565
Epoch 7/30
471/471 [==============================] - ETA: 0s - loss: 0.7436 - acc: 0.9347
Epoch 7: loss did not improve from 0.45170
471/471 [==============================] - 207s 439ms/step - loss: 0.7436 - acc: 0.9347 - val_loss: 0.1348 - val_acc: 0.9480
Epoch 8/30
471/471 [==============================] - ETA: 0s - loss: 0.3026 - acc: 0.9398
Epoch 8: loss improved from 0.45170 to 0.30264, saving model to ./Model_file/Image_classification_alpha_0.75_19-43-02\weights.h5
471/471 [==============================] - 204s 433ms/step - loss: 0.3026 - acc: 0.9398 - val_loss: 0.8953 - val_acc: 0.7792
Epoch 9/30
471/471 [==============================] - ETA: 0s - loss: 0.1474 - acc: 0.9618
Epoch 9: loss improved from 0.30264 to 0.14736, saving model to ./Model_file/Image_classification_alpha_0.75_19-43-02\weights.h5
471/471 [==============================] - 210s 446ms/step - loss: 0.1474 - acc: 0.9618 - val_loss: 1.1679 - val_acc: 0.7516
Epoch 10/30
471/471 [==============================] - ETA: 0s - loss: 0.8737 - acc: 0.9315
Epoch 10: loss did not improve from 0.14736
471/471 [==============================] - 184s 390ms/step - loss: 0.8737 - acc: 0.9315 - val_loss: 0.1930 - val_acc: 0.9289
Epoch 11/30
471/471 [==============================] - ETA: 0s - loss: 0.7336 - acc: 0.9313
Epoch 11: loss did not improve from 0.14736
471/471 [==============================] - 186s 394ms/step - loss: 0.7336 - acc: 0.9313 - val_loss: 4.5192 - val_acc: 0.4926
Epoch 12/30
471/471 [==============================] - ETA: 0s - loss: 0.6101 - acc: 0.9273
Epoch 12: loss did not improve from 0.14736
471/471 [==============================] - 183s 389ms/step - loss: 0.6101 - acc: 0.9273 - val_loss: 0.3027 - val_acc: 0.9268
Epoch 13/30
471/471 [==============================] - ETA: 0s - loss: 0.4039 - acc: 0.9424
Epoch 13: loss did not improve from 0.14736
471/471 [==============================] - 189s 400ms/step - loss: 0.4039 - acc: 0.9424 - val_loss: 0.1611 - val_acc: 0.9512
Epoch 14/30
471/471 [==============================] - ETA: 0s - loss: 0.3940 - acc: 0.9437
Epoch 14: loss did not improve from 0.14736
471/471 [==============================] - 187s 397ms/step - loss: 0.3940 - acc: 0.9437 - val_loss: 0.3338 - val_acc: 0.9246
Epoch 15/30
471/471 [==============================] - ETA: 0s - loss: 0.1769 - acc: 0.9525
Epoch 15: loss did not improve from 0.14736
471/471 [==============================] - 187s 397ms/step - loss: 0.1769 - acc: 0.9525 - val_loss: 0.2860 - val_acc: 0.9321
Epoch 16/30
471/471 [==============================] - ETA: 0s - loss: 0.8992 - acc: 0.8970
Epoch 16: loss did not improve from 0.14736
471/471 [==============================] - 193s 409ms/step - loss: 0.8992 - acc: 0.8970 - val_loss: 0.6285 - val_acc: 0.9172
Epoch 17/30
471/471 [==============================] - ETA: 0s - loss: 0.6408 - acc: 0.9122
Epoch 17: loss did not improve from 0.14736
471/471 [==============================] - 187s 396ms/step - loss: 0.6408 - acc: 0.9122 - val_loss: 2.9157 - val_acc: 0.7049
Epoch 18/30
471/471 [==============================] - ETA: 0s - loss: 0.7076 - acc: 0.9116
Epoch 18: loss did not improve from 0.14736
471/471 [==============================] - 197s 417ms/step - loss: 0.7076 - acc: 0.9116 - val_loss: 0.1505 - val_acc: 0.9459
Epoch 19/30
471/471 [==============================] - ETA: 0s - loss: 0.4566 - acc: 0.9305
Epoch 19: loss did not improve from 0.14736
471/471 [==============================] - 191s 404ms/step - loss: 0.4566 - acc: 0.9305 - val_loss: 0.4408 - val_acc: 0.9151
