opencv回顾之路Imgproc Module
图像处理模块
- 一. 基础图像处理部分:
-
- 1.图形绘制操作
- 2. 图像文本显示
- 3. 图像平滑处理(降低图像噪声:g(i,j)=∑ (k,i) F(i+k,j+l)h(k,l))
-
- 3.1 blur(); 与均值滤波器类似
- 3.2 GaussianBlur();高斯滤波器
- 3.3 medianBlur(); 中值滤波器
- 3.4 bilateralFilter() ;双边滤波, 能够很好的保留边缘特征
- 4. 膨胀(Dilating)与腐蚀(Eroding)及其他形态学处理操作(基本可以使用cv::morphologyEx覆盖所有形态学操作)
-
- 4.1 开运算Opening(先腐蚀再膨胀处理,有利于剔除细小的孤立点)
- 4.2 闭运算Closing(先膨胀再腐蚀,有利于填充孔洞)
- 4.3 形态梯度Morphological Gradient(**dst=morphgrad(src,element)=dilate(src,element)−erode(src,element)**,获取区域的边界)
- 4.4 顶帽操作Top Hat(dst=tophat(src,element)=src−open(src,element),有利于分离出孤立点、狭窄的瓶颈连接区域、小的连通域)
- 4.5 黑帽处理Black Hat(dst=blackhat(src,element)=close(src,element)−src,将闭运算的细节显示出来,可以获取孔洞,把细小的缝隙显示出来)
- 4.6 击中与击不中Hit-or-Miss(用B1去腐蚀二值化图像A,然后用B2去腐蚀A的补集,得到的结果相减就是击中击不中变换。B1为下左,B2为下右,用于提取图像中的特定结构)
- 4.1 提取区域的骨架(骨架提取、骨架端点和交叉点的提取方法)
- 5. 图像金字塔Image Pyramids(常用于上采样和下采样图像)
-
- 5.1 Gaussian Pyramid:用于下采样图像----pyrDown()。
- 5.2 Laplacian Pyramid:用于从金字塔中较低的图像重建上采样图像---pyrUp()。
- 6. 阈值分割
-
- 6.1 基础阈值分割操作: cv::threshold(),该函数支持多通道图像,下面是该方法支持的5种类型
- 6.2 cv::inRange()范围分割函数
- 6.3 自适应阈值分割cv::adaptiveThreshold()函数: 该函数实现将灰度图转化为二值化图像
- 二. 图像变换部分:
-
- 1. 自定义卷积核并实现卷积操作
- 2. 填充图像的边框
- 3. 边缘检测(后继操作一般为hough变换或轮廓查找等)
-
- 3.1 Soble()算子与Scharr()算子
- 3.2 Laplace()算子
- 3.3 Canny()算子
- 4. Hough变换
-
- 4.1 Hough直线检测
- 4.2 hough圆变换
- 4.3 使用广义霍夫变换(不规则图形的识别实现目标检测(该方法不适用于实时性要求高的应用场景,高分辨率图像可能花费几分钟时间。)
- 5. 几何变换
-
- 5.1 重映射变换
- 5.2 仿射变换
- 5.3 透视变换
- 5.4 几何变换示例代码
- 三. 图像直方图相关部分:
-
- 3.1 opencv中图像直方图的计算
- 3.2 直方图均衡处理(Histogram equalization增强图像的对比度,通常适用于灰度图,彩色图像一般是单通道处理后合并)
- 3.3 直方图比较(利用不同metric去评判多张图像的直方图的相似性,进而判断多张图像之间的相似性)
- 3.4 对比度受限的自适应直方图均衡化(CLAHE)算法
- 3.5 直方图反投影(多用于彩色(HSV空间下)图像的分割或目标检测,主要是颜色比灰度值强度的直方图更加可区分)-----案例用于图像分割
- 3.6 模板匹配(基础模板匹配算法(主要是利用图像的灰度值特征),不能用于旋转缩放或轻微变化以及多目标的检测)
- 3.7 模板匹配的算法扩展(github开源的多目标旋转缩放目标匹配)
- 四. 图像轮廓处理部分(通常是边缘检测与图像分割后的继承操作):
-
- 4.1 图像轮廓搜索
- 4.2 获取轮廓的凸包(convexHull)
- 4.3 获取轮廓的最小矩形/圆形/多边形包围框
- 4.4 获取轮廓的面积和近似长度以及获取轮廓的质心
- 4.5 计算图像的矩:cv::moments(), cv::HuMoments(),并利用图像矩获取轮廓的重心以及轮廓面积
- 4.6 判断点与轮廓的位置关系(内部、外部、在轮廓线上)
- 五. 距离变换与分水岭算法实现图像分割:
-
- 5.1 将图像的指定区域设置为指定的值
- 5.2 连通域提取(常用于图像分割之后)
- 5.3 距离变换(获取前景各组件的闭合轮廓、图像中心点、骨架等)
- 5.3 分水岭算法(官网链接:链接: [https://people.cmm.minesparis.psl.eu/users/beucher/wtshed.html](https://www.csdn.net/))
- 5.4 类型转换函数
- 5.4 使用距离变换结合分水岭算法实现图像分割案例(在使用分水岭算法是,应当尽可能多的将前景进行标注)
- 六 图像去模糊算法
一. 基础图像处理部分:
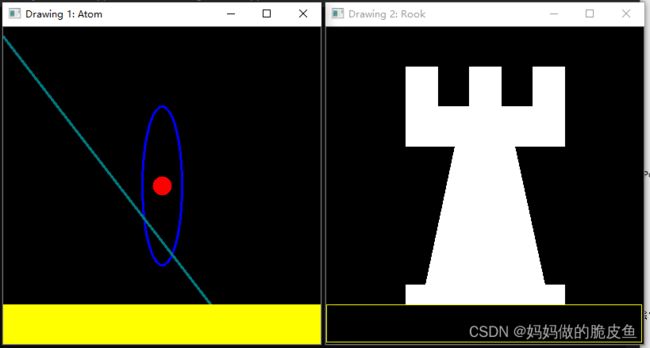
1.图形绘制操作
- 绘制直线line()
- 绘制椭圆ellipse()
- 绘制矩形框rectangle()
- 绘制圆circle()
- 绘制填充多边形fillPoly()
// 基础数据结构--点
Point pt; // 等价于Point pt = Point(10, 8 );
pt.x = 10;
pt.y = 8;
// 基础数据结构----定义三维向量Scalar,常用于填充初始化图像的数据矩阵
Scalar(a, b , c);
// 绘制几何形状的案例代码
#include
#include
#include
#define w 400
using namespace cv;
void MyEllipse(Mat img, double angle);
void MyFilledCircle(Mat img, Point center);
void MyPolygon(Mat img);
void MyLine(Mat img, Point start, Point end);
int main(void) {
char atom_window[] = "Drawing 1: Atom";
char rook_window[] = "Drawing 2: Rook";
Mat atom_image = Mat::zeros(w, w, CV_8UC3);
Mat rook_image = Mat::zeros(w, w, CV_8UC3);
MyEllipse(atom_image, 90);
MyFilledCircle(atom_image, Point(w / 2, w / 2));
MyLine(atom_image, Point(0 , 12), Point(3 * w / 4, w));
rectangle(atom_image,
Point(0, 7 * w / 8),
Point(w, w),
Scalar(0, 255, 255),
FILLED,
LINE_8);
MyPolygon(rook_image);
rectangle(rook_image,
Point(0, 7 * w / 8),
Point(w-3, w-3),
Scalar(0, 255, 255),
1,
LINE_8);
imshow(atom_window, atom_image);
moveWindow(atom_window, 0, 200);
imshow(rook_window, rook_image);
moveWindow(rook_window, w, 200);
waitKey(0);
return(0);
}
void MyEllipse(Mat img, double angle)
{
int thickness = 2;
int lineType = 8;
ellipse(img,
Point(w / 2, w / 2),
Size(w / 4, w / 16),
angle,
0,
360,
Scalar(255, 0, 0),
thickness,
lineType);
}
void MyFilledCircle(Mat img, Point center)
{
circle(img,
center,
w / 32,
Scalar(0, 0, 255),
FILLED,
LINE_8);
}
void MyPolygon(Mat img) // 绘制填充的多边形
{
int lineType = LINE_8;
Point rook_points[1][20];
rook_points[0][0] = Point(w / 4, 7 * w / 8);
rook_points[0][1] = Point(3 * w / 4, 7 * w / 8);
rook_points[0][2] = Point(3 * w / 4, 13 * w / 16);
rook_points[0][3] = Point(11 * w / 16, 13 * w / 16);
rook_points[0][4] = Point(19 * w / 32, 3 * w / 8);
rook_points[0][5] = Point(3 * w / 4, 3 * w / 8);
rook_points[0][6] = Point(3 * w / 4, w / 8);
rook_points[0][7] = Point(26 * w / 40, w / 8);
rook_points[0][8] = Point(26 * w / 40, w / 4);
rook_points[0][9] = Point(22 * w / 40, w / 4);
rook_points[0][10] = Point(22 * w / 40, w / 8);
rook_points[0][11] = Point(18 * w / 40, w / 8);
rook_points[0][12] = Point(18 * w / 40, w / 4);
rook_points[0][13] = Point(14 * w / 40, w / 4);
rook_points[0][14] = Point(14 * w / 40, w / 8);
rook_points[0][15] = Point(w / 4, w / 8);
rook_points[0][16] = Point(w / 4, 3 * w / 8);
rook_points[0][17] = Point(13 * w / 32, 3 * w / 8);
rook_points[0][18] = Point(5 * w / 16, 13 * w / 16);
rook_points[0][19] = Point(w / 4, 13 * w / 16);
const Point* ppt[1] = { rook_points[0] };
int npt[] = { 20 };
fillPoly(img,
ppt,
npt,
1,
Scalar(255, 255, 255),
lineType);
}
void MyLine(Mat img, Point start, Point end) // 绘制直线
{
int thickness = 2;
int lineType = LINE_8;
line(img,
start,
end,
Scalar(125, 120, 0), // 线段颜色
thickness, // 当为FILLED(宏为-1)是代表填充,其他为不填充表示线宽如1;
lineType);
}
2. 图像文本显示
// 文本显示函数
void cv::putText ( InputOutputArray img,
const String & text, // 待显示文本
Point org, // 显示文本的左下角坐标
int fontFace, // 文字类型FONT_HERSHEY_SIMPLEX 、FONT_HERSHEY_PLAIN 等
double fontScale,
Scalar color,
int thickness = 1,
int lineType = LINE_8, // FILLED 、LINE_4 (4领域线)、LINE_8 (8领域线)、LINE_AA (抗锯齿线)
bool bottomLeftOrigin = false
)
3. 图像平滑处理(降低图像噪声:g(i,j)=∑ (k,i) F(i+k,j+l)h(k,l))
3.1 blur(); 与均值滤波器类似
3.2 GaussianBlur();高斯滤波器
3.3 medianBlur(); 中值滤波器
3.4 bilateralFilter() ;双边滤波, 能够很好的保留边缘特征
// A code block
// ksize: 核大小
// anchor: 锚框中心的位置,当为(-1,-1)时,anchor为核的中心位置
// borderType: border mode used to extrapolate pixels outside of the image, see BorderTypes.
// Size( i, i )为核的大小,Point(-1,-1)为指定锚框的中心
blur( src, dst, Size( i, i ), Point(-1,-1) ); // 近似等价与 boxFilter();
void cv::GaussianBlur ( InputArray src,
OutputArray dst,
Size ksize,
double sigmaX, // x方向上的标准差
double sigmaY = 0, // 为0时表示为与x方向的标准差一致
int borderType = BORDER_DEFAULT
)
void cv::medianBlur ( InputArray src,
OutputArray dst,
int ksize
)
// 通常为了简化,两个 sigma 的值可以设置为相等。如果这两个值都非常小,比如小于 10,则滤波器没有什么太大的效果。如果大于 150,则会有非常强的影响,甚至会让图片产生卡通化的效果。
void cv::bilateralFilter ( InputArray src,
OutputArray dst,
int d, // 推荐为5,当大于5时,速度较慢
double sigmaColor,
double sigmaSpace,
int borderType = BORDER_DEFAULT
)
4. 膨胀(Dilating)与腐蚀(Eroding)及其他形态学处理操作(基本可以使用cv::morphologyEx覆盖所有形态学操作)
// 腐蚀函数
void cv::erode ( InputArray src, // 输入图像
OutputArray dst, // 输出图像
InputArray kernel, // 核结构,可以使用getStructuringElementget()
// 函数进行创建三种核类型(矩形、十字架、椭圆形) cv::MORPH_RECT = 0, cv::MORPH_CROSS = 1, cv::MORPH_ELLIPSE = 2;
Point anchor = Point(-1,-1), // 锚位置
int iterations = 1, // 迭代处理次数
int borderType = BORDER_CONSTANT, // 图像边界填充次数
const Scalar & borderValue = morphologyDefaultBorderValue() // 边框填充的默认值
)
// 膨胀函数
void cv::dilate ( InputArray src,
OutputArray dst,
InputArray kernel, // 使用getStructuringElementget()生成
Point anchor = Point(-1,-1),
int iterations = 1, // 迭代次数
int borderType = BORDER_CONSTANT,
const Scalar & borderValue = morphologyDefaultBorderValue()
)
// 创建所用的核的函数
Mat cv::getStructuringElement ( int shape, // cv::MORPH_RECT = 0, cv::MORPH_CROSS = 1, cv::MORPH_ELLIPSE = 2;
Size ksize,
Point anchor = Point(-1,-1)
)
// 创建腐蚀运算的核的示例代码
Mat src, erosion_dst, dilation_dst;
int erosion_type = 0;
if( erosion_elem == 0 ){ erosion_type = MORPH_RECT; } // 矩形
else if( erosion_elem == 1 ){ erosion_type = MORPH_CROSS; } // 十字形
else if( erosion_elem == 2) { erosion_type = MORPH_ELLIPSE; } // 椭圆形
Mat element = getStructuringElement( erosion_type,
Size( 2*erosion_size + 1, 2*erosion_size+1 ),
Point( erosion_size, erosion_size ) );
erode( src, erosion_dst, element ); // 腐蚀操作
dilate( src, dilation_dst, element ); // 膨胀操作
4.1 开运算Opening(先腐蚀再膨胀处理,有利于剔除细小的孤立点)
4.2 闭运算Closing(先膨胀再腐蚀,有利于填充孔洞)
4.3 形态梯度Morphological Gradient(dst=morphgrad(src,element)=dilate(src,element)−erode(src,element),获取区域的边界)
4.4 顶帽操作Top Hat(dst=tophat(src,element)=src−open(src,element),有利于分离出孤立点、狭窄的瓶颈连接区域、小的连通域)
4.5 黑帽处理Black Hat(dst=blackhat(src,element)=close(src,element)−src,将闭运算的细节显示出来,可以获取孔洞,把细小的缝隙显示出来)
4.6 击中与击不中Hit-or-Miss(用B1去腐蚀二值化图像A,然后用B2去腐蚀A的补集,得到的结果相减就是击中击不中变换。B1为下左,B2为下右,用于提取图像中的特定结构)
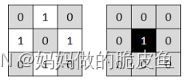
// morphologyEx() 用于执行任意高级的形态学转换
void cv::morphologyEx ( InputArray src,
OutputArray dst,
int op, // 上面的5种可选的操作(膨胀和腐蚀也可以执行):MORPH_ERODE:0、MORPH_DILATE:1 、MORPH_OPEN:2 、MORPH_CLOSE:3 、MORPH_GRADIENT:4 、MORPH_TOPHAT:5 、MORPH_BLACKHAT:6 、MORPH_HITMISS:7 (击中与击不中Only supported for CV_8UC1 binary images,其他类型操作支持任意深度和多通道的图像)
InputArray kernel, // 使用getStructuringElement.()获取
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
const Scalar & borderValue = morphologyDefaultBorderValue()
)
// 使用morphologyEx()实现各种形态学操作
int operation = (取值0至7);
Mat element = getStructuringElement( morph_elem, Size( 2*morph_size + 1, 2*morph_size+1 ), Point( morph_size, morph_size ) );
morphologyEx( src, dst, operation, element );
4.1 提取区域的骨架(骨架提取、骨架端点和交叉点的提取方法)
可以参考如下连接:
链接: https://blog.csdn.net/thequitesunshine007/article/details/106967069
5. 图像金字塔Image Pyramids(常用于上采样和下采样图像)
5.1 Gaussian Pyramid:用于下采样图像----pyrDown()。
5.2 Laplacian Pyramid:用于从金字塔中较低的图像重建上采样图像—pyrUp()。
// 上采样的图像:默认输出尺寸:Size(src.cols*2, src.rows *2 )
// 基本过程:先再原图上的偶数行列用0填充,然后使用高斯核进行卷积计算结果乘以4.
pyrUp( src, src, Size( src.cols*2, src.rows*2 ) ); // 第三个参数为上采样后的图像尺寸
// 下采样的图像
// 一般输出的下采样图像的尺寸大小默认为Size((src.cols+1)/2,(src.rows+1)/2 )
// 大致过程: 原图使用高斯核卷积图像,再将卷积后的图像的偶数行和列删除。
pyrDown( src, src, Size( src.cols/2, src.rows/2 ) ); // 第三个参数为下采样后图像的尺寸
6. 阈值分割
6.1 基础阈值分割操作: cv::threshold(),该函数支持多通道图像,下面是该方法支持的5种类型
- Binary(大于指定阈值取maxVal,其他取0)枚举值THRESH_BINARY =0;
- Binary Inverted(大于指定阈值取0,其他取maxVal)枚举值THRESH_BINARY_INV =1;
- Threshold Truncated(大于阈值取指定阈值,其他取自身值)枚举值THRESH_TRUNC =2;
- Threshold to Zero(大于阈值取自身值,其他取0)枚举值THRESH_TOZERO =3;
- Threshold to Zero Inverted(大于阈值取0,其他取自身值)枚举值THRESH_TOZERO_INV =4;
// threshold()支持5种类型的阈值分割类型操作
double cv::threshold ( InputArray src,
OutputArray dst,
double thresh, // 分割阈值,该值可以通过Otsu 或 Triangle 算法确定
double maxval, // 当使用Binary和Binary Inverted时需要指定该参数
int type // 该参数可以同时赋予多个值(以上5种搭配THRESH_OTSU 或THRESH_TRIANGLE其中一种:**THRESH_OTSU | THRESH_BINARY**)
)
// 注意:当将type指定为THRESH_OTSU 或THRESH_TRIANGLE 时,参数thresh就可以任意设置,且返回值double将表示自适应所获得的分割阈值。
cv::threshold(differ6, differ6, 60, 255, THRESH_OTSU);
cv::threshold(differ6, differ6, 60, 255, THRESH_TRIANGLE);
// 效果对比总结:在背景中提取亮目标,TRIANGLE法优于OTSU法,而在亮背景中提取暗目标,OTSU法优于TRIANGLE法。
6.2 cv::inRange()范围分割函数
void cv::inRange ( InputArray src,
InputArray lowerb,
InputArray upperb,
OutputArray dst
)
// 对每个通道的像素强度进行判断,如果位于范围内设置为255,其他设置为0.返回的图像类型为CV_8U ;
inRange(frame_HSV, Scalar(low_H, low_S, low_V), Scalar(high_H, high_S, high_V), frame_threshold);
6.3 自适应阈值分割cv::adaptiveThreshold()函数: 该函数实现将灰度图转化为二值化图像
void cv::adaptiveThreshold ( InputArray src, // Source 8-bit single-channel image.
OutputArray dst, // 与原图像一致
double maxValue, // 预设满足条件的最大值。
int adaptiveMethod, // 获取自适应阈值的方法ADAPTIVE_THRESH_MEAN_C(blockSize区域像素的平均值) 和ADAPTIVE_THRESH_GAUSSIAN_C (blockSize区域的加权和)
int thresholdType,// THRESH_BINARY(如果当前像素值大于自适应阈值,则为maxValue,其他为0) 或THRESH_BINARY_INV(与THRESH_BINARY的计算方法相反)两种方法
int blockSize, // 用于计算阈值的领域核
double C
)
二. 图像变换部分:
1. 自定义卷积核并实现卷积操作
// opencv提供cv::hal::filter2D()函数可以实现卷积操作
void cv::filter2D ( InputArray src,
OutputArray dst,
int ddepth, // 输出图像的深度,若为-1则与输入图像一致。
InputArray kernel, // 卷积核(或者更确切地说是相关内核),单通道浮点矩阵;如果要将不同的内核应用于不同的通道,请使用 split 将图像拆分为单独的颜色平面并单独处理它们。
Point anchor = Point(-1,-1),
double delta = 0, // 偏置参数,加到每一个像素上
int borderType = BORDER_DEFAULT // 以何种方式填充图像的扩充边界部分的像素
)
// 案例---创建一个均值滤波核,并卷积处理
kernel_size = 3;
kernel = Mat::ones( kernel_size, kernel_size, CV_32F )/ (float)(kernel_size*kernel_size);
// Apply filter
filter2D(src, dst, -1 , kernel, Point(-1,-1), 0, BORDER_DEFAULT );
2. 填充图像的边框
有两种填充边界的方法
- BORDER_CONSTANT: 使用指定值填充边界;
- BORDER_REPLICATE: 使用原始图像的边界值去填充边界。
// 填充边界的案例代码
RNG rng(12345);
top = (int) (0.05*src.rows); bottom = top;
left = (int) (0.05*src.cols); right = left;
Scalar value( rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255) );
copyMakeBorder( src, dst, top, bottom, left, right, BORDER_CONSTANT, value ); // 指定上下左右填充的高度
copyMakeBorder( src, dst, top, bottom, left, right, BORDER_REPLICATE);
3. 边缘检测(后继操作一般为hough变换或轮廓查找等)
3.1 Soble()算子与Scharr()算子
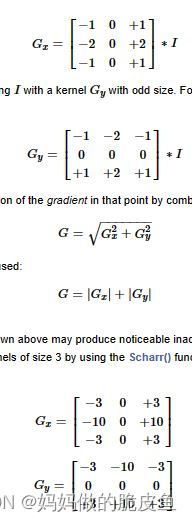
// 核心原理:依托的是边缘处的像素存在跳跃,求取离散的一阶导数其值为一个峰值。
void cv::Sobel ( InputArray src,
OutputArray dst,
int ddepth,
int dx,
int dy,
int ksize = 3, // 当等于 FILTER_SCHARR(-1)表示为3*3的核
double scale = 1,
double delta = 0,
int borderType = BORDER_DEFAULT
)
// 注意:
Scharr(src, dst, ddepth, dx, dy, scale, delta, borderType) // 不需要指定核的大小,默认为3*3的核,该方法是对Sobel的优化,且计算速度和精度都更好。但仅限3*3的核。
是相互等价的:
Sobel(src, dst, ddepth, dx, dy, FILTER_SCHARR, scale, delta, borderType).
