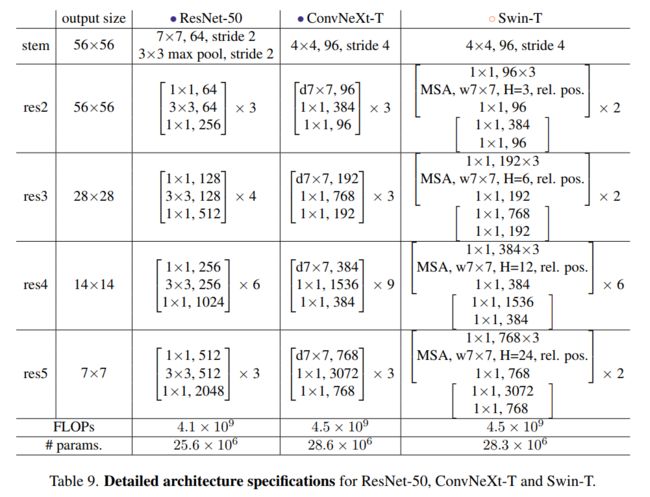
ConvNeXt:A ConvNet for the 2020s——模型简述
一、摘要

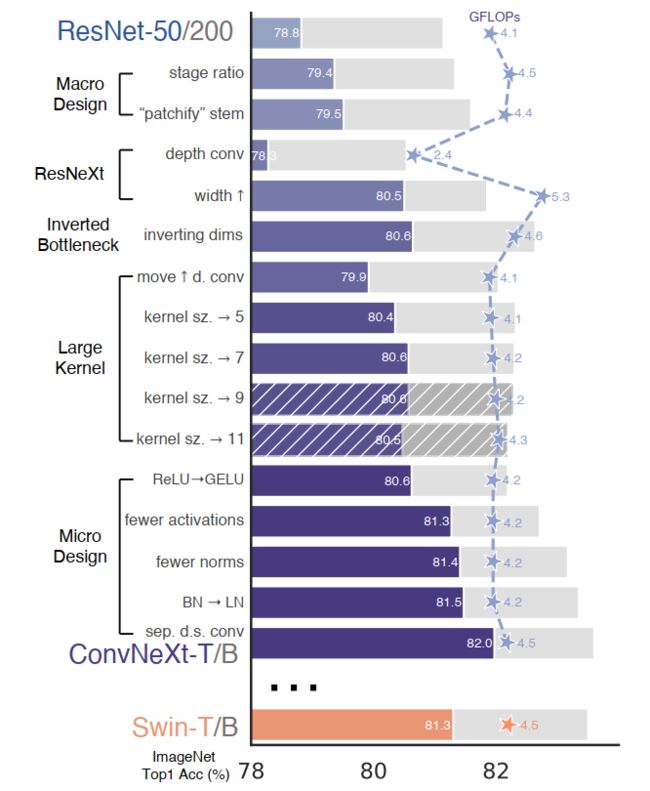
这篇论文对标去年的best paper:Swin Transformer,在相同的flops下具有更高的准确率和推理速度,它从各个方面借鉴了Swin的设计模式和训练技巧(如AdamW优化器),并一步步的将Swin的策略纳入到resnet的设计中,下图清晰地给出了模型上的一步步改动所引发的准确度的变化:
二、模型设计
针对如上的路线图简要说明一下设计思路。
2.1 stage ratio
VGG提出了把骨干网络分成若干个网络块的结构,每个网络块通过池化操作将feature map下采样到不同的尺寸。当深层的网络块层数更多时,模型的表现更好。resnet50有4个不同的网络块,堆叠的次数分别是(3,4,6,3),而在Swin-T中是(2,2,6,2),比例是1:1:3:1,作者就将这个比例用在resnet上,每个stage堆叠block的次数分别是(3,3,9,3)。
2.2 patchify stem
在Swin中是先对224尺寸的图片下采样4倍,采用的是k4s4的卷积核,同样作者将这部分替换resnet中的stem:
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
其中dims[0] = 96,和Swin一样的输出维度。[2.4]
2.3 patchify stem
ResNeXt中采用了分组卷积,将通道分组,然后以组为单位进行卷积,与ResNet相比在FLOPs以及准确度之间做到了更好的平衡。
作者采用的是depthwise convolution,它是分组卷积的一种特殊形式,即group数和channel数相同,在DwConv中,每个卷积核的channel都是等于1的,每个卷积核只负责输入特征矩阵的一个channel,故卷积核的个数必须等于输入特征矩阵的channel数,从而使得输出特征矩阵的channel数也等于输入特征矩阵的channel数。
这是因为depthwise convolution和自注意力中的加权求和操作很相似。
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
2.4 width ↑
作者将最初的通道数由64调整成96和Swin一致,准确率达到了80.5%。
2.5 inverting dims

在残差网络中,瓶颈层是中间小,两头大的结构,在MobileNetV2中采用了逆瓶颈层的结构(b),这能够减少信息的流失。
同样在Swin中的mlp层也有类似的结构,所以作者也放进了ConvNeXt中。
为了探索更大的卷积核(7x7),作者将DwConv层上移,因为在transformer中,MSA模块是放在MLP模块之前的。
2.6 Large Kernel
目前主流的做法是堆叠小卷积核替代大卷积核(像VGG),在现代gpu上有高效的硬件实现方式。
作者尝试了不同尺寸的DwConv卷积核大小,包括3, 5, 7, 9, 11,发现取到7时准确率就达到了饱和,和Swin一致。
2.7 Micro Design
(1)将激活函数ReLu替换成了GELU;
(2)使用更少的激活函数;
(3)使用更少的normalization;
(4)将BN(Batch Normalization)替换为LN(Layer Normalization)(重写);
class LayerNorm(nn.Module):
r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
(5)拆分下采样层
在resnet中,它通常使用的是主分支k3s2卷积、identity分支k1s2卷积来进行下采样。
在Swin Transformer中将下采样层从其它运算中剥离开来,即使用一个k2s2的卷积插入到不同的stage之间。
ConvNeXt也是采用了这个策略,研究显示在改变分辨率的地方添加归一化层,可以帮助稳定训练,同时也在下采样前、stem后、全局均值池化后分别加入了LN。
对比如下:
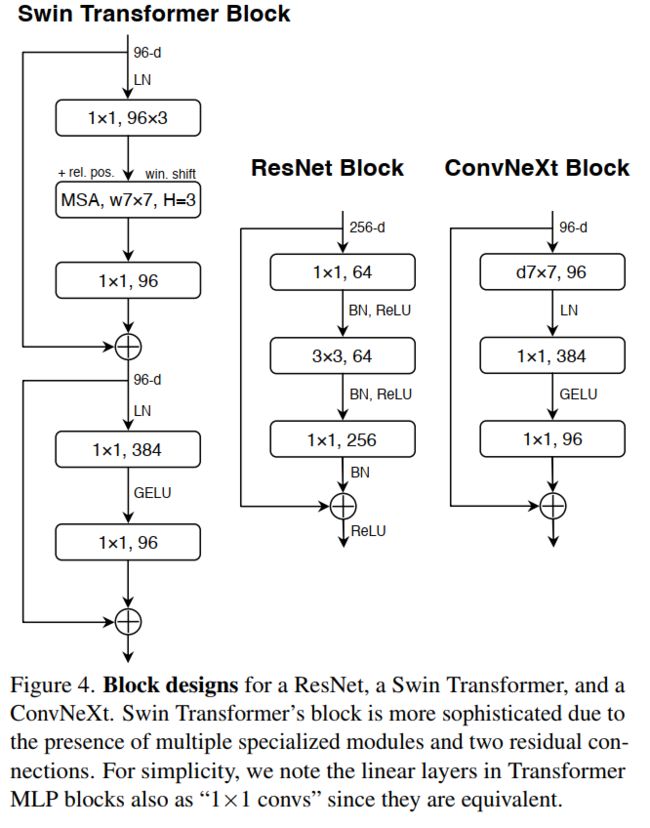
block实现代码:
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
三、总结
作者除了以上技巧还用了其他的一些方法,具体可见官方仓库代码。
如下是完整的结构对比图,省略了LN和下采样等操作: