(python)爬虫----八个项目带你进入爬虫的世界
目录
(一)入门--豆瓣
一、学前要求知识
二、目标
三、什么是爬虫
四、爬取网页
五、解析网页
六、翻页
八、代码
(二)你的心,我懂得~~--彼岸图网
一、目标
二、爬取网页
三、保存图片
四、代码
(三)视频--虎牙小姐姐跳舞视频
一、目标
二、获取详情页链接
三、获取视频地址
四、保存数据
五、完整代码
(四)登录--CSDN
一、目标
二、如何登录
三、传参链接
四、代码构建
五、完整代码
(五)、模拟人操作浏览器(selenium)
一、引子
二、selenium下载
三、selenium+python
四、代码
五、后记
(六)爬虫框架--scrapy的使用(汽车之家)
一、为什么要使用scrapy
二、scrapy框架整体架构
三、scrapy下载
四、创建scrapy项目
五、创建爬虫文件
六、爬取汽车之家
(七)爬虫注意事项
一、Robots协议
二、遵守Robots协议也有可能犯法
(八)反爬与反反爬
反爬手段与处理措施
headers字段限制和POST、GET请求参数限制
IP限制
JS加密
等
后续
(一)入门--豆瓣
一、学前要求知识
- python基础
- 前端基础
二、目标
要爬的网站是豆瓣电影 Top 250 (douban.com)
需要爬到每个电影的排名、名字、以及评分。

这是不少人踏上爬虫之路的第一个网站,现在让我们来迈出爬虫的第一步吧!
三、什么是爬虫
简单来说:爬虫就是用机器来模拟人浏览网页的过程。
四、爬取网页
使用python来爬虫,需要借助一个库,这个库不是python自带的,所以需要下载,下载方式就跟正常下载库的方法一样。
![]()
导入该库,就不在话下了吧!
在正式爬取网页前,我们需要了解,平时我们浏览网页的过程实际上就是向浏览器发起请求的过程。而请求又分很多种,最常见的为GET和POST请求,在这里我们暂时不解释GET和POST的区别。
我们要爬取豆瓣250时,当然也要知道豆瓣250的请求方式,我们用浏览器进入豆瓣250,然后按F12或者点击鼠标右键进入开发者模式,然后点击上方的网络,或者是英文 Network。
![]()
然后刷新页面,发现突然出现了一大堆,不要慌,这个就是我们在发送请求时,服务器和客户端进行网络传输发送与接收的数据包,随便点击一个,出现一个框框,然后点击框框上方的预览或者英文Preview,会大致明白这个数据包传输的是什么数据。