Sobel边缘检测案例代码:
// 当核尺寸为3*3时,opencv中通常推荐使用Scharr()算子去替代标准的Soble()算子。
GaussianBlur(image, src, Size(3, 3), 0, 0, BORDER_DEFAULT);
// 转换为灰度图
cvtColor(src, src_gray, COLOR_BGR2GRAY);
Mat grad_x, grad_y; // 梯度计算结果后存在正负值,且范围可能操作了cv_8u.
Mat abs_grad_x, abs_grad_y;
Sobel(src_gray, grad_x, ddepth, 1, 0, 3, scale, delta, BORDER_DEFAULT);
Sobel(src_gray, grad_y, ddepth, 0, 1, 3, scale, delta, BORDER_DEFAULT);
// converting back to CV_8U,转换数据类型
// 1. 对于 src * alpha + beta 的结果,如果是负值且大于 -255,则取绝对值;
// 2. 对于 src * alpha + beta 的结果,如果大于 255,则取 255;
// 3. 对于 src * alpha + beta 的结果,如果是负值且小于 -255,则取 255;
// 4. 对于 src * alpha + beta 的结果,如果在 0 - 255 之间,则保持不变;
convertScaleAbs(grad_x, abs_grad_x);
convertScaleAbs(grad_y, abs_grad_y);
addWeighted(abs_grad_x, 0.5, abs_grad_y, 0.5, 0, grad); // 需要将x和y方向的梯度结合以获取当前点位置的综合梯度值,grad即为边缘图像|Grad_x| + |Grad_y|;
3.2 Laplace()算子
核心原理:边缘点处的二阶导数取值为0,实现过程使用sobel算子计算二阶偏导之和作为边缘像素(核的尺寸大于1时)。通常Laplacian()需要结合使用高斯滤波算子。
void cv::Laplacian ( InputArray src,
OutputArray dst,
int ddepth,
int ksize = 1,
double scale = 1,
double delta = 0,
int borderType = BORDER_DEFAULT
)
// 当ksize ==1 时,使用下图中的3*3核进行计算。

cv::Mat dst, gray, edge;
cv::GaussianBlur(src, dst, cv::Size(3, 3), 0 ,0); // 高斯模糊 去除噪声
cv::cvtColor(dst, gray, cv::COLOR_BGR2GRAY); // 灰度化
Laplacian( gray, edge, CV_16S, 3, 1, 0, BORDER_DEFAULT );// 使用拉普拉斯算子提取边缘
cv::convertScaleAbs(edge, edge); // 将数据转换为CV_8U
cv::imshow("output", edge);
3.3 Canny()算子
Canny边缘检测的基本步骤:
- 使用高斯滤波器滤除噪声;
- 使用Sobel算子计算出梯度和梯度方向;
- 应用非极大值抑制删除部分非边缘候选边;
- 使用上下限阈值去筛选候选边缘点,如果当前边缘幅值大于上限阈值,直接认定为边缘;如果小于下限阈值判定为非边缘点;其他,如果该点附近连接有边缘点,则判定为边缘点,否则不是边缘点。
void cv::Canny ( InputArray image, // 8-bit图像
OutputArray edges, // 8-bit图像
double threshold1, // 下限阈值
double threshold2, // 上限阈值,推荐高低阈值比在2:1和3:1之间
int apertureSize = 3, // Sobel算子核的尺寸
bool L2gradient = false // 指定使用L1还是L2范数来计算边缘幅值
)
// 使用案例代码:
Mat dst;
blur( src_gray, detected_edges, Size(3,3) ); // 均值滤波
Canny( detected_edges, detected_edges, 100,300, 3);
dst.create(src_gray.size(), src_gray.type());
dst = Scalar::all(0);
src.copyTo( dst, detected_edges); // 由于Canny检测的返回值是一个二值图像,可以作为一个掩码,用于将掩码为1的部分复制到指定图像上。
4. Hough变换
霍夫变换的基本原理:
在笛卡尔坐标系下一条直线可以被表示为A(x1, y1)B(x2, y2)两点,同样也可以将直线基于y = k*x + q 表示为:

既有以k和q建立坐标系-----霍夫空间;
则有结论1------笛卡尔坐标系中的一条直线,对应霍夫空间中的一个点。
反之有结论2-----霍夫空间的一条直线对应笛卡尔坐标系下的一个点。
结论3-------霍夫空间中的一个点被N个直线穿过,那么对应的笛卡尔坐标系下将会存在对应N个点组成一条直线。当用极坐标表示时,N条直线变换为N条曲线。
注意: 一般霍夫空间中的点或直线采用极坐标表示:q = -kx + y 被表示为 r = xcos(Q) + y*sin(Q)。
经典的霍夫变换能够实现直线和圆的检测,广义霍夫变换可以实现指定的任意形状检测。
可以参考:链接: https://zhuanlan.zhihu.com/p/203292567
4.1 Hough直线检测
- Standard Hough Transform标准霍夫直线变换HoughLines(), 返回极坐标(Q, R)组成的元组对向量
- Probabilistic Hough Line Transform概率霍夫直线变换HoughLinesP(), 返回检测到的最佳直线(x1, y1, x2, y2)
// 算子说明
void cv::HoughLines ( InputArray image, // 8位的单通道二值图像
OutputArray lines, // 存储了霍夫线变换检测到线条的输出矢量。每一条线由具有两个元素的矢量(r,t)表示。r为离坐标原点的距离,t为弧度线条旋转角度。
double rho, // 指定R以像素为单位的距离精度,一般为1
double theta, // 指定Q以弧度为单位的角度精度,一般为 CV_PI / 180
int threshold, // 穿过霍夫空间中某一点的曲线个数
double srn = 0,
double stn = 0, // 当srn和stn都为0时,调用经典霍夫变换,否则应当大于0,即为多尺度霍夫变换
double min_theta = 0,
double max_theta = CV_PI // 对于标准和多尺度霍夫变换,检查线的最大角度。必须介于 min_theta 和 CV_PI 之间。
)
void cv::HoughLinesP ( InputArray image, // 8为单通道二值图像
OutputArray lines, // 返回值为(x1, y1, x2, y2)组成的向量
double rho,
double theta,
int threshold,
double minLineLength = 0, // 指定直线的最小长度
double maxLineGap = 0 // 指定直线两点之间的最大间隔
)
基本实现步骤如下所示:
1. 图像灰度化;
2. 图像进行平滑滤波处理;
3. 对平滑图像进行Canny()边缘检测,获取到二值化图像;
4. 对二值化图像进行霍夫直线检测,得到(Q, R)或(x1, y1, x2, y2)的直线容器;
5. 获取直线
// 霍夫直线检测案例代码
int main(int argc, char** argv)
{
Mat src, dst;
// Edge detection, 结果为单通道二值图像0或255
Canny(src, dst, 50, 200, 3);
// Copy edges to the images that will display the results in BGR
cvtColor(dst, cdst, COLOR_GRAY2BGR);
cdstP = cdst.clone();
vector lines; // will hold the results of the detection
HoughLines(dst, lines, 1, CV_PI / 180, 150, 0, 0); // Standard Hough Line Transform,, 默认范围是0至pi
// Draw the lines
for (size_t i = 0; i < lines.size(); i++)
{
float rho = lines[i][0], theta = lines[i][1];
Point pt1, pt2;
double a = cos(theta), b = sin(theta);
double x0 = a * rho, y0 = b * rho;
pt1.x = cvRound(x0 + 1000 * (-b));
pt1.y = cvRound(y0 + 1000 * (a)); // 获取得到直线起点
pt2.x = cvRound(x0 - 1000 * (-b));
pt2.y = cvRound(y0 - 1000 * (a)); // 获取得到直线终点
line(cdst, pt1, pt2, Scalar(0, 0, 255), 3, LINE_AA);
}
vector linesP; // vector<(x1, y1, x2, y2)>
HoughLinesP(dst, linesP, 1, CV_PI / 180, 50, 50, 10); // Probabilistic Line Transform
for (size_t i = 0; i < linesP.size(); i++)
{
Vec4i l = linesP[i]; // 获取每条直线的起始点值
line(cdstP, Point(l[0], l[1]), Point(l[2], l[3]), Scalar(0, 0, 255), 3, LINE_AA); // 输入线段的起始点,绘制直线
}
// Show results
imshow("Source", src);
imshow("canny", dst);
imshow("Detected Lines (in red) - Standard Hough Line Transform", cdst);
imshow("Detected Lines (in red) - Probabilistic Line Transform", cdstP);
// Wait and Exit
waitKey();
return 0;
}

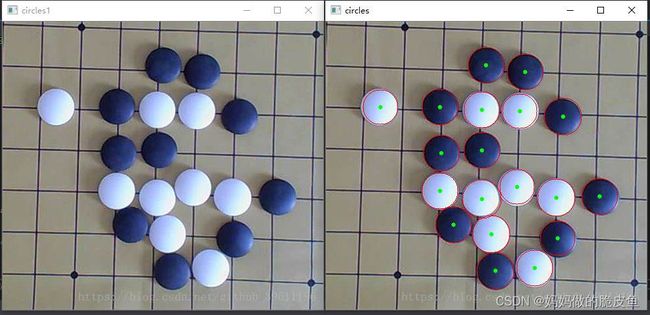
4.2 hough圆变换
使用函数HoughCircles()实现圆的检测,基础理论如下所示:
将笛卡尔坐标系下的一个圆,转换为该圆半径、圆心横纵坐标所确定的三维参数空间中一个点的过程,因此圆周上任意三点所确定的圆,经Hough变换后在三维参数空间应对应一点。 但是逐点去核查每个二维空间坐标系下对应的三维空间中对应的圆,存在计算消耗大的问题,所以opencv使用"霍夫梯度法"进行了优化。 圆心一定是在圆上的每个点的模向量上,即在垂直于该点并且经过该点的切线的垂直线上,这些圆上的模向量的交点就是圆心。
基本实现步骤如下:
- 首先对图像应用边缘检测,比如用canny边缘检测;
- 使用sobel算子计算所有像素的梯度;
- 遍历canny之后的所有非0的像素点,沿着梯度方向画线,每个点有是一个累加器,有一个线经过该点,累加器加 1,对所有累加器进行排序,根据阈值找到所有可能的圆心;
- 计算canny图像中所有的非0像素点距离圆心的距离,距离从小到大排序,选取合适的半径;
- 对选取的半径设置累加器,对于满足半径r的累加器+1
// HoughCircles() 的参数说明
void cv::HoughCircles ( InputArray image, // 8位单通道灰度图, 上面的霍夫直线或圆变换输入为二值图像
OutputArray circles, // (x,y,radius) or (x,y,radius,votes) 组成的容器
int method, // HOUGH_GRADIENT 或 HOUGH_GRADIENT_ALT.
