【论文阅读】Multimodal Fusion with Co-Attention Networks for Fake News Detection --- 虚假新闻检测,多模态融合
本博客系本人理解该论文之后所写,非逐句翻译,预知该论文详情,请参阅论文原文。
论文标题:Multimodal Fusion with Co-Attention Networks for Fake News Detection;
作者:Yang Wu, Pengwei Zhan, Yunjian Zhang, Liming Wang, Zhen Xu;
中国科学院大学;
发表会议或期刊:ACL 2021;
代码地址:未开源;
摘要:
靠人工识别谣言是费时费力的,所以急需自动识别谣言的模型。但是现有谣言检测模型在融合多模态特征方面仍有不足,比如,只是简单concatenate单模态特征作为多模态特征,而没有考虑inter-modality的关系。因此,本文提出Multimodal Co-Attention Networks (MCAN)模型,能更好地融合视觉和文本信息进行谣言检测,学习多个模态间的inter-dependence关系。在两个数据集上的实验表明,本文的模型性能超过了SOTA模型。
现有方法的问题:
- 使用了额外的信息(除了image和text内容)。比如att-RNN使用了social content,EANN使用了新闻的类别信息。首先额外信息的获取需要额外的工作,其次对额外信息的处理增加了模型的规模,增大了谣言检测的cost。
- 现有多模态谣言检测方法大多关注于图像的语义信息(semantic level),而忽略了它的物理特征(physical level)。比如图像是否重新压缩,就会在频域体现出来(frequency domain)。
- 多模态特征融合方式太简单,比如直接concatenate。虽然att-RNN使用了attention,但是它只是从文本和社交信息方面获取了attention。而实际上人们看一个新闻是否是谣言的时候,会反复观察图像和文本,也就是说在视觉和文本之间attention的过程重复了多次。这样才能充分提取inter-modality信息。
本文贡献:
- 本文提出了一个端到端的检测虚假新闻的模型,只使用图像和文本信息,不需要额外的信息或者辅助任务;
- 本文设计的MCAN模型将多个co-attention层堆叠在一起融合多模态特征,可以学习到多个模态之间的inter-dependencies关系;
- 本文模型MCAN是一个普适的框架,其中各个部件是灵活的。比如用来提取模态特征的VGG,Bert等模型可以被替换。并且本文的模态融合过程可以直接用于更多模态(超过两个模态)的数据融合;
- 在两个大规模谣言检测数据集上通过实验证明了本文模型性能超过了SOTA方法。
本文模型:
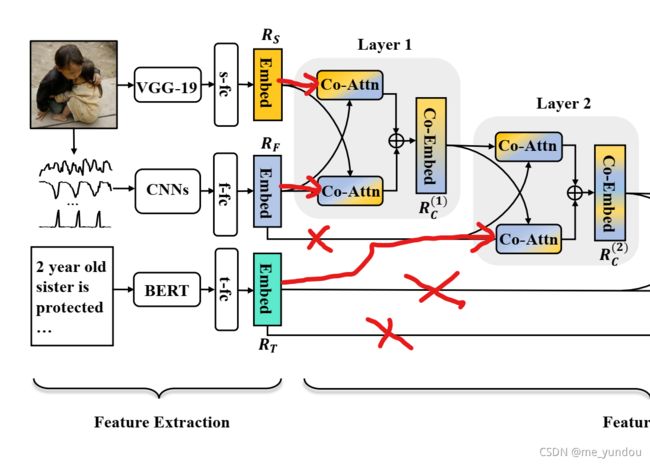
