promQL语句整理
前言:之前的文章已经介绍了prometheus原理、安装配置,可视化以及告警,本文主要是梳理prometheus时序数据库语法promQL的基本使用。
一、理解时间序列
1.1 样本
Prometheus会将所有采集到的样本数据以时间序列(time-series)的方式保存在内存数据库中,并且定时保存到硬盘上。time-series是按照时间戳和值的序列顺序存放的,我们称之为向量(vector). 每条time-series通过指标名称(metrics name)和一组标签集(labelset)命名。如下所示,可以将time-series理解为一个以时间为Y轴的数字矩阵:
^
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="idle"}
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="system"}
│ . . . . . . . . . . . . . . . . . . node_load1{}
│ . . . . . . . . . . . . . . . . . .
v
<------------------ 时间 ---------------->
在time-series中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):metric name和描述当前样本特征的labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value): 一个float64的浮点型数据表示当前样本的值。
<--------------- metric ---------------------><-timestamp -><-value->
http_request_total{status="200", method="GET"}@1434417560938 => 94355
http_request_total{status="200", method="GET"}@1434417561287 => 94334
http_request_total{status="404", method="GET"}@1434417560938 => 38473
http_request_total{status="404", method="GET"}@1434417561287 => 38544
http_request_total{status="200", method="POST"}@1434417560938 => 4748
http_request_total{status="200", method="POST"}@1434417561287 => 4785
1.2 指标(Metric)
在形式上,所有的指标(Metric)都通过如下格式标示:
<metric name>{<label name>=<label value>, ...}
标的名称(metric name)可以反映被监控样本的含义(比如,http_request_total - 表示当前系统接收到的HTTP请求总量)。指标名称只能由ASCII字符、数字、下划线以及冒号组成并必须符合正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*
标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。标签的名称只能由ASCII字符、数字以及下划线组成并满足正则表达式[a-zA-Z_][a-zA-Z0-9_]*
其中以__作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何Unicode编码的字符。在Prometheus的底层实现中指标名称实际上是以__name__=的形式保存在数据库中的,因此以下两种方式均表示的同一条time-series:
api_http_requests_total{method="POST", handler="/messages"}
等同于
{__name__="api_http_requests_total",method="POST", handler="/messages"}
二、 Metrics类型
Prometheus定义了4种不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)
2.1 Counter:只增不减的计数器
- Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标。 一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
//例如,通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
//查询当前系统中,访问量前10的HTTP地址:
topk(10, http_requests_total)
2.2 Gauge:可增可减的仪表盘
- 与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
//通过Gauge指标,用户可以直接查看系统的当前状态:
node_memory_MemFree
//还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。例如,预测系统磁盘空间在4个小时之后的剩余情况:
predict_linear(node_filesystem_free{job="node"}[1h], 4 * 3600)
2.3 Histogram和Summary分析数据分布情况
- Histogram和Summary主用用于统计和分析样本的分布情况。
- summary示例:
例如,指标prometheus_tsdb_wal_fsync_duration_seconds的指标类型为Summary。 它记录了Prometheus Server中wal_fsync处理的处理时间,通过访问Prometheus Server的/metrics地址,可以获取到以下监控样本数据:
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Prometheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s
- Histogram示例
# HELP prometheus_tsdb_compaction_chunk_range Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range histogram
prometheus_tsdb_compaction_chunk_range_bucket{le="100"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="6400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="25600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="102400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="409600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260
prometheus_tsdb_compaction_chunk_range_bucket{le="6.5536e+06"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780
prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09
prometheus_tsdb_compaction_chunk_range_count 780
与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。
同时对于Histogram的指标,我们还可以通过histogram_quantile()函数计算出其值的分位数。不同在于Histogram通过histogram_quantile函数是在服务器端计算的分位数。 而Sumamry的分位数则是直接在客户端计算完成。因此对于分位数的计算而言,Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。反之对于客户端而言Histogram消耗的资源更少。在选择这两种方式时用户应该按照自己的实际场景进行选择。
三、初始promQL
3.1 简介
PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。
3.2 查询时间序列
- 当我们直接使用监控指标名称查询时,可以查询该指标下的所有时间序列。如:
http_requests_total
等同于
http_requests_total{}
该表达式会返回指标名称为http_requests_total的所有时间序列:
http_requests_total{code="200",handler="alerts",instance="localhost:9090",job="prometheus",method="get"}=(20889@1518096812.326)
http_requests_total{code="200",handler="graph",instance="loc
- PromQL还支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配和正则匹配。
1)通过使用label=value可以选择那些标签满足表达式定义的时间序列;
2)反之使用label!=value则可以根据标签匹配排除时间序列;
3)使用label=~regx表示选择那些标签符合正则表达式定义的时间序列;
4)反之使用label!~regx进行排除;
//完全匹配模式
http_requests_total{instance!="localhost:9090"}
//正则匹配模式
http_requests_total{environment=~"staging|testing|development",method!="GET"}
3.3 范围查询
- 直接通过类似于PromQL表达式http_requests_total查询时间序列时,返回值中只会包含该时间序列中的最新的一个样本值,这样的返回结果我们称之为瞬时向量。而相应的这样的表达式称之为瞬时向量表达式。
- 而如果我们想过去一段时间范围内的样本数据时,我们则需要使用区间向量表达式。区间向量表达式和瞬时向量表达式之间的差异在于在区间向量表达式中我们需要定义时间选择的范围,时间范围通过时间范围选择器[]进行定义。例如,通过以下表达式可以选择最近5分钟内的所有样本数据:
http_requests_total{}[5m]
-----------------------------------------------------------------------------------------
http_requests_total{code="200",handler="alerts",instance="localhost:9090",job="prometheus",method="get"}=[
1@1518096812.326
1@1518096817.326
1@1518096822.326
1@1518096827.326
1@1518096832.326
1@1518096837.325
]
-----------------------------------------------------------------------------------------
除了使用m表示分钟以外,PromQL的时间范围选择器支持其它时间单位:
- s - 秒
- m - 分钟
- h - 小时
- d - 天
- w - 周
- y - 年
3.4 时间位移操作
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准:
http_request_total{} //瞬时向量表达式,选择当前最新的数据
http_request_total{}[5m] //区间向量表达式,选择以当前时间为基准,5分钟内的数据
- 而如果我们想查询,5分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢? 这个时候我们就可以使用位移操作,位移操作的关键字为offset。
http_request_total{} offset 5m
http_request_total{}[1d] offset 1d
3.5 使用聚合操作
- PromQL提供的聚合操作可以用来对这些时间序列进行处理,形成一条新的时间序列
# 查询系统所有http请求的总量
sum(http_request_total)
# 按照mode计算主机CPU的平均使用时间
avg(node_cpu) by (mode)
# 按照主机查询各个主机的CPU使用率
sum(sum(irate(node_cpu{mode!='idle'}[5m])) / sum(irate(node_cpu[5m]))) by (instance)
3.6 合法的PromQL表达式
所有的PromQL表达式都必须至少包含一个指标名称(例如http_request_total),或者一个不会匹配到空字符串的标签过滤器(例如{code=“200”})。
http_request_total # 合法
http_request_total{} # 合法
{method="get"} # 合法
{__name__=~"http_request_total"} # 合法
{__name__=~"node_disk_bytes_read|node_disk_bytes_written"} # 合法
{job=~".*"} # 不合法
四、promQL操作符
4.1 数学运算
- 瞬时向量与标量之间进行数学运算时,数学运算符会依次作用域瞬时向量中的每一个样本值,从而得到一组新的时间序列
node_memory_free_bytes_total / (1024 * 1024)
- 瞬时向量与瞬时向量之间进行数学运算时,依次找到与左边向量元素匹配(标签完全一致)的右边向量元素进行运算,如果没找到匹配元素,则直接丢弃。同时新的时间序列将不会包含指标名称。 该表达式返回结果的示例如下所示
//瞬时向量和瞬时向量之间运算
node_disk_bytes_written + node_disk_bytes_read
------------------------------------------------------------------------------------------------
{device="sda",instance="localhost:9100",job="node_exporter"}=>1634967552@1518146427.807 + 864551424@1518146427.807
{device="sdb",instance="localhost:9100",job="node_exporter"}=>0@1518146427.807 + 1744384@1518146427.807