double dp, //
double minDist, // 检测到圆心之间的最小距离
double param1 = 100, // 作为Canny边缘检测中的上限阈值,下限阈值为0.5倍。
double param2 = 100, // 共圆的像素点的个数
int minRadius = 0,
int maxRadius = 0 // 用于限制查找圆的半径范围
)
// 代码案例
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include
#include
using namespace cv;
using namespace std;
int main(int argc, char** argv)
{
Mat img, gray, img1;
img1 = imread("D:/AFile_LIMAOHUA/OpencvProject/ConsoleApplication1/ConsoleApplication1/C.jpg", 1);
img = img1.clone();
cvtColor(img, gray, COLOR_BGR2GRAY);
// smooth it, otherwise a lot of false circles may be detected
GaussianBlur(gray, gray, Size(9, 9), 2, 2);
vector circles;
HoughCircles(gray, circles, HOUGH_GRADIENT, 1, 20, 50, 30, 0, 80); // 该函数内部会进行Canny边缘检测
for (size_t i = 0; i < circles.size(); i++)
{
Point center(cvRound(circles[i][0]), cvRound(circles[i][1]));
int radius = cvRound(circles[i][2]);
// draw the circle center
circle(img, center, 3, Scalar(0, 255, 0), -1, 8, 0);
// draw the circle outline
circle(img, center, radius, Scalar(0, 0, 255), 1, 8, 0);
}
namedWindow("circles", 1);
imshow("circles", img);
namedWindow("circles1", 1);
imshow("circles1", img1);
namedWindow("gauss", 1);
imshow("gauss", gray);
waitKey(0);
return 0;
}
4.3 使用广义霍夫变换(不规则图形的识别实现目标检测(该方法不适用于实时性要求高的应用场景,高分辨率图像可能花费几分钟时间。)
广义霍夫变换的优点:
1、广义霍夫变换本质上是一种用于物体识别的方法。
2、它对部分或轻微变形的形状鲁棒性好(即对遮挡下的识别鲁棒性好)。
3、对于图像中存在其他结构(即其他线条,曲线等)干扰,鲁棒性好。
4、抗噪声能力强。
5、一次遍历即可找到多个同类目标。
缺点是需要大量的计算和存储空间。
使用步骤:
- 加载待检测图像以及目标模板图像;
- 实例化 cv::GeneralizedHoughBallard和 cv::GeneralizedHoughGuil 算法类;
- 设置类相关的参数变量;
- 执行检测与检测结果显示;
具体案例见官方链接: https://docs.opencv.org/4.7.0/da/ddc/tutorial_generalized_hough_ballard_guil.html
Ptr ballard = createGeneralizedHoughBallard();
Ptr guil = createGeneralizedHoughGuil();
5. 几何变换
5.1 重映射变换
定义:从图像中获取一个位置的像素并将它们定位在新图像中的另一个位置。如果映射图像的尺寸与原始图像不一致,可能需要使用插值法。 最简单的重映射变换有镜像翻转(水平、垂直方向)等。
// cv::remap()函数
// 数学模型: dst(x,y)=src(mapx(x,y),mapy(x,y))
void cv::remap ( InputArray src,
OutputArray dst,
InputArray map1,
InputArray map2,
int interpolation, // 插值方法
int borderMode = BORDER_CONSTANT,
const Scalar & borderValue = Scalar()
)
// map1和map2的参数解释(以上下翻转为例):
// 反转公式为:h(i,j)=(i,src.rows−j)
// 则有map1 = i; map2 = src.rows - j; 具体如下所示:
Mat src = imread( " path.jpg", IMREAD_COLOR ); // 读取图片
Mat dst(src.size(), src.type()); // 创建翻转后的图像变量
Mat map_x(src.size(), CV_32FC1); // 创建X方向的MAP1;
Mat map_y(src.size(), CV_32FC1); // 创建Y方向的MAP2;
for( int i = 0; i < map_x.rows; i++ )
{
for( int j = 0; j < map_x.cols; j++ )
{
map_x.at(i, j) = (float)j; // 待变换的像素的列坐标不变
map_y.at(i, j) = (float)(map_x.rows - i); // 待变换的像素的行坐标由第一行变最后一行
}
}
remap( src, dst, map_x, map_y, INTER_LINEAR, BORDER_CONSTANT, Scalar(0, 0, 0) );
5.2 仿射变换
仿射变换是以下基础变换的任意复合:
- 图像平移(线性变换)
- 图像旋转(向量加法)
- 图像缩放(线性变换)
定义:仿射变换是指图像可以通过一系列的几何变换来实现平移、旋转等多种操作。该变换能够保持图像的平直性和平行性。平直性是指图像经过仿射变换后,直线仍然是直线;平行性是指图像在完成仿射变换后,平行线仍然是平行线。
对应公式(两行三列的矩阵):dst(x, y) = src(M11x + M12y + M13, M21x + M22y + M23) 对于图像平移,只需要将M11,M12, M21, M22设置为1, M13设置为行偏移,M23设置为列方向的偏移就可以作为平移矩阵。
在opencv中可以用以下两个函数实现仿射变换。
// 基础仿射变换函数
void cv::warpAffine ( InputArray src,
OutputArray dst,
InputArray M, // 2行3列的仿射变换矩阵
Size dsize, // 输出图像的大小
int flags = INTER_LINEAR, // 插值模式或 WARP_INVERSE_MAP(用于逆向变换)
int borderMode = BORDER_CONSTANT,
const Scalar & borderValue = Scalar()
)
// 旋转缩放仿射变换矩阵M(2行3列)的获取函数
Mat cv::getRotationMatrix2D ( Point2f center, // 旋转图像的中心点
double angle, // 角度,以角度表示,正值表示逆时针旋转,负值表示顺时针旋转
double scale // 缩放因子
)
// 获取更加复杂的仿射变换矩阵(根据三对3仿射变换对应点获取仿射变换矩阵)
Mat cv::getAffineTransform ( const Point2f src[], // 输入图像上的三个顶点,长度为3的点类型数组
const Point2f dst[] // 输出图像上对应的三个顶点,长度为3的点类型数组
)
5.3 透视变换
定义:仿射变换可以将矩形映射为任意的平行四边形,透视变换则可以将矩形映射为任意四边形;
// 获取透视变换矩阵M(3行3列)
Mat cv::getPerspectiveTransform ( const Point2f src[], // 原始图像上的四个顶点坐标, 长度为4的点类型数组
const Point2f dst[], // 透视变换后图像上对应的四个顶点坐标 , 长度为4的点类型数组
int solveMethod = DECOMP_LU // 矩阵求解的具体实现方法,有速度和精确度上的差异
)
// 进行透视变换
void cv::warpPerspective ( InputArray src,
OutputArray dst,
InputArray M, // 3*3的矩阵
Size dsize,
int flags = INTER_LINEAR,
int borderMode = BORDER_CONSTANT,
const Scalar & borderValue = Scalar()
)
5.4 几何变换示例代码
// 基本案例代码,实现仿射变换,旋转缩放
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
CommandLineParser parser( argc, argv, "{@input | lena.jpg | input image}" );
Mat src = imread( samples::findFile( parser.get( "@input" ) ) );
if( src.empty() )
{
cout << "Could not open or find the image!\n" << endl;
cout << "Usage: " << argv[0] << " " << endl;
return -1;
}
Point2f srcTri[3]; // 长度为3的点类型数组
srcTri[0] = Point2f( 0.f, 0.f );
srcTri[1] = Point2f( src.cols - 1.f, 0.f );
srcTri[2] = Point2f( 0.f, src.rows - 1.f );
Point2f dstTri[3]; // 长度为3的点类型数组
dstTri[0] = Point2f( 0.f, src.rows*0.33f );
dstTri[1] = Point2f( src.cols*0.85f, src.rows*0.25f );
dstTri[2] = Point2f( src.cols*0.15f, src.rows*0.7f );
// 复杂仿射变换
Mat warp_mat = getAffineTransform( srcTri, dstTri );
Mat warp_dst = Mat::zeros( src.rows, src.cols, src.type() );
warpAffine( src, warp_dst, warp_mat, warp_dst.size() );
// 旋转缩放
Point center = Point( warp_dst.cols/2, warp_dst.rows/2 );
double angle = -50.0;
double scale = 0.6;
Mat rot_mat = getRotationMatrix2D( center, angle, scale );
Mat warp_rotate_dst;
warpAffine( warp_dst, warp_rotate_dst, rot_mat, warp_dst.size() );
// 透视变换相较于仿射变换的区别在与需要4个点
// vector src_point(4); vector dst_point(4);
// Mat wrap_mat = getPerspectiveTransform(src_point, dst_point);
// warpPerspective(image, resultImg, wrap_mat, Size(new_width, new_height));
imshow( "Source image", src );
imshow( "Warp", warp_dst );
imshow( "Warp + Rotate", warp_rotate_dst );
waitKey();
return 0;
}
三. 图像直方图相关部分:
定义:图像直方图表示了图像像素强度的分布,量化了每个像素强度值对应的像素数。
3.1 opencv中图像直方图的计算
// 计算图像直方图函数,opencv提供了三种重写成员函数,对于计算多通道图像直方图,一般需要将图像转换到HSV空间。
void cv::calcHist ( const Mat * images, // 任意通道和数量的图像数组,Mat类型数组
int nimages, // 表示指定图像的数量
const int * channels, // 指定使用哪个维度的通道去计算图像直方图,假设有2张3通道图像,那么就有数组{0,1,2, 3,4,5}用于计算所有图像所有通道的图像直方图,但是只需计算第一张和2张第一个通道的直方图,就为{0, 3}; 整数类型数组;
InputArray mask, // 可以传递Mat()表示空掩码,若Mask不为空,就必须保证掩码的长宽与输入图像一致,且数据类型为CV_8U。
OutputArray hist, // 存储直方图统计结果的矩阵,是一个dims维度的数组。dims = channels的长度
int dims, // 需要计算的直方图的维度,必须是整数
const int * histSize, // 每个维度的直方图的尺寸,其实就是将0-255之间划分为多少个等分,其长度要与channels一致,如int histSize[ ] = {32, 32, 32 , 100, 100, 100} 表示第一张图片所有通道的直方图都被划分为32个块,第二张图所有通道被划分为100个块。
const float ** ranges, // 需要指定每一个图像通道图像灰度值强度的取值范围,如const float* ranges[ ] = {{0, 255}, {0, 255} , {0, 255}, {0, 255}, {0, 255}, {0, 255}}; 注意这里是一个二维数组。
bool uniform = true, // 对灰度值范围是否使用均值实现区域的均等划分,和histSize相关联;
bool accumulate = false // 如果这个标志值为true,那么上一次调用函数calcHist()所计算出的保存在hist中的数据是不会被清空的,而且会与这次调用的值累加;如果这个标志值为false,那么上一次调用函数calcHist()所计算出的保存在hist中的数据是会被清空的。
)
// 其他相关函数:通道拆分
void cv::split ( const Mat & src, // 原始图像
Mat * mvbegin // Mat 类型的数组
)
// 范围归一化操作,是指将计算的灰度直方图数组数据归一化到指定的[a, b ]数值区间,方便与图像直方图的显示;
void normalize( InputArray src, OutputArray dst, double alpha = 1, double beta = 0,
int norm_type = NORM_L2, int dtype = -1, InputArray mask = noArray());
// 1. InputArray类型的src,输入图像,如Mat类型。
// 2. OutputArray类型的dst,输出图像。
// 3. double类型的alpha,归一化相关的数值。
// 4. double类型的beta,归一化相关的数值。
// 5. int类型的norm_type,归一化类型。
// 6. int类型的dtype,默认值-1,与输出矩阵的类型和通道相关。
// 7. InputArray类型的mask,掩膜。
// 注意:其中alpha和beta要根据norm_type的选择而定;一般选择NORM_MINMAX,此时,alpha和beta分别为1,0;
// 案例代码
vector bgr_planes;
split( src, bgr_planes ); // 假设src是一个BGR三通道彩色图像, 进行通道拆分
int histSize = 256; // 每一个灰度值强度作为一个划分区块
float range[] = { 0, 256 }; // 灰度强度的范围
const float* histRange[] = { range }; // 变成二维数组
bool uniform = true; // 是否使用均值划分区块
accumulate = false; // 不适用累加
Mat b_hist, g_hist, r_hist;
calcHist( &bgr_planes[0], 1, 0, Mat(), b_hist, 1, &histSize, histRange, uniform, accumulate );
calcHist( &bgr_planes[1], 1, 0, Mat(), g_hist, 1, &histSize, histRange, uniform, accumulate );
calcHist( &bgr_planes[2], 1, 0, Mat(), r_hist, 1, &histSize, histRange, uniform, accumulate );
// 上面三个计算可以使用一个calcHist进行合并处理
int hist_w = 512, hist_h = 400;
int bin_w = cvRound( (double) hist_w/histSize );
Mat histImage( hist_h, hist_w, CV_8UC3, Scalar( 0,0,0) );
normalize(b_hist, b_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat() );
normalize(g_hist, g_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat() );
normalize(r_hist, r_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat() );
3.2 直方图均衡处理(Histogram equalization增强图像的对比度,通常适用于灰度图,彩色图像一般是单通道处理后合并)
定义:这种方法通常用来增加许多图像的全局对比度。这样就可以用于增强局部的对比度而不影响整体的对比度,直方图均衡化通过有效地扩展常用的亮度来实现这种功能。这种方法对于背景和前景都太亮或者太暗的图像非常有用。
链接: https://en.wikipedia.org/wiki/Histogram_equalization
公式展示:

均衡化图像的前后对比图:

opencv下的直方图均衡化函数:
// 图像直方图均衡化函数(一般针对灰度图像)
void cv::equalizeHist ( InputArray src, // 输入图像,Source 8-bit single channel image.
OutputArray dst // 均衡化后的图像,与输入图像类型和大小一致。
)
// 该函数进行了如下操作:
// 1. 计算src的图像直方图。
// 2. Normalize这个直方图,使图像区块和为255;
// 3. 计算直方图的累计分布直方图;
// 4. 使用查表法转换图像的灰度值;
3.3 直方图比较(利用不同metric去评判多张图像的直方图的相似性,进而判断多张图像之间的相似性)
注意: 直方图可以做均衡化处理,也可以不做,看实际的应用场景;
metric共有4种:
- 相关性比较(Correlation),取值为[-1,1];不太准确
- 卡方比较(Chi-Square),取值为0-1,相似度越高越趋近于0;
- 十字交叉性(Intersection),以两个均衡直方图中每个区块对应中的最小值做累积和;
- 巴氏距离(Bhattacharyya distance),计算最为复杂但效果最好,其取值范围0-1,1表示相似度最高;
// 直方图比较函数
double cv::compareHist ( InputArray H1, // 直方图1, 必须保证H1和H2长度相等。
InputArray H2, // 直方图2
int method // 方法HISTCMP_CORREL 、HISTCMP_CHISQR、HISTCMP_INTERSECT 、HISTCMP_BHATTACHARYYA 、HISTCMP_CHISQR_ALT 等
)
3.4 对比度受限的自适应直方图均衡化(CLAHE)算法
用途:在图像去雾、低照度图像增强,水下图像效果调节、以及数码照片改善等方面都有应用。
提取的背景:全局的直方图均衡化算法会导致图像整体的强度增强,这会使得关注的局部区域由于像素强度过大,导致图像细节丢失严重,所以提出了将图像划分为n个小方块单独进行直方图均衡化,但是当小方块存在噪声时,直方图均衡化会放大噪声,所以引入了对比度受限的方法。
// 对比度受限的自适应直方图均衡化函数
Ptr cv::createCLAHE ( double clipLimit = 40.0, // 受限的对比度阈值
Size tileGridSize = Size(8, 8) // 默认为8*8的小区域(将图像划分为8行8列个小区域)
)
// 上面函数使用方法:
// 上面函数创建了一个CLAHE的类,并进行了初始化操作;
// 创建对象之后,可以调用CLAHE的实例的apply()虚函数用于均衡化图像;
virtual void cv::CLAHE::apply ( InputArray src, // 输入待处理图像type CV_8UC1 or CV_16UC1.
OutputArray dst // 均衡化处理后的图像
)
// 使用的案例代码
cv::Mat clahe_img, outImage; // 假设输入图像clahe_img是一个灰度图像
outImage.creat(clahe_img.size(), clahe_img.type());
cv::Ptr clahe = cv::createCLAHE(40,Size(8,8) );
// 直方图的柱子高度大于计算后的ClipLimit的部分被裁剪掉,然后将其平均分配给整张直方图
clahe->apply(clahe_img, outImage);
3.5 直方图反投影(多用于彩色(HSV空间下)图像的分割或目标检测,主要是颜色比灰度值强度的直方图更加可区分)-----案例用于图像分割

// 直方图反投影函数
void cv::calcBackProject ( const Mat * images, // Mat类型的数组
int nimages, // 源图像数量
const int * channels, // 指定一个待操作的图像通道数组{0,1,2}..可以参考3.1节对calcHist的参数的介绍
InputArray hist, //
OutputArray backProject, // 反投影函数的矩阵,与输入图像大小、深度相等的单通道图像
const float ** ranges, // 每一个图像通道像素值的取值范围,二维数组
double scale = 1,
bool uniform = true
)
// 获取指定图像通道到指定输出数组; 其实可以使用split代替。
void cv::mixChannels ( const Mat * src, // 输入数组或向量矩阵;所有矩阵必须具有相同的大小和相同的深度。
size_t nsrcs, // src的长度
Mat * dst, // 输出数组或向量矩阵;所有矩阵必须已经被指定内存空间,且大小和深度必须与输入图像一致。
size_t ndsts, // dst的长度
const int * fromTo, // 指定复制哪张图像的哪一个通道
size_t npairs // 在fromTo中索引对的数量
)
// mixChannels函数的使用方法
Mat bgra( 100, 100, CV_8UC4, Scalar(255,0,0,255) );
Mat bgr( bgra.rows, bgra.cols, CV_8UC3 );
Mat alpha( bgra.rows, bgra.cols, CV_8UC1 );
// forming an array of matrices is a quite efficient operation,
// because the matrix data is not copied, only the headers
Mat out[] = { bgr, alpha };
// bgra[0] -> bgr[2], bgra[1] -> bgr[1],
// bgra[2] -> bgr[0], bgra[3] -> alpha[0]
int from_to[] = { 0,2, 1,1, 2,0, 3,3 }; // 是一个索引对
mixChannels( &bgra, 1, out, 2, from_to, 4 );
// 利用直方图反向投影算法实现分割
Mat hsv; // 创建HSV图像变量
cvtColor(src, hsv, COLOR_BGR2HSV); // src是一个RGB图像
hue.create(hsv.size(), hsv.depth());
int ch[] = { 0, 0 };
mixChannels(&hsv, 1, &hue, 1, ch, 1); // 调用该函数前必须先为hue分配内存
const char* window_image = "Source image";
namedWindow(window_image);
int histSize[] = { 2 }; // 表示将图像直方图的横坐标划分为两个区块{0, 89} 和 {90, 179}
float hue_range[] = { 0, 180 }; // hsv图像H通道的取值范围
const float* ranges[] = { hue_range };
Mat hist;
calcHist(&hue, 1, 0, Mat(), hist, 1, histSize, ranges, true, false);
normalize(hist, hist, 0, 255, NORM_MINMAX, -1, Mat());
Mat backproj;
calcBackProject(&hue, 1, 0, hist, backproj, ranges, 1, true);
imshow("BackProj", backproj);
imshow(window_image, src);
// Wait until user exits the program
waitKey();

3.6 模板匹配(基础模板匹配算法(主要是利用图像的灰度值特征),不能用于旋转缩放或轻微变化以及多目标的检测)
定义:给定一个目标模板图像,在一张包含模板对象的图像中定位模板目标位置的技术。
基本原理:
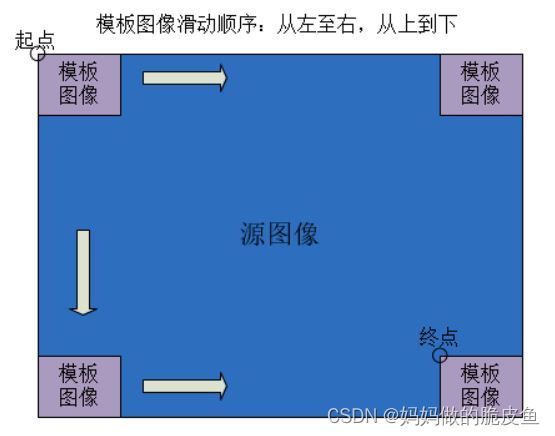
模板图像在待检测图像上按照从左至右,从上至下的顺序逐像素滑动来获取候选区域,并将候选区域与模板图像进行相似度的计算,最后将获得的相似度数值存储到(W-w+1, H-h+1)的矩阵中主要是因为模板不能滑出图像区域,所以矩阵的宽高小于原始图像。
思考:但是如果直接使用上面的思路,那么对于旋转缩放图像和搜索速度是不可接受的,opencv基于此引入了图像金字塔的方法以及使用旋转和尺度不变特征进行相似度计算,提升检测速度。
opencv提供了几种相似度计算方法:
- 平方差匹配method=TM_SQDIFF;最好匹配为0.匹配越差,匹配值越大.
