DDPG算法控制Pendulum模型的python实现
目录
0. 写在前面
1. DDPG概述
2. Pendulum概述
3. DDPG智能体创建
4. DDPG智能体训练
0. 写在前面
一开始使用MATLAB学习DDPG,很容易上手,但是对DDPG的理解不够,所以用python在深入学习一下。经过一周多的环境搭建,总算是上手了。先说一下环境:
- python: 3.7.8
- pycharm: 2022.1.2
- tensorflow: 2.8.0
- gym: 0.26.2
待解决问题:
- 虽然可以使用了,但是强迫症,看着很不爽,有知道的小伙伴交流一下,查了一些说法,希望能从源头上解决,而不是os.environ
2022-11-18 21:57:35.868680: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-11-18 21:57:36.426686: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 2782 MB memory: -> device: 0, name: GeForce GTX 1050 Ti, pci bus id: 0000:01:00.0, compute capability: 6.1
1. DDPG概述
理论性的东西就不讲了,讲点自己的理解:
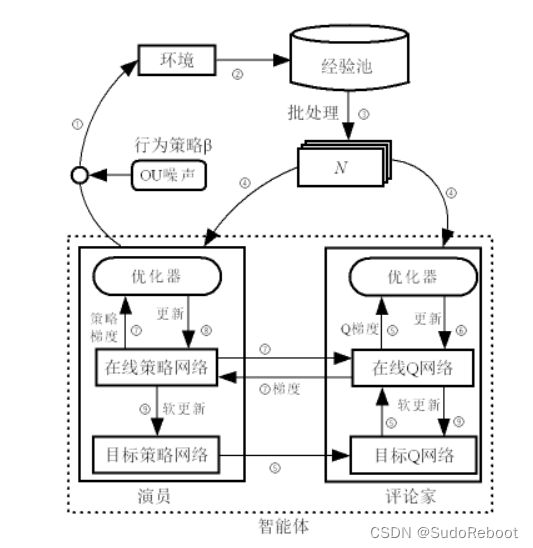
DDPG流程:
① 首先Online Actor根据环境的状态 ,输出一个控制动作
,输出一个控制动作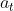 。动作作用于环境获得下一刻的状态
。动作作用于环境获得下一刻的状态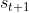 和相应的奖励
和相应的奖励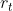
② ![]() 加上一个探索噪声:
加上一个探索噪声:![]()
③ 将![]() 保存至经验池中
保存至经验池中
④ 经验池有足够的样本后开始训练(足够的定义比较模糊)
⑤ 从经验池中抽取一批样本(mini_batch)用于训练(记为![]() ,其中
,其中![]() (1, mini_batch))
(1, mini_batch))
⑥ 将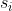 输入Online Actor,得到动作
输入Online Actor,得到动作 ,继续作用环境,得到状态和奖励,继续保存样本
,继续作用环境,得到状态和奖励,继续保存样本
⑦ Online Critic根据![]() ,计算Q值,使用梯度下降算法更新Online Actor网络的参数,以最大化Q值
,计算Q值,使用梯度下降算法更新Online Actor网络的参数,以最大化Q值
⑧ Target Actor根据 计算得到
计算得到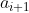 ,Target Critic根据
,Target Critic根据![]() 得到target_Q
得到target_Q
⑨ target_Q和Q之间的TD_error,使用梯度下降算法更新Online Critic网络的参数
⑩ 最后使用软更新方法,更新Target Actor和Target Critic网络
2. Pendulum概述
Pendulum是一个倒立摆,如图所示,倒立摆的摆动问题是基于控制理论中的经典问题。一端连接在固定点上的钟摆,另一端自由运动。摆在一个随机的位置开始,目标是在自由端上施加扭矩,使其摆动到一个直立的位置。竖立方向为0度。
其状态是由(cos(theta),sin(theta),d_theta)组成
其控制信号是力矩,力矩范围是(-2,2)
奖励函数:![]()

3. DDPG智能体创建
python文件结构:
- ddpg_agent.py
- main.py
# ddpg_agent.py:
import numpy as np
import tensorflow as tf
from tensorflow import keras
class DDPG(keras.Model):
def __init__(self, a_dim, s_dim, a_bound, batch_size=32, tau=0.002, gamma=0.95, a_lr=0.001, c_lr=0.001,
memory_cap=9000):
super().__init__()
self.batch_size = batch_size
self.tau = tau
self.gamma = gamma
self.a_lr = a_lr
self.c_lr = c_lr
self.memory_cap = memory_cap
self.memory = np.zeros((memory_cap, s_dim * 2 + a_dim + 1), dtype=np.float32)
self.pointer = 0
self.memory_full = False
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound[1]
self.actor_online = self._built_actor(trainable=True, name="a/online")
self.actor_target = self._built_actor(trainable=False, name="a/target")
self.actor_target.set_weights(self.actor_online.get_weights())
self.critic_online = self._built_critic(trainable=True, name="c/online")
self.critic_target = self._built_critic(trainable=False, name="c/target")
self.critic_target.set_weights(self.critic_online.get_weights())
self.a_opt = keras.optimizers.Adam(self.a_lr)
self.c_opt = keras.optimizers.Adam(self.c_lr)
self.mse = keras.losses.MeanSquaredError()
def _built_actor(self, trainable, name):
data = keras.Input(shape=(self.s_dim,))
net = keras.layers.Dense(30, activation="relu", trainable=trainable)(data)
net = keras.layers.Dense(30, activation="relu", trainable=trainable)(net)
net = keras.layers.Dense(self.a_dim, trainable=trainable)(net)
a = self.a_bound * tf.math.tanh(net)
model = keras.Model(data, a, name=name)
return model
def _built_critic(self, trainable, name):
data = keras.Input(shape=(self.a_dim + self.s_dim,))
net = keras.layers.Dense(30, activation="relu", trainable=trainable)(data)
net = keras.layers.Dense(30, activation="relu", trainable=trainable)(net)
q = keras.layers.Dense(1, trainable=trainable)(net)
model = keras.Model(data, q, name=name)
return model
def param_soft_update(self):
actor_online_weights = self.actor_online.get_weights()
critic_online_weights = self.critic_online.get_weights()
actor_target_weights = self.actor_target.get_weights()
critic_target_weights = self.critic_target.get_weights()
for i in range(len(actor_target_weights)):
actor_target_weights[i] = self.tau * actor_online_weights[i] + (1 - self.tau) * actor_target_weights[i]
for i in range(len(critic_target_weights)):
critic_target_weights[i] = self.tau * critic_online_weights[i] + (1 - self.tau) * critic_target_weights[i]
self.actor_target.set_weights(actor_target_weights)
self.critic_target.set_weights(critic_target_weights)
def pre_act(self, s):
return self.actor_online.predict(np.reshape(s, (-1, self.s_dim)), verbose=0)[0]
def sample_memory(self):
indices = np.random.choice(self.memory_cap, size=self.batch_size)
sample = self.memory[indices, :]
st_1 = sample[:, :self.s_dim]
at_1 = sample[:, self.s_dim:self.s_dim+self.a_dim]
rt_1 = sample[:, -self.s_dim-1:-self.s_dim]
st_2 = sample[:, -self.s_dim:]
return st_1, at_1, rt_1, st_2
def learn(self):
st_1, at_1, rt_1, st_2 = self.sample_memory()
with tf.GradientTape() as tape:
a = self.actor_online(st_1)
q = self.critic_online(tf.concat([st_1, a], 1))
actor_loss = tf.reduce_mean(-q)
grads = tape.gradient(actor_loss, self.actor_online.trainable_variables)
self.a_opt.apply_gradients(zip(grads, self.actor_online.trainable_variables))
with tf.GradientTape() as tape:
at_2 = self.actor_target(st_2)
q_target = rt_1 + self.gamma * self.critic_target(tf.concat([st_2, at_2], 1))
q = self.critic_online(tf.concat([st_1, at_1], 1))
critic_loss = self.mse(q_target, q)
grads = tape.gradient(critic_loss, self.critic_online.trainable_variables)
self.c_opt.apply_gradients(zip(grads, self.critic_online.trainable_variables))
return actor_loss.numpy(), critic_loss.numpy()
def store_transition(self, st_1, at_1, rt_1, st_2):
transition = np.hstack((st_1, at_1, [rt_1], st_2))
index = self.pointer % self.memory_cap
self.memory[index, :] = transition
self.pointer += 1
def train(self, Env, Model, save_model_name, max_episode=200, max_step=200, Var=1):
for episode in range(max_episode):
state = Env.reset(seed=1)[0]
episode_reward = 0
for step in range(max_step):
Env.render()
action = Model.pre_act(state)
action = np.clip(np.random.normal(action, Var), -2, 2)
env_info = Env.step(action)
state_next = env_info[0]
reward = env_info[1]
Model.store_transition(state, action, reward, state_next)
if Model.pointer > 10000:
Var *= 0.99
Model.learn()
Model.param_soft_update()
state = state_next
episode_reward += reward
print('Episode:', episode, ' Reward: %i' % int(episode_reward))
if int(episode_reward) == 0:
self.save(save_name=save_model_name)
def pre_test(self, Env, model_name):
self.load(model_name=model_name)
s = Env.reset(seed=1)[0]
for i in range(200):
Env.render()
a = self.pre_act(s)
s_next = Env.step(a)[0]
s = s_next
def save(self, save_name):
self.actor_online.save(save_name, save_format='tf')
print(save_name+' save success!')
def load(self, model_name):
self.actor_online = tf.keras.models.load_model(model_name)
4. DDPG智能体训练
# main.py:
import gym
from ddpg_agent import DDPG
if __name__ == "__main__":
do_training = False
env = gym.make("Pendulum-v1", render_mode="human") # gym模型
obs_dim = env.observation_space.shape[0] # observation维度
act_dim = env.action_space.shape[0] # action维度
a_bound = [-2.0, 2.0] # action范围
model = DDPG(a_dim=act_dim, s_dim=obs_dim, a_bound=a_bound) # DDPG agent
if do_training:
model.train(Env=env, Model=model, save_model_name='test')
else:
model.pre_test(Env=env, model_name='test')
env.close()