只使用新闻的图像image和文本text内容用于谣言检测。从图像中提取空间域(spatial-domain )特征和频域(frequency-domain) 特征,从文本中提取文本特征(textual features)。然后设计多个co-attention模块用于fuse多模态特征,得到新闻的多模态表示用于谣言检测。
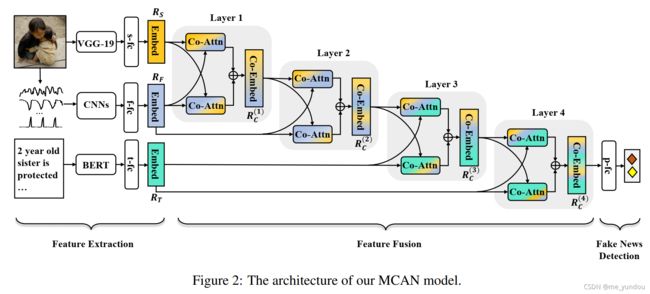
本文模型分为三个部分:特征提取,特征融合,谣言检测。如上图2所示。
1. 特征提取 feature extraction:
- 空间域特征(spatial-domain features)使用VGG-19模型提取。在VGG-19的倒数第二层后面接一个全连接层(记为s-fc)和一个激活函数,得到图像的空间域特征
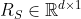 。
。
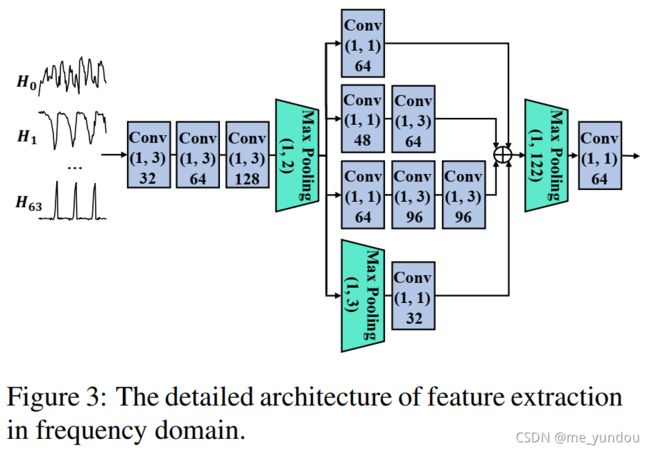
- 频域特征(frequency-domain features)使用一系列CNN网络提取,如上图3所示。首先用discrete cosine transform(DCT)将原始图像从空间域转换到频域,得到64个vectors
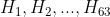 ,采样到固定的长度250。然后组合成64 * 250 的矩阵输入后续CNN网络中,最后经过一个全连接网络和一个激活函数(记为f-fc),得到图像的频域特征
,采样到固定的长度250。然后组合成64 * 250 的矩阵输入后续CNN网络中,最后经过一个全连接网络和一个激活函数(记为f-fc),得到图像的频域特征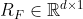 。
。 - 文本特征(textual features)使用Bert提取。然后在Bert后面接一个全连接层和激活层(记为t-fc),得到文本特征
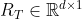 。
。
2. 特征融合 feature fusion:
本文的多模态特征融合是由一系列CA layers(co-attention layers)实现的,每个CA layer包含两个并行的CA blocks(co-attention blocks),其中CA blocks的结构如下图4所示:
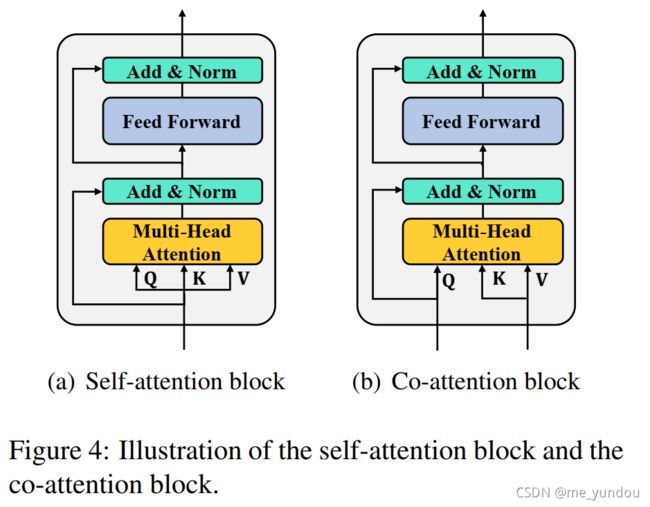
与传统transformer相比(上图4左边图),CA block(上图4右边图)的特点在于多头attention的keys和values与querys来自不同的地方,残差连接的只有querys值。传统transformer里面的QKV均来自同一个输入,而本文模型中Q来自一个模态,KV来自另一个模态。
通过将两个上述CA blocks并行排列,如图2所示,组成一个CA layer,可以实现不同模态之间信息的交互学习。举个例子,模态A和B,以及CA blocks CA1 和 CA2,那么并行的CA1和CA2处理A和B两个模态数据的方式是:CA1以模态A的数据作为Q,模态B的数据作为K和V;CA2以模态B的数据作为Q,模态A的数据作为K和V。这样就实现了模态A和B的数据的co-attention的学习,两者都被充分学习了(相比于att-RNN的只用单模态text作为了attention)。两个CA blocks的输出拼接之后经过一个全连接层,得到维度为d的输出向量,以便继续进行后续的运算。
通过将多个CA layers堆叠使用,如上图2所示,可以实现对多个模态数据的融合。本文模型使用了4个CA layers对空间域特征、频域特征、文本特征进行多模态融合。由于页数限制,本文只给出了第一个CA layer的公式,如下面所示,其他几个layer的公式类似。其中MA代表多头attention,FFN代表前馈网络层。
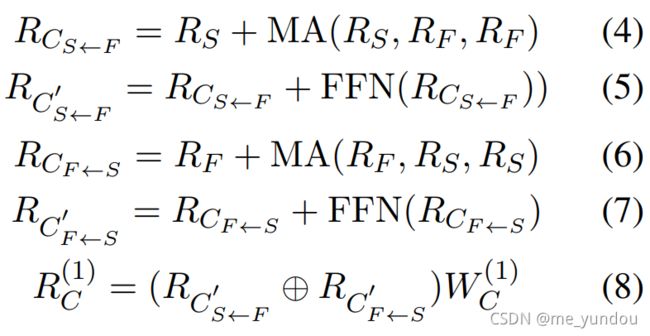
注意,本文的第一个和第三个CA layers共享参数,第二个和第四个CA layers共享参数。
3. 谣言检测 fake news detection:
将最后一个CA layer的输出经过谣言检测模块,得到一条新闻是谣言的概率,如下面公式(9)。然后用cross-entropy计算loss,如下面公式(10)。y_hat是预测值,y是新闻的真实标签,1代表谣言,0代表非谣言。
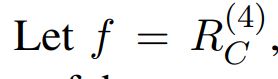
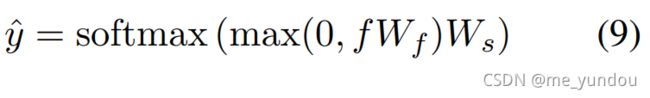
实验
任务:虚假新闻检测。
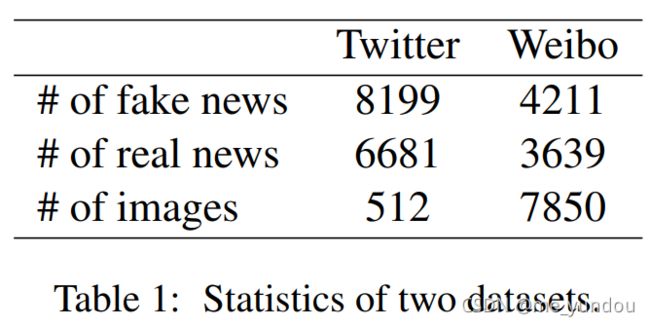
数据集:微博 Weibo [1] 和推特 Twitter [2],详情见下表1。本文将数据集划分为training set和test set,同原始的数据集划分一样。
实验设置:
- 推特数据集上VGG-19和Bert的模型参数是frozen的,为了避免过拟合问题;而微博数据集上VGG-19和Bert的参数是不frozen的,也就是说,用了谣言检测的任务对他们进行了fine-tuning(这样的话,在与其他方法,比如MVAE等使用了frozen参数的VGG-19和Bert模型的方法进行对比的时候,不公平吧);
- 模型的epoch设置为100,且使用了early stopping策略;
- 模型超参数通过grid searching挑选,挑选依据是谣言检测accuracy;
- 其他具体参数设置见论文原文;
对比方法 Baselines:
分为单模态方法(下列1-4)和多模态方法(下列5-9):
- 纯文本Text:仅使用文本信息,模型是一个Bert加后续的谣言检测网络;
- 纯空间域特征Spatial:仅使用图像信息,模型是一个VGG-19加后续的谣言检测网络;
- 纯频域特征Freq:本文的MCAN模型中仅包含处理频域特征的模块;
- VQA:一个用图像做问答的模型;
- NeuralTalk:一个做image caption的深度RNN网络;
- att-RNN:对新闻的文本,图像,社交信息用attention处理的模型。为了公平实验,本文去掉了它对social info的使用;
- EANN:用对抗的思想提取新闻的event特征。因为event信息是额外的,所以本文为了公平在实验中去掉了EANN中有关event的模块;
- MVAE:用VAE实现的谣言检测;
- MCAN-A:本文模型的变体,去掉了多模态特征fusion的部分,直接把空间域特征、频域特征、文本特征简单拼接起来作为新闻的多模态表示。
实验结果:
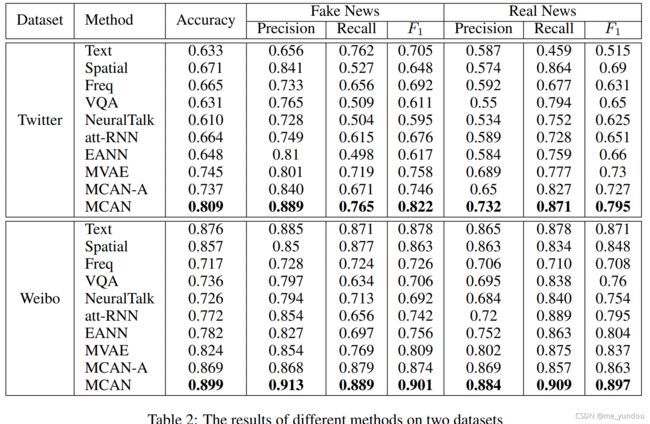
如下图2所示,从MCAN-A与单模态方法对比中可以看出,使用更多模态信息对于检测谣言确实是有帮助的。另外,Bert和VGG-19模型在微博上的性能比推特上好很多,可能的原因是,微博上的文本平均长度是推特的10倍,包含更多的信息。而且推特上的很多新闻都是同一个事件,因此在训练时容易过拟合,导致性能降低(这也是本文模型选择在推特数据集上frozen bert和vgg模型的参数的原因)。只使用fine-tune的bert和vgg,微博上的检测结果就能超过0.85,但是本文模型能接近0.9,说明本文还是强(但是其他模型连单模态都整不过了啊。。。。)。
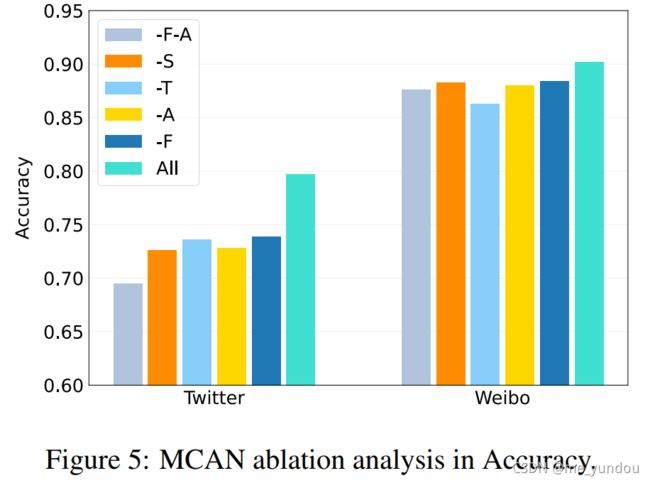
消融实验 ablation study:
定量分析:消融实验结果如下图5所示,ALL代表本文完整的MCAN模型,其他各字母分别代表MCAN的各个部分,其中F代表空间域表示(spatial-domain representation), T代表文本表示(textual representation), F代表频域表示(frequency-domain representation), A代表CA层(coattention layers)。下图中-F-A代表同时去掉频域表示和CA层的模型。
从下图可以看出,本文模型的各部分都是有效的。对推特数据集而言,文本对分辨谣言带来的贡献没有图像模态多,而微博数据集则相反,可能的原因是推特数据集的不平衡问题以及推特中新闻本文长度较短。另外,微博数据集上去掉各个部分带来的性能减低没有推特明显,可能的原因是微博数据集比较均衡,且其上的MCAN模型使用了fine-tune的VGG和Bert模型,更加平稳。
定性分析:本文将MCAN-A模型的多模态表示(三种模态的拼接)和MCAN模型的多模态表示(经过CA层的结果)用t-SNE可视化了,如下图所示。其中节点的标签是是否为谣言,没有使用CA层得到的多模态表示能够学习到一些特征,但是在某些样本上无法分辨;而MCAN学习到的多模态表示更加可分辨,具有明显的分界线。