Epoch 20/30
471/471 [==============================] - ETA: 0s - loss: 0.4832 - acc: 0.9384
Epoch 20: loss did not improve from 0.14736
471/471 [==============================] - 196s 417ms/step - loss: 0.4832 - acc: 0.9384 - val_loss: 0.7615 - val_acc: 0.8938
Epoch 21/30
471/471 [==============================] - ETA: 0s - loss: 0.4137 - acc: 0.9352
Epoch 21: loss did not improve from 0.14736
471/471 [==============================] - 204s 433ms/step - loss: 0.4137 - acc: 0.9352 - val_loss: 0.8733 - val_acc: 0.8662
Epoch 22/30
471/471 [==============================] - ETA: 0s - loss: 0.3159 - acc: 0.9440
Epoch 22: loss did not improve from 0.14736
471/471 [==============================] - 197s 417ms/step - loss: 0.3159 - acc: 0.9440 - val_loss: 0.9724 - val_acc: 0.9108
Epoch 23/30
471/471 [==============================] - ETA: 0s - loss: 0.4002 - acc: 0.9368
Epoch 23: loss did not improve from 0.14736
471/471 [==============================] - 196s 417ms/step - loss: 0.4002 - acc: 0.9368 - val_loss: 0.1955 - val_acc: 0.9565
Epoch 24/30
471/471 [==============================] - ETA: 0s - loss: 0.3001 - acc: 0.9419
Epoch 24: loss did not improve from 0.14736
471/471 [==============================] - 186s 394ms/step - loss: 0.3001 - acc: 0.9419 - val_loss: 0.5536 - val_acc: 0.8875
Epoch 25/30
471/471 [==============================] - ETA: 0s - loss: 0.1805 - acc: 0.9575
Epoch 25: loss did not improve from 0.14736
471/471 [==============================] - 190s 404ms/step - loss: 0.1805 - acc: 0.9575 - val_loss: 0.1809 - val_acc: 0.9480
Epoch 26/30
471/471 [==============================] - ETA: 0s - loss: 0.2252 - acc: 0.9482
Epoch 26: loss did not improve from 0.14736
471/471 [==============================] - 211s 447ms/step - loss: 0.2252 - acc: 0.9482 - val_loss: 0.8039 - val_acc: 0.8546
Epoch 27/30
471/471 [==============================] - ETA: 0s - loss: 0.3987 - acc: 0.9400
Epoch 27: loss did not improve from 0.14736
471/471 [==============================] - 194s 412ms/step - loss: 0.3987 - acc: 0.9400 - val_loss: 0.3924 - val_acc: 0.9214
Epoch 28/30
471/471 [==============================] - ETA: 0s - loss: 0.4590 - acc: 0.9342
Epoch 28: loss did not improve from 0.14736
471/471 [==============================] - 188s 399ms/step - loss: 0.4590 - acc: 0.9342 - val_loss: 4.9350 - val_acc: 0.5722
Epoch 29/30
471/471 [==============================] - ETA: 0s - loss: 0.3340 - acc: 0.9363
Epoch 29: loss did not improve from 0.14736
471/471 [==============================] - 191s 406ms/step - loss: 0.3340 - acc: 0.9363 - val_loss: 0.2452 - val_acc: 0.9490
Epoch 30/30
471/471 [==============================] - ETA: 0s - loss: 0.3058 - acc: 0.9350
Epoch 30: loss did not improve from 0.14736
471/471 [==============================] - 225s 478ms/step - loss: 0.3058 - acc: 0.9350 - val_loss: 1.6658 - val_acc: 0.6189
2022-05-08 21:23:55.305480: I tensorflow/core/grappler/devices.cc:66] Number of eligible GPUs (core count >= 8, compute capability >= 0.0): 1
2022-05-08 21:23:55.306393: I tensorflow/core/grappler/clusters/single_machine.cc:358] Starting new session
2022-05-08 21:23:55.310037: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1850] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2022-05-08 21:23:55.578570: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:1164] Optimization results for grappler item: graph_to_optimize
function_optimizer: function_optimizer did nothing. time = 0.002ms.
function_optimizer: function_optimizer did nothing. time = 0ms.