------------------------------------------------------------------------------------------------
PromQL支持的所有数学运算符如下所示:
- + (加法)
- - (减法)
- * (乘法)
- / (除法)
- % (求余)
- ^ (幂运算)
4.2 布尔运算
目前,Prometheus支持以下布尔运算符如下:
-
== (相等)
-
!= (不相等)
-
> (大于)
-
< (小于)
-
>= (大于等于)
-
<= (小于等于)
-
瞬时向量与标量进行布尔运算时,PromQL依次比较向量中的所有时间序列样本的值,如果比较结果为true则保留,反之丢弃。

- bool修饰符改变布尔运算的默认行为,满足返回1,不满足返回0
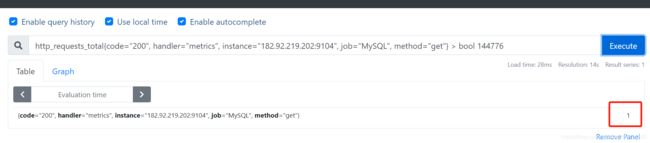
- 两个标量进行对比,必须使用bool修饰符
2 == bool 2 # 结果为1
4.3 集合运算符
- and (并且)
vector1 and vector2 会产生一个由vector1的元素组成的新的向量。该向量包含vector1中完全匹配vector2中的元素组成。 - or (或者)
vector1 or vector2 会产生一个新的向量,该向量包含vector1中所有的样本数据,以及vector2中没有与vector1匹配到的样本数据。 - unless (排除)
vector1 unless vector2 会产生一个新的向量,新向量中的元素由vector1中没有与vector2匹配的元素组成
4.4 优先级
- ^
- *, /, %
- +, -
- ==, !=, <=, <, >=, >
- and, unless
- or
五、promQL集合函数
5.1 函数
- sum (求和)
- min (最小值)
- max (最大值)
- avg (平均值)
- stddev (标准差)
- stdvar (标准方差)
- count (计数)
- count_values (对value进行计数)
- bottomk (后n条时序)
- topk (前n条时序)
- quantile (分位数)
count_values, quantile, topk, bottomk支持参数(parameter)
- without用于从计算结果中移除列举的标签,而保留其它标签。by则正好相反,结果向量中只保留列出的标签,其余标签则移除。通过without和by可以按照样本的问题对数据进行聚合
六、PromQL内置函数
6.1 内置函数
参考官网文档:https://prometheus.io/docs/prometheus/latest/querying/functions/
| 内置函数 | 说明 |
|---|---|
| abs() | |
| absent() | |
| absent_over_time() | |
| ceil() | |
| changes() | |
| clamp_max() | |
| clamp_min() | |
| day_of_month() | |
| day_of_week() | |
| days_in_month() | |
| delta() | |
| deriv() | |
| exp() | |
| floor() | |
| histogram_quantile() | |
| holt_winters() | |
| hour() | |
| idelta() | |
| increase() | |
| irate() | |
| label_join() | |
| label_replace() | |
| ln() | |
| log2() | |
| log10() | |
| minute() | |
| month() | |
| predict_linear() | |
| rate() | |
| resets() | |
| round() | |
| scalar() | |
| sort() | |
| sort_desc() | |
| sqrt() | |
| time() | |
| timestamp() | |
| vector() | |
| year() |
七、HTTP API中使用PromQL
- HTTP状态码:
200 success:调用成功的返回状态码
404 Bad Request:当参数错误或者缺失时。
422 Unprocessable Entity 当表达式无法执行时。
503 Service Unavailiable 当请求超时或者被中断时。
7.1 瞬时数据查询
接口名:GET IP:9090/api/v1/query
URL请求参数:
- query=:PromQL表达式。
- time=:用于指定用于计算PromQL的时间戳。可选参数,默认情况下使用当前系统时间。
- timeout=:超时设置。可选参数,默认情况下使用-query,timeout的全局设置。
例如使用以下表达式查询表达式up在时间点2015-07-01T20:10:51.781Z的计算结果:
$ curl 'http://localhost:9090/api/v1/query?query=up&time=2015-07-01T20:10:51.781Z'
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"value": [ 1435781451.781, "1" ]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9100"
},
"value" : [ 1435781451.781, "0" ]
}
]
}
}
- 响应数据类型
当API调用成功后,Prometheus会返回JSON格式的响应内容,格式如上小节所示。并且在data节点中返回查询结果。data节点格式如下:
{
"resultType": "matrix" | "vector" | "scalar" | "string",
"result": <value>
}
1)瞬时向量:resultType为vector
[
{
"metric": { "" : "" , ... },
"value": [ <unix_time>, "" ]
},
...
]
- 区间向量:resultType为matrix
[
{
"metric": { "" : "" , ... },
"values": [ [ <unix_time>, "" ], ... ]
},
...
]
- 标量:resultType为scalar
[ <unix_time>, "" ]
- 字符串:resultType为string
[ <unix_time>, "" ]
7.2 区间数据查询
接口名:GET /api/v1/query_range
URL请求参数:
- query=: PromQL表达式。
- start=: 起始时间。
- end=: 结束时间。
- step=: 查询步长。
- timeout=: 超时设置。可选参数,默认情况下使用-query,timeout的全局设置。
当使用QUERY_RANGE API查询PromQL表达式时,返回结果一定是一个区间向量:
{
"resultType": "matrix",
"result": <value>
}
例如使用以下表达式查询表达式up在30秒范围内以15秒为间隔计算PromQL表达式的结果。
$ curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}