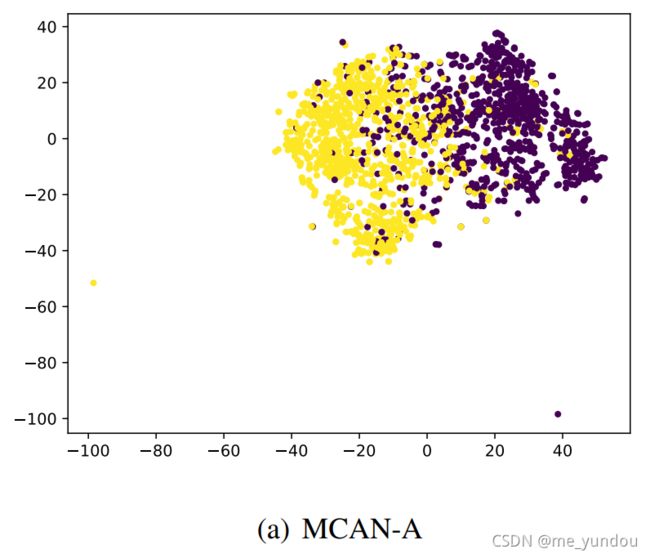
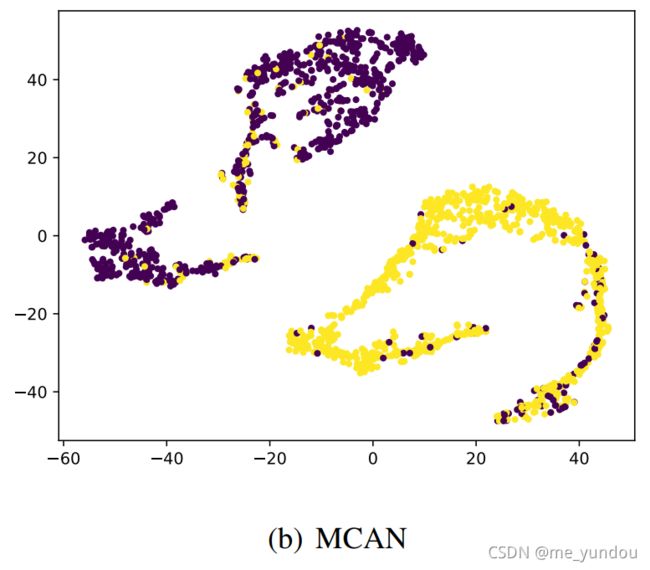
综上,可以说明本文的MCAN模型借助于CA层能够学到更具有区分性的特征表示,因此在判别谣言的性能上更好。
样例分析 case study:
本文展示了一些正确被MCAN识别出来的新闻样例,但是单模态方法(使用文本或者空间域特征)判断错误了的例子。这里不再展示图片,详情看论文原文。
总结:
本文针对多模态谣言检测问题,使用了三个子网络从文本、图像空间特征、图像频域特征三个方面提取新闻特征,并设计co-attention层对多个模态的特征进行融合。在实验中证明了本文模型有良好的分辨谣言的能力。未来,作者计划将MCAN中的CA思想应用于更多虚假新闻研究领域,比如虚假新闻传播(fake news diffusion)的分析。
个人的阅读疑问:
鉴于本人能力有限,对本论文中有些地方仍然不太明白,在此记录下来,待日后与人讨论出结果后再修改博客。
- 在融合多模态数据方面,实际上使用两个CA blocks就可以将三种信息完全囊括,为什么本文模型使用了四个CA blocks呢?是通过实验分析得出的,还是从理论上可以说明使用4个CA blocks是有效且必须的呢?
- 本文模型的四个CA blocks中第一个和第三个共享模型,第二个和第四个共享模型,为什么?只是为了减少参数量吗?还是有其他理论支持?
- 本文实验中对比的其他baselines使用的VGG-19或者Bert模型是固定参数的,没有进行fine-tune,而本文在微博数据集上对模型做了fine-tune,这样的比较是不公平的。
- 本文实验中对数据集的划分仍旧延续了training set和test set,没有用validation set做验证,模型的泛化性能有待考察。
参考文献:
[1] Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, and Jiebo Luo. 2017. Multimodal fusion with recurrent neural networks for rumor detection on microblogs. In Proceedings of the 25th ACM international conference on Multimedia, pages 795–816.
[2] C. Boididou, S. Papadopoulos, D. Dang-Nguyen, G. Boato, and Y. Kompatsiaris. 2016. Verifying multimedia use at mediaeval 2016. In MediaEval 2016 Workshop.