pytorch实战5:基于pytorch复现ResNet
基于pytorch复现ResNet
前言
最近在看经典的卷积网络架构,打算自己尝试复现一下,在此系列文章中,会参考很多文章,有些已经忘记了出处,所以就不贴链接了,希望大家理解。
后期会补上使用数据训练的代码。
完整的代码在最后。
本系列必须的基础
python基础知识、CNN原理知识、pytorch基础知识
本系列的目的
一是帮助自己巩固知识点;
二是自己实现一次,可以发现很多之前的不足;
三是希望可以给大家一个参考。
目录结构
文章目录
-
- 基于pytorch复现ResNet
-
- 1. 残差模型介绍:
- 2. 各种ResNet介绍:
- 3. 模型构建:
- 4. 总结:
1. 残差模型介绍:
标准的结构为:
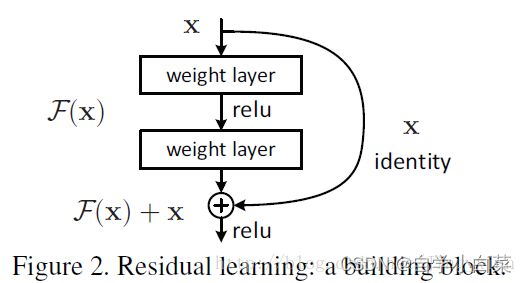
稍微修改一下:(引入了1*1卷积层,用于修改通道数)

2. 各种ResNet介绍:
图片来自网络:


注意,上面除去18、34外,其余的都是1*1-3*3-1*1的结构,并且第一层都是64个卷积核,第二层不变,第三层扩大四倍。
另外,18、34层的ResNet,第一个block块后的输出和第二个block的输入相同,因此不需要特别处理,但是对于50、101、152层的就需要特别处理,后面可以看代码注释。
3. 模型构建:
参考文献:
官方代码
https://blog.csdn.net/weixin_43940163/article/details/103760294 https://blog.csdn.net/x1027105273/article/details/123466082?spm=1001.2101.3001.6650.12&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-12-123466082-blog-103760294.pc_relevant_recovery_v2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-12-123466082-blog-103760294.pc_relevant_recovery_v2&utm_relevant_index=13
首先,还是构建block块:
# 创建block块
class My_Res_Block(nn.Module):
def __init__(self,in_planes,out_planes,stride=1,downsample=None):
'''
:param in_planes: 输入通道数
:param out_planes: 输出通道数
:param stride: 步长,默认为1
:param downsample: 是否下采样,主要是为了res+x中两者大小一样,可以正常相加
'''
super(My_Res_Block, self).__init__()
self.model = nn.Sequential(
# 第一层是1*1卷积层:只改变通道数,不改变大小
nn.Conv2d(in_planes,out_planes,kernel_size=1,stride=1),
nn.BatchNorm2d(out_planes),
nn.ReLU(),
# 第二层为3*3卷积层,根据上图的介绍,可以看出输入和输出通道数是相同的
nn.Conv2d(out_planes,out_planes,kernel_size=3,stride=stride,padding=1),
nn.BatchNorm2d(out_planes),
nn.ReLU(),
# 第三层1*1卷积层,输出通道数扩大四倍(上图中由64->256)
nn.Conv2d(out_planes,out_planes*4,kernel_size=1,stride=1),
nn.BatchNorm2d(out_planes*4),
nn.ReLU(),
)
self.relu = nn.ReLU()
self.downsample = downsample
def forward(self,x):
res = x
result = self.model(x)
# 是否需要下采样来保证res与result可以正常相加
if self.downsample is not None:
res = self.downsample(x)
# 残差相加
result += res
# 最后还有一步relu
result = self.relu(result)
return result
接着,来实现ResNet模型:
# 创建ResNet模型
class My_ResNet(nn.Module):
def __init__(self,layers=50,num_classes=1000,in_planes=64):
'''
:param layers: 我们ResNet的层数,比如常见的50、101等
:param num_classes: 最后输出的类别数,就是softmax层的输出数目
:param in_planes: 我们的block第一个卷积层使用的通道个数
'''
super(My_ResNet, self).__init__()
# 定义一个字典,来存储不同resnet对应的block的个数
# 在官方实现中,使用另外一个参数来接收,这里参考博客,采用一个字典来接收,都类似
self.layers_dict = {
50: [3,4,6,3],
101: [3,4,23,3],
}
self.in_planes = in_planes
# 最开始的一层,还没有进入block
# 输入彩色,通道为3;输出为指定的
self.conv1 = nn.Conv2d(3,self.in_planes,kernel_size=7,stride=2,padding=3)
self.bn1 = nn.BatchNorm2d(self.in_planes)
self.relu = nn.ReLU()
# 根据网络结构要求,大小变为一半
self.maxPool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
