DDPG框架的搭建&pendulum-V0环境构建
DDPG框架的搭建&pendulum-V0环境构建
- 一、pendulum-v0环境的搭建
-
- 1.系统示意图
- 2.拉格朗日方程
- 3.状态方程
- 4.仿真方程
- 5.reward定义
- 6.python程序
- 二、DDPG的实现
-
- 1.程序流程图
- 2.代码实现
- 四、实验结果
完整的代码请见:https://github.com/yangtao121/AquaRL
一、pendulum-v0环境的搭建
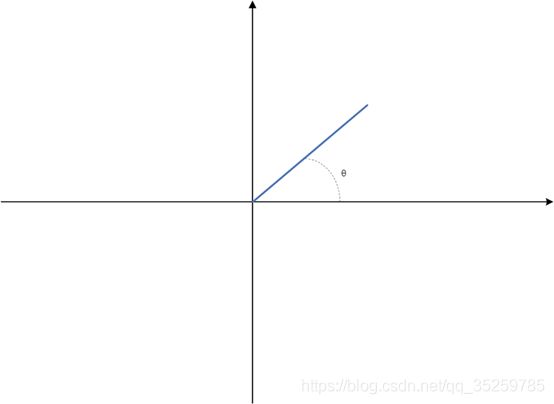
1.系统示意图
2.拉格朗日方程

3.状态方程

4.仿真方程

5.reward定义

6.python程序
import numpy as np
class pendulum:
def __init__(self):
# state参数范围设置
self.theta_high = 2 * np.pi
self.theta_low = 0
self.theta_dot_high = 8.0
self.theta_dot_low = -8.0
# 参数预设省的下面有波浪线
self.theta = 0
self.theta_dot = 0
self.u = None
self.done = False
# action范围设置
self.u_high = 2.0
self.u_low = -2.0
# 仿真参数设置
self.g = 10.0
self.dt = 0.05 # 仿真步长
self.m = 1 # 质量
self.l = 1 # 长度
# reward权重参数
self.w1 = 1
self.w2 = 0.1
self.w3 = 0.001
# 初始化状态
self.reset()
# 随机位置
def reset(self):
self.theta = np.random.uniform(self.theta_low, self.theta_high)
self.theta_dot = np.random.uniform(self.theta_dot_low, self.theta_dot_high)
self.u = None
return np.array([self.theta, self.theta_dot])
def reward(self, theta, theta_dot, u):
R = -(self.w1 * (theta - np.pi / 2) ** 2 + self.w2 * theta_dot ** 2 + self.w3 * u ** 2)
return R
def step(self, u):
# 初始化运算参数
self.done = False
# 获取k时间状态
theta = self.theta
theta_dot = self.theta_dot
# 计算reward
reward = self.reward(theta, theta_dot, u)
new_theta_dot = theta_dot + (
-(3 * self.g * np.cos(theta)) / (self.l * theta) + 3 / (self.m * self.l ** 2) * u) * self.dt
new_theta_dot = np.clip(new_theta_dot, self.theta_dot_low, self.theta_dot_high)
new_theta = theta + new_theta_dot * self.dt
# 圆整角度
while new_theta < 0:
new_theta += 2 * np.pi
while new_theta - 2 * np.pi > 0:
new_theta -= 2 * np.pi
self.theta = new_theta
self.theta_dot = new_theta_dot
# 判断当前状态是否结束
f0 = self.m * self.g * np.cos(theta) / theta
if np.abs(u - f0) < 1e-1: # 控制精度为百分之九十
# or theta_dot > self.theta_dot_high or theta_dot < self.theta_dot_low:
self.done = True
return np.array([self.theta, self.theta_dot]), reward, self.done
二、DDPG的实现
1.程序流程图

2.代码实现
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
class DDPG:
def __init__(self, upper_bound,
lower_bound,
s_dims, a_dims,
soft_update_tau=0.01,
critic_lr=0.002,
actor_lr=0.001,
gamma=0.99,
store_capacity=50000,
batch_size=64):
# 神经网络参数
self.s_dims = s_dims
self.a_dims = a_dims
self.gamma = gamma
# 优化器的定义
self.critic_optimizer = keras.optimizers.Adam(critic_lr)
self.actor_optimizer = keras.optimizers.Adam(actor_lr)
# soft update parameter
self.tau = soft_update_tau
# 环境参数
self.upper_bound = upper_bound
self.lower_bound = lower_bound
# 创建网络
self.target_actor = self.actor_net()
self.online_actor = self.actor_net()
self.target_critic = self.critic_net()
self.online_critic = self.critic_net()
self.target_actor.set_weights(self.online_actor.get_weights())
self.target_critic.set_weights(self.online_critic.get_weights())
# 数据中心的定义
self.store_capacity = store_capacity
self.batch_size = batch_size
self.store_counter = 0
self.state_transition = np.zeros((self.store_capacity, self.s_dims))
self.action_transition = np.zeros((self.store_capacity, self.a_dims))
self.reward_transition = np.zeros((self.store_capacity, 1))
self.next_state_transition = np.zeros((self.store_capacity, self.s_dims))
def record(self, state, action, reward, next_state):
index = self.store_counter % self.store_capacity
self.state_transition[index] = state
self.action_transition[index] = action
self.reward_transition[index] = reward
self.next_state_transition[index] = next_state
self.store_counter += 1
def actor_net(self):
# 初始化权值
last_init = tf.random_uniform_initializer(minval=-0.003, maxval=0.003)
inputs = layers.Input(shape=(self.s_dims,))
out = layers.Dense(512, activation="relu")(inputs)
out = layers.BatchNormalization()(out)
out = layers.Dense(512, activation="relu")(out)
out = layers.BatchNormalization()(out)
outputs = layers.Dense(1, activation="tanh", kernel_initializer=last_init)(out)
outputs = outputs * self.upper_bound
model = tf.keras.Model(inputs, outputs)
return model
def critic_net(self):
# State input
state_input = layers.Input(shape=(self.s_dims))
state_out = layers.Dense(16, activation="relu")(state_input)
state_out = layers.BatchNormalization()(state_out)
state_out = layers.Dense(32, "relu")(state_out)
state_out = layers.BatchNormalization()(state_out)
# Action Input
action_input = layers.Input(shape=(self.a_dims))
action_out = layers.Dense(32, activation="relu")(action_input)
action_out = layers.BatchNormalization()(action_out)
# 非顺序结构
concat = layers.Concatenate()([state_out, action_out])
out = layers.Dense(512, activation="relu")(concat)
out = layers.BatchNormalization()(out)
out = layers.Dense(512, activation="relu")(out)
outputs = layers.Dense(1)(out)
model = keras.Model([state_input, action_input], outputs)
return model
def learn(self):
# 从样本中采样
sample_range = min(self.store_counter, self.store_capacity)
# 获取样本的索引
sample_indices = np.random.choice(sample_range, self.batch_size)
# 将数据转化为张量
state_batch = tf.convert_to_tensor(self.state_transition[sample_indices])
action_batch = tf.convert_to_tensor(self.action_transition[sample_indices])
reward_batch = tf.convert_to_tensor(self.reward_transition[sample_indices])
reward_batch = tf.cast(reward_batch, dtype=tf.float32)
next_state_batch = tf.convert_to_tensor(self.next_state_transition[sample_indices])
# 神经网络的更新
with tf.GradientTape() as tape:
target_actions = self.target_actor(next_state_batch)
y = reward_batch + self.gamma * self.target_critic([next_state_batch, target_actions])
critic_value = self.online_critic([state_batch, action_batch])
critic_loss = tf.math.reduce_mean(tf.math.square(y - critic_value))
critic_grad = tape.gradient(critic_loss, self.online_critic.trainable_variables)
self.critic_optimizer.apply_gradients(
zip(critic_grad, self.online_critic.trainable_variables)
)
with tf.GradientTape() as tape:
actions = self.online_actor(state_batch)
critic_value = self.online_critic([state_batch, actions])
# 这地方算法有争议
# 需要修改尝试
actor_loss = -tf.math.reduce_mean(critic_value)
actor_grad = tape.gradient(actor_loss, self.online_actor.trainable_variables)
self.actor_optimizer.apply_gradients(
zip(actor_grad, self.online_actor.trainable_variables)
)
def soft_update(self):
new_weights = []
target_variables = self.target_critic.weights
for i, variable in enumerate(self.online_critic.weights):
new_weights.append(variable * self.tau + target_variables[i] * (1 - self.tau))
self.target_critic.set_weights(new_weights)
new_weights = []
target_variables = self.target_actor.weights
for i, variable in enumerate(self.online_actor.weights):
new_weights.append(variable * self.tau + target_variables[i] * (1 - self.tau))
self.target_actor.set_weights(new_weights)
def action_policy(self, state):
sample_actions = tf.squeeze(self.online_actor(state))
sample_actions = sample_actions.numpy()
legal_action = np.clip(sample_actions, self.lower_bound, self.upper_bound)
return legal_action
def save_model(self):
self.online_actor.save_weights("pendulum_online_actor.h5")
self.online_critic.save_weights("pendulum_online_critic.h5")
self.target_actor.save_weights("pendulum_target_actor.h5")
self.target_critic.save_weights("pendulum_target_critic.h5")
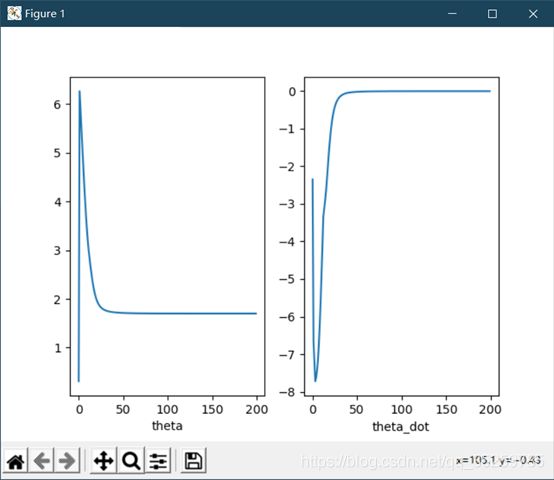
四、实验结果
学习曲线:

控制响应曲线: