mtcnn人脸检测_2020 机器学习人脸检测 MTCNN (1)
人脸识别对于我们今天已经不是什么稀奇的事,人脸识别无论是在门禁还是手机上都是必备的一项功能。今天我们就来聊一聊如何实现一个人脸识别系统。现在有很多库都支持人脸识别功能。
有关人脸识别任务通常人脸检测和人脸识别,那么什么是人脸检测(detect)和人脸识别(recognize),他们之间又什么区别呢?人脸检测是在图像中将人脸位置找到,会返回一个边界框将人脸位置以及宽高信息返回,也会返回 5 、68 或者 128 关键点,这些关键点表示出人眼睛、鼻子或者嘴角位置。更详细信息还会返回下颌的位置等。接下来通过对比两个特征点间相似度来识别人。
下面列出一些主流人脸检测以及识别库,接下来我们会意义介绍这些人脸识别库用法,以及人脸检测和识别背后理论,
- dlib
- MTCNN
- Facenet
- seetaFace
- 其他
人脸检测
今天用到是 MTCNN 来做人脸检测,用 faceNet 做人脸识别实现。
MTCNN (Multi-task Cascaded Convolutional Networks)
Multi-task Cascaded Convolutional Networks 多任务级联卷积神经网络,从字面上看就是这个意思。这里相对比较陌生的单词是 Cascaded,有瀑布落下和串联的意思。也就是说明我们图片进入到 MTCNN 后会被顺序处理,分别是图片缩放、P-Net、R-Net 和 O-Net,随后我们会按阶段给大家分析一下每一个阶段都做了哪些事情。
图片金字塔
我们都知道图片中的人脸尺寸有大有小,我们如何选择合适的预测框来框住人脸,这是我们第一个要解决的问题。我们通过使用不同尺寸的预测框,在图片上移动预测框来作为人脸检测的候选框。但是这个预测框需要最后需要输入到卷积通过 softmax 来进行判断,所以需要预测框大小一致,这样才可以进行卷积运算。所以可以通过调整图片大小而保持预测框大小不变来达到相同目的。
通常在 MTCNN 会定义一个 12×12 尺寸的预测框作为候选框。图片按一定系数进行缩放,知道缩放尺寸小于 12 为止。
import cv2
img = cv2.imread('face_dataset/ironman_actor.jpg')
img_lvl_01 = cv2.pyrDown(img)
img_lvl_01 = cv2.cvtColor(img_lvl_01,cv2.COLOR_BGR2RGB)
img_lvl_02 = cv2.pyrDown(img_lvl_01)
plt.imshow(img_lvl_01)
plt.show()
plt.imshow(img_lvl_02)
plt.show()



以上就是下图(Resize) 的步骤,有了这些尺寸不同图片了,我们就可以开始使用预测框在图片上按照一定步长来进行移动。通过 P-Net 我们会筛选掉一些预测框。每一个预测框五个数据,分别是表示预测框左上角和右下角的点坐标值和一个预测框的置信度的值。我们看一看如何通过计算来筛选掉一些不合适的框。这里介绍两个技术用于去掉多余的预测框。这里有许多预测框,这些预测框彼此两两重叠。

这里介绍一下 IOU 其实很简单就是两个矩形面积的交集除以这两个矩形的并集。这是用来衡量两个矩形重叠率,为什么要除以他们面积并集呢。这是为了将不同大小的矩形进行归一化所以除以面积来得到一个概率而不是单纯地考虑他们之间面积交集。通过计算重叠度我们就可以容易地检测出图片中的多个检测目标(人脸)。也就是将多个两两重叠预测框视为一个目标。这个如果大家不能理解,随后留言我通过图示给大家解释一下。
人脸识别应该不是什么新奇的东西,但是就看大家谁做的更好更快了。今天和大家一起聊一聊人脸识别基本打法。也就是用 mtcnn 做人脸识别,将人脸识别通过一个框识别出来,然后将输出人脸进行处理为 160 times 160160×160 图片输入到 facenet 中提取出 128 维特征点,最后计算不同图片经过上面处理得到 128 特征点计算距离来得到相似度,根据阈值来判断是否图片出现人为同一个人。这就是人脸的 pipeline。
import cv2
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
img = cv2.imread("data/imgs/naruto.jpg")
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.imshow(img)

今天我们来聊一聊人脸识别,当我们人类看到上面图片,一眼就可以认出这就是 naruto,是我个人比较喜欢一个动画中的主角。
face_box = [(450,0),(850,520)]
thickness = 4
lineType = 4
cv2.rectangle(img,face_box[0],face_box[1],(255,0,0),thickness,lineType)
plt.imshow(img)
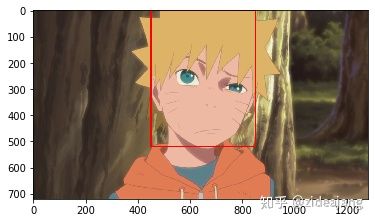
那么我们是如何完成这件事的呢?首先我们是找到人脸位置,要找到人脸位置我们就用到 mtcnn 来识别人脸的位置。
from mtcnn import MTCNN
mtcnn
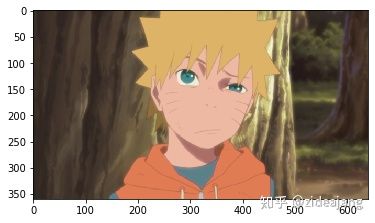
我们利用图像金子塔生成不同尺寸大小一系列图片,目的就是为了检查大小不同人脸。下面代码我们用 opencv 简单实现了一个如何获取一张图片一系列大小不同图片。
img = cv2.imread('data/imgs/naruto.jpg')
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
up_img = cv2.pyrUp(img)
img_1 = cv2.pyrDown(img)
img_2 = cv2.pyrDown(img_1)
plt.imshow(up_img)
plt.show()
plt.imshow(img)
plt.show()
plt.imshow(img_1)
plt.show()
plt.imshow(img_2)
plt.show()


Pnet
然后将图片金字塔生成图输入到Pnet,生成一堆人脸识别候选框,这些人脸候选框都是相对于原图的如下图。
img = cv2.imread("data/imgs/naruto.jpg")
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# plt.imshow(img)
face_box = [(450,0,850,520),(500,0,750,500),(500,10,850,500),(600,200,700,300),(600,200,300,200),(500,300,300,200)]
thickness = 4
lineType = 4
for i in range(len(face_box)):
cv2.rectangle(img,(face_box[i][0],face_box[i][1]),(face_box[i][2],face_box[i][3]),(255,0,0),thickness,lineType)
plt.imshow(img)
# plt.imshow(img)

Rnet
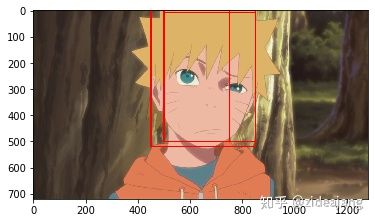
然后将这些人脸候选框截取图片输入到 Rnet 中,Rnet 会对图片中是否存在人脸进行判断评分。同时还对于原有人脸框进行修正。经过 Rnet 我们会得到一些相对正确的人脸框。
img = cv2.imread("data/imgs/naruto.jpg")
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# plt.imshow(img)
face_box = [(450,0,850,520),(500,0,750,500),(500,10,850,500)]
thickness = 4
lineType = 4
for i in range(len(face_box)):
cv2.rectangle(img,(face_box[i][0],face_box[i][1]),(face_box[i][2],face_box[i][3]),(255,0,0),thickness,lineType)
plt.imshow(img)
Onet
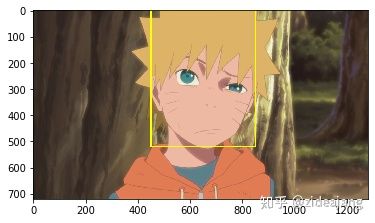
然后我们再次将 Rnet 筛选人脸候选框传入到 Onet 中,Onet 中是最精细网络筛选,其实也就是重复 Rnet 工作,对人脸框进行评分并进行修正。完成了 Onet 我们也就得到人脸位置。
img = cv2.imread("data/imgs/naruto.jpg")
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# plt.imshow(img)
face_box = [(450,0,850,520)]
thickness = 4
lineType = 4
for i in range(len(face_box)):
cv2.rectangle(img,(face_box[i][0],face_box[i][1]),(face_box[i][2],face_box[i][3]),(255,255,0),thickness,lineType)
plt.imshow(img)
Facenet
Facenet 就是输入一张人脸,然后进行特征提取,最终输出 128 维特征向量,通过比较特征向量我们辨识谁是谁。对比向量是我们事先准备好数据库,这里有代表标签的数据。然后将 facenet 提取出 128 维向量和数据库所有人脸向量进行比对,最终选择距离最短而且需要小于一定阈值的作为检测结果。
andy_img = cv2.cvtColor(cv2.imread, cv2.COLOR_BGR2RGB)
detector = MTCNN()
recognizer = detector.detect_faces(andy_img)
plt.imshow(andy_img)

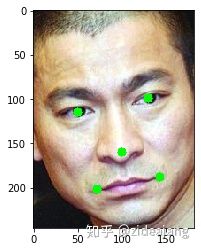
读取 Andy 图片,我们这里使用 opencv 读取图片,在 opencv 中默认颜色是 BGR 模式,但是正常的模式都是 RGB 模式所以我们需要调用 opencv 提供的 cvtColor 方法将图片数据格式转换为 RGB。然后调用 MTCHH 的 detect_faces 方法,这个方法会返回一个人脸对象集合,这里图片只有 Andy 一张脸,所以只有人脸对象,输出一下,看看检测人脸对象都包含哪些信息。
recognizer
[{'box': [77, 130, 257, 336],
'confidence': 0.9999997615814209,
'keypoints': {'left_eye': (144, 259),
'right_eye': (264, 251),
'nose': (207, 340),
'mouth_left': (166, 393),
'mouth_right': (257, 389)}}]
通常检测人脸会返回一个人脸框、和 5 个特征点分别是左右眼、鼻子和嘴角。下面我们将这些点显示出来
bounding_box = recognizer[0]['box']
right_eye = recognizer[0]['keypoints']['right_eye']
left_eye = recognizer[0]['keypoints']['left_eye']
nose = recognizer[0]['keypoints']['nose']
mouth_left = recognizer[0]['keypoints']['mouth_left']
mouth_right = recognizer[0]['keypoints']['mouth_right']
cv2.circle(andy_img,(right_eye[0],right_eye[1]),5,(0, 255, 0),-1 )
cv2.circle(andy_img,(left_eye[0],left_eye[1]),5,(0, 255, 0),-1 )
cv2.circle(andy_img,(nose[0],nose[1]),5,(0, 255, 0),-1 )
cv2.circle(andy_img,(mouth_left[0],mouth_left[1]),5,(0, 255, 0),-1 )
cv2.circle(andy_img,(mouth_right[0],mouth_right[1]),5,(0, 255, 0),-1 )
print(recognizer[0].get('box'))
andy_face_box = recognizer[0].get('box')
cv2.rectangle(andy_img,(andy_face_box[0],andy_face_box[1]),((andy_face_box[0] + andy_face_box[2]),(andy_face_box[1]+andy_face_box[3])),(255,255,0),thickness,lineType)
plt.imshow(andy_img)
[77, 130, 257, 336]

import os
face_list = os.listdir("face_dataset")
print(face_list)
['.DS_Store', 'andy.jpg', 'zidea.png']
face_encoding = []
face_name = []
for face in face_list:
if face.startswith("."):
continue
name = face.split(".")[0]
img = cv2.imread("face_dataset/"+face)
# print(img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
res = detector.detect_faces(andy_img)
rectangle = res[0]
接下来工作我们是处理这些人脸,根据人脸框将这些人脸截取出来,缩放到 160×160 正方形后输入 facenet 网络机会得到 128 维特征向量,然后我们是通过KNN 等算法计算两个张图片的距离来计算相似度。今天我们换一中用 PCA 来降维分析。
from 
cropped.save("face_dataset/andy_face.jpg")
我们在图像中有时候人脸可能是侧脸和歪着的脸,这些脸需要进行校正后在输入到 facenet 中进行特征提取,接下来我们就来做这件事。看如何通过特征点来校正人脸。这里还是用 Andy 图片作为例子来实现人脸校正的过程。
andy_img_1 = cv2.imread("face_dataset/andy_01.jpg")
# print(andy_img_1)
andy_img_1 = cv2.cvtColor(andy_img_1,cv2.COLOR_BGR2RGB)
recognizer_1 = detector.detect_faces(andy_img_1)
recognizer_1
[{'box': [103, 80, 182, 246],
'confidence': 0.9997475743293762,
'keypoints': {'left_eye': (153, 195),
'right_eye': (233, 179),
'nose': (203, 240),
'mouth_left': (175, 282),
'mouth_right': (246, 268)}}]
andy_1_face_box = recognizer_1[0].get('box')
cv2.rectangle(andy_img_1,(
andy_1_face_box[0],
andy_1_face_box[1]),
((andy_1_face_box[0] + andy_1_face_box[2]),
(andy_1_face_box[1]+andy_1_face_box[3])),
(255,255,0),thickness,lineType)
plt.imshow(andy_img_1)

img = Image.open("face_dataset/andy_01.jpg")
cropped_01 = img.crop((andy_1_face_box[0],andy_1_face_box[1],(andy_1_face_box[0] + andy_1_face_box[2]),
(andy_1_face_box[1]+andy_1_face_box[3])))
plt.imshow(cropped_01)
cropped_01.save("face_dataset/andy_face_01.jpg")
img_01 = cv2.imread("face_dataset/andy_face_01.jpg")
img_01 = cv2.cvtColor(img_01,cv2.COLOR_BGR2RGB)
plt.imshow(img_01)
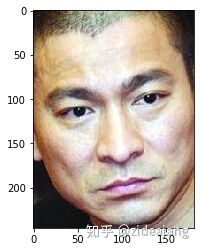
right_eye = recognizer_1[0]['keypoints']['right_eye']
left_eye = recognizer_1[0]['keypoints']['left_eye']
nose = recognizer_1[0]['keypoints']['nose']
mouth_left = recognizer_1[0]['keypoints']['mouth_left']
mouth_right = recognizer_1[0]['keypoints']['mouth_right']
cv2.circle(img_01,(right_eye[0] - andy_1_face_box[0],right_eye[1] - andy_1_face_box[1]),5,(0, 255, 0),-1 )
cv2.circle(img_01,(left_eye[0] - andy_1_face_box[0],left_eye[1] - andy_1_face_box[1]),5,(0, 255, 0),-1 )
cv2.circle(img_01,((nose[0] - andy_1_face_box[0]) ,(nose[1] - andy_1_face_box[1])),5,(0, 255, 0),-1 )
cv2.circle(img_01,((mouth_left[0] - andy_1_face_box[0]),(mouth_left[1] - andy_1_face_box[1])),5,(0, 255, 0),-1 )
cv2.circle(img_01,((mouth_right[0] - andy_1_face_box[0]),(mouth_right[1]- andy_1_face_box[1])),5,(0, 255, 0),-1 )
plt.imshow(img_01)