# 进入block层
self.block1 = self.make_layers(self.layers_dic[layers][0], stride=1, planes=64)
self.block2 = self.make_layers(self.layers_dic[layers][1], stride=2, planes=128)
self.block3 = self.make_layers(self.layers_dic[layers][2], stride=2, planes=256)
self.block4 = self.make_layers(self.layers_dic[layers][1], stride=2, planes=512)
# 要经历一个平均池化层
self.avgpool = nn.AvgPool2d(7, stride=1)
# 最后接上一个全连接输出层
self.fc = nn.Linear(512 * 4, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_x', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self,layers,stride,planes):
'''
:param planes: 最开始卷积核使用的通道数
:param stride: 步长
:param layers:该层bloack有多少个重复的
:return:
'''
downsample = None
# 判断是否需要下采样
if stride != 1 or self.inplanes != planes*4 :
downsample = nn.Sequential(
nn.Conv2d(self.in_planes, planes * 4, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * 4),
)
layers = []
# 创建第一个block,第一个参数为输入的通道数,第二个参数为第一个卷积核的通道数
layers.append(My_Res_Block(self.in_planes, planes, stride, downsample))
# 输出扩大4倍
self.in_planes = self.in_planes * 4
# 对于18,34层的网络,经过第一个残差块后,输出的特征矩阵通道数与第一层的卷积层个数一样
# 对于50,101,152层的网络,经过第一个残差块后,输出的特征矩阵通道数时第一个卷积层的4倍,因此要将后续残差块的输入特征矩阵通道数调整过来
for i in range(1, layers):
# 输入*4,输出变为最初的
layers.append(My_Res_Block(self.in_planes, planes))
return nn.Sequential(*layers) # 将列表解码
def forward(self,x):
# conv1
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# conv2_x
x = self.maxPool(x)
x = self.block1(x)
# conv3_x
x = self.block2(x)
# conv4_x
x = self.block3(x)
# conv5_x
x = self.block4(x)
# average pool and fc
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
4. 总结:
相比于之前实现的网络,ResNet模型还是比较复杂的,因此写起来也是有点困难,外加官方的代码注释不详细,所以参考了很多的文章。有所借鉴。
完整代码:
# author: baiCai
# 导包
import torch
from torch import nn
from torchvision.models import ResNet
# 创建block块
class My_Res_Block(nn.Module):
def __init__(self,in_planes,out_planes,stride=1,downsample=None):
'''
:param in_planes: 输入通道数
:param out_planes: 输出通道数
:param stride: 步长,默认为1
:param downsample: 是否下采样,主要是为了res+x中两者大小一样,可以正常相加
'''
super(My_Res_Block, self).__init__()
self.model = nn.Sequential(
# 第一层是1*1卷积层:只改变通道数,不改变大小
nn.Conv2d(in_planes,out_planes,kernel_size=1,stride=1),
nn.BatchNorm2d(out_planes),
nn.ReLU(),
# 第二层为3*3卷积层,根据上图的介绍,可以看出输入和输出通道数是相同的
nn.Conv2d(out_planes,out_planes,kernel_size=3,stride=stride,padding=1),
nn.BatchNorm2d(out_planes),
nn.ReLU(),
# 第三层1*1卷积层,输出通道数扩大四倍(上图中由64->256)
nn.Conv2d(out_planes,out_planes*4,kernel_size=1,stride=1),
nn.BatchNorm2d(out_planes*4),
nn.ReLU(),
)
self.relu = nn.ReLU()
self.downsample = downsample
def forward(self,x):
res = x
result = self.model(x)
# 是否需要下采样来保证res与result可以正常相加
if self.downsample is not None:
res = self.downsample(x)
# 残差相加
result += res
# 最后还有一步relu
result = self.relu(result)
