CNN卷积神经网络之EfficientNet V2
CNN卷积神经网络之EfficientNet V2
- 前言
- EfficientNetV1中存在的问题
- NAS 搜索
- 网络结构
- Progressive Learning渐进学习策略
前言
《EfficientNetV2: Smaller Models and Faster Training》
论文地址:https://arxiv.org/abs/2104.00298
EfficientNetV2这篇文章是在2021年发布的,刚出来没多久我就看了,不过现在才有时间整理一下。EfficientNetV2在V1上做了一些改进,先看一下性能对比:
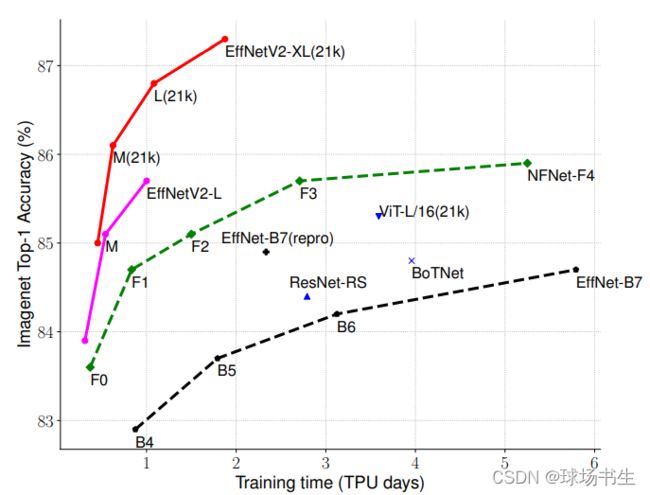
(21k)表示是经过ImageNet21k预训练之后pretrain的,利用预训练的模型,性能也提升不少。
EfficientNetV1中存在的问题
-
训练图像的尺寸很大时,训练速度非常慢。
针对这个问题一个比较好想到的办法就是降低训练图像的尺寸。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size。 -
在网络浅层中使用Depthwise convolutions速度会很慢。
虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的算子实现加速。近些年,有人开始融合部分卷积结构来实现加速(yolov5里也有类似操作)。Fused-MBConv结构非常简单,即将原来的MBConv结构主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3:

作者也在EfficientNet-B4上做了一些测试,发现将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度。可以看见理论的计算量增长很多,但实际的推理速度却是更快的。

但如果将所有stage都替换成Fused-MBConv结构会明显增加参数数量以及FLOPs,训练速度也会降低。所以作者使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。 -
同等的放大每个stage是次优的。
在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中,作者采用了非均匀的缩放策略来缩放模型。
NAS 搜索
针对上述问题,需要搜索以下的设计空间:
- convolutional operation type : {MBConv, Fused-MBConv}
- number of layer
- kernel size : {3x3, 5x5}
- expansion ratio (MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3): {1, 4, 6}
网络结构
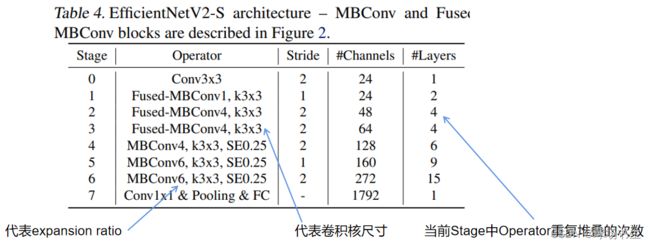
注意:源码中与表格中的通道数有出入。Conv3x3就是普通的3x3卷积 + 激活函数(SiLU)+ BN。还需要注意的是,当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。与最后全连接的dropout不一样。

源码配置参数:
v2_s_block = [ # about base * (width1.4, depth1.8)
'r2_k3_s1_e1_i24_o24_c1',
'r4_k3_s2_e4_i24_o48_c1',
'r4_k3_s2_e4_i48_o64_c1',
'r6_k3_s2_e4_i64_o128_se0.25',
'r9_k3_s1_e6_i128_o160_se0.25',
'r15_k3_s2_e6_i160_o256_se0.25',
]
r代表当前Stage中Operator重复堆叠的次数
k代表kernel_size
s代表步距stride
e代表expansion ratio
i代表input channels
o代表output channels
c代表conv_type,1代表Fused-MBConv,0代表MBConv(默认为MBConv)
se代表使用SE模块,以及se_ratio
v2_m_block = [ # about base * (width1.6, depth2.2)
'r3_k3_s1_e1_i24_o24_c1',
'r5_k3_s2_e4_i24_o48_c1',
'r5_k3_s2_e4_i48_o80_c1',
'r7_k3_s2_e4_i80_o160_se0.25',
'r14_k3_s1_e6_i160_o176_se0.25',
'r18_k3_s2_e6_i176_o304_se0.25',
'r5_k3_s1_e6_i304_o512_se0.25',
]
v2_l_block = [ # about base * (width2.0, depth3.1)
'r4_k3_s1_e1_i32_o32_c1',
'r7_k3_s2_e4_i32_o64_c1',
'r7_k3_s2_e4_i64_o96_c1',
'r10_k3_s2_e4_i96_o192_se0.25',
'r19_k3_s1_e6_i192_o224_se0.25',
'r25_k3_s2_e6_i224_o384_se0.25',
'r7_k3_s1_e6_i384_o640_se0.25',
]
Progressive Learning渐进学习策略
训练图像的尺寸对训练模型的效率有很大的影响。所以在之前的一些工作中很多人尝试使用动态的图像尺寸(比如一开始用小的图像尺寸,后面再增大),但通常会导致Accuracy降低。作者提出了一个猜想:Accuracy的降低是不平衡的正则化导致的。在训练不同尺寸的图像时,应该使用动态的正则方法(之前都是使用固定的正则方法)。

实验结果表明:当训练的图片尺寸较小时,使用较弱的数据增强augmentation能够达到更好的结果;当训练的图像尺寸较大时,使用更强的数据增强能够达到更好的接果。
基于以上实验,作者就提出了渐进式训练策略Progressive Learning。在训练早期使用较小的训练尺寸以及较弱的正则方法,这样网络能够快速的学习到一些简单的表达能力。接着逐渐提升图像尺寸,同时增强正则方法。
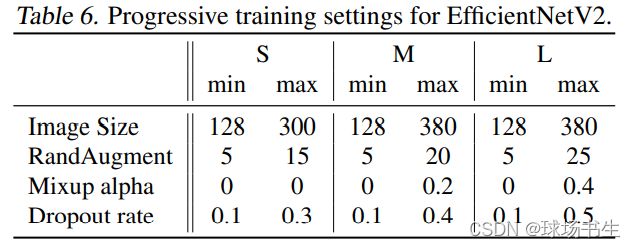
使用了渐进式学习策略后确实能够有效提升训练速度并且能够小幅提升Accuracy。
efficientnetv2_params = {
# (block, width, depth, train_size, eval_size, dropout, randaug, mixup, aug)
'efficientnetv2-s': # 83.9% @ 22M
(v2_s_block, 1.0, 1.0, 300, 384, 0.2, 10, 0, 'randaug'),
'efficientnetv2-m': # 85.2% @ 54M
(v2_m_block, 1.0, 1.0, 384, 480, 0.3, 15, 0.2, 'randaug'),
'efficientnetv2-l': # 85.7% @ 120M
(v2_l_block, 1.0, 1.0, 384, 480, 0.4, 20, 0.5, 'randaug'),
'efficientnetv2-xl':
(v2_xl_block, 1.0, 1.0, 384, 512, 0.4, 20, 0.5, 'randaug'),
# For fair comparison to EfficientNetV1, using the same scaling and autoaug.
'efficientnetv2-b0': # 78.7% @ 7M params
(v2_base_block, 1.0, 1.0, 192, 224, 0.2, 0, 0, 'effnetv1_autoaug'),
'efficientnetv2-b1': # 79.8% @ 8M params
(v2_base_block, 1.0, 1.1, 192, 240, 0.2, 0, 0, 'effnetv1_autoaug'),
'efficientnetv2-b2': # 80.5% @ 10M params
(v2_base_block, 1.1, 1.2, 208, 260, 0.3, 0, 0, 'effnetv1_autoaug'),
'efficientnetv2-b3': # 82.1% @ 14M params
(v2_base_block, 1.2, 1.4, 240, 300, 0.3, 0, 0, 'effnetv1_autoaug'),
}
参考:https://blog.csdn.net/qq_37541097/article/details/116933569
上一篇:CNN卷积神经网络之EfficientNet