多目标追踪笔记九:Learning to Track: Online Multi-Object Tracking by Decision Making
参考:https://blog.csdn.net/u012905422/article/details/74990096
1.介绍:
在跟踪检测中, 在线 mot 的一个主要挑战是如何将新视频帧上的噪声对象检测与以前跟踪的对象进行严格关联。
贡献:
将在线 mot 问题表述为马尔可夫决策过程 (mdp) 中的决策问题, 其中一个对象的生存周期是用 mdp 建模的。学习数据关联的相似功能相当于学习 mdp 的决策过程。而这种决策的学习也是基于强化学习进行的,这受益于离线学习的优势和在线数据关联在线学习的优势。
作者提出的框架能够自然处理目标的消亡和出生。通过将目标看作MDP中的状态转换,同时利用现有的在线单一对象跟踪方法。
PS:你可以从下图中很容易看出三个目标的追踪过程中,在”第二帧“,有两个目标被遮挡,从而导致目标丢失,而在“第三帧”,追踪状态恢复,目标重新回到正确轨迹。

2.相关工作
1)Multi-Object Tracking
在通过学习进行跟踪的算法中,大部分算法的目标都是通过训练数据,学习到一个反映数据关联性的相似性函数,而本文的突出贡献这是在多目标跟踪中通过增强学习算法学习数据关联性。
2)Online Single Object Tracking
在单目标跟踪算法中,大部分都是在线学习对于目标的外形描述的模型,并用该模型进行跟踪。而在多目标跟踪中,场景中目标还没有出现等情况的存在,使得该方法较难运用。本文的方法通过MDP对一个目标的整个出现时间阶段建模。
3)MDP in Vision
马尔科夫决策过程在CV中运用广泛,如识别中的特征提取,行为预测,人机协同等。MDP主要在需要一系列决策和执行行为的任务的动态环境下表现突出。本文中将目标跟踪看做MDP的任务,通过增强学习学习到MDP的policy,并用多个MDP去跟踪多个目标。
3.方法
method:Markov Decision Process (很简单的一个决策问题)
s定义目标的状态(state),a定义目标的动作(action),状态转移函数T描述任何一个状态下一个动作的影像,实值奖励函数R描述将动作a在状态s下的执行的实时奖励。
state:在MDP中,主要划分4个状态子空间,即S状态包含Active,Tracked,Lost,Inactive四个状态空间,每个子状态空间都记录了目标特征信息,包含目标外形,位置,大小和历史等。下图展示了四个子空间的转移过程。“Active”是每个目标的初始状态,当目标被目标检测算法检测出来,即进去“Active”状态。该状态可以转移到“Tracked”或“Inactive”状态,目标检测出来的true positive进入“Tracked”状态,而false alarm进入“Inactive”状态。被跟踪的目标可以继续被跟踪,或者进入“Lost”状态,如离开视野时。“Lost”状态的目标可以保持该状态,也可以因为再次出现转移到“Tracked”状态,或者因长时间未出现一直处于lost而转移到“Inactive”状态。所有目标的最终状态为“Inactive”状态,该状态只能保持不能转移。
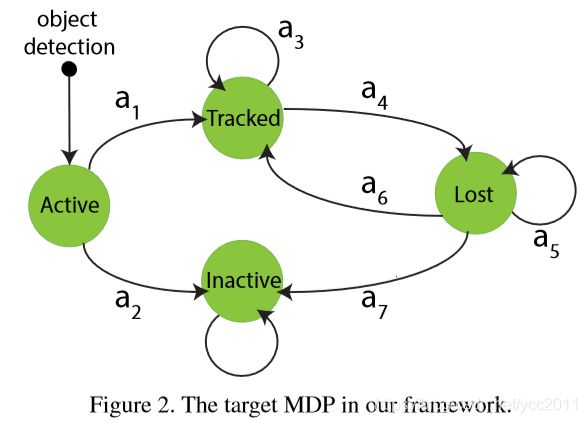
同时上图中定义了7种动作(action),也分别对应的定义了7种可能的转移函数。在MDP中,给定当前状态和一个动作,即可给出目标新的状态。同时本文中使用的MDP通过训练样本自主学习得到奖励函数。
method:各个状态(Active,Tracked,Lost,Inactive)的决策
Active:在这个状态,你要考虑当检测到的目标进入MDP中时,将检测到的目标做什么处理,是Tracked还是inactive?作者采用了SVM来分类检测结果来判断目标进入Active之后的决定。其中SVM使用5维特征向量,包括2维坐标、宽、高和检测的分数。训练样本来自训练视频。学习Active的奖励函数的方法如下:
![]()
W和b定义SVM的超平面,y(a)取1或-1,当a=a1时取1,a=a2时取-1。主要到这里,当目标检测存在错误时候,这里也会被错分类并转移成tracked状态,但是MDP的tracked和lost状态部分会进行处理。
Tracked:在追踪状态,你要决定是继续track该目标还是出现了异常情况导致目标lost。只要目标还在视野中就应该继续track,本文建立一个基于外形(appearance)的目标在线跟踪模型来跟踪目标(根据单目标跟踪的启发)。该基于外形的模型只要还能在其他视频中track到目标,就继续保持tracked状态。这里的模型来自于多个其他方法的组合,在TLD tracker的基础上进行implementation。(什么是TLD?https://www.cnblogs.com/lxy2017/p/3927456.html)
模板表示:
其中,目标的外观只是由一个模板表示, 该模板是视频帧中目标的图像补丁。每当检测到的对象转换为跟踪的目标时, 我们都会使用检测边界框初始化目标模板。在跟踪目标时, mdp 会在跟踪的帧中收集其模板, 以表示目标的历史记录, 这些历史记录将在lost状态中用于决策。
PS:从下图可以看出,作者从目标模板内密集采样点到新帧的光流。来预测下帧目标的位置。其中黄色框是目标的预测位置。图b为稳定的预测,图C为不好的预测。