最终找到了传输的数据对我们有用的数据包,再点回标头或者英文Headers,会在常规内看见请求方式的字样,后面跟着的就是该数据包的请求方式,豆瓣250的请求方式则是GET。等等先不要关闭开发者模式,我们再往下看还有一个请求标头,那这是什么啊?这个对于爬虫来讲是一层障碍,因为有些网站它会检查请求头,以此来判断是爬虫还是正常访问。在爬取网页时,一般都要加一个user-agent,以防网页有轻微的反爬操作,就导致该爬虫不能使用了。接着再点击响应或者英文Response,这就是服务器发送数据,即响应正文。那么进行爬虫的前期准备就完成了。(通常你对哪个链接发送的请求,请求信息就在哪个数据包内)
import requests
url = f'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
}
html = requests.get(url, headers=headers)
web_page = html.text因为是GET请求,所以要用requests的get方法。打印html,会发现它是Response对象,它有一个text方法,会获取该请求的数据信息,我们打印web_page,发现打印的结果是html源码也就是该数据包的响应正文。那么我们也完成了一次爬取。但是爬取出来的数据好像用处不大,这样的数据还不如正常访问网站的用处大,那么爬虫的用处也完全没有嘛。但是,爬虫还有一个重要的环节,那就是清洗数据,一个网页上的数据肯定是有一点对我们有用,大部分对我们用处不大,所以需要将有用的数据清洗出来。
五、解析网页
下面要清洗网页上的数据,这一过程叫网页解析。
解析网页一般有两种方法:
- 正则匹配(也就是python中re库)正则表达式,re,Python,正则表达式实例;
- Xpath。
今天我使用xpath来解析网页。
在python中使用xpath,需要下载lxml解析库。
pip install lxml使用前需要先将html源码实例化成etree对象。
from lxml import etree
movie = etree.HTML(web_page)接着使用etree对象的xpath属性,然后写入要匹配的路径即可。(成块爬取,将一个电影的所有信息先爬下来,然后在爬需要的信息,这样爬取的信息才一定会匹配。)
movies = middle.xpath('//*[@class="item"]')
for movie in movies:
rank = movie.xpath('.//em/text()')[0]
title = movie.xpath('.//span[1]/text()')[0]
score = movie.xpath('.//*[@class="rating_num"]/text()')[0]
print(f'排名:{rank},电影名:{title},评分:{score}')这样就完成数据的清洗。
六、翻页
聪明的你肯定发现我们只爬到了一页数据。
那么怎么爬取豆瓣250的所有数据呢,我们先不着急写代码,先翻在浏览器上翻上几页观察url(网址)的变化,发现url后面的start,每次都加25。你是不是想到了怎么爬取所有的数据,等等先不要着急,再试下第一页是否符合该规律,因为有些网址的第一页会与后面的没有规律,当然豆瓣250是符合规律的。
八、代码
import requests
from lxml import etree
total_page = 10
for page in range(0, total_page * 25, 25):
url = f'https://movie.douban.com/top250?start={page}&filter='
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
}
html = requests.get(url, headers=headers)
web_page = html.text
middle = etree.HTML(web_page)
movies = middle.xpath('//*[@class="item"]')
for movie in movies:
rank = movie.xpath('.//em/text()')[0]
title = movie.xpath('.//span[1]/text()')[0]
score = movie.xpath('.//*[@class="rating_num"]/text()')[0]
print(f'排名:{rank},电影名:{title},评分:{score}')(二)你的心,我懂得~~--彼岸图网
一、目标
要爬的网站是4K美女壁纸_高清4K美女图片_彼岸图网 (netbian.com)
需要爬到每个美女图片,并将其保存下来。
二、爬取网页
可以快速得知这个网页是get请求,于是有了以下代码:
import requests
url = 'https://pic.netbian.com/4kmeinv/'
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
}
html = requests.get(url, headers=headers)
web_page = html.text打印web_page,发现打印内容是乱码。在以下的这个位置一般都会有这个网站的编码格式

web_page = html.text.encode('iso-8859-1').decode('gbk')(前面的编码形式encode是哪个编码格式是我试出来的,一般都是utf-8。至于为什么这个是iso-8859-1,从网上搜索的答案是ISO-8859-1 是大多数浏览器默认的字符集)
这样输出的就是正常的html源码啦
由于在列表页的图片不清晰,所以需要进入详情页下载图片,发现详情页链接都在li下,但是抓取到的li中的链接只有一半,需要加上所缺失的。再浏览器中进入详情页分析缺失那一部分,多分析几个,就会发现它们缺失的是什么啦。
仔细观察网页会发现有一个特殊的图片,它不是我们想要的小姐姐,但是打印出html源码会发现它并没有出现在源码中。但是如果它出现在源码中,可以利用它多个class属性进行排除。

lis = web_html.xpath('//*[@class="slist"]//li')
base_url = 'https://pic.netbian.com'
for li in lis:
original_url = base_url + li.xpath('.//a/@href')[0]
li_class = li.xpath('./@class')
有了详情页的url后,自然是再发送一次请求进入详情页,取到图片啦~~(记得图片名也要取到哦,取图片名字是为了作为存储得文件名。同样这里的图片链接也不全,需要自己补充)
original_html = requests.get(original_url, headers=headers)
original_page = original_html.text.encode('iso-8859-1').decode('gbk')
original_page = etree.HTML(original_page)
img_name = original_page.xpath('//*[@id="img"]/img/@title')[0]
img_path = 'https://pic.netbian.com/'\
+ original_page.xpath('//*[@id="img"]/img/@src')[0](点击下载原图需要登录,所以这里是直接爬取的图片)
三、保存图片
首先在与爬虫文件同一级处创建一个文件夹用来保存小姐姐。

下载文档(图片是文档的一种):其实也就是向文件中写入数据
读写文件是爬虫经常使用的操作。
知识补充:IO操作:读写文件是最常见的IO操作。IO操作还包括访问网络,等待用户输入数据。IO操作相对于内存计算来说是比较慢的。
python的读写操作,相信大家了解(不了解的可以先补充下)
在这里呢,不推荐使用
f = open('abc1.txt', 'w')
f.write('123')
# 此处可能有很多其他写入操作
f.write('456')
f.close()最好使用(原因,有兴趣的可以搜索了解一下)
with open('./保存路径', 'wb') as f: # wb是以二进制写入内容
f.write('123')保存图片等数据时,都是保存的二进制,读时电脑会根据后缀来处理。因为这个网站图片的后缀都是jpg,所以我们就直接写上。(学过正则得可以使用正则匹配后缀,以防有特殊的)
img_html = requests.get(url=img_path, headers=headers)
img = img_html.content # 这里要用content,不能用text,因为它是二进制的
with open(f'./美女图片/{img_name}.jpg', 'wb') as f:
f.write(img)
这样就完成了一页的存储。要爬取所有页的图片,同样对每页的url进行分析。发现除第一页外,剩余的页数链接都是:https://pic.netbian.com/4kmeinv/index_{页数}.html。只需要将第一页特殊处理一下。
all_page = 145 # 总页数
for page in range(1, all_page + 1):
if page == 1:
url = 'https://pic.netbian.com/4kmeinv/index.html'
else:
url = f'https://pic.netbian.com/4kmeinv/index_{page}.html'四、代码
最后将代码模块化,整理一下。
from lxml import etree
import requests
import time
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
}
# 得到详细链接
def get_original_url(url):
html = requests.get(url, headers=headers)
web_page = html.text.encode('iso-8859-1').decode('gbk')
web_html = etree.HTML(web_page)
lis = web_html.xpath('//*[@class="slist"]//li')
return lis
# 得到图片
def get_img(original_url):
original_html = requests.get(original_url, headers=headers)
original_page = original_html.text.encode('iso-8859-1').decode('gbk')
original_page = etree.HTML(original_page)
img_name = original_page.xpath('//*[@id="img"]/img/@title')[0]
img_path = 'https://pic.netbian.com/' \
+ original_page.xpath('//*[@id="img"]/img/@src')[0]
img_html = requests.get(url=img_path, headers=headers)
img = img_html.content
return img, img_name
# 下载图片
def download_img(img, img_name):
with open(f'./美女图片/{img_name}.jpg', 'wb') as f:
f.write(img)
if __name__ == '__main__': # 这样可以显得自己是一个高手,嗯~
all_page = 3 # 总页数
for page in range(1, all_page + 1):
# time.sleep(1) 如果爬取中,发现需要输入验证码、不能爬取,加上这个。
if page == 1:
url = 'https://pic.netbian.com/4kmeinv/index.html'
else:
url = f'https://pic.netbian.com/4kmeinv/index_{page}.html'
lis = get_original_url(url)
for li in lis:
original_url = 'https://pic.netbian.com' + li.xpath('.//a/@href')[0]
img, img_name = get_img(original_url)
download_img(img, img_name)
(三)视频--虎牙小姐姐跳舞视频
一、目标
目标网站:跳舞视频_跳舞教学|比赛|搞笑|直播视频中心_虎牙视频 (huya.com)
目标:爬取每个小姐姐跳舞的视频,并将其保存。

二、获取详情页链接
对于视频的获取,同图片获取相同。我们需要进入详情页获取视频的地址。
通过分析网页的源代码,可以发现,每个视频的详情页地址都在li标签下。

通过requests库来获取网页的源代码,并通过解析网页的源代码来获取得到当前页面中所有详情页的链接地址。
all_page = 1 # 500
for page in range(1, all_page+1):
url = f'https://v.huya.com/g/Dance?set_id=31&order=hot&page={page}'
html = requests.get(url, headers=headers)
web_page = html.text
web_html = etree.HTML(web_page)
lis = web_html.xpath('//*[@class="vhy-video-list w215 clearfix"]//li')
for li in lis:
meta = {
'name': li.xpath('./a/@title')[0], # 也可以在详情页爬取
'url': 'https://v.huya.com/' + li.xpath('./a/@href')[0],
}
通过for循环,来构建所有的列表页链接,并爬取url。
三、获取视频地址
获取视频地址相较于详情页链接就比较难啦。
对源代码进行分析,可以知道视频地址在一个video标签下。

然后我们写出分析的xpath路径,却发现返回的是空列表。原来他是动态加载的,需要找到对应的请求接口链接。打开开发者模式,复制视频地址,在网络选项下通过快捷键ctrl+F来搜索”//huya-w20.huya.com/“,就可以找到对应的请求接口链接。

对视频的请求链接进行分析,去除一些不重要的参数,可以得到如下的链接‘https://liveapi.huya.com/moment/getMomentContent?&videoId=468682371’,每个视频videold的参数与详情页地址中的(如下)一一对应。

视频的请求链接所返回的是json数据内容,通过对json的分析就可以找到视频地址。 JSON在线解析及格式化验证 - JSON.cn
接下来我们编写程序来爬取视频地址。
get_video_url = 'https://liveapi.huya.com/moment/getMomentContent?videoId=' + meta['url'].replace('/play/',
'').replace(
'.html', '')
video_web_json = requests.get(get_video_url, headers=headers).json()
# 原画
video_url = video_web_json['data']['moment']['videoInfo']['definitions'][0]['url']四、保存数据
视频的保存方法与图片的一样,就不多bb了,直接放代码
video = requests.get(video_url, headers=headers).content
with open(f'./美女跳舞视频/{meta["name"]}.mp4', 'wb') as f:
f.write(video)五、完整代码
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
}
# 获取视频名和参数
def get_original():
apage_video = []
all_page = 1 # 500
for page in range(1, all_page + 1):
url = f'https://v.huya.com/g/Dance?set_id=31&order=hot&page={page}'
html = requests.get(url, headers=headers)
web_page = html.text
web_html = etree.HTML(web_page)
lis = web_html.xpath('//*[@class="vhy-video-list w215 clearfix"]//li')
for li in lis:
meta = {
'name': li.xpath('./a/@title')[0], # 也可以在详情页爬取
'url': li.xpath('./a/@href')[0],
}
apage_video.append(meta)
return apage_video
# 拼接视频地址并保存视频
def pdd_video_url(meta):
get_video_url = 'https://liveapi.huya.com/moment/getMomentContent?videoId=' + meta['url'].replace('/play/',
'').replace(
'.html', '')
video_web_json = requests.get(get_video_url, headers=headers).json()
# 原画
video_url = video_web_json['data']['moment']['videoInfo']['definitions'][0]['url']
video = requests.get(video_url, headers=headers).content
with open(f'./美女跳舞视频/{meta["name"]}.mp4', 'wb') as f:
f.write(video)
if __name__ == '__main__':
for meta in get_original():
pdd_video_url(meta)
(四)登录--CSDN
一、目标
目标网站:CSDN-专业IT技术社区-登录
目标:登录CSDN
二、如何登录
众所周知登录是需要账号和密码,然后服务器验证,验证通过后才是登录成功。那么我们是怎么样把账号密码传递给服务器的呢?
GET
GET传递参数是在请求链接后添加参数传递给服务器的。
格式:请求链接?&key=value&key1=value1...
POST
POST传递参数是建立一个表单,然后直接将表单传递给服务器。
GET参数在链接后,非常不安全,所以账号密码通常是通过POST请求传递到。
三、传参链接
可以先随便输入账号密码,然后打开开发者模式,选中网络,查询下账号密码在哪个请求下。
经分析发现,是在 'https://passport.csdn.net/v1/register/pc/login/doLogin' 链接的请求下。也就是说将账号密码发送给这个请求,就可以完成登录。
四、代码构建
import requests
url = 'https://passport.csdn.net/v1/register/pc/login/doLogin'
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
}
# 要传递的表单
data = {
}
# 因为是POST请求
login = requests.post(url, headers=headers, data=data)
print(login.text)那么表单内填写什么内容呢?我们可以看请求中将参数怎么处理的。

仿照请求,将参数写入表单。
data = {
'userIdentification': '账号',
'pwdOrVerifyCode': '密码'
}发起请求,会发现并没有登录,因为网站检查了请求头,请求头缺少一些内容。
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
'Cookie': '打开开发者模式,点击网络,在请求中查看自己的Cookie',
'Content-Type': 'text/plain'
}注意:cookie有时间限制,一定时间后需要滑块,证明自己不是爬虫。如果发现这种情况,到浏览器上手动验证即可。还是不行的话,换一个cookie。
再次发起请求

依然没有登陆成功,原来这个链接接收的是一个字符串,而且还缺失一个必要参数。
data = str({
'loginType': '1',
'userIdentification': '账号',
'pwdOrVerifyCode': '密码'
})![]()
返回这样的请求即成功登录。
那么上面需要的参数怎么找出来的,可以看 headers请求头问题 。
五、完整代码
import requests
url = 'https://passport.csdn.net/v1/register/pc/login/doLogin'
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
'Cookie': '打开开发者模式,点击网络,在请求中查看自己的Cookie',
'Content-Type': 'text/plain'
}
# 传递的表单
data = str({
'loginType': '1',
'userIdentification': '账号',
'pwdOrVerifyCode': '密码'
})
login = requests.post(url, headers=headers, data=data)
# 用于查看是否登录成功
print(login.text)(五)、模拟人操作浏览器(selenium)
一、引子
上个项目中滑块爬虫应该怎么处理呢?python代码是无法直接操作浏览器的,所以需要借助于其他工具来操作浏览器。selenium就是这样一个工具,它是一个浏览器驱动,不仅支持python、还支持其他编程语言。
二、selenium下载
请根据各自的浏览器下载selenium 驱动
- 谷歌浏览器:https://npm.taobao.org/mirrors/chromedriver/
- 微软Edge: https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
- 火狐:https://github.com/mozilla/geckodriver/releases
- Safari:https://webkit.org/blog/6900/webdriver-support-in-safari-10/
下载时要注意自己的浏览器版本,下载和浏览器版本最近的那个。
下载到哪个目录下都可以,但是最后都要把路径添加到环境变量Path中。不知道怎么设置path,请自行搜索。
如果你用其他浏览器,或者以上链接失效了,请自行搜索“selenium 驱动”查找下载地址。
三、selenium+python
在python中使用selenium需要安装selenium模块。

安装好后可尝试以下代码:正常情况会打开浏览器,显示百度页面
from selenium import webdriver
# driver = webdriver.对应的浏览器() 如Edge
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")如出错请检查以下几个点:
- selenium 驱动是否设置好了Path
- selenium 驱动和你的浏览器是否匹配
- 是否成功安装selenium模块
由于本人浏览器更新了,而selenium不经常使用导致selenium 驱动和浏览器不匹配,在这里也不编写项目啦(其实就是懒~~)
四、代码
这里放上以前写的代码,对代码稍作修改(改上自己用的浏览器),可体验下。
from selenium import webdriver
from lxml import etree
import time
# 准备工作
def open_Edge(url):
Edge = webdriver.Edge()
# 最大化浏览器
Edge.maximize_window()
# 打开浏览器
Edge.get(f'{url}')
for i in range(10):
Edge.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
return Edge
# 获取网页源码
def get_html(Edge):
time.sleep(1)
# 获取网页源码,与浏览网页时点击查看源码所看到的一样
html = Edge.page_source
return html
def get_book(html):
tree = etree.HTML(html)
book_as = tree.xpath("//div[@id='bookItem']/a")
for book_a in book_as:
# 获取书名
book_name = book_a.xpath("./div[2]/text()")
# 获取书的价格
book_price = book_a.xpath("./div[3]/div[1]/text()")
print("书名:{name},价格:{price}".format(name=book_name, price=book_price))
return 0
# 给网页翻页
def next_page(Edge):
# 找到下一页的按钮
next_page = Edge.find_element_by_xpath("//*[@id='entry']/div[2]/div[2]/div[2]/div/button[2]")
# 点击按钮
time.sleep(1)
next_page.click()
return '翻页完成'
def shut_Edge(Edge):
# 关闭浏览器
# 优雅的关闭
Edge.quit()
# 主流程
def run_project():
url = input('请输入一个url:')
# URL:https://www.epubit.com/books
Edge = open_Edge(url)
html = get_html(Edge)
get_book(html)
for i in range(0,10):
next_page(Edge)
html = get_html(Edge)
get_book(html)
shut_Edge(Edge)
if __name__ == '__main__':
run_project()
五、后记
用Selenium驱动真实的浏览器抓取数据,缺点是慢,占用资源多。毕竟它要模拟人操作浏览器,打开浏览器。为了解决这个问题,有一种浏览器叫无头浏览器(headless),没有界面,但是可以实现浏览器的功能。其中常用的一个无头浏览器叫做phantomJS,可自行了解。
selenium的功能非常强大,如果需要使用相应的功能,可自行百度。(如:怎么实现滑块验证selenium滑块验证 - 国内版 Bing)
(六)爬虫框架--scrapy的使用(汽车之家)
一、为什么要使用scrapy
使用request + selenium爬虫已经可以完成几乎所有爬虫项目了,那为什么还要学习scrapy呢?
主要为了方便多人开发时,使用的。
在实际开发中(抓取的网站可能成千上万,甚至更多。有些网站需要重复抓取更新数据)
- 有的人协调抓取的顺序,分配任务和资源,做并发处理;
- 有的人具体执行下载任务;
- 有的人负责处理和保存数据;
- 有的人负责处理代理IP,过滤数据;(代理IP主要是反爬的一种手段)
- 等;
scrapy帮我们设计好了程序的框架,做好了基础工作,比如具体下载我们不用管,多线程并发我们也不用管,我们只需要写各个组件里的具体业务代码就行了。这样也更容易管理项目。
二、scrapy框架整体架构

两幅图一样

三、scrapy下载
pip install scrapy四、创建scrapy项目
在使用scrapy爬取前,需要先创建一个scrapy项目。
scrapy startproject 项目名项目下面生成了哪些文件呢?
项目名/
scrapy.cfg # deloy configuration file
ershouche/ # project's Pyton module, you'll import your code from here
__init__.py
item.py # project items definition file
middleware.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project setting file
spider/ # a directory where you'll later put your spider
fengtian.py # spider file we just create it
__init__.py文件主要有:
-
items.py:用来存放爬虫获取的数据模型,也就是事先对数据结构进行定义;
-
middlewares.py:用来存放 middlewares 的文件,包括 Downloader middlewares 和 Spider middlewares;
-
pipelines.py:用来将 items.py 中的数据模型进行存储;
-
settings.py:爬虫的配置信息(delay,pipeline,headers等);
-
scrapy.cfg:项目配置文件;
-
spider 文件夹:爬虫文件夹。
这些文件现在不懂也没关系,后面慢慢学,最终你会理解它们各自的职责。
五、创建爬虫文件
在 spider 下可以手动建立自己的爬虫文件,但是 Scrapy 中也提供了相应的命令。
scrapy genspider 爬虫名 爬取网站爬取网站可以在项目中修改。
进入爬虫文件后,里面代码的功能:
# 导入scrapy模块
import scrapy
# 创建一个爬虫类,它继承了scrapy.Spider
class CarsSpider(scrapy.Spider):
# 爬虫的名称,就是我们前面定义的
name = 'cars'
# 爬虫允许进入的域,限定爬虫爬的范围
allowed_domains = ['www.che168.com']
# 启动爬虫的初始链接,就是爬虫的起点url
start_urls = ['http://www.che168.com/']
# 拿到起始url请求的响应(response)后,会传入parse函数(这个函数名称不要去改)
def parse(self, response):
# 在此处写爬取、解析网站的代码
pass六、爬取汽车之家
先放代码
import scrapy
import re
class FengtianSpider(scrapy.Spider):
name = 'fengtian'
allowed_domains = ['www.che168.com']
start_urls = ['https://www.che168.com/china/fengtian/#pvareaid=108402#listfilterstart']
def parse(self, response):
cars = response.xpath("//div[@id='goodStartSolrQuotePriceCore0']/ul/li[@name='lazyloadcpc']")
for car in cars:
# 取第一个extract_first()
car_name = car.xpath(".//a/div[@class='cards-bottom']/h4/text()").extract_first()
price = car.xpath(".//a/div[@class='cards-bottom']/div/span/em/text()").extract_first()
car_price = price + '万'
car_inf = car.xpath(".//a/div[@class='cards-bottom']/p/text()").extract_first()
# 正则
car_journey = ''.join(re.findall('.*万公里', car_inf))
car_buytime = ''.join(re.findall('\d{4}-\d{2}', car_inf))
car_city = ''.join(re.findall('.*万公里/.*/(.*)/', car_inf))
# 详情页
detail_path = car.xpath('./a/@href').extract_first()
detail_url = f'https://www.che168.com{detail_path}'
inf = {'型号': car_name, '里程数': car_journey, '所在地': car_city, '日期': car_buytime, '价格': car_price}
next_url = response.xpath('//*[@id="listpagination"]/a[@class="page-item-next"]/@href').extract_first()
if next_url:
full_nextlink = 'https://www.che168.com/' + next_url
# 相当与return callback回调到哪个函数
yield scrapy.Request(full_nextlink, callback=self.parse)
yield scrapy.Request(detail_url, callback=self.parse_detail_page, meta=inf)
def parse_detail_page(self, response):
seller_info = re.findall(
'(.*?)', response.text)[0]
seller_location = re.findall(
'(.*?)', response.text)[0]
inf = response.meta
print(f"{inf},商家/个人信息:{seller_info},商家/个人详细地址:{seller_location}")
这里重点提几点:
response:是Response对象;
yield :可以将它看作return,但是它可以循环;
callback:回调函数,将请求到的信息传给哪个函数;
meta:传递当前爬取到的页面信息(解析过的)。
运行爬虫:
输入命令scrapy crawl 爬虫名运行scrapy。
如果报403错误,可以打开setting,在相同的位置添加user_agent。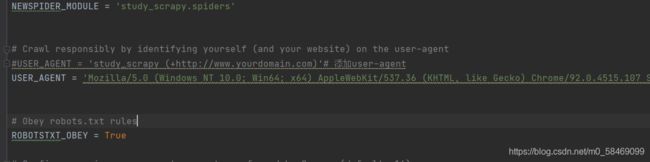
由于我写的爬虫是爬取网页上的全部页信息,所以有些请求返回了302,在浏览器中打开汽车之家,会发现需要验证。
这是因为汽车之家,采取了IP反爬。
网站运维人员在对日志进行分析时有时会发现同一时间段内某一个或某几个IP访问量特别大,由于爬虫是通过程序来自动化爬取页面信息的,因此其单位时间的请求量较大,且相邻请求时间间隔较为固定,这时就基本可以判断此类行为系爬虫所为,此时即可在服务器上对异常IP进行封锁。
面对这种情况,我们采取的措施:加上代理IP池。
这里就不展开说了,有兴趣的可先自行搜索。
(七)爬虫注意事项
一、Robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots ExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取.
也就是说Robots协议上会说明不可以爬取哪些页面。在使用scrapy爬取时,scrapy会首先爬取Robots页。一般该页在根目录下的robots.txt中,如百度:https://www.baidu.com/robots.txt
如果没有的话,就是允许爬取。
二、遵守Robots协议也有可能犯法
不一定说遵守Robots就一定没事,robots协议只是行业约定,并没有什么法规强制遵守。
平时爬取我们需要特别注意3个红线:
- 个人信息
- 商业秘密
- 国家秘密
当然爬取过程中以下2条也需要遵循
- 使用爬虫技术,使对方网站业务无法正常运行。
- 使用高并发请求,使对方服务器持续处于高压状态导致其宕机的。
不止这样,最后对爬取数据的使用也有可能犯法。
这里给大家一个政府通知作为参考:国家互联网信息办公室关于《数据安全管理办法(征求意见稿)》公开征求意见的通知-中共中央网络安全和信息化委员会办公室 (cac.gov.cn)
(八)反爬与反反爬
这里并没有讲什么处理反爬的措施,我就列一些常见反爬手段,就不细讲了。
反爬手段与处理措施
headers字段限制和POST、GET请求参数限制
处理措施:
加上需要的字段和参数
比较难的就是字段或者参数是JS文件动态生成的,这时候就需要我们查看JS源文件
IP限制
处理措施:
使用代理IP或者建立IP池
JS加密
处理措施:
这个主要就是记忆啦,比如:加密后数据最后有等号,就有可能是MD5加密
然后在JS源码中搜索关键字样,查看加密过程,之后使用python复原。
等
爬虫练习项目:crawler_practice.zip-Python文档类资源-CSDN下载
后续
爬虫方向:大概就是构建基于scrapy符合公司爬取数据的框架。
所需知识大概有:
熟悉scrapy框架,熟悉各种反爬手段以及处理措施;
熟悉MySQL、rides数据库。
上述两条是这个岗位的核心技能
这个岗位需要做到的事情就是爬取数据、筛选数据、存储数据。
如果你想要从事这方面的工作,那就朝着这个方向前进吧~~
如内容有误,还望提醒。