《Proximal Policy Optimization Algorithms》--强化学习论文笔记
原文链接
Markdown公式速写
1. policy gradient 从on policy到 off policy
policy gradient:
- 更新过程:actor与环境互动,生成轨迹 τ \tau τ, 之后按照梯度上升的方式更新policy network的参数。
- 问题:虽然使用相同轨迹执行多步优化看上去很秀,但是这样操作并不合理,实验证明它通常会导致破坏性的大策略更新
(感觉我的毕设是不是也存在这个问题???????) - 分析:按照公式,数据应该是从现在的policy θ \theta θ 的分布中采样出来,然而当每次结束一回合,更新了参数之后,原本的 θ \theta θ已经发生变化,原有采样出的数据就不能再使用了,需要重新获取数据,因此生成数据需要耗费大量的时间。
- 改进:使用另外的policy θ ′ \theta' θ′ 来与环境交互生成数据,来训练 θ \theta θ(数据可以多次用来做梯度上升更新网络)
2. importance sampling
E x ∼ p [ f ( x ) ] ≈ 1 N ∑ i = 1 N f ( x i ) E_{x\sim p}[f(x)]\approx\frac{1}{N}\sum_{i=1}^Nf(x^i) Ex∼p[f(x)]≈N1i=1∑Nf(xi)
从 p p p的分布中采样x,代入到f(x)中,计算f(x)的期望值, 其中 x i x^i xi是从 p ( x ) p(x) p(x)中采样得到的。
问题:如果现在无法从 p ( x ) p(x) p(x)中采样到 x x x, 只有从另一个分布 q ( x ) q(x) q(x)中采样的数据 x i x^i xi,该如何计算原目标表达式?
E x ∼ p [ f ( x ) ] = ∫ f ( x ) p ( x ) d x = ∫ f ( x ) p ( x ) q ( x ) q ( x ) d x = E x ∼ q [ f ( x ) p ( x ) q ( x ) ] E_{x\sim p}[f(x)]= \int f(x)p(x)dx =\int f(x)\frac{p(x)}{q(x)}q(x)dx =E_{x\sim q}[f(x)\frac{p(x)}{q(x)}] Ex∼p[f(x)]=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)q(x)p(x)]
按照上式,理论上来说,可以用另一个随机分布 q ( x ) q(x) q(x)替换 p ( x ) p(x) p(x)
但是, E x ∼ p [ f ( x ) ] = E x ∼ q [ f ( x ) p ( x ) q ( x ) ] E_{x\sim p}[f(x)]=E_{x\sim q}[f(x)\frac{p(x)}{q(x)}] Ex∼p[f(x)]=Ex∼q[f(x)q(x)p(x)]
V a r x ∼ p [ f ( x ) ] ≠ V a r x ∼ q [ f ( x ) p ( x ) q ( x ) ] Var_{x\sim p}[f(x)]\neq Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}] Varx∼p[f(x)]=Varx∼q[f(x)q(x)p(x)]
根据 V a r [ X ] = E [ X 2 ] − ( E [ X ] ) 2 Var[X]=E[X^2]-(E[X])^2 Var[X]=E[X2]−(E[X])2可得,
V a r x ∼ q [ f ( x ) p ( x ) q ( x ) ] = E x ∼ q [ ( f ( x ) p ( x ) q ( x ) ) 2 ] − ( E x ∼ q [ f ( x ) p ( x ) q ( x ) ] ) 2 = E x ∼ p [ f ( x ) 2 p ( x ) q ( x ) ] − ( E x ∼ p [ f ( x ) ] ) 2 Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}]=E_{x\sim q}[(f(x)\frac{p(x)}{q(x)})^2]-(E_{x\sim q}[f(x)\frac{p(x)}{q(x)}])^2=E_{x\sim p}[f(x)^2\frac{p(x)}{q(x)}]-(E_{x\sim p}[f(x)])^2 Varx∼q[f(x)q(x)p(x)]=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2=Ex∼p[f(x)2q(x)p(x)]−(Ex∼p[f(x)])2
