树家族基础-决策树篇(基于spark)
本文章前提是“单变量决策树”,即每次仅在备选特征中挑选1个,不考虑“多变量决策树”的情形。
另外,算法本身和spark Mlib库的支持也是两回事,有些功能算法可能本身有,但是支持库spark或是Python没有实现,所以有时候会有点混乱,要关注spark库实现。
(3)缺失值-C4.5算法不敏感
目录
1、数据质量要求
maxBins=32表示离散化连续变量分区个数最大值
2、原理解释
(1)白话原理
(2)场景
(3)缺失值-C4.5算法不敏感
(4)缺失值-Cart算法敏感
(5)不平衡数据看实际情况,可以改进优化算法
(6)离群点数据不敏感
(7)数据归一不敏感
(8)离散特征处理
3、分类树与回归树差异
4、代码相关
5、基础补充
1、数据质量要求
| 算法 | 机器学习类别 | 缺失值 | 连续值 | 不平衡数据 | 离群点 | 数据归一 | 离散特征处理 | 树形 | 特征选择依据 | spark实现 | 过拟合处理 |
| 决策树-ID3 | 多分类 | 无法处理 | 无法处理 | 不敏感 | 不敏感 | 不敏感 | 可处理 | 多叉树 | 信息增益 | no | |
| 决策树-C4.5 | 多分类 | 不敏感 | 不敏感 | 不敏感 | 不敏感 | 不敏感 | one-hot 或 K值编码 | 多叉树 | 信息增益率 | no | 后剪枝,计算大 |
| 决策树-CART | 多分类、回归 | 敏感, spark需处理 |
不敏感 | 不敏感 | 不敏感 | 不敏感 | one-hot 或 K值编码 | 二叉树 | Gini系数 | yes | 超参数: maxdepth、 maxbins、mininfogain、impurity |
maxBins=32表示离散化连续变量分区个数最大值
2、原理解释
(1)白话原理
树的生长+停止条件+结果认定:
生长即特征选择的过程,特征选择的依据根据不同的算法可能是信息增益、信息增益率或Gini系数,但不管哪一种这种公式中的重要组成部分都有pk的计算即类别占比;
停止条件包括:叶子节点纯了、特征子集为空了或是数据点在特征子集上取值相同、结点样本集为空;
结果认定:叶子节点类别占比最大的类别(作为一个概率)(或当停止条件为第3种情况时,该叶子结点的类别为其父节点中类别占比最大的类别)
(2)场景
适用于2分类或多分类问题;
决策树使用,一方面作为随机森林的基础对照,另一方面跟非专家用户好解释;
c4.5是对id3的改进,改进了3点:处理缺失值、处理连续值、特征选择依据改为信息增益率;
所以从总体上看,spark的决策树算法需要处理缺失值,需要对离散特征进行编码。
(3)缺失值-C4.5算法不敏感
在周志华《机器学习》书里,有描述C4.5算法对缺失值数据的处理算法过程,此处不详述;
直白理解:决策树的关键是解决选特征、样本根据特征值划分的问题;
选特征的时候要依据信息增益率,也就是要计算每个特征备选值被选择后数据集的信息熵,这个可以剔除缺失值考虑;当遇到样本特征值为空时,按权重划分到特征值的所有分支节点。这两点便是C4.5的处理思路。
(4)缺失值-Cart算法敏感
cart无实现缺失值的处理逻辑。
(5)不平衡数据看实际情况,可以改进优化算法
这个从决策树的原理理解:对于c4.5平衡或者不平衡,每次都是单独进行信息熵、进而进行信息增益、信息增益率的计算,所以不影响,对比的是特征选择前后的信息熵变化,也就是样本类别变化,关心的是变化,而不是数量绝对比例。对于cart,Gini系数公式中的重要组成要素也是样本类别变化,所以也不受影响。
不平衡对分裂过程没影响,看实际情况,如预测效果不佳,可以考虑结果认定时调整权重进优化;
例如某个叶子节点 所有样本权重相同, 和权重不一样,最终算出来的类别可能有差异。
spark的dt源码中未见调节权重的参数,如果要优化,可以改进算法。
概括:
权重影响的是 损失函数计算, 决策树和gbdt在分裂过程中,参考的不是损失函数,所以通过改变权重调节损失函数计算应该影响不了分裂吧 ,xgboost和lgb分裂的时候参考的损失函数,改变权重是能影响到分裂过程的
(6)离群点数据不敏感
这个从决策树的原理理解:离群点也会最终被分到某个叶子节点,不管是分对还是分错,叶子节点的最终类别都是以类别占比大的类别作为该叶子节点的类别。
(7)数据归一不敏感
这个从决策树的原理理解:每次都是从备选特征中选择一个特征,对这个特征根据属性值进行分支;所以不同特征不会放在一起处理,因此没必要进行数据归一。
(8)离散特征处理
可以采用one-hot编码,或者K值编码;
spark编码中,dataframe的schema里可以记录特征的类型、数据类型、特征名称;因此采用K值编码也可以区分离散特征还是连续特征;
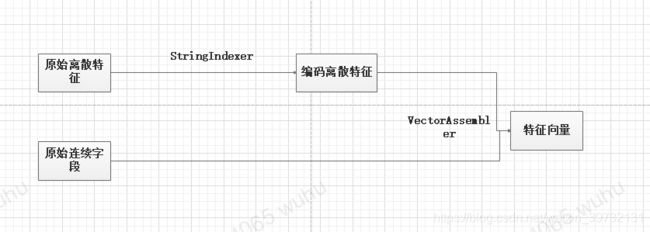
3、分类树与回归树差异
分类树特征选择衡量标准是熵或Gini系数,结果认定是 类别占比大的类别;
回归树特征选择衡量标准是最小均方误差,结果认定是各数据点的平均值;
最小均方误差公式:∑(实际值-预测值)^2/N
4、代码相关
package org.example
//package com.taiping.datascience.rdf
//打包,一般是com.公司名.项目名.模块名
//package 与目录结构一致
import org.apache.spark.ml.classification.{DecisionTreeClassifier, RandomForestClassificationModel, RandomForestClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{VectorAssembler, VectorIndexer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.ml.tuning.{ParamGridBuilder, TrainValidationSplit}
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.util.Random
object RunRDF {
def main(args: Array[String]): Unit = {//Unit 代表无返回值
val spark = SparkSession.builder().master("local[4]").getOrCreate()//创建1个SparkSession,本地运行加 local,数字跟CPU核数相关
spark.sparkContext.setLogLevel("ERROR")//只展示报错日志
import spark.implicits._
/*
Spark的Scala开发一定要加入以下这一行
它主要是使RDD转化为DataFrame以及支持后续SQL操作
*/
val dataWithoutHeader = spark.read.
option("inferSchema", true).
option("header", false).
csv("E:\\13data\\covtype\\covtype.data")
/*
println("*************************************************************************a")
println(dataWithoutHeader.first)
println(dataWithoutHeader.first.length)
*/
/* Seq是列表,适合存有序重复数据,进行快速插入/删除元素等场景
Set是集合,适合存无序非重复数据,进行快速查找海量元素的等场景*/
val colNames = Seq(
"Elevation", "Aspect", "Slope",
"Horizontal_Distance_To_Hydrology", "Vertical_Distance_To_Hydrology",
"Horizontal_Distance_To_Roadways",
"Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm",
"Horizontal_Distance_To_Fire_Points"
) ++ (
(0 until 4).map(i => s"Wilderness_Area_$i")
) ++ (
(0 until 40).map(i => s"Soil_Type_$i")//$用于拼接字母或数字
) ++ Seq("Cover_Type")
/*
println("**************************************************************************b")
println(colNames.length)
println(colNames)*/
val data = dataWithoutHeader.toDF(colNames:_*).// colNames:_* 表示将colNames当作一个序列使用
withColumn("Cover_Type", $"Cover_Type".cast("double"))//调整列,转换为double类型
//println("**************************************************************************c")
//data.show(3)
//println(data.columns.length)
//println(data.schema.fields.map(f =>f.name).toList)//查看列名
//println(data.dtypes.toMap)//查看每列的类型,IntergerType
/* val total = data.count()
data.groupBy("Cover_Type").count()
.orderBy("Cover_Type")
// .select("count").as[Double]
//.map(_ / total)
//.map(_ .formatted("%.3f"))
.show()//查看样本分布平衡性,样本严重不平衡
影响评估指标选择、分类算法选择*/
// Split into 90% train (+ CV), 10% test
val Array(trainData, testData) = data.randomSplit(Array(0.9, 0.1))
trainData.cache()
testData.cache()
/* println("**************************************************************************d")
println(trainData.count() / data.count())//得到0,对于除号“/”,它的整数除和小数除是有区别的:整数之间做除法时,只保留整数部分而舍弃小数部分。
println(((trainData.count().toDouble/data.count().toDouble)).formatted("%.2f"))*/
/*
println("*********************test 分布*****************************************e")
testData.groupBy("Cover_Type").count()
.orderBy("Cover_Type")
.show()*/
val runRDF = new RunRDF(spark)
//runRDF.simpleDecisionTree(trainData, testData)//决策树模型准确率70%
//runRDF.randomClassifier(trainData, testData)//计算随机猜测猜对的准确率38%
//runRDF.unencodeOneHot(data)
//runRDF.evaluate(trainData, testData)//模型训练、评估、选择91%
runRDF.evaluateCategorical(trainData, testData)//非one-hot编码处理进行模型训练、评估、选择92%
//runRDF.evaluateForest(trainData, testData)//随机森林非one-hot编码处理进行模型训练、评估、选择95%
trainData.unpersist()
testData.unpersist()
}//完成了数据加载
}
//spark作为参数
class RunRDF(private val spark: SparkSession) {
import spark.implicits._
def simpleDecisionTree(trainData: DataFrame, testData: DataFrame): Unit = {
//step1:spark 数据预处理,合并特征为1列
val inputCols = trainData.columns.filter(_ != "Cover_Type")
val assembler = new VectorAssembler().
setInputCols(inputCols).
setOutputCol("featureVector")
val assembledTrainData = assembler.transform(trainData)
val assembledTestData = assembler.transform(testData)
/* assembledTrainData.show(3)
assembledTrainData.select("featureVector").show(truncate = false) //truncate =false,不限制列的字符串长度显示*/
//step2:模型建立:模型实例、数据训练、应用预测
val classifier = new DecisionTreeClassifier().
setSeed(Random.nextLong()).
setLabelCol("Cover_Type").
setFeaturesCol("featureVector").
setPredictionCol("prediction")
val model = classifier.fit(assembledTrainData)
println(model.toDebugString)//查看模型字符串展示
/*
model.featureImportances.toArray.zip(inputCols).
sorted.reverse.foreach(println)//查看特征重要性
*/
val predictions = model.transform(assembledTestData)
//predictions.show(3)
//predictions.select("Cover_Type", "prediction", "probability").
//show(truncate = false)
//step3:模型评价:评价实例、评价方法
val evaluator = new MulticlassClassificationEvaluator().
setLabelCol("Cover_Type").
setPredictionCol("prediction")
val accuracy = evaluator.setMetricName("accuracy").evaluate(predictions)
val f1 = evaluator.setMetricName("f1").evaluate(predictions)
//println(s"test accuracy=$accuracy")
println(f"test accuracy=$accuracy%.2f")//格式化输出
println(s"f1=$f1")
/* val predictionRDD = predictions.//系统自带混淆矩阵实现
select("prediction", "Cover_Type").
as[(Double, Double)].rdd
val multiclassMetrics = new MulticlassMetrics(predictionRDD)
println(multiclassMetrics.confusionMatrix)*/
val confusionMatrix = predictions.//手动混淆矩阵实现
groupBy("Cover_Type").
pivot("prediction", (1 to 7)).
count().
na.fill(0.0).
orderBy("Cover_Type")
//confusionMatrix.show()
}
def classProbabilities(data: DataFrame): Array[Double]= {//该方法查看每个植被类型数据在总体数据中的比例
val total = data.count()
data.groupBy("Cover_Type").count().
orderBy("Cover_Type").
select("count").as[Double].
map(_ / total).
collect()
}
def randomClassifier(trainData: DataFrame, testData: DataFrame): Unit = {//该方法计算随机猜测的准确率
val trainPriorProbabilities = classProbabilities(trainData)
val testPriorProbabilities = classProbabilities(testData)
val accuracy = trainPriorProbabilities.zip(testPriorProbabilities).map {
case (trainProb, cvProb) => trainProb * cvProb
}.sum
//println(trainPriorProbabilities.zip(testPriorProbabilities).mkString(","))//展示tuple
// println(accuracy.formatted("%.2f"))
}
def evaluate(trainData: DataFrame, testData: DataFrame): Unit = {//该方法完整完成模型的训练、评估、及选择
val inputCols = trainData.columns.filter(_ != "Cover_Type")
val assembler = new VectorAssembler().
setInputCols(inputCols).
setOutputCol("featureVector")
val classifier = new DecisionTreeClassifier().
setSeed(Random.nextLong()).
setLabelCol("Cover_Type").
setFeaturesCol("featureVector").
setPredictionCol("prediction")
val pipeline = new Pipeline().setStages(Array(assembler, classifier))
val paramGrid = new ParamGridBuilder().
addGrid(classifier.impurity, Seq("gini", "entropy")).
addGrid(classifier.maxDepth, Seq(1, 20)).
addGrid(classifier.maxBins, Seq(40, 300)).
addGrid(classifier.minInfoGain, Seq(0.0, 0.05)).
build()
val multiclassEval = new MulticlassClassificationEvaluator().
setLabelCol("Cover_Type").
setPredictionCol("prediction").
setMetricName("f1")//f1作为衡量指标
val validator = new TrainValidationSplit().
setSeed(Random.nextLong()).
setEstimator(pipeline).
setEvaluator(multiclassEval).
setEstimatorParamMaps(paramGrid).
setTrainRatio(0.9)
val validatorModel = validator.fit(trainData)//一组模型
val paramsAndMetrics = validatorModel.validationMetrics.
zip(validatorModel.getEstimatorParamMaps).sortBy(_._1)
/* paramsAndMetrics.foreach { case (metric, params) =>
println(metric)
println(params)
println()
}*/
val bestModel = validatorModel.bestModel//最优模型
//println(bestModel.asInstanceOf[PipelineModel].stages.last.extractParamMap)//最优模型参数
val validationMax=validatorModel.validationMetrics.max
//println(s"train-best_score :$validationMax")//验证集最好准确率
val testAccuracy = multiclassEval.evaluate(bestModel.transform(testData))
//println(s"testAccuracy:$testAccuracy")//测试集准确率
val trainAccuracy = multiclassEval.evaluate(bestModel.transform(trainData))
//println(s"trainAccuracy:$trainAccuracy")//训练集准确率
/*
val predictions=bestModel.transform(testData)
val confusionMatrix = predictions.//手动混淆矩阵实现
groupBy("Cover_Type").
pivot("prediction", (1 to 7)).
count().
na.fill(0.0).
orderBy("Cover_Type")
confusionMatrix.show()
*/
}
def unencodeOneHot(data: DataFrame)= {//不采用one-hot编码
val wildernessCols = (0 until 4).map(i => s"Wilderness_Area_$i").toArray//列表
val wildernessAssembler = new VectorAssembler().
setInputCols(wildernessCols).
setOutputCol("wilderness")
//val unhotUDF = udf((vec: Vector) => vec.toArray.indexOf(1.0).toDouble)//是否转换toDouble不影响
val unhotUDF = udf((vec: Vector) => vec.toArray.indexOf(1.0))
val withWilderness = wildernessAssembler.transform(data).
drop(wildernessCols:_*).
withColumn("wilderness", unhotUDF($"wilderness"))
/* println("*****************************************************")
withWilderness.show()*/
val soilCols = (0 until 40).map(i => s"Soil_Type_$i").toArray
val soilAssembler = new VectorAssembler().
setInputCols(soilCols).
setOutputCol("soil")
//定义成变量就没有返回值,否则就是返回值
soilAssembler.transform(withWilderness).
drop(soilCols:_*).
withColumn("soil", unhotUDF($"soil"))
//soilness.show()
}
def evaluateCategorical(trainData: DataFrame, testData: DataFrame) = {//采用非one-hot编码的方法处理离散变量进行模型选择
val unencTrainData = unencodeOneHot(trainData)
val unencTestData = unencodeOneHot(testData)
val inputCols = unencTrainData.columns.filter(_ != "Cover_Type")
val assembler = new VectorAssembler().
setInputCols(inputCols).
setOutputCol("featureVector")
val indexer = new VectorIndexer().//区分连续变量、离散变量,并对离散变量编号
setMaxCategories(40).//40个取值以内就是离散变量,会重新编号,40个以上认为是连续变量则不处理
setInputCol("featureVector").
setOutputCol("indexedVector")
val classifier = new DecisionTreeClassifier().
setSeed(Random.nextLong()).
setLabelCol("Cover_Type").
setFeaturesCol("indexedVector").
setPredictionCol("prediction")
val pipeline = new Pipeline().setStages(Array(assembler, indexer, classifier))
val paramGrid = new ParamGridBuilder().
addGrid(classifier.impurity, Seq("gini", "entropy")).
addGrid(classifier.maxDepth, Seq(1, 20)).
addGrid(classifier.maxBins, Seq(40, 300)).
addGrid(classifier.minInfoGain, Seq(0.0, 0.05)).
build()
val multiclassEval = new MulticlassClassificationEvaluator().
setLabelCol("Cover_Type").
setPredictionCol("prediction").
setMetricName("accuracy")
val validator = new TrainValidationSplit().
setSeed(Random.nextLong()).
setEstimator(pipeline).
setEvaluator(multiclassEval).
setEstimatorParamMaps(paramGrid).
setTrainRatio(0.9)
val validatorModel = validator.fit(unencTrainData)
val bestModel = validatorModel.bestModel
//println(bestModel.asInstanceOf[PipelineModel].stages.last.extractParamMap)
val testAccuracy = multiclassEval.evaluate(bestModel.transform(unencTestData))
println(s"unencodeMethod-test-accuray:$testAccuracy")
}
def evaluateForest(trainData: DataFrame, testData: DataFrame): Unit = {
val unencTrainData = unencodeOneHot(trainData)
val unencTestData = unencodeOneHot(testData)
val inputCols = unencTrainData.columns.filter(_ != "Cover_Type")
val assembler = new VectorAssembler().
setInputCols(inputCols).
setOutputCol("featureVector")
val indexer = new VectorIndexer().
setMaxCategories(40).
setInputCol("featureVector").
setOutputCol("indexedVector")
val classifier = new RandomForestClassifier().
setSeed(Random.nextLong()).
setLabelCol("Cover_Type").
setFeaturesCol("indexedVector").
setPredictionCol("prediction").
setImpurity("entropy").
setMaxDepth(20).
setMaxBins(300)
val pipeline = new Pipeline().setStages(Array(assembler, indexer, classifier))
val paramGrid = new ParamGridBuilder().
addGrid(classifier.minInfoGain, Seq(0.0, 0.05)).
addGrid(classifier.numTrees, Seq(1, 10)).
build()
val multiclassEval = new MulticlassClassificationEvaluator().
setLabelCol("Cover_Type").
setPredictionCol("prediction").
setMetricName("accuracy")
val validator = new TrainValidationSplit().
setSeed(Random.nextLong()).
setEstimator(pipeline).
setEvaluator(multiclassEval).
setEstimatorParamMaps(paramGrid).
setTrainRatio(0.9)
val validatorModel = validator.fit(unencTrainData)
val bestModel = validatorModel.bestModel
val forestModel = bestModel.asInstanceOf[PipelineModel].//看参数,需要实例化
stages.last.asInstanceOf[RandomForestClassificationModel]
println(forestModel.extractParamMap)//随机森林参数
println(forestModel.getNumTrees)//树的数量
forestModel.featureImportances.toArray.zip(inputCols).//特征重要性
sorted.reverse.foreach(println)
val testAccuracy = multiclassEval.evaluate(bestModel.transform(unencTestData))
println(s"forest-unencode-accuracy:$testAccuracy")//测试集准确率
bestModel.transform(unencTestData.drop("Cover_Type")).select("prediction").show()
}
}5、基础补充
(1)熵

(2) 信息增益

信息增益倾向于选择特征值多的特征,极端情况下例如特征的每一个取值都不重复,则其分类结点的熵为0,此时信息增益最大;因此ID3算法处理不了缺失值(没有填充算法考虑)、连续值,而且倾向于选择特征值多的特征;
(3) 信息增益率

(4)c4.5算法是对ID3算法的改进,有对遇到缺失值的处理方案(特征选择时忽略、应用时按权重分配),特征选择依据采用了信息增益率,较id3算法就可以避免倾向选择特征值多的特征和连续值。
(5)Gini系数

树类算法之---决策树Cart树Gini系数就算原理。_Ricky-CSDN博客_gini系数 决策树
参考上方链接对cart树基本描述
(6)cart算法-分类
Cart树是一个二叉树,所以在计算Gini系数的时候,还要考虑,要以哪个特征值作为切分。
先选择基尼系数最小的特征,再对应选择该特征下,Gini系数最小的特征值作为分裂点。