视频运动放大系列(1)- Motion Magnification 2005
撰写内容基于原始论文和公开代码,若有不正确之处,欢迎各位留言指正!
本文解读Ce Liu 等人在 ACM SIGGRAPH 2005 展示的视频运动放大技术,该技术首先使用流体力学的拉格朗日运动方法分析了视频中K个物体的运动轨迹,并根据各运动轨迹分割出K个运动层,再设定具体的放大倍率对指定物体沿着运动轨迹施加放大位移,最后合成运动放大视频。Ce Liu等人将很大一部分工作都花费在运动物体上的分割上,相较如今主流的深度学习技术,当时使用经典的特征点跟踪和基于能量最小化的图像分割方式实现运动物体层的分类。
先通过图1直观感受运动放大的效果,由图1可知出秋千横梁运动形变最明显,借此可分析横梁的结构动力特征,这正是视频运动放大的意义之一。
 图1:运动放大效果图
图1:运动放大效果图
接着结合图2介绍Ce Liu 等人开发算法的整体框架,并根据原文的理解对框架内每一个小步骤进行总结概括,以方便读者从整体上了解该算法。如图2所示,每一小步骤分别为:
(a)寻找视频的参考帧的背景层“静态”特征点,聚合“静态”特征点的“静态”轨迹,消除由相机抖动带来的微小运动;
(b)聚合视频中所有运动物体特征点的运动轨迹;
(c)将(b)的运动轨迹与运动物体相匹配,并根据运动物体的运动轨迹和外观划分"物体层";
(d)设置放大倍率,对选中的“物体层”进行运动放大,其中“showing holes”指的是运动放大后,图像缺失的部分,即灰度为全黑的像素部分;
(e)根据背景层的纹理,对“showing holes”进行填充;
(f)对(c)中分割出物体层进行手动调整,补齐物体层缺失的小部分像素,并重新对(e)图像渲染;
补充对背景层和物体层的理解,比方在刷墙的时候,我们总是先完成背景部分的绘画,再绘制主体部分内容,由于视频运动放大技术涉及物体分割、运动物体放大和对放大物体的合成渲染,那么将背景和物体理解为“层”是件自然的事情。
 图2:整体算法框架
图2:整体算法框架
梳理完算法的整体框架后,逐一分析(a)~(f)步骤的具体实现。步骤(a)在原论文中被称为“Robust Video Registration”,目的是消除由相机不自觉地抖动引入的微小运动。(a)步骤实现流程如图3所示。通过计算像素块间的平方差之和检测参考帧(第一帧)背景的Harris角点,其表达式为:
![]()
由于Harris角点仅有旋转不变性,不具有尺度不变性,再对图像进行高斯金字塔分解,通过多张分解图像同一角点筛选出具有尺度不变性的Harris角点,即多尺度Harris角点。接着使用最小平方和误差(Minimum sum of squared different,SSD)计算参考帧特征点与其余帧特征点的整像素位移,再通过局部LK光流法(Local Lucas-Kanade algorithm)在整像素位移上搜索亚像素位移,获得参考帧背景的多尺度Harris角点与其余帧之间的精确位移。
为最大限度准确获取背景的“静态”轨迹,进一步从全部背景特征点中筛选出“稳定”的背景特征点,假设从共有 个特征点贯穿于
个特征点贯穿于 帧图像,将第
帧图像,将第![]() 帧的第
帧的第![]() 个特征点记为
个特征点记为![]() ,坐标为
,坐标为![]() ,
,![]() 从参考帧到第k帧的位移为
从参考帧到第k帧的位移为![]() 。由参考帧到第K帧图像的特征点局部匹配质量加权估计背景的全局仿射运动
。由参考帧到第K帧图像的特征点局部匹配质量加权估计背景的全局仿射运动![]() ,特征点
,特征点![]() 归属轨迹
归属轨迹![]() 的概率为:
的概率为:
其中,方差![]() 是由平均重建误差(Mean reconstruction error)估计的:
是由平均重建误差(Mean reconstruction error)估计的:
![\LARGE \sigma _{k}=\frac{1}{n}\sum_{n}^{} \left \| A_{k}\left [ x_{nk}\: y_{nk} \: 1\right ]^{\top }-\left [ v_{nk}^{x}\: y_{nk}^{x} \right ] \right \|^{2}](http://img.e-com-net.com/image/info8/4e47c22668924f91957f233eacc77bc3.gif)
将相机抖动视为随机噪声,特征点n对全部帧的全局仿射运动概率为每帧全局仿射运动概率相乘:
![]()
最终,根据公式![]() 从全部特征点中筛选稳定的背景特征点,然后为稳定的背景特征点重新由SSD匹配和局部LK光流计算参考帧到其余帧的位移,并计算稳定背景特征点在每帧的全局仿射运动
从全部特征点中筛选稳定的背景特征点,然后为稳定的背景特征点重新由SSD匹配和局部LK光流计算参考帧到其余帧的位移,并计算稳定背景特征点在每帧的全局仿射运动![]() ,全局仿射运动
,全局仿射运动![]() 就是稳定背景特征点的轨迹。
就是稳定背景特征点的轨迹。
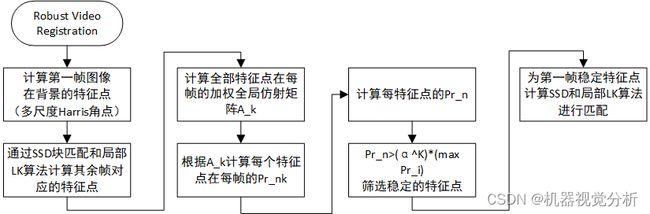 图3:稳定背景特征点提取流程图
图3:稳定背景特征点提取流程图
步骤(b)中,首先使用期望最大化(Expectation Maximization,EM)算法计算每个特征点窗口的权重图,并根据权重图实现加权SSD块匹配,目的是在遮挡边界附近实现可靠的匹配。如图4所示,EM算法在“E”步和"M"步之间交替进行,先通过“E”步计算特征点窗口权重,再通过“M”步根据权重图执行SSD块匹配和局部LK光流算法计算特征点位移,接着返回“E”步重复迭代至满足收敛条件。
 图4:EM算法示意图
图4:EM算法示意图
在执行“E”步计算特征点窗口权重值之前,先计算第n个特征点在第k帧的先验概率:
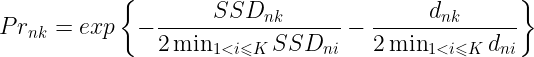
其中![]() 是第k帧与参考帧在的第n个特征点的SSD值,
是第k帧与参考帧在的第n个特征点的SSD值,![]() 是第k帧的第n个特征点距离处N个最近特征点的平均距离。由图5轨迹3示意和上述公式可知,第n个特征点在第k帧中必须满足SSD误差尽量小且不是运动轨迹的离群值才能归为可靠的特征点。
是第k帧的第n个特征点距离处N个最近特征点的平均距离。由图5轨迹3示意和上述公式可知,第n个特征点在第k帧中必须满足SSD误差尽量小且不是运动轨迹的离群值才能归为可靠的特征点。
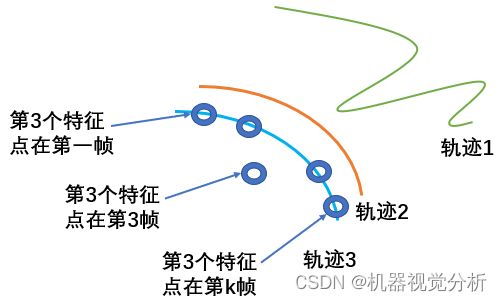 图5:特征点运动轨迹示意图
图5:特征点运动轨迹示意图
得到第n个特征点在第k帧的先验概率后,通过平均重建误差计算权重图:
其中![]() 是在第k帧的第n个特征点周围尺寸为2w*2w的窗口,而
是在第k帧的第n个特征点周围尺寸为2w*2w的窗口,而![]() 是
是![]() 中的相关坐标点,
中的相关坐标点,![]() 是第n个特征点在
是第n个特征点在![]() 的平均方差,
的平均方差,![]() 。
。
获取权重图后,执行“M”步骤,即根据权重图执行SSD块匹配和局部LK光流计算准确位移。根据原论文介绍,在经过10次左右的EM迭代后,大多数特征点收敛到可靠的位移估计,然而还存在在不稳定的特征点,必须对其进行修剪,修建标准分别为:
(1)通过设置SSD匹配阈值除去仅出现在第一帧的特征点的轨迹;
(2)取第n个特征点轨迹上的平均先验概率作为轨迹度量距离,若该度量距离低于一组轨迹中全部特征点先验概率的30%,则将轨迹n去除,如图5所示轨迹1明显不是和轨迹2,3一组,故删去;
(3)根据Pr_nk去除第n个特征点在第k帧的跟踪点并根据轨迹n的整体变化趋势平滑该点,如图5的轨迹3所示;
前两个标准在EM算法前后都执行,第三个标准在EM算法后执行。完成对每个特征点的跟踪后,对相关特征点轨迹聚类分组,形成为运动物体层分割的基础,通过运动可以将不同外观或没有空间连续性的区域进行分组,聚类的目标是将具有共同运动特征轨迹分为一组,即使在运动方向可能不同,使用相关指数![]() 度量特征点n、m轨迹的相似性:
度量特征点n、m轨迹的相似性:
