利用Logistic函数和LSTM分析疫情数据
利用Logistic函数和LSTM分析疫情数据
作者:林泽龙 Mo
1. 背景
2019 新型冠状病毒 (SARS-CoV-2),曾用名 2019-nCoV,通用简称新冠病毒,是一种具有包膜的正链单股 RNA 冠状病毒,为 2019 年底出现的新型冠状病毒感染的肺炎疫情的病原。在疫情爆发期间,研究人员对肺炎阳性患者样本进行核酸检测以及基因组测序后发现了这一病毒。
如今疫情成了人们最为关心的话题,通过各方的努力疫情也得到了相应的控制,对于疫情的预测许多专业的人士也有不同看法,本文就基于两个简单的模型来预测和分析疫情的数据,当然结果也仅供参考。
2. 数据采集
本文数据包含新型冠状病毒肺炎疫情数据和2003年中国非典疫情数据,其中新型冠状病毒数据主要来自国家卫健委官网和其他各大门户网站,非典数据主要来自世界卫生组织。其中新型冠状病毒数据主要用逻辑回归函数来拟合,非典数据主要用来训练LSTM模型,然后基于该模型来分析新型冠状病毒数据。
3. 利用 Logistic 函数拟合曲线
Logistic函数或Logistic曲线是一种常见的S形函数,它是皮埃尔·弗朗索瓦·韦吕勒在1844或1845年在研究它与人口增长的关系时命名的。该模型广泛应用于生物繁殖和生长过程、人口增长过程模拟。该函数公式如下,
P ( t ) = K P 0 e r t K + ( P 0 e r t − 1 ) P(t)=\frac{KP_0e^rt}{K+(P_0e^rt-1)} P(t)=K+(P0ert−1)KP0ert
其中为 P 0 P_0 P0初始值, K K K为终值, r r r衡量曲线变化快慢, t t t为时间。
接下去就是要用已有的数据,拟合出上述方程得出最优参数。我们的数据格式如下,统计时间从1月10至2月14日。我们主要去拟合全国确诊人数。
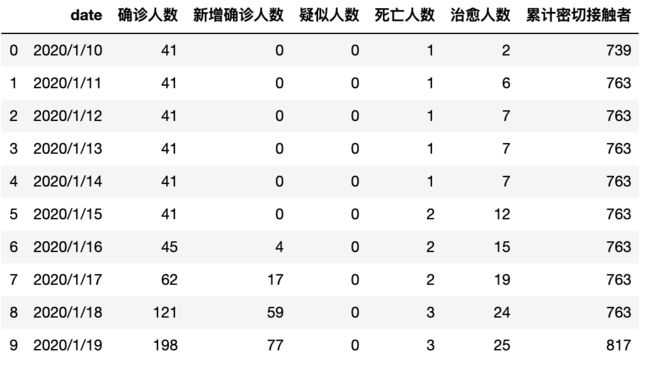
图1:最新疫情数据格式
我们的代码是设定该函数后利用最小二乘法去拟合数据。代码如下:
def logistic_increase_function(t,K,P0,r):
t0=1
r=0.2
# r值越大,模型越快收敛到K,r值越小,越慢收敛到K
exp_value=np.exp(r*(t-t0))
return (K*exp_value*P0)/(K+(exp_value-1)*P0)
# 用最小二乘法估计拟合 参数t为时间 P为对应时间的确诊人数
popt, pcov = curve_fit(logistic_increase_function, t, P)
#popt里面是拟合后的最优参数系数
print("K:",popt[0],"P0:",popt[1],"r:",popt[2])
最终拟合后的预测函数和以往数据的对比图如下:
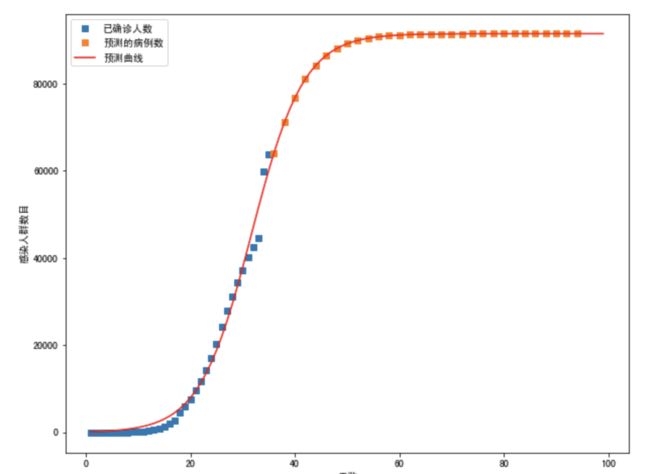
图2:逻辑增长函数拟合后的结果
如果有兴趣可以通过最下方的项目地址查看最新数据和全部代码。
4. 利用LSTM模型预测感染人数
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,LSTM 神经元可以存储时序信息,来解决上下文和时间问题,且没有影响其性能的消失梯度问题。通俗来讲,如果一个比较好的 LSTM 模型,我们就可以利用昨天和今天的数据来准确的预测明天的数据。关于 LSTM 的介绍在往期的文章中有过介绍,这里就不再赘述了,有兴趣的可以点击LSTM股票市场预测入门查看。
由于利用神经网络训练需要大量的数据,而新型冠状病毒的数据量目前较少,所以选择了数据稍微多些的2003年非典数据,数据是从2003年3月17日至2003年7月11日的感染人数和死亡人数的数据,数据格式如下。
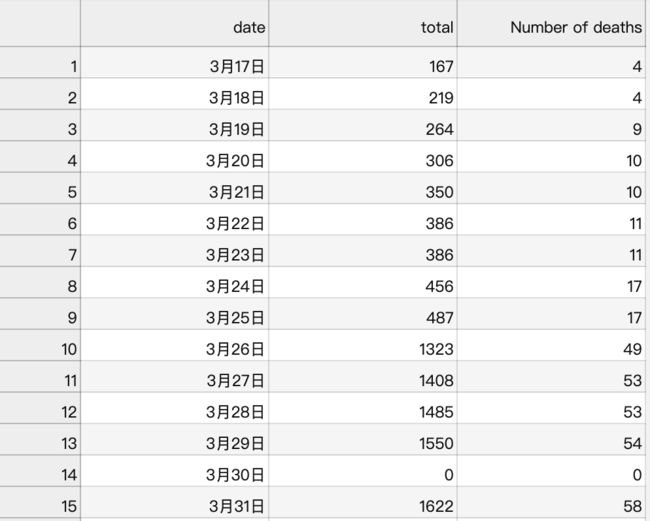
图3:非典数据格式
4.1数据预处理
由于数据并不连续,所以我们将中间缺失的数据进行处理,主要方法是取前一天的数据和之后第一天未缺失的数据相加的平均值作为缺失数据的值。代码如下:
dataframe = pd.read_csv('SARS.csv',usecols=[1])
for i in range(dataframe['total'].shape[0]):
if dataframe['total'][i] == 0:
j=i+1
while(dataframe['total'][j]==0):
j+=1
dataframe['total'][i]=(dataframe['total'][i-1]+dataframe['total'][j])//2
4.2归一化处理
归一化可以使模型训练更快和取得更好的结果,所以我们也可以利用起来。
#归一化
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
4.2数据处理
由于数据较少,我们取得时间步长为2,即是用近两天的结果预测第三天的结果。代码如下:
def create_dataset(dataset, timestep ):
dataX, dataY = [], []
for i in range(len(dataset)-timestep -1):
a = dataset[i:(i+timestep )]
dataX.append(a)
dataY.append(dataset[i + timestep ])
return np.array(dataX),np.array(dataY)
#训练数据太少 timestep 取2
timestep = 1
trainX,trainY = create_dataset(dataset,timestep )
4.3网络构建
我们的数据十分的简单,因此也不需要复杂的网络,代码主要用了 keras 框架。
model = Sequential()
model.add(LSTM(4, input_shape=(None,1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
model.save("LSTM.h5")
4.4最终结果
下面两图展现了非典数据训练的结果和模型预测新型冠状病毒的对比。可以发现 LSTM 可以大概的预测后一天的病情发展,但由于2月12日湖北地区确诊方式改变导致了人数暴增,不过现在病情已经趋于稳定。希望人们生活可以早日恢复正常,患者早日康复。项目地址:https://momodel.cn/workspace/5e44fecd6f6696a6d279f612?type=app
以下为实际的训练结果
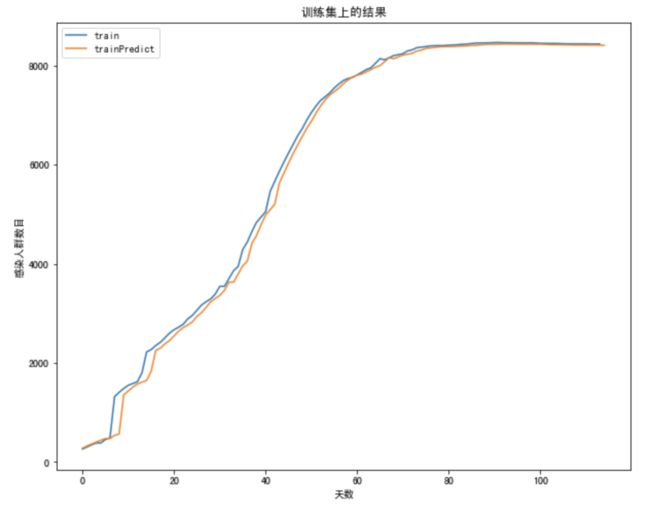
图4:模型在训练集上的结果
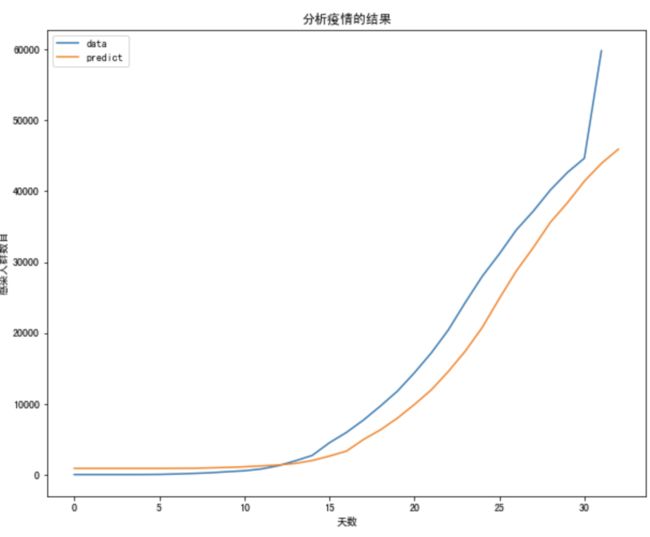
图5:利用模型分析预测新型冠状病毒曲线
五.参考资料
1.使用Logistic 增长模型拟合2019-nCov肺炎感染确诊人数
2. LSTM股票市场预测入门
3.利用 LSTM 进行家庭用户用电预测
关于我们
Mo(网址:https://momodel.cn)是一个支持 Python 的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
Mo 人工智能俱乐部 是由人工智能在线建模平台(网址:https://momodel.cn)的研发与产品团队发起、致力于降低人工智能开发与使用门槛的俱乐部。团队具备大数据处理分析、可视化与数据建模经验,已承担多领域智能项目,具备从底层到前端的全线设计开发能力。主要研究方向为大数据管理分析与人工智能技术,并以此来促进数据驱动的科学研究。
近期 Mo 也在持续进行机器学习相关的入门课程和论文分享活动,欢迎大家关注我们的公众号:MomodelAI获取最新资讯!