2022-05-08 21:23:58.257698: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:tensorflow:From D:\Mx-yolo\Mx-yolov3_EN_3.0.0\core\python39\lib\site-packages\tensorflow\lite\python\convert_saved_model.py:59: load (from tensorflow.python.saved_model.loader_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This function will only be available through the v1 compatibility library as tf.compat.v1.saved_model.loader.load or tf.compat.v1.saved_model.load. There will be a new function for importing SavedModels in Tensorflow 2.0.
2022-05-08 21:24:04.831046: I tensorflow/core/grappler/devices.cc:66] Number of eligible GPUs (core count >= 8, compute capability >= 0.0): 1
2022-05-08 21:24:04.831255: I tensorflow/core/grappler/clusters/single_machine.cc:358] Starting new session
2022-05-08 21:24:04.836142: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1850] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2022-05-08 21:24:05.178406: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:1164] Optimization results for grappler item: graph_to_optimize
function_optimizer: Graph size after: 2454 nodes (1823), 5160 edges (4083), time = 88.9ms.
function_optimizer: function_optimizer did nothing. time = 0.001ms.
WARNING:tensorflow:From D:\Mx-yolo\Mx-yolov3_EN_3.0.0\core\python39\lib\site-packages\tensorflow\lite\python\util.py:305: convert_variables_to_constants (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.convert_variables_to_constants`
WARNING:tensorflow:From D:\Mx-yolo\Mx-yolov3_EN_3.0.0\core\python39\lib\site-packages\tensorflow\python\framework\convert_to_constants.py:925: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
2022-05-08 21:24:05.840118: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:357] Ignored output_format.
2022-05-08 21:24:05.840298: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:360] Ignored drop_control_dependency.
118/118 [==============================] - 12s 98ms/step - loss: 1.1679 - acc: 0.7516
Final validation loss:
1.1679378747940063
Final validation accuracy:
0.7515923380851746
[[9.9999964e-01 3.0431755e-07]
[1.0000000e+00 5.7752953e-08]
[1.0000000e+00 9.1201835e-10]
...
[7.3647302e-01 2.6352698e-01]
[4.5762701e-07 9.9999952e-01]
[1.4694989e-06 9.9999857e-01]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 1 1 1 0 0 1 0 1 1 1 1
1 1 1 1 0 1 1 0 1 0 1 0 1 1 1 1 0 1 0 1 0 0 1 1 0 1 1 1 1 1 0 0 1 1 0 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 0 0 0 1 0 1 0 1 0 0 1 0 1 1 1 1 1 1 1 1 0
0 1 1 1 1 1 0 1 0 1 1 1 0 1 1 1 0 1 1 1 0 0 0 0 0 1 1 1 1 1 0 1 0 1 1 1 1
1 1 1 0 1 1 0 1 1 0 0 1 1 1 0 1 1 1 1 1 1 1 1 0 1 1 0 1 0 1 0 1 1 0 1 1 1
1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 0 1 0 1 1 0 1 1 1 1 0 0 1
1 1 1 1 1 0 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 1 1 1 1 1 1
1 1 1 1 1 0 1 1 0 0 0 0 1 0 1 0 1 1 0 0 1 1 1 1 1 1 0 0 1 1 0 0 0 0 0 0 1
1 1 1 0 1 1 1 1 1 1 1 0 0 1 1 0 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1
1 1 1 1 1 1 1 1 1 0 1 0 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 1 1 1 1 1 1 0 1 1
1 1 1 1 1 1 1 0 1 1 1 1 0 0 0 1 0 1 0 0 1 0 0 1 0 1 0 1 1 1 1 1 0 1 1 1 0
0 0 0 0 1 1 0 1 1 0 1 0 1 0 1 1 0 1 1 1 0 1 1 1 0 1 0 1 1 0 0 0 1 0 0 0 1
0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 0 1 0 0 1 1 1
1 1 0 0 1 0 1 1 0 1 1 0 1 0 1 0 0 1 0 1 1 1 0 1 1 1 1 1 1 0 1 0 1 0 1 0 0
0 1 0 0 0 1 1 0 0 0 1 1 1 0 0 1 0 1 1 1 1 0 1 0 1 0 1 0 1 1 1 1 1 1 1 1 0
0 1 1 1 0 1 1 1 1 0 0 0 0 1 1 1 1 0 1 0 1 1 1 1 1 1 1 0 1 1 1 0 1 0 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 1 0 0 1
1 1 1 1 1 0 1 1 0 1 1 1 1 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1
0 0 1 0 1 1 1 1 1 1 1 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0
1 0 1 1 0 1 1 0 0 1 0 1 1 0 0 1 1]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
[[243 0]
[234 465]]
precision recall f1-score support
NORMAL 0.51 1.00 0.67 243
PNEUMONIA 1.00 0.67 0.80 699
accuracy 0.75 942
macro avg 0.75 0.83 0.74 942
weighted avg 0.87 0.75 0.77 942
2022-05-08 21:26:20.823275: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2022-05-08 21:26:20.823396: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Found 470 images belonging to 2 classes.
Search for prediction images in subfolders of path <>:
Found 261 images belonging to 1 classes.
class names: {'NORMAL': 0, 'PNEUMONIA': 1}
number of classes: 2
2022-05-08 21:26:24.735839: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2022-05-08 21:26:24.736502: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cublas64_11.dll'; dlerror: cublas64_11.dll not found
2022-05-08 21:26:24.737744: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cublasLt64_11.dll'; dlerror: cublasLt64_11.dll not found
2022-05-08 21:26:24.998343: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cusolver64_11.dll'; dlerror: cusolver64_11.dll not found
2022-05-08 21:26:24.998845: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cusparse64_11.dll'; dlerror: cusparse64_11.dll not found
2022-05-08 21:26:24.999567: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudnn64_8.dll'; dlerror: cudnn64_8.dll not found
2022-05-08 21:26:24.999905: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1850] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2022-05-08 21:26:25.003211: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Filename Prediction
0 predict\IM-0125-0001.jpeg NORMAL
1 predict\IM-0154-0001.jpeg NORMAL
2 predict\IM-0226-0001.jpeg NORMAL
3 predict\IM-0236-0001.jpeg NORMAL
4 predict\IM-0245-0001.jpeg NORMAL
.. ... ...
256 predict\person977_bacteria_2902.jpeg PNEUMONIA
257 predict\person979_virus_1654.jpeg PNEUMONIA
258 predict\person991_bacteria_2918.jpeg PNEUMONIA
259 predict\person992_virus_1670.jpeg NORMAL
260 predict\person998_bacteria_2927.jpeg PNEUMONIA
[261 rows x 2 columns]
The model file has been saved:./Model_file/Image_classification_alpha_0.75_19-43-02/weights.tflite
End of training!
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
conv1_pad (ZeroPadding2D) (None, 226, 226, 3) 0
conv1 (Conv2D) (None, 112, 112, 24) 648
conv1_bn (BatchNormalizatio (None, 112, 112, 24) 96
n)
conv1_relu (ReLU) (None, 112, 112, 24) 0
conv_dw_1 (DepthwiseConv2D) (None, 112, 112, 24) 216
conv_dw_1_bn (BatchNormaliz (None, 112, 112, 24) 96
ation)
conv_dw_1_relu (ReLU) (None, 112, 112, 24) 0
conv_pw_1 (Conv2D) (None, 112, 112, 48) 1152
conv_pw_1_bn (BatchNormaliz (None, 112, 112, 48) 192
ation)
conv_pw_1_relu (ReLU) (None, 112, 112, 48) 0
conv_pad_2 (ZeroPadding2D) (None, 114, 114, 48) 0
conv_dw_2 (DepthwiseConv2D) (None, 56, 56, 48) 432
conv_dw_2_bn (BatchNormaliz (None, 56, 56, 48) 192
ation)
conv_dw_2_relu (ReLU) (None, 56, 56, 48) 0
conv_pw_2 (Conv2D) (None, 56, 56, 96) 4608
conv_pw_2_bn (BatchNormaliz (None, 56, 56, 96) 384
ation)
conv_pw_2_relu (ReLU) (None, 56, 56, 96) 0
conv_dw_3 (DepthwiseConv2D) (None, 56, 56, 96) 864
conv_dw_3_bn (BatchNormaliz (None, 56, 56, 96) 384
ation)
conv_dw_3_relu (ReLU) (None, 56, 56, 96) 0
conv_pw_3 (Conv2D) (None, 56, 56, 96) 9216
conv_pw_3_bn (BatchNormaliz (None, 56, 56, 96) 384
ation)
conv_pw_3_relu (ReLU) (None, 56, 56, 96) 0
conv_pad_4 (ZeroPadding2D) (None, 58, 58, 96) 0
conv_dw_4 (DepthwiseConv2D) (None, 28, 28, 96) 864
conv_dw_4_bn (BatchNormaliz (None, 28, 28, 96) 384
ation)
conv_dw_4_relu (ReLU) (None, 28, 28, 96) 0
conv_pw_4 (Conv2D) (None, 28, 28, 192) 18432
conv_pw_4_bn (BatchNormaliz (None, 28, 28, 192) 768
ation)
conv_pw_4_relu (ReLU) (None, 28, 28, 192) 0
conv_dw_5 (DepthwiseConv2D) (None, 28, 28, 192) 1728
conv_dw_5_bn (BatchNormaliz (None, 28, 28, 192) 768
ation)
conv_dw_5_relu (ReLU) (None, 28, 28, 192) 0
conv_pw_5 (Conv2D) (None, 28, 28, 192) 36864
conv_pw_5_bn (BatchNormaliz (None, 28, 28, 192) 768
ation)
conv_pw_5_relu (ReLU) (None, 28, 28, 192) 0
conv_pad_6 (ZeroPadding2D) (None, 30, 30, 192) 0
conv_dw_6 (DepthwiseConv2D) (None, 14, 14, 192) 1728
conv_dw_6_bn (BatchNormaliz (None, 14, 14, 192) 768
ation)
conv_dw_6_relu (ReLU) (None, 14, 14, 192) 0
conv_pw_6 (Conv2D) (None, 14, 14, 384) 73728
conv_pw_6_bn (BatchNormaliz (None, 14, 14, 384) 1536
ation)
conv_pw_6_relu (ReLU) (None, 14, 14, 384) 0
conv_dw_7 (DepthwiseConv2D) (None, 14, 14, 384) 3456
conv_dw_7_bn (BatchNormaliz (None, 14, 14, 384) 1536
ation)
conv_dw_7_relu (ReLU) (None, 14, 14, 384) 0
conv_pw_7 (Conv2D) (None, 14, 14, 384) 147456
conv_pw_7_bn (BatchNormaliz (None, 14, 14, 384) 1536
ation)
conv_pw_7_relu (ReLU) (None, 14, 14, 384) 0
conv_dw_8 (DepthwiseConv2D) (None, 14, 14, 384) 3456
conv_dw_8_bn (BatchNormaliz (None, 14, 14, 384) 1536
ation)
conv_dw_8_relu (ReLU) (None, 14, 14, 384) 0
conv_pw_8 (Conv2D) (None, 14, 14, 384) 147456
conv_pw_8_bn (BatchNormaliz (None, 14, 14, 384) 1536
ation)
conv_pw_8_relu (ReLU) (None, 14, 14, 384) 0
conv_dw_9 (DepthwiseConv2D) (None, 14, 14, 384) 3456
conv_dw_9_bn (BatchNormaliz (None, 14, 14, 384) 1536
ation)
conv_dw_9_relu (ReLU) (None, 14, 14, 384) 0
conv_pw_9 (Conv2D) (None, 14, 14, 384) 147456
conv_pw_9_bn (BatchNormaliz (None, 14, 14, 384) 1536
ation)
conv_pw_9_relu (ReLU) (None, 14, 14, 384) 0
conv_dw_10 (DepthwiseConv2D (None, 14, 14, 384) 3456
)
conv_dw_10_bn (BatchNormali (None, 14, 14, 384) 1536
zation)
conv_dw_10_relu (ReLU) (None, 14, 14, 384) 0
conv_pw_10 (Conv2D) (None, 14, 14, 384) 147456
conv_pw_10_bn (BatchNormali (None, 14, 14, 384) 1536
zation)
conv_pw_10_relu (ReLU) (None, 14, 14, 384) 0
conv_dw_11 (DepthwiseConv2D (None, 14, 14, 384) 3456
)
conv_dw_11_bn (BatchNormali (None, 14, 14, 384) 1536
zation)
conv_dw_11_relu (ReLU) (None, 14, 14, 384) 0
conv_pw_11 (Conv2D) (None, 14, 14, 384) 147456
conv_pw_11_bn (BatchNormali (None, 14, 14, 384) 1536
zation)
conv_pw_11_relu (ReLU) (None, 14, 14, 384) 0
conv_pad_12 (ZeroPadding2D) (None, 16, 16, 384) 0
conv_dw_12 (DepthwiseConv2D (None, 7, 7, 384) 3456
)
conv_dw_12_bn (BatchNormali (None, 7, 7, 384) 1536
zation)
conv_dw_12_relu (ReLU) (None, 7, 7, 384) 0
conv_pw_12 (Conv2D) (None, 7, 7, 768) 294912
conv_pw_12_bn (BatchNormali (None, 7, 7, 768) 3072
zation)
conv_pw_12_relu (ReLU) (None, 7, 7, 768) 0
conv_dw_13 (DepthwiseConv2D (None, 7, 7, 768) 6912
)
conv_dw_13_bn (BatchNormali (None, 7, 7, 768) 3072
zation)
conv_dw_13_relu (ReLU) (None, 7, 7, 768) 0
conv_pw_13 (Conv2D) (None, 7, 7, 768) 589824
conv_pw_13_bn (BatchNormali (None, 7, 7, 768) 3072
zation)
conv_pw_13_relu (ReLU) (None, 7, 7, 768) 0
global_average_pooling2d (G (None, 768) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 768) 0
dense (Dense) (None, 2) 1538
=================================================================
Total params: 1,834,514
Trainable params: 1,818,098
Non-trainable params: 16,416
_________________________________________________________________
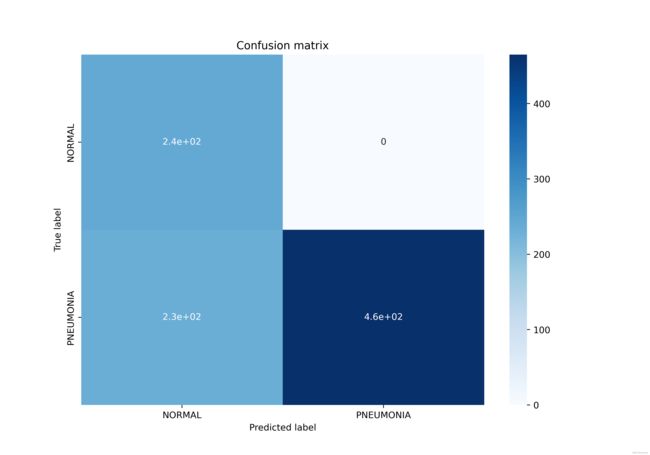
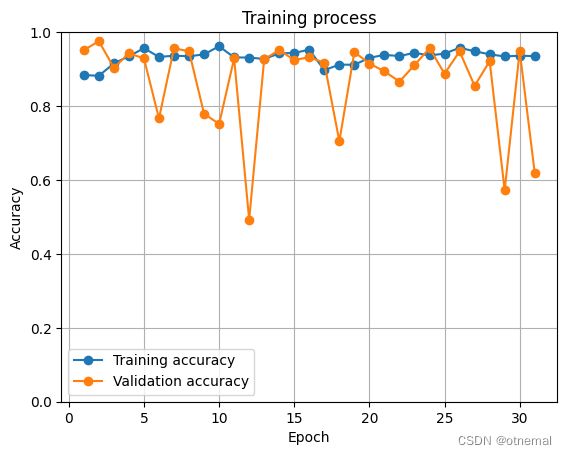
效果感觉还行,应该是过拟合的问题
最后测试识别图
总体识别率在百分之七十-百分之八十左右,还需要优化。
数据集来源于:Kaggle