模板跟踪:(用到了TLD的追踪模式:https://blog.csdn.net/zhangyonggang886/article/details/52863298)
为了使用目标模板进行跟踪, 我们计算了从模板内密集和均匀采样点到新视频帧的光流。这就使得光流质量很大程度上决定了跟踪的效果。对于给定的模板和其上的点,通过基于影像金字塔的迭代Lucas-Kanade方法计算光流,通过前向后向光流错误来测量预测的稳定性(如果前后预测点很接近,则预测的稳定性较好。论文中使用了欧几里得距离、取距离的中值Emed来表示两点的接近性),通过这样筛选掉大于设置阈值的不稳定的匹配点,使用剩下的匹配点来预测目标的边界框。如果光流质量不好,则相应的预测效果也不会好!
但仅仅根据光流做预测是很冒险的,因为跟踪的目标可能来自检测算法的错误检测。所以作者添加对象检测器加以辅助,即如果已经确定跟踪到的目标在检测器的辅助检测下一直没有被检测到,则认为该追踪到的目标就是误报!所以作者利用之前的目标历史,计算已追踪目标Tk和检测目标Dk的在第k帧时的重叠程度o(Tk,Dk)。取过去k帧的检测中的中值数Omean: mean(o(Tk,Dk))。结合光流和检测器,得出奖励函数:
其中e0和o0为指定阈值。y(a)为正负一(对应继续保持追踪)。-y(a)表示变成lost状态

模板更新:
处理好追踪的模板后,需要更新目标的外观模型,以此适应外观变换。相比于一些在线方法当追踪到模板就更新外观模型的方法,会在更新过程中积累错误但得不更正,作者的方法使用“lazy”的更新原则,并采用了对象检测器来防止跟踪偏移。
具体来说, 如果跟踪中使用的模板能够跟踪目标, 则该模板将保持不变。每当模板由于外观更改而无法跟踪目标时, mdp 就会将目标传输到丢失状态。当目标从lost转换为tracked时, "跟踪" 模板将替换为关联的检测。(lost状态的处理策略)
而作者的“lazy”更新规则精华在于,将模板K存储为被跟踪模板的历史记录,跟踪中的模板也是K模板之一。但这些存储的模板可能不是最新模板,这也是为了解决在更新过程中,错误积累导致的失误。
Lost:该状态在MDP上需要决定下一步是lost还是tracked还是inactive。这个很好理解了,如果目标丢失经过帧数值超过设置的阈值,则将其设置为inactive,当处于lost状态的目标与某一检测结果关联时,才设置状态为Tracked,否则继续为lost。
数据关联:当目标处于lost状态,数据关联的关键则为如何找到目标和检测结果的关联。论文使用了![]() :即为lost的目标和当前检测的直接特征向量(Feature Representation.)。则对于lost的状态下的奖励函数为:
:即为lost的目标和当前检测的直接特征向量(Feature Representation.)。则对于lost的状态下的奖励函数为:

(w,b)是控制函数的参数,当从lost转换为tracked时,y(a)=1;当lost目标保持原状态时,y(a)=-1。在lost阶段的policy学习的目标,就是来学习到决策函数中的参数(w,b)。
增强/强化学习:(什么是强化学习?https://www.cnblogs.com/jinxulin/p/3511298.html)
-------------------------------------------------------------------------------------------
强化/增强学习:
1. 增强学习是试错学习(Trail-and-error),由于没有直接的指导信息,智能体要以不断与环境进行交互,通过试错的方式来获得最佳策略。
2. 延迟回报,增强学习的指导信息很少,而且往往是在事后(最后一个状态)才给出的,这就导致了一个问题,就是获得正回报或者负回报以后,如何将回报分配给前面的状态。
-------------------------------------------------------------------------------------------
在MDP中,本文通过增强学习方法训练二进制分类器。初始化权重(w0,b0)开始训练,并设置二类分类器的训练样本为空。这里的二类分类器值在MDP犯错时候进行更新;强化学习的目的则是为了训练MDP用于成功追踪所有的目标。其主要增强学习算法流程如下:

Feature Representation:文章主要设计特征向量描述目标t和检测结果d的相似性。目标在历史K个视频流中出现被K个templates代表,通过光流法判断每个template和检测结果的相似性,后面通过光流结果加入bbox的相似性来作为特征。
Multi-Object Tracking with MDPs:
对于多目标跟踪问题,文章为每个对象指定一个 mdp, mdp 遵循学习的策略来跟踪该对象。给定一个新的输入视频帧, 跟踪状态中的目标首先进行处理, 以确定它们是应保持在跟踪状态还是应传输到丢失状态。然后计算了目标未覆盖的丢失目标和目标检测之间的成对相似性, 采用基于边界框重叠的非最大抑制来抑制覆盖检测, 并给相似性评分由二进制分类器计算的数据关联。之后, 在匈牙利算法 [29] 中使用相似性分数来获取检测和丢失目标之间的分配。根据分配, 链接到某些对象检测的丢失目标将转移到跟踪状态。最后, 我们为每个对象检测初始化一个 mdp, 任何对象的检测都不会被追踪的目标所覆盖。同时,跟踪目标在跟踪中的优先级高于丢失的目标, 并且被跟踪目标所覆盖的检测被抑制, 以减少数据关联中的歧义。

Conclusion:
文章提出了一种新的基于马尔可夫决策过程的在线多目标跟踪框架, 其中一个对象的生存期是用一个具有四个状态子空间 (活动、跟踪、丢失和非活动) 的 mdp 建模的。mdp 中的状态转换自然处理跟踪中物体的出生死亡和消失。将数据关联的相似函数作为 mdp 策略的一部分, 并进行强化学习。我们的框架是通用的集成与不同的技术, 在对象检测, 单个对象跟踪和数据关联使用它们的 mdp 策略学习。我们已经测试了具有挑战性的 mot 基准跟踪框架的实现, 该基准的性能优于在基准测试的最新方法, 其显著优势