- 标准平方差匹配 method=TM_SQDIFF_NORMED;
- 相关匹配 method=TM_CCORR:所以较大的数表示匹配程度较高,0标识最坏的匹配效果
- 标准相关匹配 method=TM_CCORR_NORMED;
- 相关匹配 method=TM_CCOEFF:1表示完美匹配,-1表示匹配很差,0表示没有任何相关性(随机序列).
- 标准相关匹配 method=TM_CCOEFF_NORMED:
opencv相关函数介绍:
// 模板匹配函数
void cv::matchTemplate ( InputArray image, // It must be 8-bit or 32-bit floating-point
InputArray templ, // 模板, 通常建议对模板进行归一化处理
OutputArray result, // 必须是单通道32位浮点型,并且 宽高为(W-w+1, H-h+1)
int method, // TM_SQDIFF ,TM_SQDIFF_NORMED等
InputArray mask = noArray() // 使用掩码可以对模板和候选区域的某些部分屏蔽掉,以实现即使模板与候选区域在匹配过程忽略掉掩码部分的差异。
)
// 获取Mat中最大值和最小值以及最大值和最小值对应的坐标点
void cv::minMaxLoc ( InputArray src, // matchTemplate 函数的输出result
double * minVal, // 相关性的最小值
double * maxVal = 0, // 相关性的最大值
Point * minLoc = 0, // 最小相关左上角坐标
Point * maxLoc = 0, // 最大相关左上角坐标 ,注意:这里的最大相关不代表相似性程度最大
InputArray mask = noArray() // 用于确定src的有效区域
)
扩展内容:
建议当获取到result之后,如果输入图像存在多个模板对象,就不能单一的使用minMaxLoc去获取目标位置,而是可以考虑使用非极大值抑制算法去筛选多个最佳匹配目标;
// opencv实现模板匹配的案例:
int main()
{
Mat img_display;
img.copyTo( img_display );
int result_cols = img.cols - templ.cols + 1;
int result_rows = img.rows - templ.rows + 1;
result.create( result_rows, result_cols, CV_32FC1 );
matchTemplate( img, templ, result, match_method);
normalize( result, result, 0, 1, NORM_MINMAX, -1, Mat() );
double minVal; double maxVal; Point minLoc; Point maxLoc;
Point matchLoc;
minMaxLoc( result, &minVal, &maxVal, &minLoc, &maxLoc, Mat() );
if( match_method == TM_SQDIFF || match_method == TM_SQDIFF_NORMED )
{ matchLoc = minLoc; } // 因为这两种方法的最小值才是对应最佳匹配位置
else // 其他方法的最大值对应最佳匹配位置
{ matchLoc = maxLoc; }
rectangle( img_display, matchLoc, Point( matchLoc.x + templ.cols , matchLoc.y + templ.rows ), Scalar::all(0), 2, 8, 0 );
rectangle( result, matchLoc, Point( matchLoc.x + templ.cols , matchLoc.y + templ.rows ), Scalar::all(0), 2, 8, 0 );
imshow( image_window, img_display );
imshow( result_window, result );
return;
}
3.7 模板匹配的算法扩展(github开源的多目标旋转缩放目标匹配)
知识扩展,不同模板匹配方法:
Fastest_Image_Pattern_Matching (可以实际使用)
链接: github :https://github.com/DennisLiu1993/Fastest_Image_Pattern_Matching
----优点: 开源,含SIMD加速与亚像素精度,与haclon形状匹配做过对比,角度与位置精度相差不大.
----缺点: 不支持多尺度匹配,匹配速度与halcon还是存在很大差距(同一台电脑上运行,该项目95ms,halcon 4.6ms),但感觉一般项目,时间上还是可以接受.
shape_based_matching
链接: github :https://github.com/meiqua/shape_based_matching
----优点: 开源,具备多目标,多角度,多尺度模板匹配功能。
----缺点: 匹配位置精度和角度与halcon相差较大,且存在同一目标匹配多次的问题,需要进一步去重等优化。
GeoMatch,Edge-Based-Template-Matching 用opencv编写的形状匹配算法,但不具旋转和缩放功能。
链接: https://www.codeproject.com/articles/99457/edge-based-template-matching
更多模板匹配的扩展方法内容总结可以参考博客:
链接: https://blog.csdn.net/libaineu2004/article/details/103026348
四. 图像轮廓处理部分(通常是边缘检测与图像分割后的继承操作):
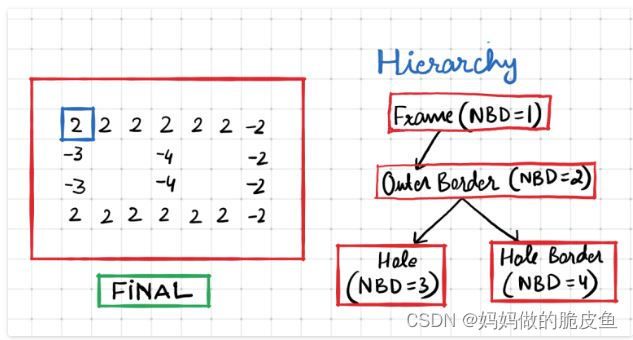
4.1 图像轮廓搜索
算法原理可以参考:
链接: https://theailearner.com/tag/suzuki-contour-algorithm-opencv/
其实基本可以视为围绕下面图片中的思路展开的:

// 轮廓查询函数参数解释
void cv::findContours ( InputArray image, // an 8-bit single-channel image,非零值视为1,0视为0,以将图像转换为二值化图像; 源图像可以由 compare, inRange, threshold , adaptiveThreshold, Canny获取
OutputArrayOfArrays contours, // Each contour is stored as a vector of points ,vector> contours
OutputArray hierarchy, // 如上图2表示层次的NBD,是一个 std::vector容器,其长度等于轮廓数量,具体元素的顺序为:[Next, Previous, First Child, Parent]。
int mode, //定义轮廓的检索模式
int method, // 定义轮廓的近似方法:
Point offset = Point() //Point偏移量,所有的轮廓信息相对于原始图像对应点的偏移量,相当于在每一个检测出的轮廓点上加上该偏移量
)
// hierarchy是对上图2树形结构的一个描述;
Next:与当前轮廓处于同一层级的下一条轮廓---若Next=-1表示同级没有下一条轮廓
Previous:与当前轮廓处于同一层级的上一条轮廓;Previous=-1同级没有上一条轮廓
First Child:当前轮廓的第一条子轮廓,没有子轮廓取-1.
Parent:当前轮廓的父轮廓,没有父轮廓取-1.
***// 参数mode的取值:***
==**RETR_EXTERNAL:**== 只检测最外围轮廓
==**RETR_LIST:**== 检测所有的轮廓,包括内围、外围轮廓,但是检测到的轮廓不建立等级关系
==**ETR_CCOMP:**== 检测所有的轮廓,但所有轮廓只建立两个等级关系,外围为顶层,若外围的内围轮廓还包含了其他的轮廓信息,则内围内的所有轮廓均归属于顶层
==**RETR_TREE:**== 检测所有轮廓,所有轮廓建立一个等级树结构。外层轮廓包含内层轮廓,内层轮廓还可以继续包含内嵌轮廓
**method:**
CHAIN_APPROX_NONE : 保存物体边界上所有连续的轮廓点到contours容器内
CHAIN_APPROX_SIMPLE :仅保存轮廓的拐点信息
CHAIN_APPROX_TC89_L1 : Teh-Chin近似算法
CHAIN_APPROX_TC89_KCOS : Teh-Chin近似算法
// 基本的案例代码
threshold(im,im,120,255,THRESH_BINARY);
vector<vector<Point> > contours;
vector<Vec4i> hierarchy;
findContours(im,contours,hierarchy,CV_RETR_CCOMP, CV_CHAIN_APPROX_NONE);
Mat contoursImage(im.rows,im.cols,CV_8U,Scalar(255));
for(int i=0;i<contours.size();i++){
if(hierarchy[i][3]!=-1) // 如果轮廓存在子轮廓,就将该轮廓绘出
drawContours(contoursImage,contours,i,Scalar(0),3);
}
4.2 获取轮廓的凸包(convexHull)
// 获取轮廓凸包的函数参数说明
void cv::convexHull ( InputArray points, // Input 2D point set, stored in std::vector or Mat.一般为轮廓点
OutputArray hull, // vector of points
bool clockwise = false, // 方向标志。如果为 true,则输出凸包的方向为顺时针方向。否则,它逆时针方向。
bool returnPoints = true // 为TRUE时表示返回的凸包为points向量,
)
4.3 获取轮廓的最小矩形/圆形/多边形包围框
opencv提供的相关函数:
// 用指定精度拟合多边形,用更少的顶点表示的多边形或曲线与原始的多边形或曲线之间的距离最小,或达到指定的精度需求。
void cv::approxPolyDP ( InputArray curve, // Input vector of a 2D point stored in std::vector or Mat,vector >
OutputArray approxCurve, // 与输入类型一致vector >
double epsilon, // 指定的最大距离
bool closed // 逼近的曲线或多边形是否闭合
)
// 计算指定点集或灰度图像非0像素的最小包围矩形
Rect cv::boundingRect ( InputArray array ) // gray-scale image or 2D point set, stored in std::vector or Mat
// 查找包围点集的最小闭合圆
void cv::minEnclosingCircle ( InputArray points, // Input vector of 2D points, stored in std::vector<> or Mat
Point2f & center, // 圆的中心点vector执行最小矩形/圆形/多边形包围框的案例
// 实例代码段
Mat canny_output;
Canny( src_gray, canny_output, thresh, thresh*2 ); // 边缘检测
vector<vector<Point> > contours;
findContours( canny_output, contours, RETR_TREE, CHAIN_APPROX_SIMPLE ); // 轮廓查找
