本周的总结
目录
本周完成的计划
论文阅读1
ABSTRACT(摘要)
1 INTRODUCTION(介绍)
2 METHODOLOGY(方法)
Phase One (classification)
Phase Two (segmentation)
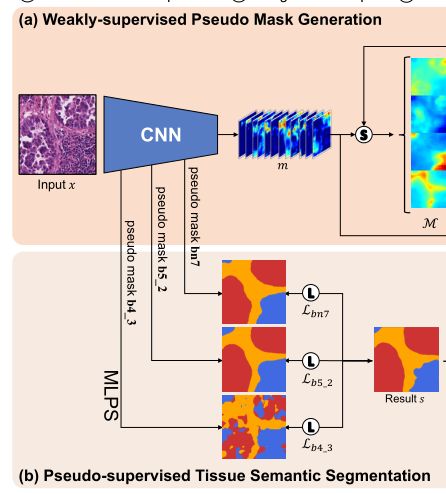
A. Weakly-supervised Pseudo Mask Generation(弱监督伪标签生成)
B. Pseudo-supervised Tissue Semantic Segmentation(伪监督组织分割)
3 EXPERIMENTS(实验)
4 CONCLUSION(结论)
论文阅读2
ABSTRACT(摘要)
1 INTRODUCTION(介绍)
2 Class Activation Mapping(类激活图)
Conclusion(结论)
Class Activate Map(类激活图)代码实现
CAM效果
本周工作总结
本周完成的计划
- 读弱监督论文《Multi-Layer Pseudo-Supervision for Histopathology Tissue Semantic Segmentation using Patch-level Classification Labels》
- 读论文《Learning Deep Features for Discriminative Localization》,主要是提出CAM
- 跑CAM(Class Activate Map)程序代码
- 参加线下第五届计算与数字医学国际研讨会
论文阅读1
Multi-Layer Pseudo-Supervision for Histopathology Tissue Semantic Segmentation using Patch-level Classification Labels(基于Patch级别分类标签的多层伪监督病理组织语义分割)
ABSTRACT(摘要)
组织级语义分割是计算病理学中至关重要的一步。全监督模型通过密集的像素级注释已经取得了优异的性能。然而,在千兆像素的整个幻灯片图像上绘制这样的标签是极其昂贵和耗时的。在本文中,我们只使用补丁级别的分类标签来实现对组织病理图像的组织语义分割,最终减少了标注的工作量。我们提出了一个包括分类和分割两个阶段的两步模型。在分类阶段,我们提出了一种基于CAM的模型,通过补丁级别的标签来生成伪掩模。在分割阶段,我们提出了多层伪监督算法,实现了组织语义的分割。为了缩小像素级和补丁级注释之间的信息差距,已经提出了几项技术创新。作为本文的一部分,我们介绍了一种新的肺腺癌弱监督语义分割(WSSS)数据集(LUAD-HistoSeg)。我们在两个数据集上进行了几个实验来评估我们提出的模型。我们提出的模型比两种最先进的WSSS方法性能更好。请注意,使用完全监督的模型,我们可以获得类似的定量和定性结果,MIUU和FwIoU的差距只有2%左右。与人工标注相比,我们的模型可以大大节省标注时间从小时到分钟不等。
1 INTRODUCTION(介绍)
肿瘤微环境(TME)不仅在肿瘤的发生发展中起着至关重要的作用,而且还影响着癌症患者的治疗效果和预后。TME由不同类型的组织组成,包括肿瘤上皮、肿瘤浸润淋巴细胞(TIL)、肿瘤相关间质等,已有研究证明它们与肿瘤进展密切相关。TIL被认为是许多实体肿瘤的预后生物标志物,如肺癌、乳腺癌和结直肠癌。而肿瘤上皮和肿瘤相关间质之间的串扰与肿瘤进展相关。因此,对不同类型的组织进行区分和分割,对TME的精确定量是至关重要的。

在这篇文章中,我们提出了一个简单而有效的CNN模型,用于组织病理组织的语义分割,只使用补丁级别的标注。病理学家只需要判断斑块中是否存在不同的组织类别,而不是在WSIS上仔细绘制组织的边界,这大大节省了注释时间。该模型的基本思想是利用patch级别的分类标签自动生成像素级的语义分割掩码,然后利用生成的伪掩码训练语义分割模型。
我们提出的模型包括分类阶段和分割阶段。在分类阶段,我们提出了一种基于CAM的伪掩码生成分类模型。为了避免区分区域缩小的问题,我们提出了一种渐进式丢弃注意力(PDA)来逐步去激活突出显示的区域,并推动分类网络根据非优势区域来区分组织类别。在分割阶段,我们利用多层分类网络生成的伪掩码训练一个语义分割模型,我们称之为多层伪监督(MLP)。MLP可以提供不同阶段的信息,以缩小补丁级标签和像素级标签之间的信息差距。由于长尾和分布不平衡的问题,一些训练样本较少的组织类别可能无法从伪掩模中学习到良好的特征表示,这容易导致假阳性分割结果。为了解决这个问题,我们提出了一种分类门机制来降低非优势组织类别的假阳性率。
本文的主要贡献概括如下:
- 提出了一种仅使用patch级分类标签的组织病理图像语义分割模型,大大节省了病理学家的标注时间。
- 提出了具有渐进式丢弃注意力机制的多层伪监督机制,以缩小patch级标签和像素级标签之间的信息差距。引入分类门机制,降低了误报率。
- 与弱监督语义分割模型相比,我们提出的模型在两个数据集上获得了最先进的性能,并且与完全监督基线的性能相当。
- 发布第一个LUAD数据集,用于弱监督组织语义分割。
2 METHODOLOGY(方法)
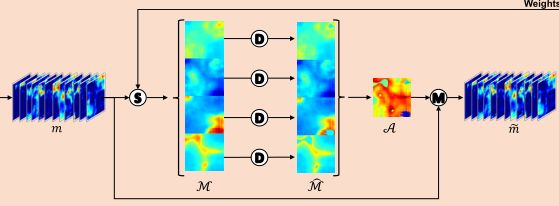
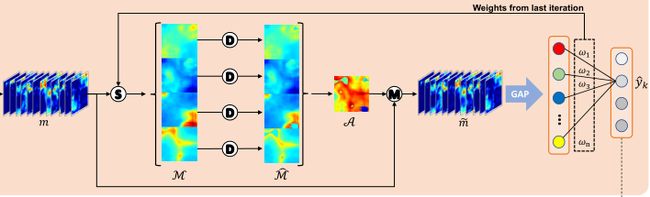
手动标注组织病理学图像的密集像素级label是极其困难和耗时的。为了减轻标注工作量,本文提出了一种仅使用补丁级别标签的组织语义分割模型。图2演示了我们提议的模型的系统设计。在A节中,我们使用我们提出的渐进式丢弃注意力训练了一个patch级别的多标签分类网络,以生成像素级的伪掩码。在B节中,我们提出了多层伪监督来训练语义分割模型。为了进一步指导分割结果,提出了一种分类门机制,以降低误报率。
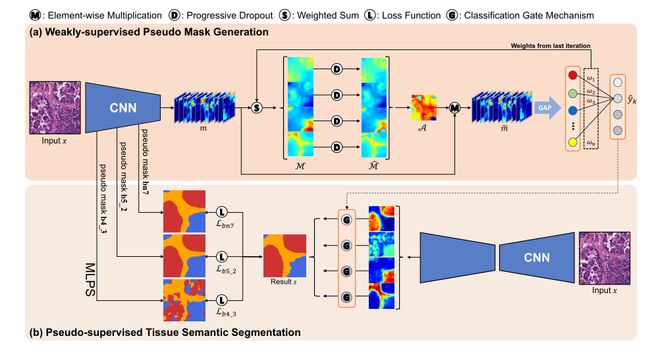
Phase One (classification)
这个阶段的目标是只使用补丁级别的标签来生成密集像素级的伪遮罩。提出了一种基于渐进式丢弃注意力(PDA)的弱监督模型,用于组织语义分割的多层伪掩码生成。
Phase Two (segmentation)
利用在分类阶段生成的伪掩码,我们可以形成用于分割模型的新的训练数据,在多层伪监督(MLP)的指导下,引入DeepLab V3+模型和分类门机制进行语义分割,生成最终分割结果。
A. Weakly-supervised Pseudo Mask Generation(弱监督伪标签生成)
对于千兆像素的整个WSI图像,定义patch中组织类的存在或不存在显然比仔细绘制像素级标注容易得多。因此,我们的目标是探索信息非常有限的patch级别的标注是否足以用于像素级的语义分割。Zhouet al.。已经证明分类、定位、检测和分割任务具有相似的目标。在训练分类模型时,特征映射(Class Activation Maps,CAM)提供可用于目标定位和分割的区别性目标位置线索。受此启发,我们通过首先训练分类模型,提出了一种新的基于CAM的模型。由于组织的分布具有某种程度的随机性和分散性,因此在一个补丁中可能包含多种组织类型。因此,我们将组织分类定义为一个多标签分类问题。
1)伪掩码生成:如图2(A)所示,给定一个输入片,我们首先提取深度特征图,如下所示:
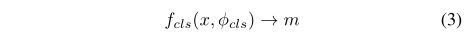
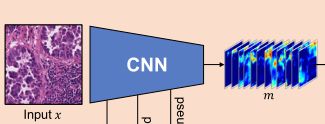
为了提供更丰富、更全面的特征表示,我们提出了渐进式丢弃注意力,如下图,以避免分类模型过于关注最具区分性的区域, A是注意力map。
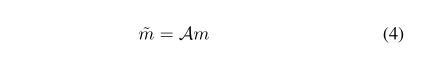
在渐进式丢弃注意力后,第k个组织类别![]() 的概率可以通过全局平均池和完全连接层来计算,其中GAP(·)表示全局平均池,在分类网络中应用了多标签软边缘损失。
的概率可以通过全局平均池和完全连接层来计算,其中GAP(·)表示全局平均池,在分类网络中应用了多标签软边缘损失。


在训练好的多标签分类模型的基础上,通过梯度加权类激活映射(Grad-CAM)生成像素级伪掩模,用于下一步的分割模型。
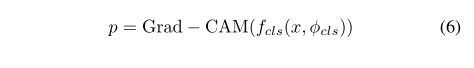
2) 渐进式丢弃注意力:虽然分类模型可以为分割任务提供空间位置提示。但这两项任务的目标仍然不同。随着训练过程的深入,常用的分类模型往往侧重于图像中最具区分性的部分/区域,而忽略了一些不重要的区域。激活区域收缩问题会影响分割任务。与自然图像相比,不同组织类型的空间排列具有较大的随机性,因此在肿瘤组织病理学图像中会被放大。此外,one hot 编码标签只包含非常有限的信息。从斑块级标签到像素级标签仍然存在巨大的信息鸿沟。因此,如何最大限度地发挥这种稀疏注释的价值,以缩小差距,仍然是一个极端的任务。为了克服以上两个挑战,我们提出了渐进式辍学注意(PDA)。让我们从它的基本形式开始,丢弃注意力机制。
Dropout Attention:
建议的丢弃注意机制的想法是简单而直观的。希望神经网络能够从稀疏标签中学习尽可能多的信息。在训练过程中,分类模式不允许仅靠最有辨别力的领域就能“轻松赚钱”。相反,CNN模型必须学习更完整、更全面的空间信息。因此,我们失活了所有组织类别的类激活图中最重要的区域,如图2(A)所示。该策略弱化了最具区分性区域的贡献,迫使神经网络对非优势区域进行多标签分类,在提取深层特征时可以有效地扩展激活区域。根据这一思想,我们首先通过特征映射的加权和为每个类别生成一个类激活映射(CAM)
![]()
 代表的是第k个类别的CAM图,对于我们设置了丢弃的截断值
代表的是第k个类别的CAM图,对于我们设置了丢弃的截断值 ,用来失活最突出显示的区域并刷新,
,用来失活最突出显示的区域并刷新,![]() 是使用了dropout的CAM,是一个相对值,取决于它取决于类激活映射的最大值,
是使用了dropout的CAM,是一个相对值,取决于它取决于类激活映射的最大值, 是dropout的相关系数。
是dropout的相关系数。
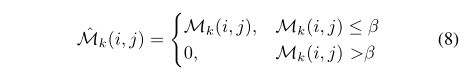
![]()
最后,Dropout注意图A是所有失活CAM的平均值
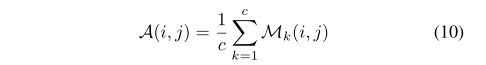
渐进式丢弃注意力:
正如我们上面提到的,当训练过程进一步进行时,激活的区域将逐渐缩小到更小的区域。根据这一观察结果,我们提出了一种基于丢弃注意力的反向操作,称为渐进式丢弃注意力(PDA)。PDA逐渐扩大失活区域,以应对这种不断缩小的问题。我们重新设计了原始的dropout系数变成一个渐进的dropout系数,它不再是一个恒定值,渐进式dropout系数µ将随着训练周期的增加而自适应地减小,直到µ达到下限。

通过渐进式丢弃注意,区分性区域收缩问题大大缓解,分类模型可以学习更丰富和更广泛的特征表示,并且可以生成更精确的伪掩码。

图4.渐进式丢弃注意力的例子。我们展示了在不同的训练时期,有(上排)和没有(下排)辍学的肿瘤相关间质区域的类激活图。失活区随训练次数的增加而扩大。(来自LUAD-HistoSeg的示例)
B. Pseudo-supervised Tissue Semantic Segmentation(伪监督组织分割)
在分割阶段,我们在伪掩码 的监督下训练一个语义分割模型
的监督下训练一个语义分割模型![]() ,得到输入patch
,得到输入patch  的语义分割结果
的语义分割结果

为了进一步提高该阶段的语义分割性能,提出了多层伪监督机制和分类门机制两种具体设计方案。
1) Multi-Layer Pseudo-Supervision(多层伪监督)
由于patch级标签和像素级标签之间存在信息鸿沟,即使在有渐进式丢弃注意力机制的情况下,从分类网络中学习到的空间信息仍然是不完整的。为了缩小差距,我们必须给分割模型带来更多的信息。由于CNN模型在不同的阶段学习不同层次的语义特征,我们从三个不同的层次生成多层伪掩码来丰富信息。然后计算语义分割结果与所有伪掩码之间的交叉熵损失。请注意,使用双线性插值将多层伪掩码上采样到原始图像分辨率, 是超参数,在实际实验时,我们将
是超参数,在实际实验时,我们将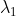 =0.2,
=0.2,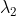 =0.2,
=0.2,![]() =0.6。
=0.6。
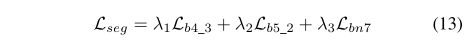
2) Classification Gate Mechanism(分类门机制)
长尾问题是医学数据,尤其是组织病理学图像中常见的问题。对于那些非优势组织类别,如坏死和淋巴细胞,它们将被优势组织类别主宰。非优势类比优势类更容易产生不令人满意的伪掩码,这可能会增加分割阶段的误报率(出现假阳性)。
为了克服长尾问题,降低非优势类别的误报率,我们提出了一种分类门机制。在我们提出的框架下,我们观察到在patch图像中是否存在组织类别的问题上,分类结果的置信度普遍高于分割结果,特别是对于非优势类别。由于分类模型是通过地面真实标签来训练的,而分割模型是通过伪掩码来训练的。
基于这一观察,我们为每个输出通道引入一个门,让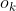 表示来自分割模型的第k个组织类别的输出概率图,如果来自分类
表示来自分割模型的第k个组织类别的输出概率图,如果来自分类 模型的组织类别的预测概率
模型的组织类别的预测概率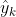 小于阈值
小于阈值 ,这意味着这一类别的存在率很低,然后,我们将通过调零来“关闭”概率图的大门。
,这意味着这一类别的存在率很低,然后,我们将通过调零来“关闭”概率图的大门。
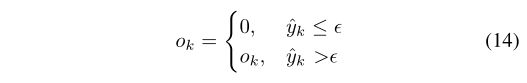
最后,语义分割结果可以通过下面公式得到,实际中我们设置阈值=0.1
![]()
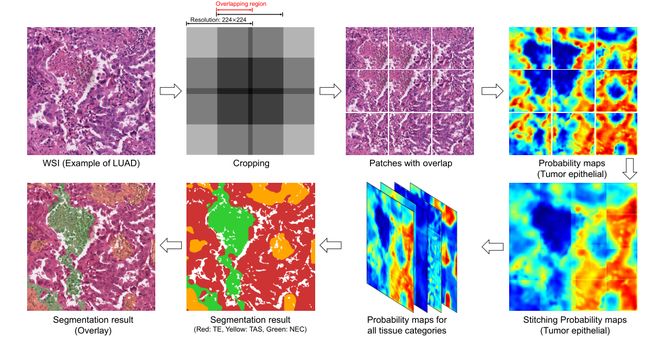
3) Semantic Segmentation for WSIs:我们在上面定义的模型是patch级别的语义分割模型。接下来,我们介绍了整个WSI图像语义分割的实现方法。如图下图所示,我们首先从超过50%重叠区域的整个WSI图像中裁剪patch。利用该分割模型,可以为每个patch生成n个通道概率图。然后我们将概率图缝合到WSI级别。对于重叠区域,我们计算每个像素位置上每个类别的概率平均值。然后通过argmax运算得到整个幻灯片图像的语义分割结果。
3 EXPERIMENTS(实验)
在这一部分中,我们进行了几个实验,以综合评估我们提出的模型的能力,即它在只使用patch级别的标注的情况下实现语义分割的效果。Sec V-A定量和定性的了比较我们的方法与最先进的方法。我们在进行消融研究,Sec V-B评估我们提出的的渐进式丢弃关注力的有效性,多层为监督和分类门机制的有效性。
A. Quantitative and Qualitative Comparisons
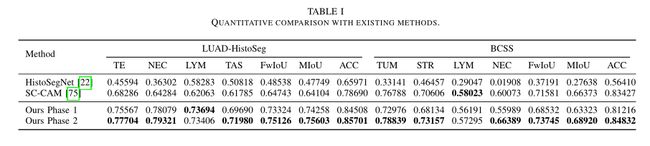
表I展示了与现有方法的定量比较。我们将我们提出的模型与两个基于SOTA CAM的弱监督语义分割模型进行了比较,一个用于组织病理图像(HistoSegNet),另一个用于自然图像(SC-CAM)。如表I所示,我们的最终模型在两个数据集上的表现都大大优于现有的两个模型。在LUAD-HistoSeg数据集中,即使是在阶段1中由分类模型生成的伪掩码也可以在这两个数据集中优于现有的两种基于CAM的WSSS方法,这证明了我们提出的渐进式丢弃注意的优越性。在第二阶段对分割模型进行训练后,我们的模型在LUAD-HistoSeg中除LYM之外的所有类别上都取得了显著且一致的改进。因为LYM在这个数据集中只占4%左右,这是非常不平衡的。缺乏训练样本可能会导致性能不稳定。
B. Ablation Studies
我们进行了一系列的消融研究,以定量和定性地评价这些新技术的优越性,包括渐进式丢弃注意力(PDA)、多层伪监督(MLP)和分类门控机制。
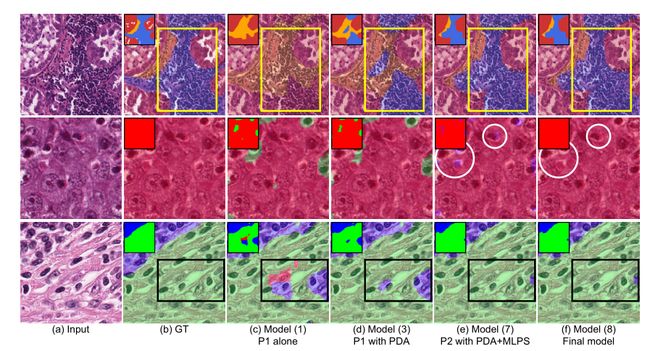
上图.消融研究的定性结果。第一行来自LUAD-HistoSeg。接下来的两行来自BCSS。定量结果如表III所示。我们还选择了几个有代表性的基线模型(1)、(3)、(7)和(8)来定性地证明上图中提出的新颖性的有效性。

我们提出的模型仍然存在一些局限性。它在主要组织类别中取得了突出的表现。但对于非优势类,缺乏足够的训练样本一直是影响精确分割结果的最大障碍。
4 CONCLUSION(结论)
本文提出了一种癌组织病理图像的组织级语义分割模型。该模型的主要贡献是将像素级的标注替换为patch级的标注,这是病理学家减少标注工作量的重大进步。我们提出的模型获得了与全监督模型相当的性能,这意味着病理学家只需要定义patch中组织类别的存在或不存在,而不需要仔细地绘制标签。在方法论上,我们提出了几项技术创新,以最大限度地缩小patch级标注和像素级标注之间的信息差距,并取得了优异的语义分割性能。为了促进计算病理学和癌症研究领域的发展,我们还引入了一个新的弱监督肺腺癌语义分割数据集LUADHistoSeg。这是首个针对肺癌的组织级语义分割数据集。通过应用我们提出的模型,我们还不断地为不同的癌症类型生成更多的组织级语义分割数据集。我们会邀请更多资深病理学家参与这项计划,以进行标签审核。希望这些数据集能很快发布。
论文阅读2
Learning Deep Features for Discriminative Localization(用于区别性定位的深度特征学习)
ABSTRACT(摘要)
在这项工作中,我们回顾了中提出的全局平均池层,并阐明了它如何显式地使卷积神经网络(CNN)在接受图像级别标签训练的情况下仍具有显著的定位能力。虽然这项技术之前被认为是一种规则化训练的手段,但我们发现它实际上建立了一个通用的可本地化的深层表征,暴露了CNN在图像上的隐含注意力。尽管全局平均汇集看起来很简单,但在ILSVRC 2014上,我们能够在没有任何边界框注释的情况下获得37.1%的TOP-5%的目标定位错误。我们通过各种实验证明,尽管我们的网络只是被训练来解决分类任务,但我们仍然能够定位出具有区分性的图像区域。
1 INTRODUCTION(介绍)
Zhou et al最近的工作表明,尽管没有提供对对象位置的监控,卷积神经网络(CNN)各层的卷积单元实际上起到了对象检测器的作用。尽管具有在卷积层中定位对象的非凡能力,但当使用完全连通的层进行分类时,这种能力就会丧失。
为了实现这一点,使用了全局平均池,它起到了结构调节器的作用,防止了训练过程中的过拟合。在我们的实验中,我们发现这个全局平均汇聚层的优点不仅仅是简单地充当正则化??事实上,只要稍作调整,网络就可以保持其卓越的定位能力,直到最后一层。
如图1(A)所示,经过对象分类训练的CNN能够成功地将用于动作分类的区别性区域定位为人类与之交互的对象,而不是人类本身。

图1.结合我们的类激活映射(CAM)技术,对全局平均池层的简单修改,就能使得经过分类训练的CNN在单个正向传递中既对图像进行分类,又定位特定类别的图像区域,例如,用于刷牙的牙刷和用于砍伐树木的电锯。
Weakly-supervised object localization(弱监督对象定位):
最近已经有一些工作探索使用CNN的弱监督目标定位。Bergamoet et al提出了一种自学习物体定位技术,该技术包括遮蔽图像区域以识别引起最大激活的区域,从而定位物体。
Visualizing CNNs(可视化CNN)
最近已经有一些工作可视化了CNN学习的内部表征,试图更好地理解它们的性质。Zeileret al使用去卷积网络来可视化激活每个单元的模式。周等人表明,CNN在识别场景的训练时学习对象检测,并证明同一网络可以在单一的前向传递中同时进行场景识别和对象定位。
我们的方法可以准确地突出图像的哪些区域对于区分是重要的。总体而言,我们的方法提供了对CNN的又一次窥探。
2 Class Activation Mapping(类激活图)
在本节中,我们将描述在CNN中使用全局平均池(GAP)生成类激活映射(CAM)的过程。特定类别的类激活图指示CNN用来标识该类别的区别图像区域(例如,图3)。生成这些map的过程如图2所示。

我们使用类似于Network in Network和GoogLeNe的网络结构-网络主要由卷积层组成,就在最终输出层(在分类的情况下为Softmax)之前,我们对卷积特征映射执行全局平均汇集,并将其用作产生所需输出(分类或其他)的完全连接层的特征。给定这种简单的连通性结构,我们可以通过将输出层的权重投影回卷积特征映射(我们称之为类激活映射)来识别图像区域的重要性。
如图2所示,全局平均汇集输出最后卷积层的每个单元的特征地图的空间平均。这些值的加权和用于生成最终输出。类似地,我们计算最后一卷积层的特征映射的加权和,以获得我们的类激活映射。

在图4中,突出显示了使用不同类别c来生成地Map时,单个图像的不同之处。我们观察到,即使对于给定同一张图像,不同类别的区分的区域也是不同的。这表明我们的方法起到了预期的作用。
Conclusion(结论)
在这项工作中,我们提出了一种称为类激活映射(CAM)的通用技术,通过全局平均池的CNN来做到。这使得经过分类训练的CNN能够学习用于对象定位,而不使用任何边界框标注。类激活图使我们可以在任何给定的图像上可视化预测的类别分数,突出通过CNN检测到的有区别的目标部分。此外,我们还证明了CAM定位技术可以推广到其他视觉识别任务,即我们的技术产生了通用的可定位的深层特征,这些特征可以帮助其他研究人员理解CNN用于他们的任务辨别的基础。
Class Activate Map(类激活图)代码实现
"""
PyTorch implementation of:
Learning Deep Features for Discriminative Localization
"""
import argparse
import copy
import os
import cv2
import numpy as np
import torchvision
import torch
from PIL import Image
from torchvision.models.resnet import resnet152, resnet18, resnet50
import ImageNetLabels
model_name_to_func = {
"resnet18": torchvision.models.resnet18,
"resnet34": torchvision.models.resnet34,
"resnet50": torchvision.models.resnet50,
"resnet101": torchvision.models.resnet101,
"resnet152": torchvision.models.resnet152,}
def parse_args():
parser = argparse.ArgumentParser(
"Class activation maps in pytorch")
parser.add_argument('--model_name', type=str,
help='name of model to use', required=True)
parser.add_argument('--input_image', type=str,
help='path to input image', required=True)
parser.add_argument('--save_gif', default=False,
help='save a gif animation', required=False, action='store_true')
args = parser.parse_args()
assert args.model_name in list(model_name_to_func.keys()), 'Model [%s] not found in supported models in [%s]' % (
args.model_name, list(model_name_to_func.keys()), )
return args
class ReshapeModule(torch.nn.Module):
def __init__(self):
super(ReshapeModule, self).__init__()
def forward(self, x):
b, c, h, w = x.shape
x = x.view(b*c, h*w).permute(1, 0)
return x
def modify_model_cam(model):
"""Modifies a pytorch model object to remove last
global average pool and replaces with a custom reshape
node that enables generating class activation maps as
forward pass
Args:
model: pytorch model graph
Raises:
ValueError: if no global average pool layer is found
Returns:
model: modified model with last global average pooling
replaced with custom reshape module
"""
# fetch all layers + globalavgpoollayers
alllayers = [n for n, m in model.named_modules()]
globalavgpoollayers = [n for n, m in model.named_modules(
) if isinstance(m, torch.nn.AdaptiveAvgPool2d)]
if globalavgpoollayers == []:
raise ValueError('Model does not have a Global Average Pool layer')
# check if last globalavgpool is second last layer - otherwise the method wont work
assert alllayers.index(globalavgpoollayers[-1]) == len(
alllayers)-2, 'Global Average Pool is not second last layer'
# remove last globalavgpool with our custom reshape module
model._modules[globalavgpoollayers[-1]] = ReshapeModule()
return model
def infer_with_cam_model(cam_model, image):
"""Run forward pass with image tensor and get class activation maps
as well as predicted class index
Args:
cam_model: pytorch model graph with custom reshape module modified using modify_model_cam()
image: torch.tensor image with preprocessing applied
Returns:
class activation maps and most probable class index
"""
with torch.no_grad():
output_cam_acti = cam_model(image)
_, output_cam_idx = torch.topk(torch.mean(
output_cam_acti, dim=0), k=10, dim=-1)
return output_cam_acti, output_cam_idx
def postprocess_cam(cam_image, image):
"""Process class activation map to generate a heatmap
overlay the heatmap on original image
Args:
cam_model: pytorch model graph with custom reshape module modified using modify_model_cam()
image: numpy array for image to overlay heatmap on top
Returns:
numpy array with image + overlayed heatmap
"""
h, w = image.shape[0:2]
sp = int(np.sqrt(cam_image.shape[0]))
assert cam_image.shape[0] == sp * \
sp, 'Only activation maps that are square are supported at the moment'
# make square class act map (if possible)
cam_image = np.reshape(cam_image, [sp, sp])
# normalise to be in range [0, 255]
cam_image = cam_image - np.min(cam_image)
cam_image = (cam_image/np.max(cam_image) * 255).astype(np.uint8)
# resize to input image shape and make a heatmap
cam_image_processed = cv2.applyColorMap(
cv2.resize(cam_image, (w, h)), cv2.COLORMAP_JET)
# BGR to RGB (opencv is BGR image, PIL output is RGB)
cam_image_processed = cam_image_processed[:, :, ::-1]
return cam_image_processed
if __name__ == '__main__':
args = parse_args()
# preprocessing for imagenet models
preprocess_imagenet = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# run on cuda if possible
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# fetch the model and apply cam modification
orig_model = model_name_to_func[args.model_name](pretrained=True)
orig_model.eval()
class_act_map_model = modify_model_cam(copy.deepcopy(orig_model))
class_act_map_model.to(device)
# load image, preproceess
filename = args.input_image
input_image_pil = Image.open(filename)
input_image = preprocess_imagenet(input_image_pil).unsqueeze(0)
input_image = input_image.to(device)
input_image_raw_np = np.asarray(input_image_pil)
# run inference with input image
selidx=0
output_cam_acti, output_cam_idx = infer_with_cam_model(
class_act_map_model, input_image)
print('Prediction [%s] at index [%d]' % (
ImageNetLabels.idx_to_class[output_cam_idx[selidx].item()], output_cam_idx[selidx]))
cam_image_raw = output_cam_acti[:, output_cam_idx[selidx].item()].cpu().detach().numpy()
cam_image_processed = postprocess_cam(
cam_image_raw, input_image_raw_np)
# overlay on top of original image
alpha = 0.5
cam_image_overlayed = (1-alpha) * input_image_raw_np + alpha * cam_image_processed
# save
Image.fromarray(cam_image_overlayed.astype(np.uint8)).save(
os.path.join('results', os.path.basename(args.input_image)))
# create gif animation if required
if args.save_gif:
cam_image_overlayed_gif = []
for al in [x/100. for x in range(50)]:
cam_image_overlayed_gif.append((1-al) * input_image_raw_np + al * cam_image_processed)
for al in reversed([x/100. for x in range(50)]):
cam_image_overlayed_gif.append((1-al) * input_image_raw_np + al * cam_image_processed)
factor = min([300./x for x in cam_image_overlayed_gif[0].shape[0:2]])
cam_image_overlayed_gif = [Image.fromarray(x.astype(np.uint8)).resize([int(factor * s) for s in reversed(x.shape[0:2])])
for x in cam_image_overlayed_gif]
cam_image_overlayed_gif[0].save(os.path.join('results', os.path.basename(args.input_image).split('.')[
0] + '.gif'), save_all=True, append_images=cam_image_overlayed_gif[1:], optimize=True, duration=40, loop=0)
CAM效果


本周工作总结
1.通过本周阅读的的这篇病理弱监督分割,学习了基于image-level的弱监督分割的整个流程,一般都是1.先通过多标签分类模型获取图像的类激活图(CAM)作为种子区域 2.在种子区域的基础上对种子区域进行扩展得到图像的伪标签(Pseudo-Mask)3.把上一步得到的伪标签当做真实标签训练一个全监督分割模型
2.学习了CAM的代码实现,我们可以通过CAM,来进行CNN的可视化(也可以看通过CAM来看网络特征的提取是否优秀),也是弱监督生成伪标签的最关键一步。