【读点论文】ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation,逐点卷积加上空洞卷积
ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
Abstract
-
本文引入了一种快速高效的卷积神经网络ESPNet,用于资源约束下的高分辨率图像语义分割。ESPNet基于一种新的卷积模块——高效空间金字塔(efficient spatial pyramid, ESP),它在计算、内存和功耗方面都非常高效。
-
ESPNet比表现良好的语义分割网络PSPNet快22倍(在标准GPU上),小180倍,而分类准确率仅低8%。本文在各种语义分割数据集上评估EPSNet,包括cityscape、PASCAL VOC和一个乳腺活检整个幻灯片图像数据集。
-
在相同的内存和计算限制下,ESPNet在标准指标和本文新引入的性能指标(衡量边缘设备上的效率)上都优于所有当前高效的CNN网络,如MobileNet、ShuffleNet和ENet。本文的网络可以在标准GPU和边缘设备上分别以每秒112帧和9帧的速度处理高分辨率图像。
-
论文地址:[1803.06815] ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation (arxiv.org)
Introduction
-
深度卷积神经网络(Deep convolutional neural networks, CNNs)在视觉场景理解任务中取得了很高的精度[Pyramid scene parsing network,Spatial pyramid pooling in deep convolutional networks for visual recognition,Deeplab]。虽然这些网络的精度随着深度和宽度的增加而提高,但大型网络速度缓慢,耗电量大。
-
这在计算量大的语义分割任务上尤其成问题[Segmentation-based urban traffic scene understanding,Da-rnn,Joint semantic segmentation and 3d reconstruction from monocular video]。例如,PSPNet具有6570万个参数,运行速度约为1 FPS,而标准笔记本电脑的电池放电速率为77瓦。许多先进的现实世界应用,如自动驾驶汽车、机器人和增强现实,都是敏感的,并要求在边缘设备上本地在线处理数据。这些精确的网络需要大量的资源,不适合边缘设备,这些设备的能量开销有限,内存限制有限,计算能力下降。
-
卷积分解已经证明了它在降低深度cnn(如Inception[Going deeper with convolutions,Rethinking the inception architecture for computer vision,Inception-v4], ResNext和Xception)的计算复杂度方面的成功。本文引入了一种基于卷积分解原理的高效卷积模块ESP(高效空间金字塔)(见下图)。
-
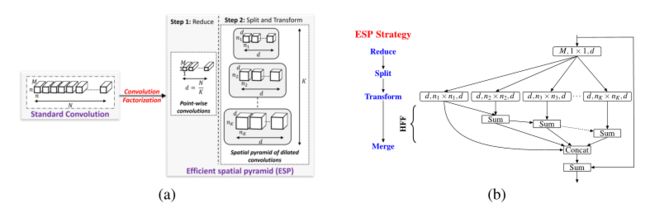
-
(a)将标准卷积层分解为逐点卷积和扩张卷积的空间金字塔,构建高效的空间金字塔(ESP)模块。
-
(b) ESP模块框图。ESP模块的有效接收域较大,引入了网格伪影,采用分层特征融合(HFF)去除网格伪影。增加了输入和输出之间的跨接,以改善信息流。展开的卷积层表示为(#输入通道,有效内核大小,#输出通道)。膨胀卷积核的有效空间维数为 n k × n k n_k × n_k nk×nk,其中 n k = ( n − 1 ) 2 k − 1 + 1 , k = 1 , ⋅ ⋅ ⋅ , k n_k = (n−1)2^{k−1} + 1,k = 1,···,k nk=(n−1)2k−1+1,k=1,⋅⋅⋅,k。注意,只有n × n个像素参与膨胀的卷积核。在我们的实验中n = 3, d = M K d =\frac MK d=KM。
-
-
基于这些ESP模块,本文提出了一种高效的网络结构ESPNet,可以轻松地部署在资源受限的边缘设备上。ESPNet是快速,小,低功耗,低延迟,但仍然保持分割精度。
-
ESP基于卷积分解原理,将一个标准卷积分解为两个步骤:(1)逐点卷积和(2)扩张卷积的空间金字塔,如上图所示。逐点卷积有助于减少计算量,而扩张卷积的空间金字塔对特征映射进行重新采样,从较大的有效接收野学习表征。本文证明了ESP模块比其他的卷积分解形式(如Inception和ResNext)更高效。
-
在相同的内存和计算限制下,ESPNet的表现优于MobileNet和ShuffleNet(另外两种基于因数分解原理的高效网络)。本文注意到现有的空间金字塔方法(例如[Deeplab]中的atrous空间金字塔模块)计算成本很高,不能在不同的空间层次上用于学习表示。
-
与这些方法相比,ESP算法计算效率高,可以在CNN网络的不同空间层次上使用。现有的基于扩张卷积的网络规模大,效率低,但本文的ESP模块以一种新颖高效的方式推广了扩张卷积的使用。
-
为了分析CNN网络在边缘设备上的性能,本文引入了一些新的性能指标,如对GPU频率的敏感性和曲速执行效率。为了展示ESPNet的强大功能,本文在人工智能和计算机视觉中最昂贵的任务之一:语义分割上评估了本文的网络。
-
经验证明,ESPNet在学习类似数量的参数时,比ENet(能效最高的语义分割网络之一)更准确、高效和快速。本文的结果还表明,ESPNet学习广义表示,并优于ENet另一个有效的网络ERFNet在没见过的数据集上。ESPNet可以在高端GPU上以每秒112帧的速度处理高分辨率的RGB图像,在笔记本电脑上以每秒21帧的速度处理,在边缘设备上以每秒9帧的速度处理。
Related Work
-
许多不同的技术,如卷积分解、网络压缩和低比特网络,已经被提出来加速卷积神经网络。本文首先简要介绍了这些方法,然后简要概述了基于cnn的语义分割。
-
Convolution factorization:
- 卷积分解将卷积运算分解为多个步骤,降低了计算复杂度。这种分解已经成功地展示了它在降低深度CNN网络(例如Inception系列, factorized network,ResNext , Xception和MobileNets)计算复杂度方面的潜力。ESP模块也是基于这种分解原理构建的。ESP模块将卷积层分解为逐点卷积和扩张卷积的空间金字塔。这种因子分解有助于降低计算复杂度,同时允许网络从一个较大的有效接受域学习表示。
-
Network Compression:
- 另一种建立高效网络的方法是压缩。这些方法使用哈希[Compressing neural networks with the hashing trick]、剪枝[Compressing deep neural networks with pruning, trained quantization and huffman coding]、向量量化[Quantized convolutional neural networks for mobile devices]和收缩[Icnet for real-time semantic segmentation on high-resolution images,Speeding up convolutional neural networks with low rank expansions]等技术来减小预训练网络的大小。
-
Low-bit networks:
- 另一种实现高效网络的方法是低比特网络,它通过量化权值来降低网络的规模和复杂性(例如[Xnor-net])。
-
Sparse CNN:
- 为了消除CNN中的冗余,提出了稀疏CNN方法,如稀疏分解[Sparse convolutional neural networks]、结构稀疏学习Learning structured sparsity in deep neural networks]、基于字典的方法[Lcnn: Lookup-based convolutional neural network]。本文注意到,基于压缩的方法、低比特网络和稀疏CNN方法同样适用于ESPNets,并且是本文工作的补充。
-
Dilated convolution:
-
扩展卷积[A real-time algorithm for signal analysis with the help of the wavelet transform]是标准卷积的一种特殊形式,通过在卷积核的每个像素之间插入零(或孔)来增加核的有效接收域。
-
对于膨胀率为r的n × n扩张卷积核,其有效大小为 [ ( n − 1 ) r + 1 ] 2 [(n−1)r + 1]^2 [(n−1)r+1]2。膨胀率指定像素之间的零(或孔)的数量。但是由于膨胀,只有n × n个像素参与卷积运算,在降低计算成本的同时增加了有效的内核大小。
-
Multi-scale context aggregation by dilated convolutions以递增的扩张速率叠加扩张的卷积层,从较大的有效接受场学习上下文表征。[Dilated residual networks,Learning to segment breast biopsy whole slide images,Understanding convolution for semantic segmentation]也采用了类似的策略。Chen等人介绍了一种atrous空间金字塔(ASP)模块。
-
这个模块可以看作是deeplab的并行版本。这些模块的计算效率很低(例如,asp对内存有很高的要求,需要学习更多的参数;见3.2节)。本文的ESP模块还使用扩展卷积并行学习多尺度表示;然而,它的计算效率很高,可以在CNN网络的任何空间层次上使用。
-
-
CNN for semantic segmentation:
- 人们提出了不同的基于cnn的分割网络,如多维递归神经网络,encoder-decoders[Enet,Erfnet,Segnet,U-net],[Hypercolumns for object segmentation and fine-grained localization],基于区域的表示,级联网络。一些支持技术和这些网络一起被用于实现高精度,包括集成特征、多阶段训练、来自其他数据集的额外训练数据、目标建议、基于crf的后处理和基于金字塔的特征重采样。
-
Encoder-decoder networks:
- 本文的工作与这有关。编码器解码器网络首先通过执行卷积和降采样操作来学习表示。然后通过执行上采样和卷积操作对这些表示进行解码。ESPNet首先学习编码器,然后附加一个轻量级解码器来生成分割掩码。这与现有的网络形成了对比,在这些网络中,解码器要么是编码器的精确复制(如[Segnet]),要么相对于编码器(如[Enet,Ernet])来说相对较小(但重量不轻)。
-
Feature re-sampling methods:
- 特征重采样方法使用不同的池化率和核大小对相同尺度的卷积特征映射进行重新采样,以实现高效分类。特征重采样的计算成本很高,并且只在分类层之前进行,以学习尺度不变表示。本文引入了一种计算效率高的卷积模块,允许在CNN网络的不同空间层次上进行特征重采样。
ESPNet
- 下面详细介绍了ESPNET的细节,并描述了构建ESPNET的核心ESP模块。本文将ESP模块与类似的CNN模块进行比较,如Inception系列, ResNext ,MobileNet,和ShuffleNet模块。
ESP module
-
ESPNet基于高效的空间金字塔(ESP)模块,该模块是一种卷积的分解形式,将标准卷积分解为逐点卷积和膨胀卷积的空间金字塔(见上图a)。ESP模块中的逐点卷积采用1 × 1卷积将高维特征映射投影到低维空间。
-
然后,扩张卷积的空间金字塔使用K, n × n个同时扩张的卷积核对这些低维特征映射重新采样,每个卷积核的扩张速率为 2 k − 1 , K = 1 , ⋅ ⋅ ⋅ , K 2^{k−1},K ={1,···,K} 2k−1,K=1,⋅⋅⋅,K。这种分解方法大大减少了ESP模块所需的参数数量和内存,同时保持了较大的有效接收域 [ ( n − 1 ) 2 K − 1 + 1 ] 2 [(n−1)2^{K−1} + 1]^2 [(n−1)2K−1+1]2。这种金字塔式卷积运算被称为扩张卷积的空间金字塔,因为每个扩张的卷积核学习不同接收域的权值,因此类似于空间金字塔。
-
标准卷积层取输入特征图 F i ∈ R W × H × M F_i∈\Bbb R^{W×H×M} Fi∈RW×H×M,应用N个核 K ∈ R m × n × M K∈\Bbb R^{m×n×M} K∈Rm×n×M生成输出特征图 F o ∈ R W × H × N F_o∈\Bbb R^{W×H×N} Fo∈RW×H×N,其中W和H表示特征图的宽度和高度,m和N表示核的宽度和高度,m和N表示输入和输出特征通道的数量。为了简单起见,本文假设m = n,因此标准卷积核学习 n 2 M N n^2MN n2MN参数。这些参数与n × n核的空间维数和输入M通道、输出n通道的数量密切相关。
-
Width divider K:
-
为了减少计算量,本文引入了一个简单的超参数K,它的作用是统一收缩网络中各个ESP模块的特征映射维数。
-
Reduce:对于给定的K, ESP模块首先通过逐点卷积将特征映射从m维空间缩减到N K维空间(上图a中的步骤1)。
-
split:然后将低维特征映射拆分到K个并行分支上。
-
Transform:然后每个分支使用 2 k − 1 , k = 1 , ⋅ ⋅ ⋅ , k − 1 2^{k−1},k ={1,···,k−1} 2k−1,k=1,⋅⋅⋅,k−1给出的n × n个扩张速率不同的卷积核同时处理这些特征映射(上图a中的步骤2)。
-
merge:然后将这K个并行扩展卷积核的输出连接起来,产生一个n维输出特征map。上图b展示了ESP模块采用的减少-分裂-转换-合并策略。
-
ESP模块具有 M N K + ( n N ) 2 K \frac{MN}{K}+ \frac{(nN)^2}K KMN+K(nN)2参数,其有效接收域为 [ ( n − 1 ) 2 K − 1 + 1 ] 2 [(n−1)2^{K−1} + 1]^2 [(n−1)2K−1+1]2与标准卷积的 n 2 N M n^2NM n2NM参数相比,采用两步分解的方法使ESP模块的参数总数减少了 n 2 M K M + n 2 N \frac{n^2MK}{M+n^2N} M+n2Nn2MK的一倍,同时有效接收域增加了约 [ 2 K − 1 ] 2 [2^{K−1}]^2 [2K−1]2。例如,当n = 3, n = M = 128, K = 4时,ESP模块的有效接收域为17 × 17,比标准卷积核(有效接收域为3 × 3)少学习3.6倍的参数。
-
-
Hierarchical feature fusion (HFF) for de-gridding:
-
虽然将扩张卷积的输出拼接在一起会给ESP模块带来一个较大的有效感受野,但也会引入不必要的棋盘或网格假象,如下图所示。
-

-
(a)举例说明一个网格伪像,其中单个活动像素(红色)与膨胀率r = 2的3×3膨胀卷积核卷积。
-
(b)具有和不具有层次特征融合(HFF)的ESP模块特征图可视化。ESP中的HFF消除了网格伪影。彩色观看效果最佳。
-
为了解决ESP中的网格问题,使用不同膨胀率的核获得的特征映射在拼接之前会进行层次化添加(上图b中的HFF)。该解决方案简单有效,且不会增加ESP模块的复杂性,这与现有方法不同,现有方法通过使用膨胀率较小的卷积核学习更多参数来消除网格误差[Dilated residual networks,Understanding convolution for semantic segmentation]。为了改善网络内部的梯度流动,ESP模块的输入和输出特征映射使用元素求和[Deep residual learning for image recognition]进行组合。
-
Relationship with other CNN modules
-
The ESP module shares similarities with the following CNN modules.
-
MobileNet module:
-
MobileNet模块,如下图a所示,使用深度可分离卷积[Xception],将标准卷积分解为深度卷积(变换)和点卷积(展开)。与ESP模块相比,它学习参数少,内存要求高,接收域低。ESP模块的一个极端版本(K = N)与MobileNet模块几乎相同,只是在卷积操作的顺序上有所不同。在MobileNet模块中,空间卷积之后是点向卷积;然而,在ESP模块中,点卷积之后是空间卷积。注意ESP模块的有效感受野 ( [ ( n − 1 ) 2 K − 1 + 1 ] 2 ) ([(n−1)2^{K−1} + 1]^2) ([(n−1)2K−1+1]2)高于MobileNet模块( [ n ] 2 [n]^2 [n]2)。
-
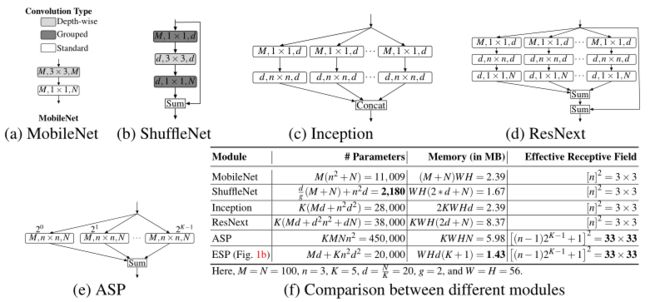
-
Different types of convolutional modules for comparison.
-
本文将该层表示为(#输入通道,内核大小,#输出通道)。(e)的膨胀速率在每一层的最上面。这里g表示分组卷积中卷积组的个数。为了简单起见,本文只报告(d)中卷积层的内存。为了将所需的内存转换为字节,将其乘以4(一个浮点数需要4字节存储)。
-
-
ShuffleNet module:
- 如上图b所示的ShuffleNet模块是基于reduce-transform-expand的原理。它是ResNet中瓶颈块的优化版本。为了减少计算量,shuffle使用了分组卷积和深度卷积。它将ResNet中瓶颈块中的1 × 1和3 × 3卷积分别替换为1 × 1分组卷积和3 × 3深度可分卷积。与ESP模块相比,Shufflenet模块学习的参数要少得多,但对内存的要求更高,接收域也更小。
-
Inception module:
- Inception模块是基于splitreduce-transform-merge的原则构建的。这些模块通常在通道数量和内核大小上是异构的(例如,一些模块是由标准卷积和因数卷积组成的)。与Inception模块相比,ESP模块设计简单明了。为了便于比较,上图c显示了Inception模块的同构版本。上图f是Inception模块和ESP模块的对比。ESP(1)学习的参数更少,(2)对内存的要求更低,(3)有效接收域更大。
-
ResNext module:
- 如上图d所示,ResNext模块是ResNet中瓶颈模块的并行版本,基于split-reduce - transform-expand-merge的原理。ESP模块与ResNext类似,涉及分支和残差求和。然而,ESP模块在内存和参数方面效率更高,有效接收域更大。
-
Atrous spatial pyramid (ASP) module:
- ASP模块基于拆分-转换-合并的原理构建,如上图e所示。ASP模块涉及到分支,每个分支学习内核在不同的接受域(使用扩张卷积)。虽然ASP模块具有高效的接收域,在分割任务中表现较好,但ASP模块对内存的要求较高,需要学习更多的参数。与ASP模块不同,ESP模块的计算效率很高。
Experiments
- 语义分割是人工智能和计算机视觉中最昂贵的任务之一。为了展示ESPNet的强大功能,本文在多个数据集上对ESPNet的性能进行了评估,用于语义分割,并与最先进的网络进行了比较。
Experimental set-up
-
Network structure:
-
ESPNet使用ESP模块学习卷积核以及下采样操作,除了第一层是标准的大步卷积。所有层(卷积和ESP模块)后面都有一个批归一化和一个PReLU非线性,除了最后一个点卷积,它既没有批归一化,也没有非线性。最后一层输入softmax进行像素级分类。
-
ESPNet的不同变体如下图所示。第一个变体,ESPNet-A(图a),是一种标准网络,它以RGB图像作为输入,并使用ESP模块学习不同空间层次的表示,以产生一个分割掩码。第二种ESP - b(图b)通过在之前的跨步ESP模块和之前的ESP模块之间共享特征映射,改善了ESPNet-A内部的信息流。第三种变体,ESPNet-C(图c),加强了ESPNet-B内部的输入图像,以进一步改善信息的流动。这三种变量产生的输出的空间维度是输入图像的1 / 8。第四种变体,ESPNet(图d),在ESPNet- c中添加了一个轻量级解码器(使用reduceupsample-merge的原理构建),输出与输入图像相同空间分辨率的分割mask。
-
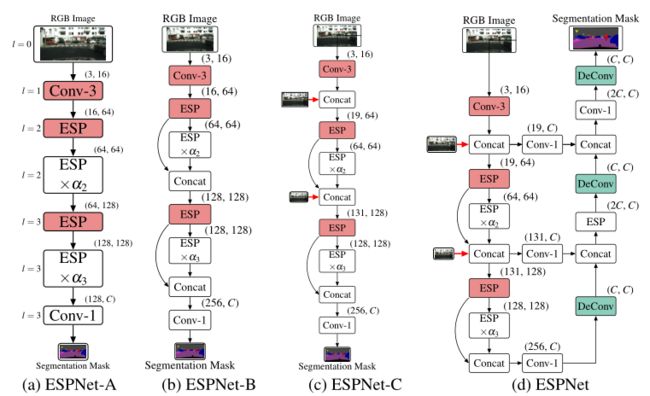
-
从ESPNet- a到ESPNet的路径。红色和绿色色框分别代表负责下采样和上采样操作的模块。空间级别的l在(a)中的每个模块的左侧。本文将每个模块表示为(#输入通道,#输出通道)。这里,conv-n表示n × n卷积。
-
为了在不改变网络拓扑结构的情况下构建具有较深计算效率的边缘设备网络,超参数α控制网络的深度;ESP模块在空间层次l上重复 α l α_l αl次。在更高的空间层次(l = 0和l = 1), cnn需要更多的内存,因为这些层次的特征图的空间维数较高。为了节省内存,ESP和卷积模块都不会在这些空间级别上重复。用于构建ESPNet(从ESPNet- a到ESPNet)的构建模块函数在附录B中进行了讨论。
-
-
Dataset:
-
本文在cityscape数据集上评估了ESPNet,该数据集是一个城市视觉场景理解数据集,包含2975张训练图、500张验证图和1,525张测试高分辨率图像。该数据集是在50个城市的不同季节采集的。该任务是将一幅图像分割成19个类,属于7个项目(例如:人和骑手类属于同一类人)。本文使用Cityscapes在线服务器在测试集上评估本文的网络。
-
为了研究泛化性,本文在一个没见过的数据集上测试了ESPNet。本文使用Mapillary数据集来完成这个任务,因为它具有多样性。本文将验证集(# 2000张图片)中的注释(65个类)映射到Cityscape数据集中的7个类别。为了进一步研究本文网络的分割能力,本文在来自不同领域的另外两个流行数据集上训练和测试了ESPNet。
-
首先,本文使用了众所周知的PASCAL VOC数据集,该数据集有1464张训练图像、1448张验证图像和1456张测试图像。任务是将图像分割成20个前景类。本文使用PASCAL VOC在线服务器在测试集(comp6类别)上评估本文的网络。
-
按照惯例,本文使用了来自[Semantic contours from inverse detectors,coco]的其他图像。其次,本文使用了乳腺活检整个幻灯片图像数据集,之所以选择该数据集,是因为生物医学图像中的组织结构在大小和形状上有所不同,而且因为该数据集允许本文检查从一个大的接收野学习表征的潜力。
-
该数据集由30张训练图像和28张验证图像组成,平均大小为10000 × 12000,远远大于自然场景图像。
-
-
Performance evaluation metrics:
- 大多数传统的CNNs通过精度、延迟、网络参数数量和网络大小来衡量网络性能(如[Mobilenets,Shufflenet,Enet,Erfnet,SqueezeNet])。这些指标提供了有关网络的高级信息,但无法证明有限的可用硬件资源的有效使用。除了这些指标之外,本文还引入了几个系统级指标来描述CNN在资源受限设备上的性能[Deep-dive analysis of the data analytics workload in cloudsuite,Performance characterization of high-level programming models for gpu graph analytics.]。
-
Segmentation accuracy
- 分割精度是由ground truth值和预测的分割掩码之间的平均交集(mIOU)分数来衡量的。
-
Latency
- 延迟表示CNN网络处理图像所需的时间。这通常是以每秒帧数(FPS)来衡量的。
-
Network parameters
- 网络参数表示网络学习到的参数个数。
-
Network size
- 网络大小表示存储网络参数所需的存储空间量。一个高效的网络应该有一个较小的网络大小。
-
Sensitivity to GPU frequency
- GPU频率敏感度衡量应用程序的计算能力,定义为执行时间变化百分比与GPU频率变化百分比的比值。数值越高,说明应用程序对GPU的利用效率越高。
-
Utilization rates
- 利用率是指运行在边缘设备上的计算资源(CPU、GPU和内存)的利用率。特别是,边缘设备(如Jetson TX2)中的计算单元在CPU和GPU之间共享内存。
-
Warp execution efficiency
- Warp执行效率定义为每次执行Warp中活动线程的平均百分比。gpu以warp的形式调度线程,warp中的每个线程都以单指令多数据的方式执行。曲速执行效率越高,说明GPU使用效率越高。
-
Memory efficiency
- 内存效率是请求/存储的字节数与从设备(或共享)内存传输/传输到设备(或共享)内存的字节数之比,以满足加载/存储请求。由于内存事务是在块中进行的,因此这个指标允许我们确定使用内存带宽的效率。
-
Power consumption
- 功耗是应用程序在推断期间所消耗的平均功率。
-
Training details:
-
使用PyTorch和CUDA 9.0和cuDNN后端对ESPNet网络进行训练。ADAM的初始学习率为0.0005,每100个epoch衰减2次,权重衰减为0.0005。交叉熵损失函数中使用了逆类概率加权方案来解决类不平衡问题[Enet,Erfnrt]。随机初始化权重。标准策略,如缩放、裁剪和翻转,被用来增加数据。Cityscape数据集的图像分辨率为2048 × 1024,所有的精度结果都是在这个分辨率下报告的。为了训练网络,本文对RGB图像进行了二次采样。当输出分辨率小于2048 × 1024时,采用双线性插值对输出进行上采样。为了在PASCAL数据集上进行训练,本文使用了固定大小为512 × 512的图像。
-
ESPNet的训练分为两个阶段。首先,ESPNet-C使用降采样注释进行训练。其次,在ESPNet- c上附加一个轻量级解码器,然后对整个ESPNet网络进行训练。
-
本文的实验使用了三种不同的GPU设备:(1)桌面使用NVIDIA TitanX GPU (3584 CUDA核),(2)笔记本使用NVIDIA GTX-960M GPU (640 CUDA核),(3)边缘设备使用NVIDIA Jetson TX2 (256 CUDA核)。有关硬件的详细信息,请参见附录A。
-
除非另有明确说明,对于大小为1024 × 512的RGB图像,在经过200次平均试验后,将报告诸如功耗和推理速度等统计数据。为了收集硬件级统计数据,使用了NVIDIA和Intel的硬件分析和跟踪工具,如NVPROF , Tegrastats和PowerTop。在本文的实验中,本文将α2 = 2和α3 = 8的ESPNet称为ESPNet,除非另有明确说明。
-
Results on the Cityscape dataset
-
Comparison with state-of-the-art efficient convolutional modules:
-
为了理解ESP模块,本文将ESPNet-C中的ESP模块替换为最先进的高效卷积模块,如图3所示(MobileNet , ShuffleNet, Inception 系列, ResNext,和ResNet),并评估它们在Cityscape验证数据集上的性能。本文没有与ASP进行比较,因为它的计算成本很高,不适合边缘设备。
-
下图对比了ESPNet-C不同卷积模块的性能。本文的ESP模块的性能分别比MobileNet和ShuffleNet模块高出7%和12%,同时学习的参数数量相似,网络大小和推理速度相当。此外,ESP模块的精度与ResNext和Inception相当,效率更高。一个基本的ResNet模块(两个3 × 3卷积的堆栈和一个跳跃连接)提供了最好的性能,但必须学习6.5×更多的参数。
-
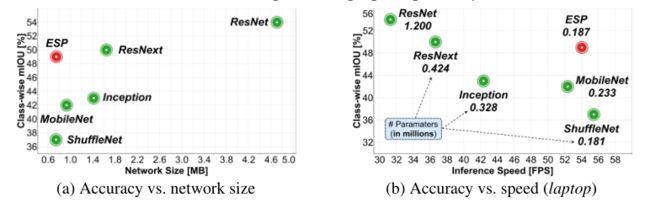
-
最先进的高效卷积模块之间的比较。为了公平的比较不同的模块,本文使用K = 5, d = N K d =\frac NK d=KN, α2 = 2, α3 = 3。本文使用标准的大步卷积进行降采样。对于ShuffleNet,本文使用g = 4和K = 4,这样得到的ESPNet-C网络与ESP块具有相同的复杂度。
-
-
Comparison with state-of-the-art segmentation methods:
-
本文比较了ESPNet和最先进的语义分割网络的性能。这些网络要么使用预先训练的网络(VGG: FCN-8s和SegNet, ResNet: DeepLab-v2和PSPNet,以及SqueezeNet : SQNet),要么从头训练(ENet和ERFNet)。下图比较了ESPNet和最先进的方法。ESPNet的准确率比ENet高出2%,而在台式机和笔记本电脑上的运行速度分别为1.27×和1.16×。
-
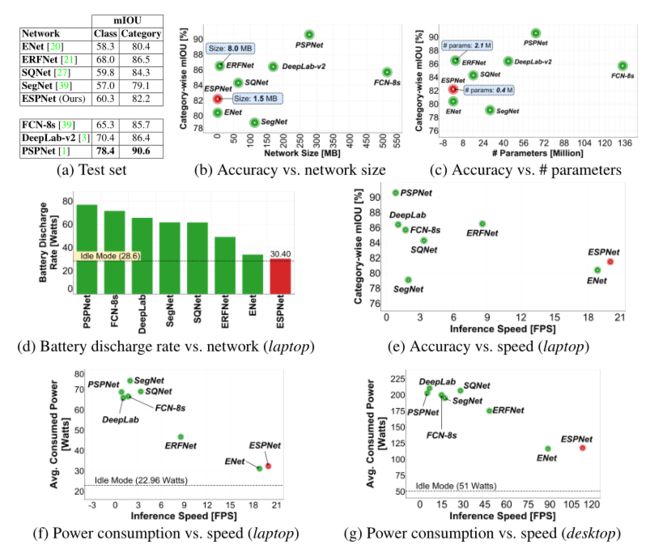
-
比较最先进的分割方法在城市景观测试集在两个不同的设备。所有网络(FCN-8s , SegNet , SQNet, ENet, DeepLabv2 , PSPNet, ERFNet)都没有条件随机场,并转换为PyTorch进行公平比较。彩色观看效果最佳。
-
ESPNet在属于同一类别的类之间会犯一些错误,因此类的精度较低。例如,骑手可能会与人混淆。然而,ESPNet提供了一个很好的分类精度。ESPNet的分类mIOU比PSPNet低8%,而学习的参数少180×个。ESPNet具有更低的功耗,更低的电池放电率,并且显著快于最先进的方法,同时仍然实现了具有竞争力的分类精度;这使得ESPNet适合在边缘设备上分割。另一种高效的分割网络ERFNet具有良好的分割精度,但比ESPNet多了5.5倍的参数,大了5.44倍,耗电更大,电池放电率也更高。此外,ERFNet不能有效地利用边缘设备上有限的可用硬件资源。
-
Segmentation results on other datasets
-
Unseen dataset:
-
下表a比较了ESPNet与ENet和ERFNet在不可见数据集上的性能。这些网络在cityscape数据集上训练,并在Mapillary数据集测试。
-

-
不同数据集的结果。这里,参数的数量以百万为单位,并且✳表明使用了更广泛的ESPNet版本。在l ={1,2,3}时,我们用(16,128,256)作为输出通道数,K = 4。参见附录F获得更多示例图像。
-
选择ENet和ERFNet,因为ENet是最有效的分割网络之一,而ERFNet具有较高的准确率和中等的效率。本文的实验表明,ESPNet学习了良好的对象泛化表示,并在不可见数据集上从定性和定量上优于ENet和ERFNet。
-
-
PASCAL VOC 2012 dataset:
- (上表c)在PASCAL数据集上,ESPNet比SegNet (PASCAL VOC上最小的网络之一)的准确率高4%,同时学习的参数少81×个。ESPNet的精度比PSPNet (PASCAL VOC上最精确的网络之一)低22%,同时学习的参数少了180倍。
-
Breast biopsy dataset:
- (上表d)在乳腺活检数据集上,ESPNet获得了相同的精度,同时学习了9.5×更少的参数。
Performance analysis on an edge device
-
本文在NVIDIA Jetson TX2上测量性能,这是一个边缘设备的计算平台。性能分析结果见下图。
-
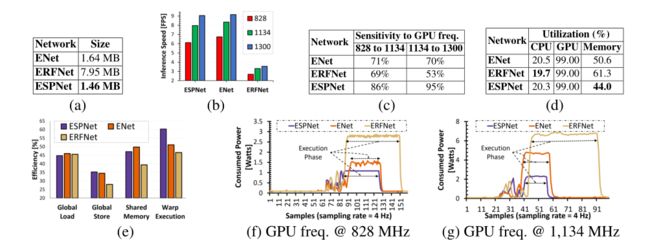
-
在NVIDIA Jetson TX2上使用ENet和ERFNet的ESPNet性能分析:(a)网络大小,(b)推断速度与GPU频率的对比(MHz), ©灵敏度分析,(d)利用率,(e)效率,以及(f, g)两种不同GPU频率下的功耗。在(d)中,没有考虑网络初始化阶段的统计,因为它们在所有网络中是相同的。参见附录E的时间与利用地块。彩色观看效果最佳。
-
-
Network size:
- 上图a对比了ESPNet与ENet和ERFNet的32位未压缩网络大小。ESPNet的网络大小分别比ENet和ERFNet小1.12×和5.45×,这很好地体现了ESPNet的架构设计。
-
Inference speed and sensitivity to GPU frequency:
- 上图b对比了ESPNet与ENet和ERFNet的推理速度。ESPNet与ENet的帧率基本相同,但对GPU频率更敏感(上图c)。因此,ESPNet在高端显卡(如GTX960M和TitanX)上实现了比ENet更高的帧率。例如,在NVIDIA TitanX上,ESPNet比ENet快1.27倍。在NVIDIA Jetson TX2上,ESPNet比ERFNet快3倍。
-
Utilization rates:
- 上图d比较了不同网络的CPU、GPU和内存利用率。这些网络是吞吐量密集型的,因此GPU利用率很高,而CPU利用率很低。这些网络的内存利用率有很大不同。与ENet和ERFNet相比,ESPNet的内存占用较低,这表明ESPNet适合内存受限的设备。
-
Warp execution efficiency:
- 上图e对比了ESPNet、ENet和ERFNet的warp执行效率。ESPNet的翘曲执行比ENet高出约9%,比ERFNet高出约14%。这表明ESPNet具有较小的warp divergence,促进了边缘设备上有限的GPU资源的有效利用。本文注意到翘曲执行效率比GPU利用率更能反映GPU资源的利用率。即使有少量的warp活动,GPU频率也会很忙,GPU利用率很高。
-
Memory efficiency:
- (上图e)所有网络的全局负载效率相似,但ERFNet的存储和共享内存效率较差。这可能是由于ERFNet将20%的计算能力用于执行内存对齐操作,而ESPNet和ENet在此操作上分别花费4.2%和6.6%的时间。参见附录C,了解不同内核的计算细分。
-
Power consumption:
- 上图f和g比较了ESPNet与ENet和ERFNet在两种不同GPU频率下的功耗。在网络执行阶段,ESPNet、ENet和ERFNet在GPU频率为824mhz时的平均功耗分别为1 W、1.5 W和2.9 W,在GPU频率为1134mhz时的平均功耗分别为2.2 W、4.6 W和6.7 W;说明ESPNet是一个节电网络。
Ablation studies: The path from ESPNet-A to ESPNet
-
更大的网络或集成多个网络的输出可以提供更好的性能,但对于ESPNet,目标是为边缘设备提供高效的网络。为了在保持效率的同时提高ESPNet的性能,对设计选择进行了系统研究。下表总结了结果。
-
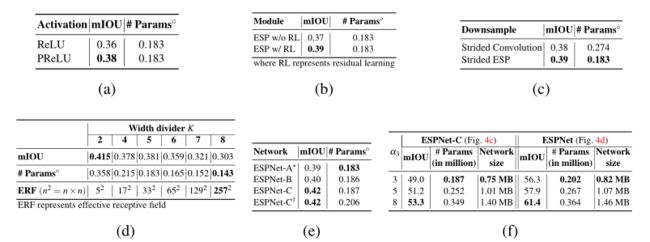
-
从ESPNet- a到ESPNet的路径。在这里,⭐表示下采样采用跨步ESP,†表示将输入增强法替换为输入感知融合法,◦表示数值为百万。(a-e)中的所有网络以α3 = 3训练100个epoch,而(f)中的网络以变量α3训练300个epoch。宽度分割器(K):(上表d)增加K会增大有效接收野
-
-
ReLU vs PReLU:
- (上表a)在ESPNet-A中用PReLU替换ReLU,准确率提高了2%,同时对网络复杂度的影响最小。
-
Residual learning in ESP:
- (上表b)当去除ESP模块中的跳接时,ESPNet-A的准确率下降了约2%。这验证了残差学习的有效性。
-
Down-sampling:
- (上表c)在ESPNet-A中用跨步式ESP替换标准的跨步式卷积,精度提高1%,参数减少33%。
-
Width divider (K):
- (上表d)增加K可以增大ESP模块的有效接收域,同时减少网络参数的数量。重要的是,ESPNet-A的准确率随着K的增加而下降。例如,将K从2提高到8会导致ESPNet-A的准确率下降11%。准确性下降的部分原因是ESP模块的有效感受野超出了输入特征映射的大小。对于1024 × 512的图像,输入的特征图在空间级l = 2和l = 3的空间维数分别为256 × 128和128 × 64。但是,有些核的接收域较大(K = 8时为257 × 257)。这些核的权值对学习没有帮助,导致精度较低。在K = 5时,本文发现参数数量和精度之间有一个很好的权衡,因此,本文在实验中使用K = 5。
-
ESPNet-A → ESPNet-C:
-
(上表e)将ESPNet-A中基于卷积的网络宽度扩展操作替换为ESPNet-B中的拼接操作,准确率提高了约1%,且网络参数数量没有明显增加。采用输入增强方法(ESPNet-C)后,ESPNet-B在没有大幅增加网络参数的情况下,准确率进一步提高了约2%。这可能是由于输入强化方法在输入图像和编码阶段之间建立了直接的联系,改善了信息的流动。
-
与本文的输入增强方法最接近的工作是[Learning to segment breast biopsy whole slide images]的输入感知融合方法,它学习下采样输入图像上的表示,并将它们与卷积单元相加结合。当本文提出的输入增强方法被[Learning to segment breast biopsy whole slide images]中的输入感知融合所取代时,准确率并没有提高,但网络参数的数量增加了约10%。
-
-
ESPNet-C → ESPNet:
- (上表f)在ESPNet- c中添加一个轻量级解码器将精度提高了约6%,而从ESPNet- c到ESPNet的参数数量和网络大小分别仅增加了20000和0.06 MB。
Conclusion
- 提出了一种基于空间金字塔模块的语义分割网络ESPNet。除了传统指标之外,本文还引入了一些新的系统级指标,这些指标有助于分析CNN网络的性能。本文的实证分析表明,espnet是快速和有效的。本文还演示了ESPNet可以很好地学习对象的泛化表示,并在自然数据集中表现良好。
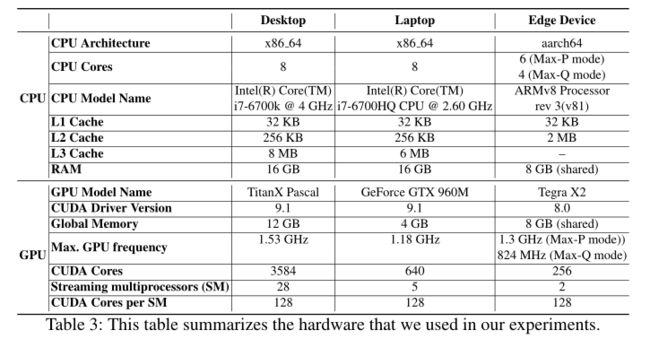
A Hardware Details
-
本文的实验用了三台机器。下表总结了关于这些机器的详细信息。边缘设备上的计算平台(例如Jetson TX2)在CPU和GPU之间共享全局内存或RAM,而笔记本和桌面设备有专用的CPU和GPU内存。
-
-
NVIDIA Jetson TX2可以在不同的模式下运行。在性能模式(Max-P)中,TX2中所有的CPU核都是启用的,而在正常模式(Max-Q模式)中,6个CPU核中只有4个是活动的。在这些模式下,CPU和GPU的时钟频率是不同的,因此,应用程序在不同的模式下会有不同的功耗需求。
B The path from ESPNet-A to ESPNet
-
ESPNet的不同变体如下图所示。第一种变体ESPNet-A(图8a)是一种标准网络,它以RGB图像为输入,并使用ESP模块学习不同空间层次的表示,以产生分割掩码。第二种ESP - b(图8b)通过在之前的跨步ESP模块和之前的ESP模块之间共享特征映射,改善了ESP - a内部的信息流。第三种变体,ESPNet-C(图8c),加强了ESPNet-B内部的输入图像,以进一步改善信息的流动。这三种变量产生的输出的空间维度是输入图像的1 / 8。第四种变体,ESPNet(图8d),在ESPNet- c中增加了一个轻量级解码器(使用简化采样原理构建),输出与输入图像相同空间分辨率的分割掩码。接下来将讨论用于构建ESPNet(从ESPNet- a到ESPNet)的构建模块函数。
-

-
从ESPNet- a到ESPNet的路径。红色和绿色色框分别代表负责下采样和上采样操作的模块。空间级别的l在(a)中的每个模块的左侧。我们将每个模块表示为(#输入通道,#输出通道)。这里,convn表示n × n卷积。
-
Efficient down-sampling:
-
最近的CNN架构在降采样操作中使用了大步卷积而不是池化操作,因为它允许学习非线性的降采样操作,同时允许扩展网络宽度。标准的跨步卷积运算是昂贵的;因此,它们被跨步式ESP模块所取代,以实现降采样。
-
ESP模块学习非线性降采样操作时,用n × n步卷积代替了逐点卷积。通过降采样操作改变特征图的空间维度。在[Deep residual learning for image recognition,Densely connected convolutional networks]之后,本文没有在降采样操作中使用跳接连接来组合输入和输出特征映射。
-
通过步进卷积和步进ESP学习到的参数个数分别为 n 2 M N n^2MN n2MN和 n 2 M N K + ( n 2 N 2 K 2 ⋅ K ) \frac{n^2MN}{ K} + (\frac{n^2 N^2}{K^2}·K ) Kn2MN+(K2n2N2⋅K),分别。通过将步进卷积表示为步进ESP进行降采样,所需参数数量减少 K M M + N \frac{KM}{M+N} M+NKM倍,有效接收域增加约 [ 2 K − 1 ] 2 [2^{K−1}]^2 [2K−1]2倍。本文将这个网络称为ESPNet-A(上图a)。
-
-
Network width expansion:
- 为了保持每个空间层次的计算复杂度,传统的CNNs在每次下采样操作后都会将网络宽度扩大一倍,通常使用卷积运算。接下来[Densely connected convolutional networks],本文将从前一个跨步ESP模块接收到的特征映射与前一个ESP模块连接起来,以增加网络的宽度,如上图b中弯曲箭头所示。串联操作在同一空间层次上建立了输入和输出之间的远距离连接,因此改善了网络内部的信息流动。本文将这个网络称为ESPNet-B(上图b)。
-
Input reinforcement:
- 由于下采样和卷积操作,空间信息丢失。为了进行补偿,本文在网络内部强化输入图像。本文对输入图像进行下采样,并将其与前一个跨步ESP模块和前一个ESP模块的特征映射进行连接。将带输入增强的ESPNet-B称为ESPNet-C(上图c)。由于输入的RGB图像只有3个通道,因此由于输入增强而增加的网络复杂性是最小的。
-
Depth multiplier α:
-
为了在不改变网络拓扑结构的情况下构建具有较深计算效率的边缘设备网络,本文引入了超参数α来控制网络的深度。该参数α在空间级l重复ESP模块αl次。在更高的空间级,即l = 0和l = 1, cnn需要更多的内存,因为在这些空间级l = 0和l = 1时,特征图的空间维数较高。为了节省内存,不会在这些空间级别上重复ESP或卷积模块。
-
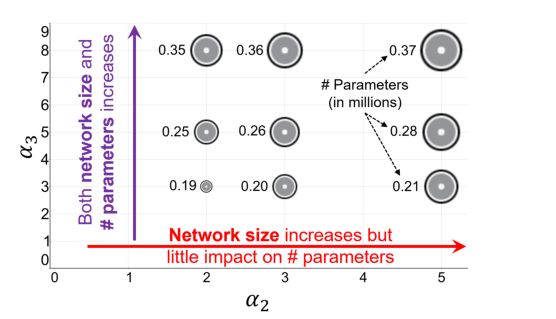
当本文改变这些参数的值时,网络所需的计算资源数量也会改变。下图显示了αl,l ={2,3}对网络参数及其大小的影响。随着α2的增加,网络的大小增加,但对参数的数量影响很小。当α3增大时,网络的大小和参数的数量都增加。参数的数量和网络的大小都应该随着深度的增加而增加。因此,为了创建深度和高效的ESPNet网络,本文固定α2的值,改变α3的值。
-
-
深度乘数α2和α3在创建高效网络中的关系。这里,圈大小∝网大小。
-
-
RUM for efficient decoding:
-
ESPNetC输出的空间分辨率是输入图像尺寸的1 / 8。直接对特征图进行上采样,比如使用双线性插值,可以在标准度量上给出很好的精度,但输出通常是粗糙的。
-
采用一种自下而上的方法(例如[A deep convolutional encoder-decoder architecture for image segmentation,U-net]),使用一个简单的规则:Reduce-UpsampleMerge (RUM)来聚合ESPNet-C学习到的多层次信息。Reduce:将空间层次l和l−1的特征映射投影到C维空间,C代表数据集中类的数量。上采样:使用2×2反卷积核对空间级l的简化特征映射上采样2倍,使其具有与l - 1级特征映射相同的空间维度。合并:l级的上采样特征映射通过拼接操作与l−1级的c维特征映射相结合。重复这个过程,直到特征图的空间维度与输入图像相同。我们将这种网络称为ESPNet(上图d)。
-
C Top-10 Kernels in ESPNet, ENet, and ERFNet
-
卷积操作使用高度优化的通用矩阵乘法(GEMM)操作和im2col等内存重新排序操作来实现。对于快速高效的网络,GEMM操作对应的内核应该对计算资源利用率有较高的贡献。
-
下图显示了ENet、ERFNet和ESPNet执行的前10个内核。本文可以看到,在ESPNet中排名TOP1的内核是GEMM,它大约占总计算时间的38%。由于卷积操作是使用GEMM内核实现的,这表明ESPNet可以有效地利用TX2中有限的计算资源。
-

-
该图显示了前10个内核及其对计算资源利用率的贡献。TOP1内核用绿色突出显示。
-
同样,ENet中排名第一的内核也是GEMM;然而,该内核对计算的贡献不如ESPNet那么大。这就是为什么ENet对GPU频率的敏感度较低,并且在NVIDIA TitanX上的运行速度比ESPNet慢1.27倍,而在NVIDIA TX2上的运行速度几乎相同。另一方面,ERFNet中排名第一的内核是内存对齐内核。这表明ERFNet会被内存操作阻塞。
D Image Size vs. Inference Speed
-
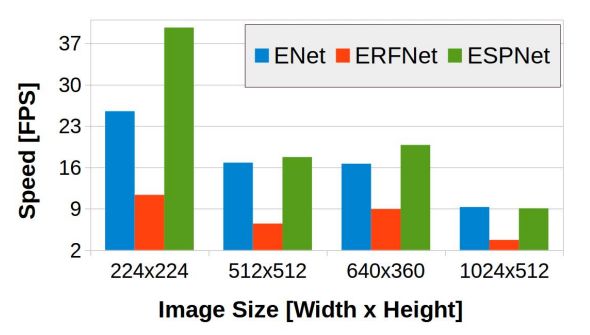
下图总结了图像大小对推理速度的影响。在较小的图像分辨率(224x224和640x360)下,ESPNet比ENet和ERFNet更快。然而,对于高分辨率的图像,ESPNet提供了与ENet相似的推断速度。本文假设ESPNet的瓶颈是由于TX2设备上有限和共享的资源。本文注意到,ESPNet在高端设备(如笔记本和桌面)上处理高分辨率图像的速度比ENet快。
-
-
The impact of image size on the inference speed on an edge device
E Resource Utilization Plots for ENet, ERFNet, and ESPNet
-
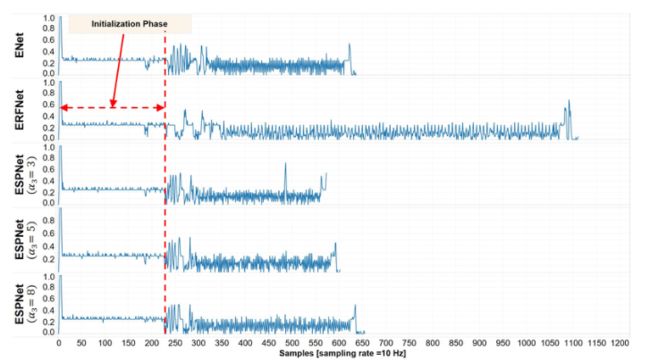
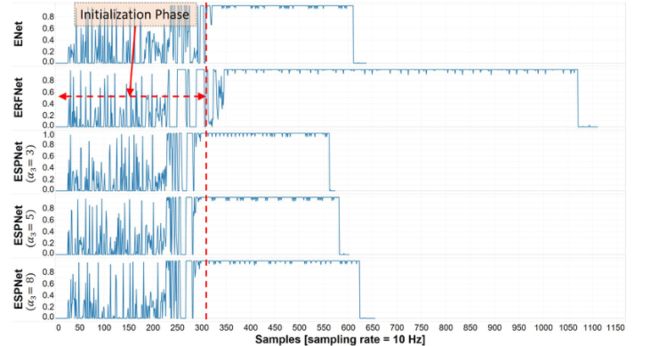
下图显示了ENet、ERFNet和ESPNet的TX2资源(CPU、GPU和内存)随时间的利用率。数据是在Max-Q模式下使用Tegrastats收集的。这些网络是吞吐量密集型的,因此,GPU利用率很高,而CPU利用率很低。注意,平均CPU利用率低于25%;这表明这些网络只使用可用的4个CPU内核中的一个,如果在TX2上运行其他应用程序,可以将其绑定到单个CPU内核,从而更好地利用CPU资源。这些网络的内存利用率有很大不同。与ENet和ERFNet相比,ESPNet的内存占用较低,这表明ESPNet适合内存受限的设备。
-
-
这个图比较了NVIDIA Jetson TX2上的CPU利用率。对于ESPNet,使用α2 = 2。在这里,1.0表示100%的CPU利用率。
-
-
这个图比较了NVIDIA Jetson TX2上的GPU利用率。对于ESPNet,使用α2 = 2。在这里,1.0代表100%的GPU利用率。
-
-
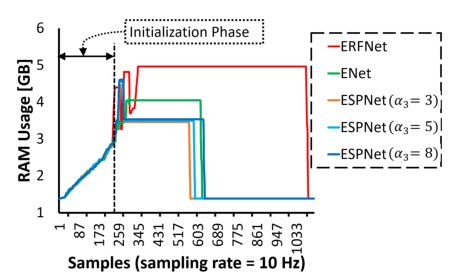
这个图比较了NVIDIA Jetson TX2上的内存利用率。对于ESPNet,使用α2 = 2。TX2上最大可用内存为8gb,由CPU和GPU共享。
-
回想一下,α2 = 2和α3 = 8的ESPNet学习到的参数数量与ENet相同。然而,ESPNet的内存占用比ENet低(上图);说明ESPNet的内存效率更高,可以有效地利用共享内存。
F Results on the Cityscape and the Mapillary Dataset
-
下表给出了Cityscape数据集上的分类和分类结果的汇总,
-
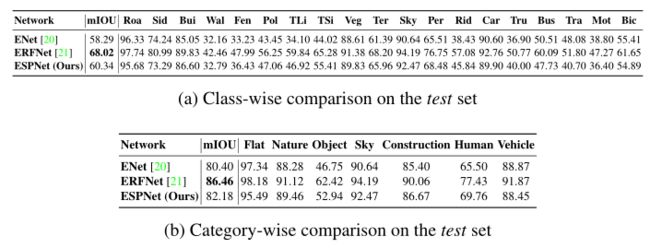
-
Cityscape数据集的比较。与其他网络的比较,请参阅城市景观排行榜: https://www.cityscapes-dataset.com/benchmarks/
-
-
而下表给出了Mapillary数据集上的分类结果。尽管ERFNet在每个类上都优于ENet和ESPNet,但它在Mapillary数据集上的表现很差。
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-01FXHZDP-1663055676749)(C:\Users\WDQ\AppData\Roaming\marktext\images\2022-08-23-15-27-58-image.png)]](http://img.e-com-net.com/image/info8/328fd41a9747455a94678e5ae6801ae2.jpg)
-
在Mapillary验证集上进行分类比较。ESPNet学习了对象的广义表示,并且在野外表现优于ENet和ERFNet。
-
-
特别是,ERFNet很难在Mapillary数据集上对简单的类进行分类,例如sky,而在这些类上,ENet和ESPNet表现得相对较好。我们注意到,ESPNet学习了关于对象的良好泛化表示,并且表现良好,即使在野外。下图分别给出了Cityscape和Mapillary数据集的定性结果。
-

-
