【论文笔记】A promotion method for generation error-based video anomaly detection
关键词: 2020年、GE-based 、 block-level GE
摘要
基于生成误差(GE)的方法在此任务中表现出良好的性能。该方法首先训练生成神经网络生成正态样本,然后将梯度(GEs)较大的样本判断为异常。几乎所有基于GE的方法都利用框架级GEs来检测异常。然而,异常通常发生在局部区域,帧级GE将正常区域的GEs引入异常检测中,这带来了两个问题 i)正常区域的GEs降低了异常帧的异常显著性 ii)不同的视频具有不同的正态水平,很难对不同的视频设置一个统一的阈值来检测异常。针对这些问题,我们提出一种推广方法:使用 the maximum of block-level GEs on the frame 来检测异常。首先计算the block-level GEs at each position on the frame。然后用the maximum of the block-level
GEs on the frame检测异常。在已有的生成神经网络(GNN)模型的基础上,对多个数据集进行了实验。
1.介绍
许多作品用GNN的GE来检测异常。他们首先训练一个GNN来生成正态样本,然后将大梯度值的样本判断为异常。用训练好的GNN模型和ground truth,可以计算出GE (intensity)map。

许多研究[4-6]通过对每个视频片段的GEs进行归一化来解决这个问题。但是这种方法也带来了另一个问题:即使不存在异常,在每个视频片段中都会产生很高的异常分数。这种方法会带来较高的误报率。
本文针对上述问题提出了一种推广方法。减小了正常区域GEs对异常检测的干扰。在测试阶段,在生成GE图后,我们首先计算各个场景的块级GE(block-level GE)。然后用帧内block-level GE最大值来检测异常。这一过程可以通过平均滤波操作和最大池化操作实现。

3.方法
基于GE的深度学习方法的过程可以分为两个步骤:训练步骤和测试步骤。测试阶段使用了我们的推广方法。
3.1. GE-maps
训练GNN后,用GNN生成GE maps
ς --GNN
I ˆ – ς的输出
I --Iˆ的地面真实值
C --I的通道数
i,j–视频帧的空间坐标
L n --计算误差时的范数

3.2. Block-level process
Saliency–显著性
L–GE值
P–I上的的像素个数
ei --GE图正常或异常上,第i个正常像素的GE值
e’j–异常帧上,第j个异常像素的GE值
n–异常帧上的异常像素个数

我们可以假设,异常帧中正常区域的GE = 正常帧中相应正常区域的GE。
将式(3)(4)代入式(2),则异常显著性为:

Saliency与![]() (异常帧中正常区域的GE)
(异常帧中正常区域的GE)
成反比,意味着:正常区域的GE对最终GE贡献越高,异常帧的GE显著性就越低。
因此,通过减少正常区域的GE对最终GE的贡献,可以提高异常显著性。
在本文中,我们通过将帧级GE替换为块级GE来实现这一目标:首先在框架上放置一个尺寸固定的滑动窗口,计算每个窗口位置的块级GE。然后在帧上选取块级GEs的最大值进行异常检测。
K–一帧的总块数
h,w–块的高度和宽度
(6)–第k个块Bk的block-level GE
块级操作可以通过平均滤波器的卷积层和最大池化层来实现。因此,该操作可以在GPU上加速。在块级处理之后,使用中值滤波器沿时间轴平滑GEs,滤波器的中值半径设为15。
3.3. Anomaly score
我们通过对整个数据集的GEs进行归一化来计算异常分数,而不是对每个视频进行归一化。对每个视频片段中的GEs进行归一化处理,会在每个视频片段中产生较高的异常值,这样即使不存在异常,也会在每个视频片段中检测到异常。
min (LB)和max (LB) – 数据集中所有帧的GEs的最小值和最大值

当一帧有多个异常分数时,我们利用它们的加权和来计算最终的异常分数:
si(t)–数据集第t帧的第i次异常分数
αi --si(t)的权重

4.实验
[6]作为baseline,因为 i)它是一个典型的基于GE的方法 ii)它提供多种GE maps:pixel-
value GE 、optical flow GE、gradient value GE
从三个角度来评估有效性: i) anomaly saliency, ii) normal-GE-level, iii)
anomaly detection performance
然后分析了块大小、中值滤波半径、不同归一化方法 对异常检测性能的影响。
4.1数据集和评估标准
数据集:CUHK Avenue、UCSD Pedestrian
Avenue数据集包含16个训练视频和21个测试视频。异常事件包括跑步、扔书包、扔纸等。
UCSD数据集有两个子数据集:Ped1、Ped2。两个子数据集捕捉不同的场景,但对异常事件有相似的定义,包括骑自行车、玩滑板、穿越草坪、开车等。这两个子数据集通常是分开使用的。
评估标准:最常用的评价指标是ROC和曲线下面积(AUC)。AUC值越高,异常检测性能越好。在[6]中,我们检测帧级异常并使用帧级AUC来评估性能。
4.2block-level对异常显著性的影响
首先可视化frame-level GE曲线和block-level GE曲线。然后,在多个数据集和多种类型GE图上计算并比较块级处理前后的异常显著性。
frame-level GE curve 、 block-level GE curve are shown in:
在块级过程中,我们设h = w = 30。
下表也证明了块级GEs的异常显著性远远高于框架级GEs,证明块级过程有助于提高异常显著性
在公式(8)中,用所有正常帧的GEs平均值来替换L normal,用所有非正常帧的GEs平均值来替换Labnormal。
4.3 block-level对normal-GE-levels的影响
不同的视频片段有不同的normal-GE-levels,这干扰了异常检测。在本节中,我们从三个方面证明了block-level解决这一问题的有效性
i)证明normal-GE-levels与前景目标数正相关
ii)我们证明了block-level可以降低前景目标数与normal-GE-levels之间的相关性。
iii)我们证明了block-level可以减少不同视频片段间的normal-GE-levels差别
图4显示了在框架级和块级GE pixel Ped2数据集中,normal-GE-levels和前景目标数之间的关系
h = w = 30 ,滤波器的中值半径=15
在Ped2数据集中,所有视频片段都很短,我们可以假设一个视频片段中的前景目标数量是稳定的。因此,我们计算每个视频中前景目标数的平均值。为了将GE曲线和前景目标数字曲线形象化,我们将前景目标数字除以一个固定的值。

蓝色曲线表示不同帧的GE。
绿色曲线反映了不同视频片段中前景目标数量的平均值。
灰色区域表示正常帧,红色区域表示异常帧。
(a)frame-level GEs和前景目标数量间的关系
(b)block-level GEs和前景目标数量间的关系
表2显示了前景目标数量和normal-GE-levels之间的相关系数。
从图4和表2可以看出,前景目标数与normal-GE-levels之间的相关性较高,而block-level process可以降低这种相关性。
在表3中,我们利用了Ped2中的几组样本,来证明block-level process对于(减少不同normal-GE-levels之间差异)的有效性。我们用拥挤正常视频的normal-GE-levels除以不那么拥挤的正常视频的normal-GE-levels得到一个比率,并用这个比率来衡量不同的normal- GE-levels之间的差异程度。比值越接近1,差异就越小。

如表3所示,block-level GEs的比率接近于1,这说明block-level process可以减少不同normal-GE-levels之间的差异。表3中,视频的Indexes与图4中所示相同。
4.4 block-level process对AUC的影响
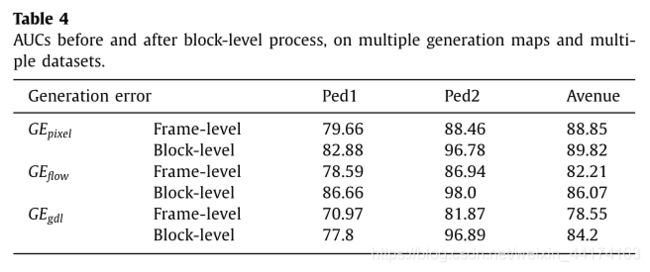
用frame-level AUC评价block-level process的效果。
如表4所示,对多数据集的和多类型GE图进行block-level process后,frame-level AUCs得到了显著提升,证明了block-level process对异常检测的有效性。
4.5 最优block-size
block-level process对AUCs的提升呈先升后降的趋势

图5 (b-d)显示了不同数据集中的最佳块大小,不同的数据集有不同的最佳块大小,我们认为原因在于:异常通常是由目标引起的,设置一个大的候选区间来设置block-size,可以提高异常检测性能

然而当设置block-size=1时,在ped2上,GE(pixel)的表现(AUC=81.9)低于frame-level GE (pixel)(AUC = 88.5),我们认为是因为当块大小设置的太小时,块级过程容易受到噪声的影响。所以,把block-size设置为target-level size最佳。
4.6不同中值滤波半径的影响
模型生成的GEs中含有噪声,本文采用中值滤波方法对噪声进行滤波。
在图6中,我们可视化了各参数相对于中值滤波器半径的灵敏度。
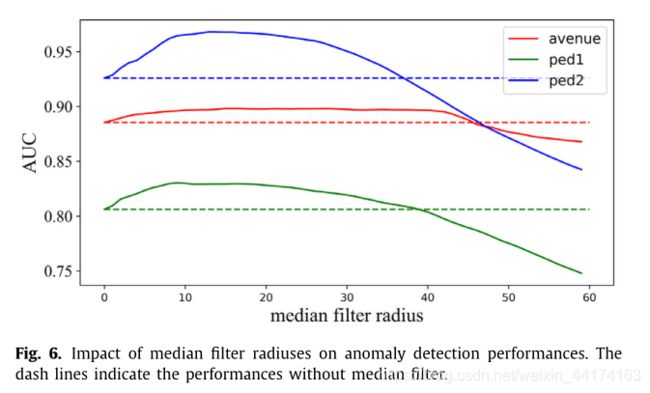
从图中可以看出,中值滤波有助于提高异常检测性能,且中值滤波半径的候选区间较大。
4.7 不同规范化方法的影响
计算异常分数有两种归一化方法 i)对整个数据集中的GEs进行规格化 ii)对每个视频中的GEs进行规格化。我们分别称它们为norm_whole和norm_each。
在视频异常检测任务中,可以考虑两种应用场景: i)当已知视频中存在异常时,只需定位异常的时间位置即可。ii)我们事先不知道视频是否包含异常,我们需要确定视频是否包含异常,同时定位异常事件发生的时间。
在第一个场景中,我们使用数据集的测试数据作为评估集,因为在Ped1、Ped2和Avenue数据集中,每个测试视频都包含异常。在第二个场景中,我们使用每个数据集中的所有训练视频和测试视频来形成评估集,因为所有的训练视频都是正常视频,而所有的测试视频都包含异常。
图7为Ped2数据集中,block-level GE (pixel)在不同归一化方法下产生的异常分数

从图7 (a)可以看出,norm_whole下的异常分数曲线与图4 (b)中的GE像素曲线相似,这是因为所有异常分数都是在统一的归一化标准下由GE像素计算的。如图7 (b)所示,norm_each无论视频是否包含异常事件,对每个视频中的GE像素归一化为[0,1]
表6给出了多个数据集中不同块级GEs生成的异常分数在不同场景和归一化方法下的异常检测性能
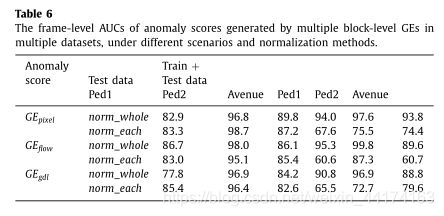
在第一种仅使用测试数据作为评价集的情况下,不同归一化方法下异常分数的异常检测性能具有竞争力。这意味着在处理不同场景密度对异常检测的影响时,块级处理和norm_each可以达到大致相同的效果。因此,在本例中,我们可以使用norm_whole或norm_each来计算异常分数。
在结合训练数据和测试数据形成评价集的第二种情况下,在norm_whole下生成的异常分数的异常检测性能要远远高于在norm_each下生成的异常分数。一般来说,在训练数据上的表现往往是高的。但在使用norm_each时,训练数据和测试数据的AUCs比测试数据要低。出现这种现象的原因是,norm_each在每个视频片段中都产生了强异常分数,如图7 (b)所示,尽管视频中不存在异常。它给普通视频带来了很多不必要的误报,比如训练视频。因此,norm_each不适用于评价集中包含正常样本的情况.
在实际应用程序中,大多数情况是第二种情况。因此,我们采用norm_whole来计算异常分数
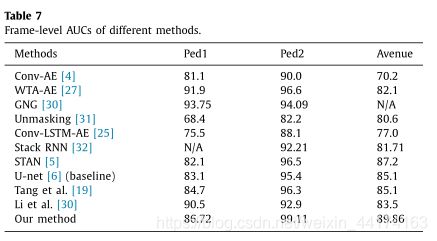
4.8 与现有方法比较
利用公式(9),把GE(pixel)产生的异常分数S(pixel)加GE(flow)产生的异常分数S(flow)得到最终异常分数。

异常检测性能如表7所示,在块级过程中,我们设h = w = 30,设中值滤波器半径为15。与基线[6]相比,我们的方法在所有数据集上显著提高了框架级AUC,证明了该方法的有效性。与其他方法相比,我们在Ped2和Avenue数据集上取得了最先进的性能。
5.结论
在本文中,我们提出了一种基于GE的异常检测方法的改进方法: 利用block-level process减少正常区域GE对异常检测的干扰。在多数据集上的实验表明,该方法有效地提高了基于GE方法的异常检测性能,并在多数据集上达到了最先进的检测性能。