vector<vector<Point> > contours_poly( contours.size()); // 逼近多边形轮廓点点变量
vector<Rect> boundRect( contours.size() );
vector<Point2f>centers( contours.size() );
vector<float>radius( contours.size() );
for( size_t i = 0; i < contours.size(); i++ )
{
approxPolyDP( contours[i], contours_poly[i], 3, true ); // 多边形逼近
boundRect[i] = boundingRect( contours_poly[i] ); // 最小矩形包围框
minEnclosingCircle( contours_poly[i], centers[i], radius[i] ); // 最小圆包围框
}
Mat drawing = Mat::zeros( canny_output.size(), CV_8UC3 );
for( size_t i = 0; i< contours.size(); i++ )
{
Scalar color = Scalar( rng.uniform(0, 256), rng.uniform(0,256), rng.uniform(0,256) );
drawContours( drawing, contours_poly, (int)i, color );
rectangle( drawing, boundRect[i].tl(), boundRect[i].br(), color, 2 );
circle( drawing, centers[i], (int)radius[i], color, 2 );
}
imshow( "Contours", drawing );
4.4 获取轮廓的面积和近似长度以及获取轮廓的质心
// 获取轮廓的面积
double cv::contourArea ( InputArray contour, // vector
bool oriented = false // 返回是否带有-号的值;
)
// 获取等值曲线或多边形的周长
double cv::arcLength ( InputArray curve, // vector
bool closed // 指定曲线是否闭合
)
4.5 计算图像的矩:cv::moments(), cv::HuMoments(),并利用图像矩获取轮廓的重心以及轮廓面积
定义: 图像不变矩是一组具有平移、灰度、尺度、旋转不变性的用于描述图像特征的数据,且该数据不易受到光线、噪声、几何变形的干扰。图像矩通常表征了图像的大小、灰度、方向、形状等特征,被广泛应用于模式识别、目标分类、目标识别、与防伪估计、图像编码、图像重构等领域。
几种常见矩:
(1)空间矩Mji(空间矩的实质为面积或者质量。)
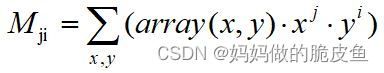
其中 (i + j) 等于几就表示几阶矩。
重心计算公式:
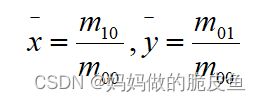
轮廓的面积:
area = M00;
(2)中心距MUji(中心矩体现的是图像强度的最大和最小方向(中心矩可以构建图像的协方差矩阵),其只具有平移不变性,所以用中心矩做匹配效果不会很好。)
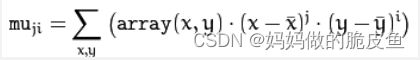
(3)归一化中心距

(4)Hu矩空间矩(Hu矩具有尺度、旋转、平移不变性,可以用来做匹配。)
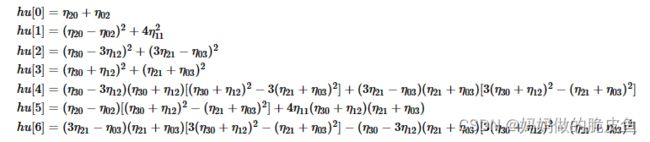
opencv 中提供了两个图像矩计算函数:
// 1. opencv中提供moments函数用于计算多边形区域的空间矩、
// 中心距、归一化中心距,最高为三阶矩:
Moments cv::moments (InputArray array, // 一幅8位、单通道图像,或一个二维浮点数组(Point of Point2f)。
bool binaryImage = false // 只有当输入为图象时才有用,表示是否将单通道图像视为二值化图像
)
// Moments类的成员变量如下所示:
cv::Moments::Moments
(
// 空间矩(10个)
double m00,double m10,double m01,double m20,double m11,double m02,double m30,double m21,double m12,double m03
// 中心矩(7个)
double mu20, double mu11, double mu02, double mu30, double mu21 , double mu12,double mu03
// 中心归一化矩()
double nu20, double nu11, double nu02, double nu30, double nu21, double nu12,double nu03;
)
// 使用中心矩计算Hu矩
void cv::HuMoments (const Moments & moments, // cv::Moments::Moments的计算结果
double hu[7]
)
图像中心矩和hu-矩的计算案例:
int main()
{
Mat image = imread( "F:/C++/2. OPENCV 3.1.0/TEST/test1.png", 1 );
if(!image.data ) { printf("读取图片错误,请确定目录下是否有imread函数指定图片存在~! \n"); return false; }
cvtColor(image, image, CV_BGR2GRAY);
Moments mts = moments(image); // 对整副图像求所有矩,当然这里可以输入轮廓点集,当以图像为输入时,会将所有大于0的像素点视为轮廓点集
// 计算质心
//add 1e-5 to avoid division by zero,这里很重要。
// Point2f mc; 用于存储质心
// mc = Point2f( static_cast(mu[i].m10 / (mu[i].m00 + 1e-5)),static_cast(mu[i].m01 / (mu[i].m00 + 1e-5)) );
// 计算面积
// double Contour_area mu[i].m00;
double hu[7];
HuMoments(mts, hu); // 对整副图像求Hu几何不变矩
for (int i=0; i<7; i++)
{
cout << log(abs(hu[i])) <<endl; // 取对数 (自然指数e 为底)
}
return 0;
}
4.6 判断点与轮廓的位置关系(内部、外部、在轮廓线上)
opencv提供的函数如下所示:
double cv::pointPolygonTest ( InputArray contour, // 输入轮廓点集
Point2f pt, // 指定点
bool measureDist // 当该值为TRUE时返回与等值线的实际距离,为false时返回-1表示在外部,0表示在轮廓线上、1表示在内部。
)
扩展: 可以根据指定的轮廓取获取所有在轮廓内部或外部的像素,进而实现图像目标物的提取。
五. 距离变换与分水岭算法实现图像分割:
5.1 将图像的指定区域设置为指定的值
Mat& cv::Mat::setTo ( InputArray value, // 标量转换为输入数组如:Scalar(0, 0, 0)
InputArray mask = noArray() // 必须是CV_8U数据类型,可以有多个通道
)
5.2 连通域提取(常用于图像分割之后)
连通域提取函数
int cv::connectedComponents ( InputArray image, //待标记不同连通域的单通道图像,数据类型必须为CV_8U。
OutputArray labels, // 标记不同连通域后的输出图像,与输入图像具有相同的尺寸。这里相当于是不同组件的像素被赋予对应的标签,相当于是一个掩码。
int connectivity = 8, // 4或8领域
int ltype = CV_32S, // 输出图像标记的类型 CV_32S and CV_16U
int ccltype // 连通域提取的算法类型
)
返回值表示提取到的连通域的个数,包含了背景
连通域提取的算法类型ccltype :
CCL_DEFAULT:
CCL_WU:
CCL_GRANA:
CCL_BOLELLI:
CCL_SAUF:
CCL_BBDT :
CCL_SPAGHETTI:
第二种重载函数
int cv::connectedComponents ( InputArray image,
OutputArray labels,
int connectivity = 8,
int ltype = CV_32S
)
扩展函数:
connectedComponentsWithStats(); 可以用于进行连通域提取并获得各个组件的中心坐标,以及最小矩形包围框。
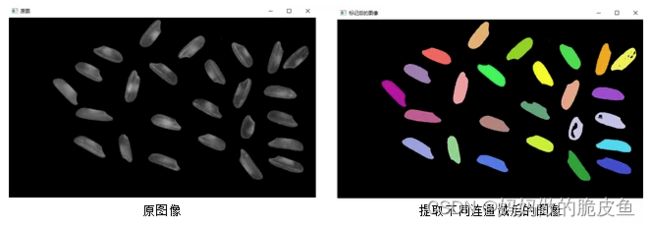
提取连通域的案例代码:
1.#include <opencv2\opencv.hpp>
2.#include <iostream>
3.#include <vector>
4.
5.using namespace cv;
6.using namespace std;
7.
8.int main()
9.{
10. //对图像进行距离变换
11. Mat img = imread("rice.png");
12. if (img.empty())
13. {
14. cout << "请确认图像文件名称是否正确" << endl;
15. return -1;
16. }
17. Mat rice, riceBW;
18.
19. //将图像转成二值图像,用于统计连通域
20. cvtColor(img, rice, COLOR_BGR2GRAY);
21. threshold(rice, riceBW, 50, 255, THRESH_BINARY);
22.
23. //生成随机颜色,用于区分不同连通域
24. RNG rng(10086);
25. Mat out;
26. int number = connectedComponents(riceBW, out, 8, CV_16U); //统计图像中连通域的个数
27. vector<Vec3b> colors;
28. for (int i = 0; i < number; i++)
29. {
30. //使用均匀分布的随机数确定颜色
31. Vec3b vec3 = Vec3b(rng.uniform(0,256),rng.uniform(0,256),rng.uniform(0,256));
32. colors.push_back(vec3);
33. }
34.
35. //以不同颜色标记出不同的连通域
36. Mat result = Mat::zeros(rice.size(), img.type());
37. int w = result.cols;
38. int h = result.rows;
39. for (int row = 0; row < h; row++)
40. {
41. for (int col = 0; col < w; col++)
42. {
43. int label = out.at<uint16_t>(row, col); // 最关键的是这行代码
44. if (label == 0) //背景的黑色不改变
45. {
46. continue;
47. }
48. result.at<Vec3b>(row, col) = colors[label];
49. }
50. }
51.
52. //显示结果
53. imshow("原图", img);
54. imshow("标记后的图像", result);
55.
56. waitKey(0);
57. return 0;
58.}
5.3 距离变换(获取前景各组件的闭合轮廓、图像中心点、骨架等)
定义:就是计算一个二值图像中所有像素值大于1的像素离其最近小于等于0的像素之间的距离,并将计算所得的距离作为当前前景像素的灰度值。
实现的基础原理如下图所示:

上图显示的是经典的TD算法执行的过程,0,1,2,3表示该像素的一个类别标签。通常需要使用不同的距离计算公式去获取0点到非0点之间的距离。
上面图二为距离变换后的图像,可以看出,距离背景像素越远的前景像素强度越亮,进而从视觉上形成了一种水塘的效果。即形成了一种前景包围背景的轮廓。也可以参考下图,能够有更加清晰的获取到分割每个组件的轮廓:

opencv中提供了两种计算距离变换的函数(距离变换的值大于0):
void cv::distanceTransform ( InputArray src, // 8位二值化单通道图像
OutputArray dst, // 8位或32位浮点单通道图像
OutputArray labels, // 输出2D的标签,类型为CV_32SC1
int distanceType,
int maskSize,
int labelType = DIST_LABEL_CCOMP
)
distanceType:
DIST_USER--自定义距离函数
DIST_L1--distance = |x1-x2| + |y1-y2|
DIST_L2--欧式距离函数,推荐使用
DIST_C--distance = max(|x1-x2|,|y1-y2|)
DIST_L12--L1-L2 metric: distance = 2(sqrt(1+x*x/2) - 1))
DIST_FAIR--distance = c^2(|x|/c-log(1+|x|/c)), c = 1.3998
DIST_WELSCH-- distance = c^2/2(1-exp(-(x/c)^2)), c = 2.9846
DIST_HUBER-- distance = |x|<c ? x^2/2 : c(|x|-c/2), c=1.345
maskSize:
DIST_MASK_3
DIST_MASK_5
注意:distanceType等于DIST_L1或DIST_C下时,3*3和5*5所得结果一样。
labelType:
DIST_LABEL_CCOMP: 相邻(同一个component)的背景像素都将被赋予同一个类别标签。
DIST_LABEL_PIXEL:每一个背景像素都将被赋值不同的标签
// 对上面函数的重载
void cv::distanceTransform ( InputArray src,
OutputArray dst,
int distanceType,
int maskSize,
int dstType = CV_32F
)
5.3 分水岭算法(官网链接:链接: https://people.cmm.minesparis.psl.eu/users/beucher/wtshed.html)
基本过程可以基于下图进行理解:
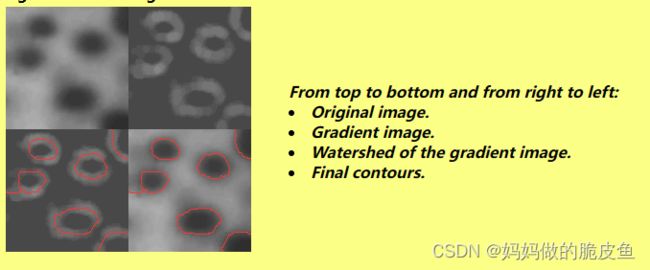
但是使用在实际应用中,使用上面的流程会导致过度分割,这主要是因为梯度图易受噪声和图像局部的极度不稳定性的干扰。
基于此提出了基于标记受控的分水岭算法(Marker-controlled watershed) 基本过程如下图:
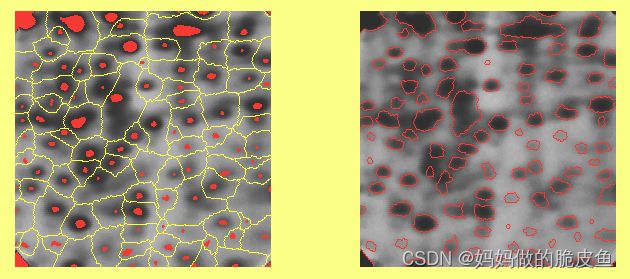
可以看到上面左图和之前距离变换图像的结果图像有点类似。所以距离变换图像结果通常可以用来作为分水岭算法的标记。当然也可以使用其他自动标记方法
如分水岭算法官网提供的咖啡豆分离方法:(距离函数+分水岭)

opencv提供了基于标记点约束的分水岭函数:
void cv::watershed ( InputArray image, 8位三通道图像
InputOutputArray markers // 32位单通道图像
)
// 参数markers的解释
5.4 类型转换函数
void cv::Mat::convertTo ( OutputArray m,
int rtype,
double alpha = 1,
double beta = 0
)
转换公式:m(x,y)=saturate_cast<rType>(α(∗this)(x,y)+β)
5.4 使用距离变换结合分水岭算法实现图像分割案例(在使用分水岭算法是,应当尽可能多的将前景进行标注)
以halcon中的糖块分割为例:
整个流程为:
(1)阈值分割与连通域提取
(2)距离变换+分水岭算法(获取标记掩码,其中等于0表示不确定区域,等于1表示背景,大于1表示前景)
(3)求取阈值分割区域与分水岭分割区域的交集部分,就可以获取到糖豆的具体位置
- halcon分割代码,有助于理解整个过程:
dev_clear_window()
dev_get_window (WindowHandle)
*读取图片
read_image (Image, 'C:/Users/hp/Desktop/1.JPG')
dev_set_draw ('fill')
*read_image (Image, 'pellets')
get_image_size (Image, Width, Height)
*自动阈值分割
rgb1_to_gray (Image, GrayImage)
threshold (GrayImage, Regions, 110, 255)
connection (Regions, ConnectedRegions)
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 40, 50000)
*欧式距离函数的距离变换
distance_transform (SelectedRegions, DistanceImage, 'octagonal', 'true', Width, Height)
*int4转byte(将灰度值的范围约束到0-255)
convert_image_type (DistanceImage, ImageConverted, 'byte')
*图像取反
invert_image (ImageConverted, ImageInvert)
*图像比例增强 按最大比例增强对比度。
scale_image_max(ImageInvert, ImageScaleMax)
*分水岭算法
watersheds_threshold(ImageScaleMax, Basins, 30) // 30是指两个相邻盆地相交岭峰与相邻盆地最低点的最大高度分割阈值,若大于30那么其中最低的盆地就作为一个独立的区域。
select_shape (Basins, SelectedBasins, 'area', 'and', 2000, 50000)
gen_contour_region_xld(SelectedBasins, Contours, 'border')
*取出两个区域中重叠的部分,分割出的区域与分水岭获取的区域求交集
intersection (SelectedBasins, SelectedRegions, RegionIntersection)
dev_display(Image)
dev_display(RegionIntersection)
dev_display(Image)
* dev_set_draw ('margin')
dev_set_line_width (3)
dev_display (RegionIntersection)
dev_set_color ('red')
dev_set_line_width (2)
area_center (RegionIntersection, Area, Row, Column) *
gen_cross_contour_xld (Cross, Row, Column, 15, 0.785398)
count_obj (RegionIntersection, Number)
*设置字体颜色
dev_set_color ('green')
*设置文字大小
set_display_font (WindowHandle, 30, 'mono', 'true', 'false')
*设置文字位置
set_tposition (WindowHandle, 15, 220)
write_string(WindowHandle, 'count=' + Number)
处理结果:
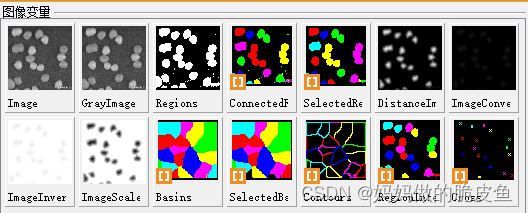
注意: 从下图可以看出intersection求交集实现了将阈值分割所得存在连接的多个目标完全分离。

- opencv分割代码
基本流程:
输入图像->灰度->阈值分割->距离变换(再次分割)->寻找种子(连通域提取,将连通域掩码作为分水岭所需的掩码)->转换连通域掩码格式为CV_32S, marker->分水岭变换->输出图像
#include (i, CC_STAT_LEFT);
int y = status.at(i, CC_STAT_TOP);
int w = status.at(i, CC_STAT_WIDTH);
int h = status.at(i, CC_STAT_HEIGHT);*/
int area = status.at<int>(i, CC_STAT_AREA);
// 其实这样写速度有些慢,应该先找出所有符合条件的label,在进行像素更改,这样只需遍历一遍图像
if (area < 20) // 将面积小于200的区域设置成背景,即将那些label等于i的像素更改为0
{
for (int row = 0; row < grayImage.rows; row++)
{
for (int col = 0; col < grayImage.cols; col++)
{
int index = connectImage.at<uint16_t>(row, col);
if (index == i) //背景的黑色不改变
{
grayImage.at<uint8_t>(row, col) = 0;
}
}
}
}
else
{
//绘制中心点
int center_x = (int)centroids.at<double>(i, 0);
int center_y = (int)centroids.at<double>(i, 1);
circle(CropImage, Point(center_x, center_y), 2, Scalar(0, 0, 255), 1, 8, 0);
}
}
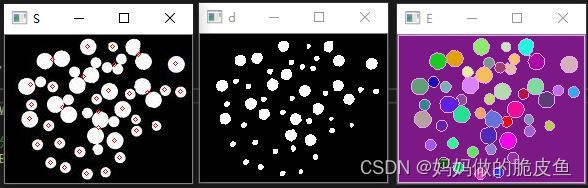
imshow("S", CropImage);
Mat UnKnown;
grayImage.copyTo(UnKnown);
// 对筛选后的二值化图像进行距离变换
Mat distanceImg(grayImage.size(), CV_32FC1);
distanceTransform(grayImage, distanceImg, DIST_L2, 3);
// 将距离变换结果归一化到0-1区间
normalize(distanceImg, distanceImg, 0, 1.0, NORM_MINMAX);
// 对距离变换图像进行阈值分割获取前景区域,以执行分水岭算法的标记
threshold(distanceImg, distanceImg, 0.4, 1.0, THRESH_BINARY);
// 设置不确定的区域为0
Mat kernel = getStructuringElement(2, Size(2, 2), Point(-1, -1));
dilate(distanceImg, distanceImg, kernel, Point(-1, -1), 1); // 加上该项处理,分割的想过会更好,所以得出尽可能将前景区域进行标记
imshow("d", distanceImg);
Mat dist_8u;
distanceImg.convertTo(dist_8u, CV_8U);
// 连通域提取
Mat mask_d;
int numbers = connectedComponents(dist_8u, mask_d, 8, CV_16U); // 注意这里返回的number的长度包含了背景,mask_d取值从0开始,0表示背景
// 将带有标签的掩码整体加1,其中背景变为1,其他前景标签大于1
mask_d += 1;
// 设置不确定的区域为0
Mat kernel1 = getStructuringElement(1, Size(3,3),Point(-1,-1));
dilate(UnKnown, UnKnown, kernel1,Point(-1,-1),3);
Mat disC;
distanceImg.convertTo(disC,CV_8U);
normalize(UnKnown, UnKnown,0,255 , NORM_MINMAX);
normalize(disC, disC, 0,255 , NORM_MINMAX);
mask_d.convertTo(mask_d, CV_8U);
Mat dImg = UnKnown - disC;
mask_d.setTo(Scalar(0), dImg);
/*normalize(mask_d, mask_d, 0, 255, NORM_MINMAX);
imshow("U", mask_d);*/
// 由于分水岭分割需要的掩码类型为CV_32S
Mat masker;
mask_d.convertTo(masker, CV_32S);
watershed(CropImage, masker);
// Generate random colors
vector<Vec3b> colors;
for (size_t i = 0; i < 255; i++) // 设置为255是为了显示颜色更加丰富,以保证不同区域不会显示为相近的颜色
{
int b = theRNG().uniform(0, 256);
int g = theRNG().uniform(0, 256);
int r = theRNG().uniform(0, 256);
colors.push_back(Vec3b((uchar)b, (uchar)g, (uchar)r));
}
// Create the result image
Mat dst1 = Mat::zeros(masker.size(), CV_8UC3);
masker.convertTo(masker,CV_8U);
// Fill labeled objects with random colors
for (int i = 0; i < masker.rows; i++)
{
for (int j = 0; j < masker.cols; j++)
{
int index = masker.at<uint8_t>(i, j);
cout << index << " numbers: " << numbers << endl;
dst1.at<Vec3b>(i, j) = colors[index*2];
}
}
imshow("E", dst1);
waitKey(0);
}
结果显示:
六 图像去模糊算法
图像去模糊主要的难点案例是不对焦造成的图像模糊和运动造成的图像模糊。对于其他类型的图像缺陷如噪点、曝光不正确、失真都有较好的处理方法。(来自:Restoration of defocused and blurred images)链接: http://yuzhikov.com/articles/BlurredImagesRestoration1.htm
这篇综述展示了常见的4种方法:
- Wiener filter
- Tikhonov regularization
- lucy-Richardson filter
- Blind deconvolution