context encoder代码注释
提示:文章主要是对context encoder的部分代码进行解析,并对论文中的实验内容进行复现。
本文是对《Context Encoders: Feature Learning by Inpainting》中的实验进行的复现,并对代码部分进行解释
- 会议/期刊:CVPR 2016
- 论文链接:CVPR 2016 Open Access Repository
- 代码链接:GitHub - BoyuanJiang/context_encoder_pytorch: PyTorch Implement of Context Encoders: Feature Learning by Inpainting
- 作者:Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, Alexei A. Efros
- 单位:University of California, Berkeley
参考文章:(17条消息) context encoder代码解读_EstherWjj的博客-CSDN博客
网络结构以及对应代码解析
model.py
1.生成器网络G
本层网络输入为128*128的遮挡图片,输出为64*64的修复图片。
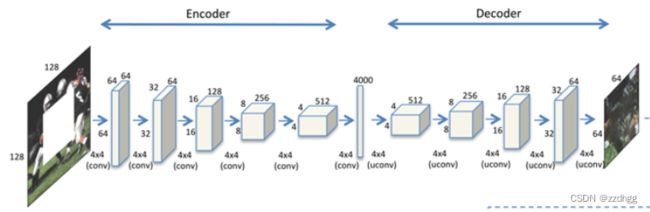
#定义生成器网络G 输入128*128
class _netG(nn.Module):
##定义了一个大类,主要完成两个任务:1.构造__init__函数,用来搭建网络中的每一层
#2.构建前向计算函数forword函数,连接各层
def __init__(self, opt):#定义网络中需要的算子,如卷积,全连接层
super(_netG, self).__init__()
self.ngpu = opt.ngpu #生成器feature map数
self.main = nn.Sequential(
#编码器 输入为128*128的遮挡图,经过5次采样卷积
# input is (nc) x 128 x 128 nc为通道数
nn.Conv2d(opt.nc,opt.nef,4,2,1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# layer2 state size: (nef) x 64 x 64,输出为64*32*32
nn.Conv2d(opt.nef,opt.nef,4,2,1, bias=False),#kernel_size=4,stride=2,padding=1
nn.BatchNorm2d(opt.nef),
nn.LeakyReLU(0.2, inplace=True),
# layer3 state size: (nef) x 32 x 32 输出为128*16*16
nn.Conv2d(opt.nef,opt.nef*2,4,2,1, bias=False),
nn.BatchNorm2d(opt.nef*2),
nn.LeakyReLU(0.2, inplace=True),
# layer4 state size: (nef*2) x 16 x 16 输出为256*8*8
nn.Conv2d(opt.nef*2,opt.nef*4,4,2,1, bias=False),
nn.BatchNorm2d(opt.nef*4),
nn.LeakyReLU(0.2, inplace=True),
# layer5 state size: (nef*4) x 8 x 8 输出为512*4*4
nn.Conv2d(opt.nef*4,opt.nef*8,4,2,1, bias=False),
nn.BatchNorm2d(opt.nef*8),
nn.LeakyReLU(0.2, inplace=True),
# 全连接层 state size: (nef*8) x 4 x 4
nn.Conv2d(opt.nef*8,opt.nBottleneck,4, bias=False),
# tate size: (nBottleneck) x 1 x 1 输出为4000*1*1
nn.BatchNorm2d(opt.nBottleneck),
nn.LeakyReLU(0.2, inplace=True),
# input is Bottleneck, going into a convolution
nn.ConvTranspose2d(opt.nBottleneck, opt.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(opt.ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(opt.ngf * 8, opt.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(opt.ngf * 4, opt.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(opt.ngf * 2, opt.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(opt.ngf, opt.nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
#上面的是将所有的层都放在了构造函数_init_里面,但是只是定义了一系列的层,各个层之间什么连接关系都没有,而实在forword里面实现所有层的连接关系
def forward(self, input):
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input)
return output定义了一个大类,主要完成两个任务:1.构造__init__函数,用来搭建网络中的每一层 2.构建前向计算函数forword函数,连接各层
2.判别网络D
此网络为真实的图像和生成器生成的图片
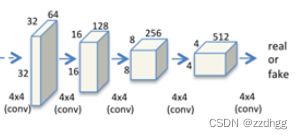
代码如下:
class _netlocalD(nn.Module):
def __init__(self, opt):
super(_netlocalD, self).__init__()
self.ngpu = opt.ngpu
self.main = nn.Sequential(
#输入遮挡部分的真实图像64*64
# input is (nc) x 64 x 64
nn.Conv2d(opt.nc, opt.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(opt.ndf, opt.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(opt.ndf * 2, opt.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(opt.ndf * 4, opt.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(opt.ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input)
return output.view(-1, 1)train.py
1.参数设置
1.通过add_argument函数添加各种参数
2.然后通过使用opt.统一调用
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', default='streetview', help='cifar10 | lsun | imagenet | folder | lfw ')
parser.add_argument('--dataroot', default='dataset/train', help='path to dataset')
parser.add_argument('--workers', type=int, help='number of data loading workers', default=2)
parser.add_argument('--batchSize', type=int, default=64, help='input batch size')
parser.add_argument('--imageSize', type=int, default=128, help='the height / width of the input image to network')
parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
parser.add_argument('--ngf', type=int, default=64)
parser.add_argument('--ndf', type=int, default=64)
parser.add_argument('--nc', type=int, default=3)
parser.add_argument('--niter', type=int, default=25, help='number of epochs to train for')
parser.add_argument('--lr', type=float, default=0.0002, help='learning rate, default=0.0002')
parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
parser.add_argument('--cuda', action='store_true', help='enables cuda')
parser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')
parser.add_argument('--netG', default='', help="path to netG (to continue training)")
parser.add_argument('--netD', default='', help="path to netD (to continue training)")
parser.add_argument('--outf', default='.', help='folder to output images and model checkpoints')
parser.add_argument('--manualSeed', type=int, help='manual seed')
parser.add_argument('--nBottleneck', type=int,default=4000,help='of dim for bottleneck of encoder')
parser.add_argument('--overlapPred',type=int,default=4,help='overlapping edges')
parser.add_argument('--nef',type=int,default=64,help='of encoder filters in first conv layer')
parser.add_argument('--wtl2',type=float,default=0.998,help='0 means do not use else use with this weight')
parser.add_argument('--wtlD',type=float,default=0.001,help='0 means do not use else use with this weight')
opt = parser.parse_args() #将上面定义的各种参数,统一使用opt.调用
print(opt)2.图像数据预处理
if opt.dataset in ['imagenet', 'folder', 'lfw']:
# folder dataset
dataset = dset.ImageFolder(root=opt.dataroot,
transform=transforms.Compose([ #transforms是pytorch的图像预处理包,用Compose进行多个步骤整合到一起
transforms.Scale(opt.imageSize), #调整到需要的大小
transforms.CenterCrop(opt.imageSize), #中心区域进行裁剪
transforms.ToTensor(), #将图像的灰度从(0,255)变化到(0,1)
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), #把(0,1)变换到(-1,1)
]))
elif opt.dataset == 'lsun':
dataset = dset.LSUN(db_path=opt.dataroot, classes=['bedroom_train'],
transform=transforms.Compose([
transforms.Scale(opt.imageSize),
transforms.CenterCrop(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
elif opt.dataset == 'cifar10':
dataset = dset.CIFAR10(root=opt.dataroot, download=True,
transform=transforms.Compose([
transforms.Resize(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
)
elif opt.dataset == 'streetview':
transform = transforms.Compose([transforms.Scale(opt.imageSize),
transforms.CenterCrop(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
dataset = dset.ImageFolder(root=opt.dataroot, transform=transform )
assert dataset
dataloader = torch.utils.data.DataLoader(dataset, batch_size=opt.batchSize,
shuffle=True, num_workers=int(opt.workers))3.初始化网络,权重初始化
# custom weights initialization called on netG and netD 对整个网络进行初始化定义,权重初始化
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
resume_epoch=0 #当整个数据集通过了神经网络一次并返回了一次,更新一次训练
netG = _netG(opt)
netG.apply(weights_init) #apply将搜索网络中所有的module,并把权重应用到所有的module中
if opt.netG != '':
netG.load_state_dict(torch.load(opt.netG,map_location=lambda storage, location: storage)['state_dict'])
resume_epoch = torch.load(opt.netG)['epoch']
print(netG)
netD = _netlocalD(opt)
netD.apply(weights_init)
if opt.netD != '':
netD.load_state_dict(torch.load(opt.netD,map_location=lambda storage, location: storage)['state_dict'])
resume_epoch = torch.load(opt.netD)['epoch']
print(netD)
criterion = nn.BCELoss() #二元交叉熵损失函数
criterionMSE = nn.MSELoss() #均方误差
input_real = torch.FloatTensor(opt.batchSize, 3, opt.imageSize, opt.imageSize)
input_cropped = torch.FloatTensor(opt.batchSize, 3, opt.imageSize, opt.imageSize)
label = torch.FloatTensor(opt.batchSize)
real_label = 1
fake_label = 0
#real_center = torch.FloatTensor(opt.batchSize, 3, opt.imageSize/2, opt.imageSize/2)
real_center = torch.FloatTensor(opt.batchSize, 3, int(opt.imageSize/2), int(opt.imageSize/2))4.优化器设置
# setup optimizer 通过梯度下降,不断重置参数,逐渐逼近最小的loss
optimizerD = optim.Adam(netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))5.训练生成器与判别器
输入为真实图片和生成器产生的假照片,然后对抗训练判别器。
#训练判别器,输入真实图片和生成器产生的假照片,然后对抗训练判别器网络
for epoch in range(resume_epoch,opt.niter):
for i, data in enumerate(dataloader, 0):
real_cpu, _ = data
real_center_cpu = real_cpu[:,:,int(opt.imageSize/4):int(opt.imageSize/4)+int(opt.imageSize/2),int(opt.imageSize/4):int(opt.imageSize/4)+int(opt.imageSize/2)]
batch_size = real_cpu.size(0)
input_real.resize_(real_cpu.size()).copy_(real_cpu)
input_cropped.resize_(real_cpu.size()).copy_(real_cpu)
real_center.resize_(real_center_cpu.size()).copy_(real_center_cpu)
input_cropped.data[:,0,int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred),int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred)] = 2*117.0/255.0 - 1.0
input_cropped.data[:,1,int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred),int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred)] = 2*104.0/255.0 - 1.0
input_cropped.data[:,2,int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred),int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred)] = 2*123.0/255.0 - 1.0
# train with real
netD.zero_grad() #判别器优化梯度全部为0
#让D尽可能把假照片判别为0
label.resize_(batch_size).fill_(real_label) #标签全部改为1(一开始判别为真实照片)
output = netD(real_center)
errD_real = criterion(output, label) #计算真实照片的损失值
errD_real.backward() #反向传输
D_x = output.data.mean()
# train with fake,D尽可能的把图片辨别为0
# noise.data.resize_(batch_size, nz, 1, 1)
# noise.data.normal_(0, 1)
fake = netG(input_cropped) #生成假图
label.data.fill_(fake_label) #把假图的标签全改为0
output = netD(fake.detach())
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.data.mean()
errD = errD_real + errD_fake #计算总损失
optimizerD.step() #优化判别器
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
#固定判别器,训练生成器,判别器判别生成的假图片为真
netG.zero_grad() #梯度全部降到零
label.data.fill_(real_label) # fake labels are real for generator cost
output = netD(fake) #判别刚刚生成的假图片
errG_D = criterion(output, label) #计算判别为假图片为真的损失值
# errG_D.backward(retain_variables=True)
# errG_l2 = criterionMSE(fake,real_center)
wtl2Matrix = real_center.clone()
wtl2Matrix.data.fill_(wtl2*overlapL2Weight)
wtl2Matrix.data[:,:,int(opt.overlapPred):int(opt.imageSize/2 - opt.overlapPred),int(opt.overlapPred):int(opt.imageSize/2 - opt.overlapPred)] = wtl2
#计算L2的误差值
errG_l2 = (fake-real_center).pow(2)
errG_l2 = errG_l2 * wtl2Matrix
errG_l2 = errG_l2.mean()
errG = (1-wtl2) * errG_D + wtl2 * errG_l2 #计算总损失函数
errG.backward()
D_G_z2 = output.data.mean()
optimizerG.step()6.保存图片
#输出结果
print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f / %.4f l_D(x): %.4f l_D(G(z)): %.4f'
% (epoch, opt.niter, i, len(dataloader),
errD.item(), errG_D.item(),errG_l2.item(), D_x,D_G_z1, ))
#保存图像
if i % 100 == 0: #每100张图片放在一张照片中
vutils.save_image(real_cpu,
'result/train/real/real_samples_epoch_%03d.png' % (epoch))
vutils.save_image(input_cropped.data,
'result/train/cropped/cropped_samples_epoch_%03d.png' % (epoch))
recon_image = input_cropped.clone()
recon_image.data[:,:,int(opt.imageSize/4):int(opt.imageSize/4+opt.imageSize/2),int(opt.imageSize/4):int(opt.imageSize/4+opt.imageSize/2)] = fake.data
vutils.save_image(recon_image.data,
'result/train/recon/recon_center_samples_epoch_%03d.png' % (epoch))
# do checkpointing
torch.save({'epoch':epoch+1,
'state_dict':netG.state_dict()},
'model/netG_streetview.pth' )
torch.save({'epoch':epoch+1,
'state_dict':netD.state_dict()},
'model/netlocalD.pth' )实验结果
我训练采用的训练集为celeba-256,三万张face照片。
训练两百轮结果如下:
测试结果如下:

总结
由于训练的数据集过于少,图像修复的结果相对较差,但是本文主要的目的是熟悉此论文的代码,以及实验结果。(上文可能有不少的错误欢迎批评,讨论)