飞桨万能转换小工具X2Paddle,教你玩转模型迁移
百度推出飞桨(PaddlePaddle)后,不少开发者开始转向国内的深度学习框架。但是从代码的转移谈何容易,之前的工作重写一遍不太现实,成千上万行代码的手工转换等于是在做一次二次开发。
现在,有个好消息:无论Caffe、TensorFlow、ONNX都可以轻松迁移到飞桨平台上。虽然目前还不直接迁移PyTorch模型,但PyTorch本身支持导出为ONNX模型,等于间接对该平台提供了支持。
然而,有人还对存在疑惑:不同框架之间的API有没有差异?整个迁移过程如何操作,步骤复杂吗?迁移后如何保证精度的损失在可接受的范围内?
大家会考虑很多问题,而问题再多,归纳一下,无外乎以下几点:
1.API差异:模型的实现方式如何迁移,不同框架之间的API有没有差异?如何避免这些差异带来的模型效果的差异?
2.模型文件差异:训练好的模型文件如何迁移?转换框架后如何保证精度的损失在可接受的范围内?
3.预测方式差异:转换后的模型如何预测?预测的效果与转换前的模型差异如何?
飞桨开发了一个新的功能模块,叫X2Paddle(Github见参考1),可以支持主流深度学习框架模型转换至飞桨,包括Caffe、Tensorflow、onnx等模型直接转换为Paddle Fluid可加载的预测模型,并且还提供了这三大主流框架间的API差异比较,方便我们在自己直接复现模型时对比API之间的差异,深入理解API的实现方式从而降低模型迁移带来的损失。
下面以TensorFlow转换成Paddle Fluid模型为例,详细讲讲如何实现模型的迁移。
TensorFlow-Fluid 的API差异
在深度学习入门过程中,大家常见的就是手写数字识别这个demo,下面是一份最简单的实现手写数字识别的代码:
from tensorflow.examples.tutorials.mnist import input_dataimport tensorflow as tfmnist = input_data.read_data_sets("MNIST_data/", one_hot=True)x = tf.placeholder(tf.float32, [None, 784]) W = tf.Variable(tf.zeros([784, 10]))b = tf.Variable(tf.zeros([10]))y = tf.nn.softmax(tf.matmul(x, W) + b)y_ = tf.placeholder("float", [None, 10])cross_entropy = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits = y,labels = y_))train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)init = tf.global_variables_initializer()sess = tf.Session()sess.run(init)for i in range(1, 1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder("float", [None, 10])
cross_entropy = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits = y,labels = y_))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(1, 1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
大家看这段代码里,第一步是导入mnist数据集,然后设置了一个占位符x来表示输入的图片数据,再设置两个变量w和b,分别表示权重和偏置来计算,最后通过softmax计算得到输出的y值,而我们真实的label则是变量y_ 。
前向传播完成后,就可以计算预测值y与label y_之间的交叉熵。
再选择合适的优化函数,此处为梯度下降,最后启动一个Session,把数据按batch灌进去,计算acc即可得到准确率。
这是一段非常简单的代码,如果我们想把这段代码变成飞桨的代码,有人可能会认为非常麻烦,每一个实现的API还要一一去找对应的实现方式,但是这里,我可以告诉大家,不!用!这!么!麻!烦!因为在X2Paddle里有一份常用的Tensorflow对应Fluid的API表,(https://github.com/PaddlePaddle/X2Paddle/tree/master/tensorflow2fluid/doc),如下所示:

对于常用的TensorFlow的API,都有相应的飞桨接口,如果两者的功能没有差异,则会标注功能一致,如果实现方式或者支持的功能、参数等有差异,即会标注“差异对比”,并详细注明。
譬如,在上文这份非常简单的代码里,出现了这些TensorFlow的API:
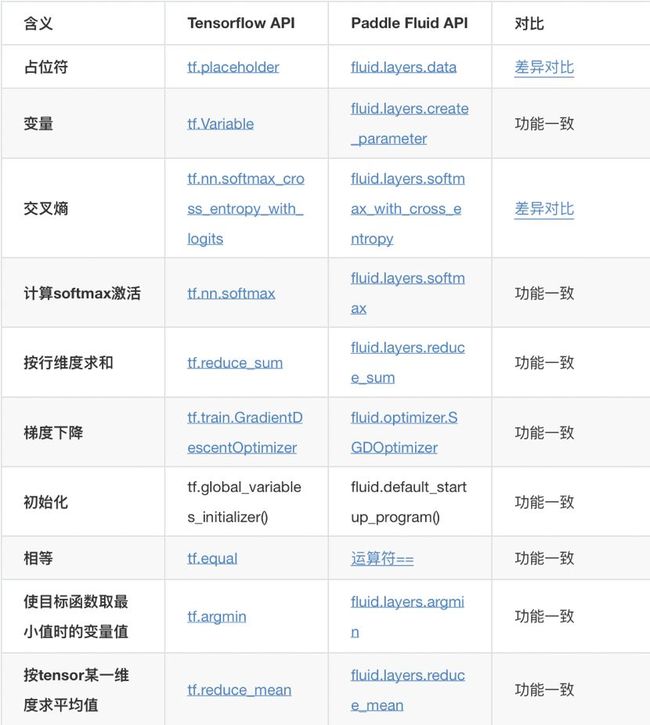
在出现的这些api里,大部分的功能都是一致的,只有两个功能不同,分别是tf.placeholder和tf.nn.softmax_cross_entropy_with_logits ,分别对应 fluid.layers.data 和 fluid.layers.softmax_with_cross_entropy . 我们来看看具体差异:
tf.placeholder V.S fluid.layers.data
常用TensorFlow的同学对placeholder应该不陌生,中文翻译为占位符,什么意思呢?在TensorFlow 2.0以前,还是静态图的设计思想,整个设计理念是计算流图,在编写程序时,首先构筑整个系统的graph,代码并不会直接生效,这一点和python的其他数值计算库(如Numpy等)不同,graph为静态的,在实际的运行时,启动一个session,程序才会真正的运行。这样做的好处就是:避免反复地切换底层程序实际运行的上下文,tensorflow帮你优化整个系统的代码。我们知道,很多python程序的底层为C语言或者其他语言,执行一行脚本,就要切换一次,是有成本的,tensorflow通过计算流图的方式,可以帮你优化整个session需要执行的代码。
在代码层面,每一个tensor值在graph上都是一个op,当我们将train数据分成一个个minibatch然后传入网络进行训练时,每一个minibatch都将是一个op,这样的话,一副graph上的op未免太多,也会产生巨大的开销;于是就有了tf.placeholder,我们每次可以将 一个minibatch传入到x = tf.placeholder(tf.float32,[None,32])上,下一次传入的x都替换掉上一次传入的x,这样就对于所有传入的minibatch x就只会产生一个op,不会产生其他多余的op,进而减少了graph的开销。
参数对比
tf.placeholder
tf.placeholder( dtype, shape=None, name=None )
shape=None,
name=None
)
paddle.fluid.layers.data
paddle.fluid.layers.data( name, shape, append_batch_size=True, dtype='float32', lod_level=0, type=VarType.LOD_TENSOR, stop_gradient=True)
shape,
append_batch_size=True,
dtype='float32',
lod_level=0,
type=VarType.LOD_TENSOR,
stop_gradient=True)从图中可以看到,飞桨的api参数更多,具体差异如下:
-
Batch维度处理
TensorFlow: 对于shape中的batch维度,需要用户使用None指定;
飞桨: 将第1维设置为-1表示batch维度;如若第1维为正数,则会默认在最前面插入batch维度,如若要避免batch维,可将参数append_batch_size设为False。
-
梯度是否回传
tensorflow和pytorch都支持对输入求梯度,在飞桨中直接设置stop_gradient = False即可。如果在某一层使用stop_gradient=True,那么这一层之前的层都会自动的stop_gradient=True,梯度不会参与回传,可以对某些不需要参与loss计算的信息设置为stop_gradient=True。对于含有BatchNormalization层的CNN网络,也可以对输入求梯度,如
layers.data( name="data", shape=[32, 3, 224, 224], dtype="int64", append_batch_size=False, stop_gradient=False)"data",
shape=[32, 3, 224, 224],
dtype="int64",
append_batch_size=False,
stop_gradient=False)
tf.nn.softmax_cross_entropy_with_logits V.S fluid.layers.softmax_with_cross_entropy
参数对比
tf.nn.softmax_cross_entropy_with_logits( _sentinel=None, labels=None, logits=None, dim=-1, name=None)None,
labels=None,
logits=None,
dim=-1,
name=None
)
paddle.fluid.layers.softmax_with_cross_entropy
paddle.fluid.layers.softmax_with_cross_entropy( logits, label, soft_label=False, ignore_index=-100, numeric_stable_mode=False, return_softmax=False)
label,
soft_label=False,
ignore_index=-100,
numeric_stable_mode=False,
return_softmax=False
)功能差异
标签类型
TensorFlow:labels只能使用软标签,其shape为[batch, num_classes],表示样本在各个类别上的概率分布;
飞桨:通过设置soft_label,可以选择软标签或者硬标签。当使用硬标签时,label的shape为[batch, 1],dtype为int64;当使用软标签时,其shape为[batch, num_classes],dtype为int64。
返回值
TensorFlow:返回batch中各个样本的log loss;
飞桨:当return_softmax为False时,返回batch中各个样本的log loss;当return_softmax为True时,再额外返回logtis的归一化值。
疑问点?
硬标签,即 one-hot label, 每个样本仅可分到一个类别
软标签,每个样本可能被分配至多个类别中
numeric_stable_mode:这个参数是什么呢?标志位,指明是否使用一个具有更佳数学稳定性的算法。仅在 soft_label 为 False的GPU模式下生效. 若 soft_label 为 True 或者执行场所为CPU, 算法一直具有数学稳定性。注意使用稳定算法时速度可能会变慢。默认为 True。
return_softmax: 指明是否额外返回一个softmax值, 同时返回交叉熵计算结果。默认为False。
如果 return_softmax 为 False, 则返回交叉熵损失。
如果 return_softmax 为 True,则返回元组 (loss, softmax) ,其中交叉熵损失为形为[N x 1]的二维张量,softmax为[N x K]的二维张量。
代码示例
data = fluid.layers.data(name='data', shape=[128], dtype='float32')label = fluid.layers.data(name='label', shape=[1], dtype='int64')fc = fluid.layers.fc(input=data, size=100)out = fluid.layers.softmax_with_cross_entropy( logits=fc, label=label)128], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
fc = fluid.layers.fc(input=data, size=100)
out = fluid.layers.softmax_with_cross_entropy(
logits=fc, label=label)
所以通过API对应表,我们可以直接转换把TensorFlow代码转换成Paddle Fluid代码。但是如果现在项目已经上线了,代码几千行甚至上万行,或者已经训练出可预测的模型了,如果想要直接转换API是一件非常耗时耗精力的事情,有没有一种方法可以直接把训练好的可预测模型直接转换成另一种框架写的,只要转换后的损失精度在可接受的范围内,就可以直接替换。下面就讲讲训练好的模型如何迁移。
模型迁移
VGG_16是CV领域的一个经典模型,我以tensorflow/models下的VGG_16为例,给大家展示如何将TensorFlow训练好的模型转换为飞桨模型。
下载预训练模型
import urllibimport sysdef schedule(a, b, c): per = 100.0 * a * b / c per = int(per) sys.stderr.write("\rDownload percentage %.2f%%" % per) sys.stderr.flush()url = "http://download.tensorflow.org/models/vgg_16_2016_08_28.tar.gz"fetch = urllib.urlretrieve(url, "./vgg_16.tar.gz", schedule)
import sys
def schedule(a, b, c):
per = 100.0 * a * b / c
per = int(per)
sys.stderr.write("\rDownload percentage %.2f%%" % per)
sys.stderr.flush()
url = "http://download.tensorflow.org/models/vgg_16_2016_08_28.tar.gz"
fetch = urllib.urlretrieve(url, "./vgg_16.tar.gz", schedule)
解压下载的压缩文件
import tarfilewith tarfile.open("./vgg_16.tar.gz", "r:gz") as f: file_names = f.getnames() for file_name in file_names: f.extract(file_name, "./")
with tarfile.open("./vgg_16.tar.gz", "r:gz") as f:
file_names = f.getnames()
for file_name in file_names:
f.extract(file_name, "./")
保存模型为checkpoint格式
import tensorflow.contrib.slim as slimfrom tensorflow.contrib.slim.nets import vggimport tensorflow as tfimport numpywith tf.Session() as sess: inputs = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 3], name="inputs") logits, endpoint = vgg.vgg_16(inputs, num_classes=1000, is_training=False) load_model = slim.assign_from_checkpoint_fn("vgg_16.ckpt", slim.get_model_variables("vgg_16")) load_model(sess)as slim
from tensorflow.contrib.slim.nets import vgg
import tensorflow as tf
import numpy
with tf.Session() as sess:
inputs = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 3], name="inputs")
logits, endpoint = vgg.vgg_16(inputs, num_classes=1000, is_training=False)
load_model = slim.assign_from_checkpoint_fn("vgg_16.ckpt", slim.get_model_variables("vgg_16"))
load_model(sess)
numpy.random.seed(13) data = numpy.random.rand(5, 224, 224, 3) input_tensor = sess.graph.get_tensor_by_name("inputs:0") output_tensor = sess.graph.get_tensor_by_name("vgg_16/fc8/squeezed:0") result = sess.run([output_tensor], {input_tensor:data}) numpy.save("tensorflow.npy", numpy.array(result))
data = numpy.random.rand(5, 224, 224, 3)
input_tensor = sess.graph.get_tensor_by_name("inputs:0")
output_tensor = sess.graph.get_tensor_by_name("vgg_16/fc8/squeezed:0")
result = sess.run([output_tensor], {input_tensor:data})
numpy.save("tensorflow.npy", numpy.array(result))
saver = tf.train.Saver() saver.save(sess, "./checkpoint/model")"./checkpoint/model")TensorFlow2fluid目前支持checkpoint格式的模型或者是将网络结构和参数序列化的pb格式模型,上面下载的vgg_16.ckpt仅仅存储了模型参数,因此我们需要重新加载参数,并将网络结构和参数一起保存为checkpoint模型。
将模型转换为飞桨模型
import tf2fluid.convert as convertimport argparseparser = convert._get_parser()parser.meta_file = "checkpoint/model.meta"parser.ckpt_dir = "checkpoint"parser.in_nodes = ["inputs"]parser.input_shape = ["None,224,224,3"]parser.output_nodes = ["vgg_16/fc8/squeezed"]parser.use_cuda = "True"parser.input_format = "NHWC"parser.save_dir = "paddle_model"convert.run(parser)as convert
import argparse
parser = convert._get_parser()
parser.meta_file = "checkpoint/model.meta"
parser.ckpt_dir = "checkpoint"
parser.in_nodes = ["inputs"]
parser.input_shape = ["None,224,224,3"]
parser.output_nodes = ["vgg_16/fc8/squeezed"]
parser.use_cuda = "True"
parser.input_format = "NHWC"
parser.save_dir = "paddle_model"
convert.run(parser)
注意:部分OP在转换时,需要将参数写入文件;或者是运行tensorflow模型进行infer,获取tensor值。两种情况下均会消耗一定的时间用于IO或计算,对于后一种情况,
打印输出log信息(截取部分)
INFO:root:Loading tensorflow model...INFO:tensorflow:Restoring parameters from checkpoint/modelINFO:tensorflow:Restoring parameters from checkpoint/modelINFO:root:Tensorflow model loaded!INFO:root:TotalNum:86,TraslatedNum:1,CurrentNode:inputsINFO:root:TotalNum:86,TraslatedNum:2,CurrentNode:vgg_16/conv1/conv1_1/weightsINFO:root:TotalNum:86,TraslatedNum:3,CurrentNode:vgg_16/conv1/conv1_1/biasesINFO:root:TotalNum:86,TraslatedNum:4,CurrentNode:vgg_16/conv1/conv1_2/weightsINFO:root:TotalNum:86,TraslatedNum:5,CurrentNode:vgg_16/conv1/conv1_2/biases...INFO:root:TotalNum:86,TraslatedNum:10,CurrentNode:vgg_16/conv3/conv3_1/weightsINFO:root:TotalNum:86,TraslatedNum:11,CurrentNode:vgg_16/conv3/conv3_1/biasesINFO:root:TotalNum:86,TraslatedNum:12,CurrentNode:vgg_16/conv3/conv3_2/weightsINFO:root:TotalNum:86,TraslatedNum:13,CurrentNode:vgg_16/conv3/conv3_2/biasesINFO:root:TotalNum:86,TraslatedNum:85,CurrentNode:vgg_16/fc8/BiasAddINFO:root:TotalNum:86,TraslatedNum:86,CurrentNode:vgg_16/fc8/squeezedINFO:root:Model translated!from checkpoint/model
INFO:tensorflow:Restoring parameters from checkpoint/model
INFO:root:Tensorflow model loaded!
INFO:root:TotalNum:86,TraslatedNum:1,CurrentNode:inputs
INFO:root:TotalNum:86,TraslatedNum:2,CurrentNode:vgg_16/conv1/conv1_1/weights
INFO:root:TotalNum:86,TraslatedNum:3,CurrentNode:vgg_16/conv1/conv1_1/biases
INFO:root:TotalNum:86,TraslatedNum:4,CurrentNode:vgg_16/conv1/conv1_2/weights
INFO:root:TotalNum:86,TraslatedNum:5,CurrentNode:vgg_16/conv1/conv1_2/biases
...
INFO:root:TotalNum:86,TraslatedNum:10,CurrentNode:vgg_16/conv3/conv3_1/weights
INFO:root:TotalNum:86,TraslatedNum:11,CurrentNode:vgg_16/conv3/conv3_1/biases
INFO:root:TotalNum:86,TraslatedNum:12,CurrentNode:vgg_16/conv3/conv3_2/weights
INFO:root:TotalNum:86,TraslatedNum:13,CurrentNode:vgg_16/conv3/conv3_2/biases
INFO:root:TotalNum:86,TraslatedNum:85,CurrentNode:vgg_16/fc8/BiasAdd
INFO:root:TotalNum:86,TraslatedNum:86,CurrentNode:vgg_16/fc8/squeezed
INFO:root:Model translated!
到这一步,我们已经把tensorflow/models下的vgg16模型转换成了Paddle Fluid 模型,转换后的模型与原模型的精度有损失吗?如何预测呢?来看下面。
预测结果差异
加载转换后的飞桨模型,并进行预测
上一步转换后的模型目录命名为“paddle_model”,在这里我们通过ml.ModelLoader把模型加载进来,注意转换后的飞桨模型的输出格式由NHWC转换为NCHW,所以我们需要对输入数据做一个转置。处理好数据后,即可通过model.inference来进行预测了。具体代码如下:
import numpyimport tf2fluid.model_loader as mlmodel = ml.ModelLoader("paddle_model", use_cuda=False)numpy.random.seed(13)data = numpy.random.rand(5, 224, 224, 3).astype("float32")# NHWC -> NCHWdata = numpy.transpose(data, (0, 3, 1, 2))results = model.inference(feed_dict={model.inputs[0]:data})numpy.save("paddle.npy", numpy.array(results))
import tf2fluid.model_loader as ml
model = ml.ModelLoader("paddle_model", use_cuda=False)
numpy.random.seed(13)
data = numpy.random.rand(5, 224, 224, 3).astype("float32")
# NHWC -> NCHW
data = numpy.transpose(data, (0, 3, 1, 2))
results = model.inference(feed_dict={model.inputs[0]:data})
numpy.save("paddle.npy", numpy.array(results))
对比模型损失
转换模型有一个问题始终避免不了,就是损失,从Tesorflow的模型转换为Paddle Fluid模型,如果模型的精度损失过大,那么转换模型实际上是没有意义的,只有损失的精度在我们可接受的范围内,模型转换才能被实际应用。在这里可以通过把两个模型文件加载进来后,通过numpy.fabs来求两个模型结果的差异。
import numpypaddle_result = numpy.load("paddle.npy")tensorflow_result = numpy.load("tensorflow.npy")diff = numpy.fabs(paddle_result - tensorflow_result)print(numpy.max(diff))
paddle_result = numpy.load("paddle.npy")
tensorflow_result = numpy.load("tensorflow.npy")
diff = numpy.fabs(paddle_result - tensorflow_result)
print(numpy.max(diff))
打印输出
6.67572e-06
从结果中可以看到,两个模型文件的差异很小,为6.67572e-06 ,几乎可以忽略不计,所以这次转换的模型是可以直接应用的。
需要注意的点
-
转换后的模型需要注意输入格式,飞桨中输入格式需为NCHW格式。
此例中不涉及到输入中间层,如卷积层的输出,需要了解的是飞桨中的卷积层输出,卷积核的shape与TensorFlow有差异。
-
模型转换完后,检查转换前后模型的diff,需要测试得到的最大diff是否满足转换需求。
总结
X2Paddle提供了一个非常方便的转换方式,让大家可以直接将训练好的模型转换成Paddle Fluid版本。
转换模型原先需要直接通过API对照表来重新实现代码。但是在实际生产过程中这么操作是很麻烦的,甚至还要进行二次开发。
如果有新的框架能轻松转换模型,迅速运行调试,迭代出结果,何乐而不为呢?
虽然飞桨相比其他AI平台上线较晚,但是凭借X2Paddle小工具,能快速将AI开发者吸引到自己的平台上来,后续的优势将愈加明显。
除了本文提到的tensoflow2fluid,Paddle Fluid还支持caffe2fluid、onnx2fluid,大家可以根据自身的需求体验一下,有问题可以留言交流~
参考资料:
-
X2Paddle Github:https://github.com/PaddlePaddle/X2Paddle
-
tensorflow2fluid: https://github.com/PaddlePaddle/X2Paddle/tree/master/tensorflow2fluid
-