Pytorch搭建基于SRCNN图像超分辨率重建模型及论文总结
SRCNN(Super-Resolution Convolutional Neural Network)
论文出处:Learning a Deep Convolutional Network for Image Super-Resolution
图像超分辨率重建,简言之能将一张低分辨率的图片,重建生成一张高分辨率的图片,该技术在遥感图像监测,医疗领域,车牌识别,人脸识别等多个领域起着很大的作用。
SRCNN是首度将深度学习用于超分辨率重建领域的网络模型,之后的网络大都以此为基础进行结构上的改进调优。
论文原文中对该模型架构分为了以下三部分:


第一层:特征块提取与表示层
在该层中,将低分辨率的图片作为输出,在预处理阶段(唯一的一步操作)通过使用双三次插值将其放大到所需的大小,放大倍数可以为2,3,4倍,放大后的图像仍为低分辨率图像,然后通过第一层卷积提取特征。该层可以表示为F1
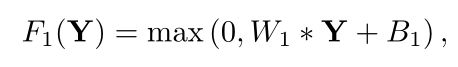
第二层:非线性映射层
该层通过非线性映射,将第一层的高维特征向量映射到另一个高维向量上,即第一层为每个图像块提取一个n1维特征。在第二层中,将这些n1维向量中的每一个都映射成n2维向量。通过以下公式:
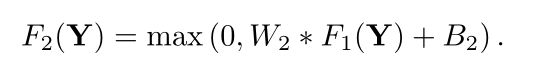
它的过程可以表示为:
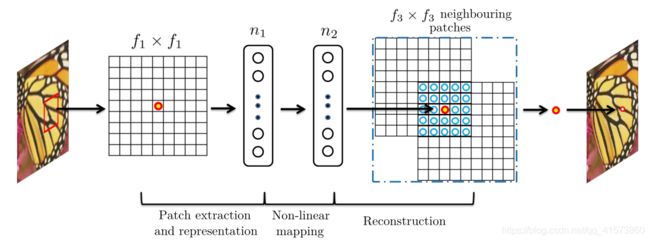
第三层:高分辨率图像重建层
第三层通过一个卷积层来实现高分辨率图像的重建工作。

损失函数
SRCNN采用均方误差(MSE)作为loss函数,因为使用均方误差作为损失函数有利于高PSNR。
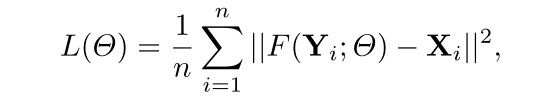
模型架构框图

第一层获取到输入的低分辨率图像后采用64个大小为9*9的卷积核提取特征。
第二层由32个1*1大小的卷积核构成。
第三层由1个5*5的卷积核构成。
模型搭建
基础环境
python 3.7, pytorch1.7.1, RTX3090,数据集采用BSDS300
网络构建
第一层64*9*9,s=1,padding=4;
第二层32*1*1
第三层应该为1*5*5(这里放大4倍,为4*5*5),s=1,padding=2
class Net(torch.nn.Module):
def __init__(self, num_channels, base_filter, upscale_factor=2):
super(Net, self).__init__()
self.layers = torch.nn.Sequential(
nn.Conv2d(in_channels=num_channels, out_channels=base_filter, kernel_size=9, stride=1, padding=4, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=base_filter, out_channels=base_filter // 2, kernel_size=1, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=base_filter // 2, out_channels=num_channels * (upscale_factor ** 2), kernel_size=5, stride=1, padding=2, bias=True),
nn.PixelShuffle(upscale_factor)
)
def build_model(self):
self.model = Net(num_channels=1, base_filter=64, upscale_factor=self.upscale_factor).to(self.device)
self.model.weight_init(mean=0.0, std=0.01)
self.criterion = torch.nn.MSELoss()
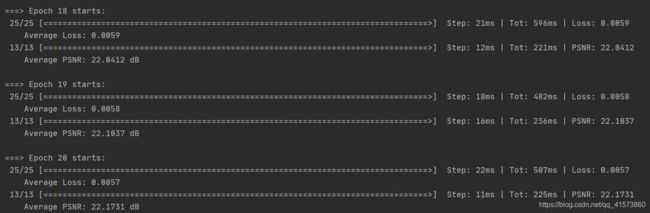
torch.manual_seed(self.seed)训练过程
def train(self):
self.model.train()
train_loss = 0
for batch_num, (data, target) in enumerate(self.training_loader):
data, target = data.to(self.device), target.to(self.device)
self.optimizer.zero_grad()
loss = self.criterion(self.model(data), target)
train_loss += loss.item()
loss.backward()
self.optimizer.step()
progress_bar(batch_num, len(self.training_loader), 'Loss: %.4f' % (train_loss / (batch_num + 1)))
print(" Average Loss: {:.4f}".format(train_loss / len(self.training_loader)))验证过程及PSNR计算
def test(self):
self.model.eval()
avg_psnr = 0
with torch.no_grad():
for batch_num, (data, target) in enumerate(self.testing_loader):
data, target = data.to(self.device), target.to(self.device)
prediction = self.model(data)
mse = self.criterion(prediction, target)
psnr = 10 * log10(1 / mse.item())
avg_psnr += psnr
progress_bar(batch_num, len(self.testing_loader), 'PSNR: %.4f' % (avg_psnr / (batch_num + 1)))
print(" Average PSNR: {:.4f} dB".format(avg_psnr / len(self.testing_loader)))模型训练超参
parser = argparse.ArgumentParser(description='PyTorch Super Res Example')
parser.add_argument('--batchSize', type=int, default=8, help='training batch size')
parser.add_argument('--testBatchSize', type=int, default=8, help='testing batch size')
parser.add_argument('--nEpochs', type=int, default=20, help='number of epochs to train for')
parser.add_argument('--lr', type=float, default=0.01, help='Learning Rate. Default=0.01')
parser.add_argument('--seed', type=int, default=123, help='random seed to use. Default=123')
parser.add_argument('--upscale_factor', '-uf', type=int, default=4, help="super resolution upscale factor")
parser.add_argument('--model', '-m', type=str, default='srcnn', help='choose which model is going to use')训练结果