使用相关指数的归一化相关性,对所有特征点轨迹构建相似矩阵,并将![]() 小于0.9的轨迹及周围共5个特征点的轨迹丢弃,然后再使用谱聚类将所有特征点轨迹分为K组。从每组的特征轨迹中,原论文试图在所有像素上插值一个密集的光流场,将每个像素分配到一个运动组,以形成运动物体层表示。由于跟踪的对象可以是非刚性的,使用局部加权线性回归插值计算每一像素点的仿射运动,为了加快计算速度,将每隔四个像素点使用上述插值方法计算位移,再采用双三次插值得到所有像素点的全场密集光流,并使用
小于0.9的轨迹及周围共5个特征点的轨迹丢弃,然后再使用谱聚类将所有特征点轨迹分为K组。从每组的特征轨迹中,原论文试图在所有像素上插值一个密集的光流场,将每个像素分配到一个运动组,以形成运动物体层表示。由于跟踪的对象可以是非刚性的,使用局部加权线性回归插值计算每一像素点的仿射运动,为了加快计算速度,将每隔四个像素点使用上述插值方法计算位移,再采用双三次插值得到所有像素点的全场密集光流,并使用![]() 表示第i帧到第k帧中第l层的密集光流。最后,由图6总结步骤(b)的具体实现流程。
表示第i帧到第k帧中第l层的密集光流。最后,由图6总结步骤(b)的具体实现流程。
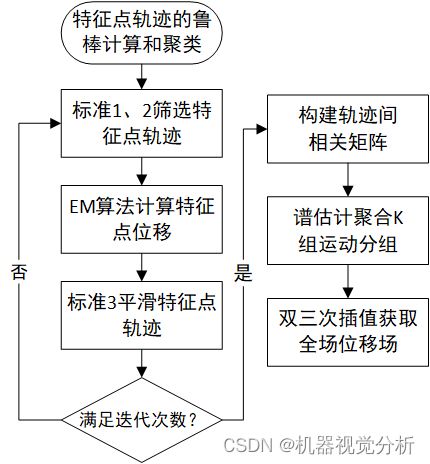 图6:步骤(b)流程图
图6:步骤(b)流程图
步骤(c)使用运动相似性、颜色相似性和空间一致性三种判断主线共同为图像每个像素分配运动层,其核心思想是为每条主线构造像素分组概率,再通过图切割优化的方法综合三种分组概率将每个像素点分配至某个运动层。首先根据运动相似性计算分组概率:

其中u是相邻帧数,![]() 是方差,将低概率的像素分配至离群层。
是方差,将低概率的像素分配至离群层。
然后采用高斯混合模型根据颜色相似性计算分组概率:
![]()
接着采用兼容函数支持像素点在空间不连续的地方改变分层:
最后采用图切割方法最小化由分组标签分配给像素点的总能量,最终实现每帧图像的运动层分割:
步骤(d)~(f)的实现将结合图7、8详细分析, 由于对每一帧执行最小能量分割,分配至每物体层像素点不稳定,会发生变化。为解决这个问题,将每帧分割好的像素与参考帧对比,借此将每帧像素投影回参考帧,投影回参考帧上的点在全部帧中具有80%的连续性(遮挡导致不连续),如图7(a)所示,注意此时参考帧的同一像素可能被分配至一个以上的运动物体层。由于运动放大会显示图7(c)中黑色的区域,对该区域使用纹理修复填补“黑洞”。最后,处理图中的异常值,例如在秋千上的人由于快速运动而未被跟踪从而被视为异常值,图8(b) 显示了不包括离群值的渲染序列的一帧,图 8(c) 显示了添加图 8(a) 的离群像素的最终渲染图像结果。总之,渲染序列的最终表示由N组层加上一个离群层(并不是必需的)组成。每个层都由一个分割掩膜(图 7(a))和其外观(图 7(d))定义。
 图7:步骤(d)~(f)的详细补充
图7:步骤(d)~(f)的详细补充
 图8:异常值修复
图8:异常值修复
虽然自动分割的效果很好,但仍不可避免地产生分割小错误导致合成视频中的伪影。为了解决这个问题,算法允许用户在参考帧上修改已分割好的层,如图7(d)所示。在图7(d)中,用户修改了第1层物体的分割外观,删除附加在遮阳篷上帆布上的像素、修补了梁上的黑孔、并补齐了秋千竖直梁下的后腿,如图7(e)所示。当用户选择好想放大的物体层后,归属于该层的每一像素位移都被乘上设定的放大因子,形成运动放大图像,原论文推荐放大因子为4至40。每个物体层的排序和异常值像素都可以手动分配,根据排序原论文从后到前渲染每个运动层的像素。通过本文讲解后,总结算法核心分为四大块,分别为视频背景“稳定”特征点轨迹提取、运动物体特征点轨迹提取及初步分层、根据运动,颜色和空间连续性对运动物体实行精确分割、用户干预分割层并放大指定运动物体。至此整个算法分析完毕,随文附上原论文下载地址,如果您喜欢本文麻烦多多评论转发!
http://people.csail.mit.edu/billf/publications/Motion_Magnification.pdf