综上
V a r x ∼ p [ f ( x ) ] = E x ∼ p [ f ( x ) 2 ] − E x ∼ p ( [ f ( x ) ] ) 2 ( 1 ) Var_{x\sim p}[f(x)]=E_{x\sim p}[f(x)^2]-E_{x\sim p}([f(x)])^2\color{blue}(1) Varx∼p[f(x)]=Ex∼p[f(x)2]−Ex∼p([f(x)])2(1)
V a r x ∼ q [ f ( x ) p ( x ) q ( x ) ] = E x ∼ p [ f ( x ) 2 p ( x ) q ( x ) ] − ( E x ∼ p [ f ( x ) ] ) 2 ( 2 ) Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}]=E_{x\sim p}[f(x)^2{\color{red}\frac{p(x)}{q(x)}}]-(E_{x\sim p}[f(x)])^2\color{blue}(2) Varx∼q[f(x)q(x)p(x)]=Ex∼p[f(x)2q(x)p(x)]−(Ex∼p[f(x)])2(2)
比较两式可得,(2)中等号后第一项在结构上多了 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x),
理论上,对 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x)采样足够多次,得到的期望的值是一样的,但是如果采样的数据不够多, p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x)差距又很大的话,因为方差的差距会很大,那么得到的期望值会有非常大的差距。
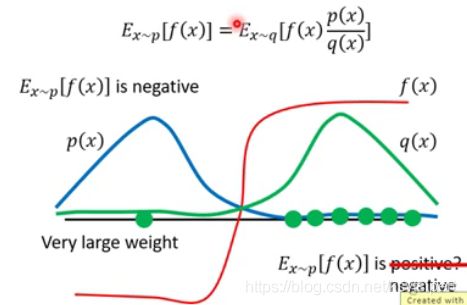
如图,假设我们通过 q ( x ) q(x) q(x)中采样的数据来计算 p p p分布中的 E [ f ( x ) ] E[f(x)] E[f(x)], p ( x ) p(x) p(x)、 q ( x ) q(x) q(x)和 f ( x ) f(x) f(x)的曲线如图所示,假设交点对应的点为 ( 0 , 0 ) (0,0) (0,0)点,由图像可知,在 p ( x ) p(x) p(x)中采样得到的数据绝大多数 f ( x ) f(x) f(x)为负值, E [ f ( x ) ] E[f(x)] E[f(x)]为负值,而在 q ( x ) q(x) q(x)中采样时,如果只采样较少数据,极大概率值只能采样到如图右边绿色圆点所示( q ( x ) q(x) q(x)中数据集中区)的数据,由此计算出的期望必定为正值,结果与实际不符,只有当采样足够多的数据时,才可能采样到 q ( x ) q(x) q(x)左侧的数据,得到 f ( x ) f(x) f(x)为负的情况,而此时,这一项会乘以 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x)这一很大的权重,才能平衡到大量采样到期望为正的数据的计算结果,使得最终结果与 p ( x ) p(x) p(x)分布中的期望逼近。
3. PPO/TRPO
由1,2,policy gradient可实现on policy ->off policy的转化
即 ∇ R θ ‾ = E τ ∼ p θ ( τ ) [ R ( τ ) ∇ l o g p θ ( τ ) ] ⇒ ∇ R θ ‾ = E τ ∼ p θ ′ ( τ ) [ p θ ( τ ) p θ ′ ( τ ) R ( τ ) ∇ l o g p θ ( τ ) ] \nabla\overline {R_\theta} = E_{\color{red}\tau \sim p_\theta(\tau)} [R(\tau)\nabla logp_\theta(\tau)]\Rightarrow\nabla\overline {R_\theta} = E_{\color{red}\tau \sim p_{\theta'}(\tau)} [{\color{red}\frac{p_\theta(\tau)}{p_{\theta'}(\tau)}}R(\tau)\nabla logp_\theta(\tau)] ∇Rθ=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]⇒∇Rθ=Eτ∼pθ′(τ)[pθ′(τ)pθ(τ)R(τ)∇logpθ(τ)]
θ ′ \theta' θ′用来与环境交互采样数据,示范给 θ \theta θ, θ \theta θ可以更新参数很多次,数据可以重复利用。
又在policy gradient中,更新参数时,每一步使用相同的 R ( τ ) R(\tau) R(τ)是不合理的,应该使用从当前动作到最终动作的 [accumulated reward-baseline] 作为此动作的收益,即Advantage function的思想,可以表示为:
gradient for update
= E ( s t , a t ) ∼ π θ [ A θ ( s t , a t ) ∇ l o g p θ ( a t n ∣ s t n ) ] = E_ {(s_t,a_t){ \sim \pi_\theta}} [A^\theta(s_t,a_t)\nabla logp_\theta(a^n_t|s^n_t)] =E(st,at)∼πθ[Aθ(st,at)∇logpθ(atn∣stn)]
= E ( s t , a t ) ∼ π θ ′ [ P θ ( s t , a t ) P θ ′ ( s t , a t ) A θ ′ ( s t , a t ) ∇ l o g p θ ( a t n ∣ s t n ) ] = E_ {(s_t,a_t){ \sim \pi_{\theta'}}} [\frac{P_\theta(s_t,a_t)}{P_{\theta'}(s_t,a_t)}{\color{blue}A^{\theta'}(s_t,a_t)}\nabla logp_\theta(a^n_t|s^n_t)] =E(st,at)∼πθ′[Pθ′(st,at)Pθ(st,at)Aθ′(st,at)∇logpθ(atn∣stn)]
= E ( s t , a t ) ∼ π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) p θ ( s t ) p θ ′ ( s t ) A θ ′ ( s t , a t ) ∇ l o g p θ ( a t n ∣ s t n ) ] =E_ {(s_t,a_t){ \sim \pi_{\theta'}}} [\frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)}\frac{p_\theta(s_t)}{p_{\theta'}(s_t)} A^{\theta'}(s_t,a_t)\nabla logp_\theta(a^n_t|s^n_t)] =E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)pθ′(st)pθ(st)Aθ′(st,at)∇logpθ(atn∣stn)]
p θ ( s t ) {p_\theta(s_t)} pθ(st)和 p θ ′ ( s t ) {p_{\theta'}(s_t)} pθ′(st)看是一样的(环境因素),此项可消去
综上,由 ∇ f ( x ) = f ( x ) ∇ l o g f ( x ) \nabla f(x)=f(x)\nabla logf(x) ∇f(x)=f(x)∇logf(x)得: J θ ′ ( θ ) = E ( s t , a t ) ∼ π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) ] J^{\theta'}(\theta)=E_ {(s_t,a_t){ \sim \pi_{\theta'}}} [\frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)] Jθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
如何避免 p ( θ ) p(\theta) p(θ)和 p ( θ ′ ) p(\theta') p(θ′)相差过大,即是PPO/TRPO完成的事情 -----【add constraint】
Proximal Policy Optimization(PPO):
J P P O θ ′ ( θ ) = J θ ′ ( θ ) − β K L ( θ , θ ′ ) J^{\theta'}_{PPO}(\theta)=J^{\theta'}(\theta)-\beta KL(\theta,\theta') JPPOθ′(θ)=Jθ′(θ)−βKL(θ,θ′)
-------KL散度放在了梯度的表达式中,易操作
Trust Region Policy Optimization(TRPO):
J T R P O θ ′ ( θ ) = E ( s t , a t ) ∼ π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) ] J^{\theta'}_{TRPO}(\theta)=E_ {(s_t,a_t){ \sim \pi_{\theta'}}} [\frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t,a_t)] JTRPOθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
----------- K L ( θ , θ ′ ) < δ KL(\theta,\theta')<\delta KL(θ,θ′)<δ作为额外约束条件,难算
两者的差距不是提现在参数本身的差距,而是behavior distance: 给定相同的state, 得到的action的距离(网络得到的action的概率分布)不能相差太多。得到action的概率分布的相似程度,用KL散度来计算,将KL divergence(KL散度)作为PPO的似然函数的一部分,如下节。
4. PPO算法
- initial policy parameters θ 0 \theta^0 θ0
- in each iteration:
- using θ k \theta^k θk to interact with env to collect { s t , a t s_t,a_t st,at} and compute A θ k ( s t , a t ) A^{\theta^k}(s_t,a_t) Aθk(st,at)
- find θ \theta θ optimizing J P P O ( θ ) J_{PPO}(\theta) JPPO(θ)
J P P O θ k ( θ ) = J θ k ( θ ) − β K L ( θ , θ k ) J^{\theta^k}_{PPO}(\theta)=J^{\theta^k}(\theta)-\color{blue}\beta KL(\theta,\theta^k) JPPOθk(θ)=Jθk(θ)−βKL(θ,θk) - if K L ( θ , θ k ) > K L m a x , i n c r e a s e β KL(\theta,\theta^k)>KL_{max}, increase \beta KL(θ,θk)>KLmax,increaseβ
- if K L ( θ , θ k ) < K L m i n , d e c r e a s e β − − a d a p t i v e K L p e n a l t y KL(\theta,\theta^k)
PPO2
PPO的另一种实现方法,通过clip裁剪,约束两个分布之间的相似性。
J P P O 2 θ k ( θ ) ≈ ∑ ( s t , a t ) m i n ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) A θ k ( s t , a t ) , c l i p ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , 1 − ε , 1 + ε ) A θ k ( s t , a t ) ) J^{\theta^k}_{PPO2}(\theta)\approx \sum_{(s_t,a_t)}min( \frac{p_\theta(a_t|s_t)}{p_{\theta^k}(a_t|s_t)}A^{\theta^k}(s_t,a_t),clip(\frac{p_\theta(a_t|s_t)}{p_{\theta^k}(a_t|s_t)},1-\varepsilon,1+\varepsilon)A^{\theta^k}(s_t,a_t)) JPPO2θk(θ)≈(st,at)∑min(pθk(at∣st)pθ(at∣st)Aθk(st,at),clip(pθk(at∣st)pθ(at∣st),1−ε,1+ε)Aθk(st,at))
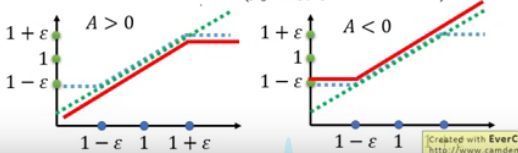
A>0时,必然要增加 p θ ( a t , s t ) p_\theta(a_t,s_t) pθ(at,st), update参数直到 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) \frac{p_\theta(a_t|s_t)}{p_{\theta^k}(a_t|s_t)} pθk(at∣st)pθ(at∣st)超出临界值 1 + ε 1+\varepsilon 1+ε为止,控制 θ \theta θ与 θ k \theta^k θk不能相差过多。
A<0时同理。
OpenAI给出的PPO算法伪代码:

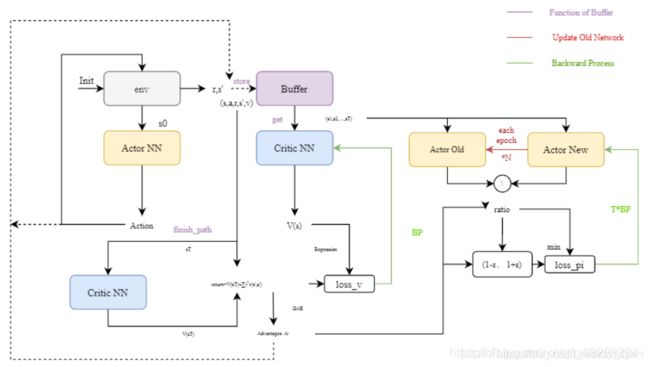
流程图: