保存与加载模型
保存与加载模型
首先给出PyTorch官网的两个教程:
- 教程一:加载Tensor
- 教程二:加载Model
这里讲一种常用的方法
保存&&加载
torch.save(x, path)
- x:要保存的信息
- path:保存的路径
注意这个x可以是一个简单的Tensor,也可以是我们的模型参数
torch.load(path)
- path:要加载的模型路径
此函数返回和之前保存的一模一样的x信息,即之前保存的x是什么,这个函数就返回什么
这里举两个例子方便理解,一个是Tensor的例子,另一个是Model的例子
(1)Tensor
import torch
x = torch.tensor([0, 1, 2, 3, 4])
torch.save(x, 'tensor.pth')
y = torch.load('tensor.pth')
print(y)
'''
tensor([0, 1, 2, 3, 4])
'''
此时当前文件目录下会出现tensor.pth文件,也就是说我们用torch.save()保存了变量x,然后用torch.load()加载赋值给y输出
(2)Model
在训练模型的时候,我们往往需要保存模型的epoch,model参数以及optimizer的信息,保存的代码如下
torch.save({'epoch': epoch,
'state_dict': model_restoration.state_dict(),
'optimizer' : optimizer.state_dict()},
# os.path.join(model_dir,"model_latest.pth")
os.path.join(model_dir,f"model_epoch_{epoch}.pth"))
重新加载模型的程序如下
# 加载模型参数
def load_checkpoint(model, weights):
checkpoint = torch.load(weights)
try:
model.load_state_dict(checkpoint["state_dict"])
except:
state_dict = checkpoint["state_dict"]
new_state_dict = OrderedDict()
for k, v in state_dict.items():
name = k[7:] # remove `module.`
new_state_dict[name] = v
model.load_state_dict(new_state_dict)
# 加载optimizer参数
def load_optim(optimizer, weights):
checkpoint = torch.load(weights)
optimizer.load_state_dict(checkpoint['optimizer'])
# 加载epoch
def load_start_epoch(weights):
checkpoint = torch.load(weights)
epoch = checkpoint["epoch"]
return epoch
注意上面的load_checkpoint函数,如果在训练时用了DataParallel函数,那么最终参数会带有module,此时就应该将其去掉
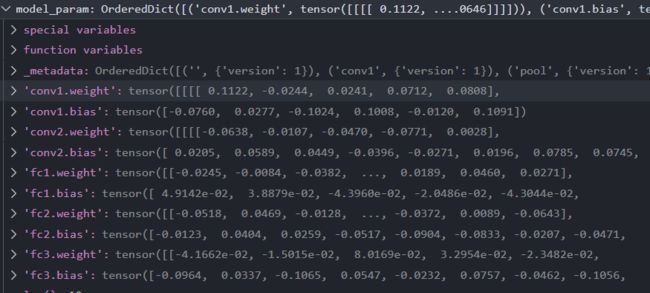
没有使用DataParallel的参数形式
使用DataParallel的参数形式,可以发现参数前带有module
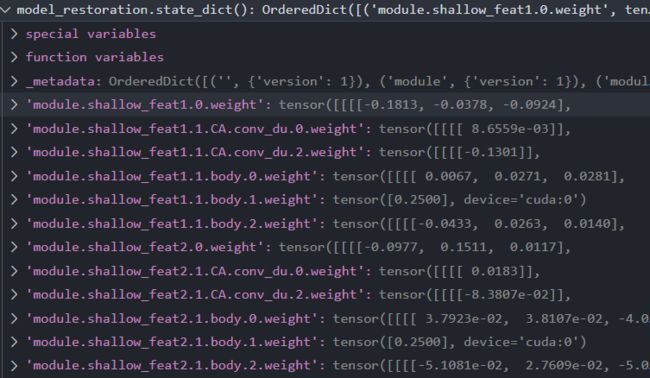
我们在保存模型时都保存了些什么呢?下面程序展示了保存的模型和优化器的一些信息,从输出可以看出,我们传入torch.save()中的就是模型中卷积等的weight和bias等信息。那么为什么使用DataParallel之后加载参数需要去掉module呢,这是因为我们真实的模型中是没有module这个前缀的,是conv1.weight或者conv1.bias,而我们使用并行计算时,参数就会被归到module下,就变为了module.conv1.weight以及module.conv1.bias,如果在load的时候不把前缀module.去掉,模型就无法匹配参数,也就没法恢复了,所以在恢复参数的时候要注意索引是否一致
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# define model
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass,self).__init__()
self.conv1=nn.Conv2d(3, 6, 5)
self.pool=nn.MaxPool2d(2, 2)
self.conv2=nn.Conv2d(6, 16, 5)
self.fc1=nn.Linear(16*5*5, 120)
self.fc2=nn.Linear(120, 84)
self.fc3=nn.Linear(84, 10)
def forward(self,x):
x=self.pool(F.relu(self.conv1(x)))
x=self.pool(F.relu(self.conv2(x)))
x=x.view(-1,16*5*5)
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
def main():
# Initialize model
model = TheModelClass()
# Initialize optimizer
optimizer=optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
'''
model的state_dict()与optimizer的略有不同
model:
torch.nn.Module模块中的state_dict只包含卷积层和全连接层的参数
当网络中存在batchnorm时,例如vgg网络结构,torch.nn.Module模块中
的state_dict也会存放batchnorm's running_mean
optimizer:
state_dict字典对象包含state和param_groups的字典对象,而param_groups key
对应的value也是一个由学习率,动量等参数组成的一个字典对象
'''
# print model state_dict
print('Model.state_dict: ')
model_param = model.state_dict()
for param_tensor in model_param:
# print key value字典
print(param_tensor, '\t', model.state_dict()[param_tensor].size())
# print optimizer state_dict
print('Optimizer state_dict: ')
optim_param = optimizer.state_dict()
for var_name in optim_param:
print(var_name, '\t', optimizer.state_dict()[var_name])
if __name__=='__main__':
main()
'''
Model.state_dict:
conv1.weight torch.Size([6, 3, 5, 5])
conv1.bias torch.Size([6])
conv2.weight torch.Size([16, 6, 5, 5])
conv2.bias torch.Size([16])
fc1.weight torch.Size([120, 400])
fc1.bias torch.Size([120])
fc2.weight torch.Size([84, 120])
fc2.bias torch.Size([84])
fc3.weight torch.Size([10, 84])
fc3.bias torch.Size([10])
Optimizer state_dict:
state {}
param_groups [{'lr': 0.001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]}]
'''