return result
# 创建ResNet模型
class My_ResNet(nn.Module):
def __init__(self,layers=50,num_classes=1000,in_planes=64):
'''
:param layers: 我们ResNet的层数,比如常见的50、101等
:param num_classes: 最后输出的类别数,就是softmax层的输出数目
:param in_planes: 我们的block第一个卷积层使用的通道个数
'''
super(My_ResNet, self).__init__()
# 定义一个字典,来存储不同resnet对应的block的个数
# 在官方实现中,使用另外一个参数来接收,这里参考博客,采用一个字典来接收,都类似
self.layers_dict = {
50: [3,4,6,3],
101: [3,4,23,3],
}
self.in_planes = in_planes
# 最开始的一层,还没有进入block
# 输入彩色,通道为3;输出为指定的
self.conv1 = nn.Conv2d(3,self.in_planes,kernel_size=7,stride=2,padding=3)
self.bn1 = nn.BatchNorm2d(self.in_planes)
self.relu = nn.ReLU()
# 根据网络结构要求,大小变为一半
self.maxPool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
# 进入block层
self.block1 = self.make_layers(self.layers_dic[layers][0], stride=1, planes=64)
self.block2 = self.make_layers(self.layers_dic[layers][1], stride=2, planes=128)
self.block3 = self.make_layers(self.layers_dic[layers][2], stride=2, planes=256)
self.block4 = self.make_layers(self.layers_dic[layers][1], stride=2, planes=512)
# 要经历一个平均池化层
self.avgpool = nn.AvgPool2d(7, stride=1)
# 最后接上一个全连接输出层
self.fc = nn.Linear(512 * 4, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_x', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self,layers,stride,planes):
'''
:param planes: 最开始卷积核使用的通道数
:param stride: 步长
:param layers:该层bloack有多少个重复的
:return:
'''
downsample = None
# 判断是否需要下采样
if stride != 1 or self.inplanes != planes*4 :
downsample = nn.Sequential(
nn.Conv2d(self.in_planes, planes * 4, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * 4),
)
layers = []
# 创建第一个block,第一个参数为输入的通道数,第二个参数为第一个卷积核的通道数
layers.append(My_Res_Block(self.in_planes, planes, stride, downsample))
# 输出扩大4倍
self.in_planes = self.in_planes * 4
# 对于18,34层的网络,经过第一个残差块后,输出的特征矩阵通道数与第一层的卷积层个数一样
# 对于50,101,152层的网络,经过第一个残差块后,输出的特征矩阵通道数时第一个卷积层的4倍,因此要将后续残差块的输入特征矩阵通道数调整过来
for i in range(1, layers):
# 输入*4,输出变为最初的
layers.append(My_Res_Block(self.in_planes, planes))
return nn.Sequential(*layers) # 将列表解码
def forward(self,x):
# conv1
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# conv2_x
x = self.maxPool(x)
x = self.block1(x)
# conv3_x
x = self.block2(x)
# conv4_x
x = self.block3(x)
# conv5_x
x = self.block4(x)
# average pool and fc
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
'''
参考文章:
https://blog.csdn.net/x1027105273/article/details/123466082?spm=1001.2101.3001.6650.12&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-12-123466082-blog-103760294.pc_relevant_recovery_v2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-12-123466082-blog-103760294.pc_relevant_recovery_v2&utm_relevant_index=13
https://blog.csdn.net/weixin_43940163/article/details/103760294
'''