subword系列算法
1. 前言
nlp领域目前已经发展到一个非常高的层次了,这个层次不仅仅是模型和数据方面,还涌现出了很多非常巧妙的trick,这篇文章就记录一下关于tokenization方面的工作。
所谓的tokenization其实就是将文本切分成words或者subwords,然后转成ids以便模型处理。最初的nlp分词非常简单,对于英语类以空格分割的语言来说,简单的以空格进行分割就行,不过这样简单的处理还存在一些问题,比如说*“Don’t you love Transformers? We sure do.”,如果简单分割,那么就会得到[“Don’t”, “you”, “love”, “”, “Transformers?”, “We”, “sure”, “do.”],对于“Transformers?”* 或者 “do.”这样的分词结果,显然是不合适,所以还需要考虑一下符号的影响,这可以通过现在很多开源工具实现,比如spaCy或者Moses等等。不过很明显会有个问题,那就是你切分的越细,得到的vocabulary越大,对于存储空间的要求也越大,虽然大部分情况下我们的词典都不会特别大,但是总是存在意外情况,尤其是Bert这类对于语料越大效果越好的模型的出现,更是加剧了这种情况。如果切分成words会导致内存问题,那么一个想法就是做character级别的tokenization,对于英文来说只有26个,那么算上大小写也只有52个,这可以大大缓解过大的embedding matrix问题,但是,character级别需要模型去从序列顺序中学习word的表示,模型在这方面显然不如直接切分word来的直观,所以这类方法会有性能方面的损失。在这种情况下,混合了word和character的一些新方法应运而出,这类方法被称为subword。
2.subword tokenization
2.1 Byte Pair Encoding
这种算法其实很简单,从其名字基本可以了解到一些东西,最显眼的就是pair这个词。它的做法是每次使用频次最高的一个字节对来替换这两个字节。
算法流程:
- 准备足够大的训练语料
- 确定期望的subword词表大小
- 将单词拆分为字符序列并在末尾添加后缀“ ”(这里不是必须,可以添加任意可以代表结束的字符),统计单词频率。 本阶段的subword的粒度是字符。 例如,“ low”的频率为5,那么我们将其改写为“ l o w ”:5
- 统计每一个连续字节对的出现频率,选择最高频者合并成新的subword
- 重复第4步直到达到第2步设定的subword词表大小或下一个最高频的字节对出现频率为1

2.1.1 构建subword字典
有输入的word和其频次,首先将word分成character,并将subword词典初始化为character:
{'l o w ': 5, 'l o w e r ': 2, 'n e w e s t ': 6, 'w i d e s t ': 3}
Iter 1, 最高频连续字节对"e"和"s"出现了6+3=9次,合并成"es",将"es"加入subword词典。输出:
{'l o w ': 5, 'l o w e r ': 2, 'n e w es t ': 6, 'w i d es t ': 3}
Iter 2, 最高频连续字节对"es"和"t"出现了6+3=9次, 合并成"est",并将"est"加入subword词典。输出:
{'l o w ': 5, 'l o w e r ': 2, 'n e w est ': 6, 'w i d est ': 3}
Iter 3, 以此类推,最高频连续字节对为"est"和"" 输出,同样加入subword词典:
{'l o w ': 5, 'l o w e r ': 2, 'n e w est': 6, 'w i d est': 3}
……
Iter n, 继续迭代直到达到预设的subword词表大小或下一个最高频的字节对出现频率为1。
2.1.2 编码
根据2.1.1得到了subword的字典,对单词就可以进行编码了,将字典按照字符长度递减排列,然后依次遍历词典中的subword,如果单词包含了该subword,那么就用该subword加入单词的分解集合中,对剩余的字符进行迭代。这里将词典首先排序,便可以保证最先加入集合的subword是最后生成的。若最后还有一些字符序列无法在字典中找到,则替换为特殊的subword,比如*< unk >*.
同样举个例子, 已有排好序的词典:
[“errrr”, “tain”, “moun”, “est”, “high”, “the”, “a”]
对单词"mountain",遍历词典,首先看到“tain”出现在了单词中,加入该subword,对剩余的"moun"继续便利,下一个subword “moun”匹配,加入,那么便得到了单词的分解结果为:[“moun”, “tain”]。
2.1.3 解码
将tokens拼接在一起即可,注意"< /w>"代表句子结束。
# 编码序列
[“the</w>”, “high”, “est</w>”, “moun”, “tain</w>”]
# 解码序列
“the</w> highest</w> mountain</w>”
2.2 WordPiece
wordpiece思路基本与Byte Pair Encoding,唯一的不同就是在进行合并tokens对的时候不是使用max frequency,而是使用概率来确定合并哪两个tokens对,计算公式为:
s c o r e ( A , B ) = F r e q u e n c y ( A , b ) / ( F r e q u e n c y ( A ) ∗ F r e q u e n c y ( B ) ) score(A,B)=Frequency(A,b)/(Frequency(A)*Frequency(B)) score(A,B)=Frequency(A,b)/(Frequency(A)∗Frequency(B))
取score最大的tokens对进行合并,这么做也很直观,类似于词袋模型中的tfidf。
transformers 库中的BERT tokenizer即是使用的这种方法:
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence = "A Titan RTX has 24GB of VRAM"
>>> tokenized_sequence = tokenizer.tokenize(sequence)
>> print(tokenized_sequence)
['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
"##“代表当前序列是前面字节的后缀,比如’R’, ‘##T’, '##X’三个序列,应该拼合为"RTX”.这里没有使用结束符号,而是使用拼接符号来确保单词何时结束。
2.3 Unigram Language Model
这是一种基于语言模型的tokenization方式,不同于BPE或者WordPiece,该方法不是从基础字符开始然后通过一定的规则进行合并,这种方法通过一个很大的词典开始,然后渐进的缩减词典规模。生成词典的具体流程如下:

其中,L的计算公式为:
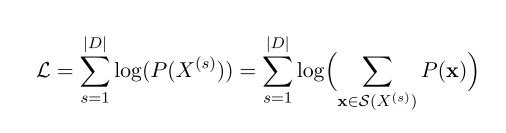
其中, ∥ D ∥ \|D\| ∥D∥为词典的大小, S ( x ) S(x) S(x)为词x的所有可能的tokenization组合集合。
得到词典以后,就是进行tokenization了,不过要注意的是tokenization的方式可能不止一种,比如有以下的词典:
['b', 'g', 'h', 'n', 'p', 's', 'u', 'ug', 'un', 'hug']
那么对于单词“hugs” ,可以有如下的几种组合: ['hug', 's'], ['h', 'ug', 's'] 或者 ['h', 'u', 'g', 's'],由于生成字典的时候每个subword都是有对应的概率的,所以可以取tokens概率乘积最大的组合或者以概率随机取一个组合。
2.4 SentencePiece
仔细看一下上面的几种方法可以发现,他们都是需要实现构建一个词典,然后迭代,而且上面几种方法对于没有分隔符的语言比如中文来说并不适用,因为对于中文这类语言来说,单个字已经是最小单元了,无法细分为更小的单元了。所以上面几种方法都是与语言相关的,那么,有没有language-independent 的方法呢?当当当,这时候就到了SentencePiece粉墨登场的时候了。
SentencePiece主要由4个模块组成:Normalizer,Trainer,Encoder, 以及Decoder。Normalizer是一个将语义等价的Unicode字符归一化为规范形式的模块。 Trainer从归一化语料中训练subword分割模型,一般使用BPE或者unigram。 Encoder内部执行Normalizer对输入文本进行归一化,并将输入文本用Trainer训练的subword模型标记成subword序列。 Decoder将subword序列转换为归一化文本。这四个模块有如下的关系:Decoder( Encoder (Normalizer(corpus))) = Normalizer (corpus),作者称这为lossless tokenization。通过这些模块,SentencePiece实现了一种端到端的tokenization。
transformers库的XlNet,ALBERT等使用了这种方法:
>>> from transformers import XLNetTokenizer
>>> tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
>>> tokenizer.tokenize("Don't you love Transformers? We sure do.")
['▁Don', "'", 't', '▁you', '▁love', '▁', '', '▁', 'Transform', 'ers', '?', '▁We', '▁sure', '▁do', '.']
其中的 ‘▁’ 代表空格,在decode的时候将该符号替换回空格即可。
3.中文实践
3.1 中文bpe算法
'''
中文bpe算法
'''
def get_pairs(word):
'''
:param word: tokens序列,对于中文而言,直接tuple(text)处理即可,处理后中文就变成了字的序列。
'''
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
class Encoder:
def __init__(self, encoder, bpe_merges):
'''
:param encoder: subword词典
:param bpe_merges: 需要合并的两个subwords
'''
self.encoder = encoder
self.decoder = {v: k for k, v in self.encoder.items()}
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
self.cache = {}
self.max_len = 0
def bpe(self, token):
'''
:param token: 要处理的文本
'''
if token in self.cache:
return self.cache[token]
word = tuple(token)
# 获取文本的所有字
pairs = get_pairs(word)
if not pairs:
return token
while True:
# 获取需要合并的subword对,注意这里已经排序
bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
# 不再继续可以合并
if bigram not in self.bpe_ranks:
break
first, second = bigram
new_word = []
# i代表first subword左边的所有subword序列
i = 0
while i < len(word):
try:
# 找到了可以合并的subword pair,先将first subword左边的所有subword加入list
j = word.index(first, i)
new_word.extend(word[i:j])
i = j
except:
# 没有找到可以合并的subword pair
new_word.extend(word[i:])
break
if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
# 找到了可以合并的subword对
new_word.append(first + second)
i += 2
else:
new_word.append(word[i])
i += 1
new_word = tuple(new_word)
word = new_word
if len(word) == 1:
break
else:
pairs = get_pairs(word)
word = ' '.join(word)
self.cache[token] = word
return word
def encode(self, text):
return [self.encoder.get(token, 1) for token in self.tokenize(text)]
def decode(self, tokens):
text = ''.join([self.decoder[token] for token in tokens])
return text
def tokenize(self, text):
bpe_tokens = []
bpe_tokens.extend(bpe_token for bpe_token in self.bpe(text).split(' '))
return bpe_tokens
def convert_tokens_to_ids(self, tokens):
return [self.encoder.get(token, 1) for token in tokens]
4.总结
-
传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题)
-
传统词tokenization方法不利于模型学习词缀之间的关系
-
- E.g. 模型学到的“old”, “older”, and “oldest”之间的关系无法泛化到“smart”, “smarter”, and “smartest”。
-
Character embedding作为OOV的解决方法粒度太细
-
Subword粒度在词与字符之间,能够较好的平衡OOV问题