【PyTorch】9 序列到序列Transformer实战——nn.Transformer、nn.TransformerEncoder、PositionalEncoding
使用nn.Transformer和torchtext的序列到序列建模
- 1. 加载和批量操作数据
- 2. 产生输入和目标序列的函数
- 3. 定义模型
-
- 3.1 Positional Encoding
- 3.2 Transformer Model
- 4. 运行模型
- 5. 全部代码
- 小结
原中文教程,英文教程,英文API文档
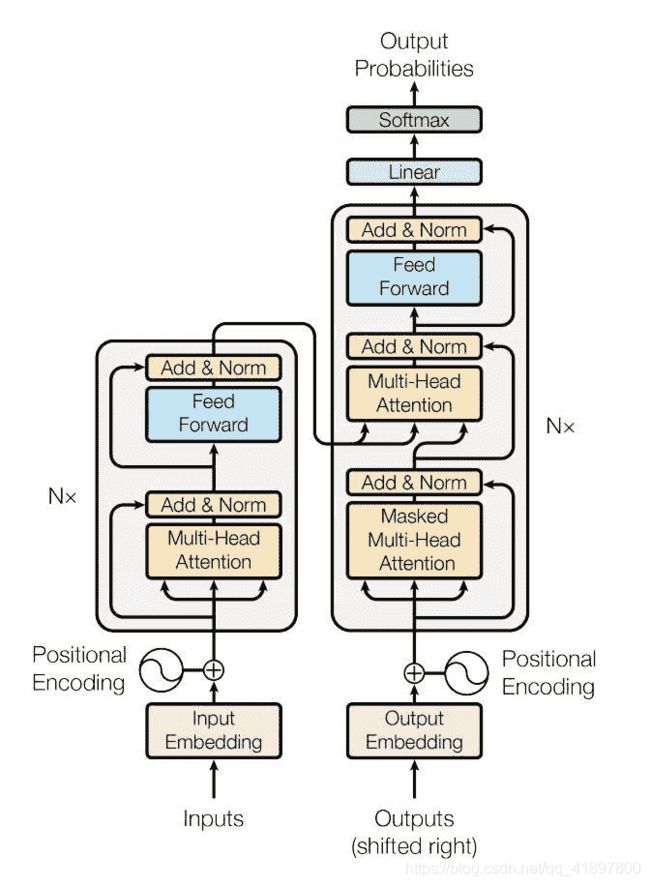
PyTorch 1.2 版本包括一个基于《Attention Is All You Need》的标准Transformer模块。 事实证明,该转换器模型在许多序列间问题上具有较高的质量,同时具有更高的可并行性。nn.Transformer模块完全依赖于注意力机制(另一个最近实现为nn.MultiheadAttention的模块)来绘制输入和输出之间的全局依存关系。 nn.Transformer模块现已高度模块化,因此可以轻松地修改/组成单个组件(如本教程中的nn.TransformerEncoder)
1. 加载和批量操作数据
本教程使用torchtext生成 Wikitext-2 数据集。 vocab对象是基于训练数据集构建的,用于将标记数字化为张量。 从序列数据开始,batchify()函数将数据集排列为列,以修剪掉数据分成大小为batch_size的批量后剩余的所有标记。 例如,以字母为序列(总长度为 26)并且批大小为 4,我们将字母分为 4 个长度为 6 的序列:
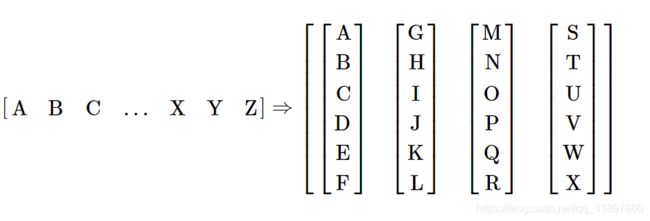
这些列被模型视为独立的,这意味着无法了解G和F的依赖性,但可以进行更有效的批量操作
从以下网址下载数据集并解压,得到wiki.test.tokens、wiki.train.tokens、wiki.valid.tokens三个文件,内容如下所示:


关于map()函数:
map(function, iterable, ...)
map()根据提供的函数对指定序列做映射,第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表
最后生成的vocab测试:
print(vocab['apple'])
print(vocab['man'])
print(vocab['.'])
print(vocab['='])
print(vocab['' ])
print(vocab['Senjō'])
print(vocab['Valkyria'])
print(vocab['' ])
11503
241
4 # .
10 # =
0
0
0
0
可见其他的单词都是0
numel()函数:返回数组中元素的个数
import torch
x = torch.tensor([0, 0])
print(x.numel())
2
filter() 函数
filter(function, iterable)
用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中
以test_data为例,data_process(iter(io.open(test_filepath, encoding='utf-8')))的结果:
tuple(filter)返回的是:
(..., tensor([ 10, 10, 2374, 10, 10]), ...) # = = Legacy = =
tuple(filter)[0]:
tensor([ 10, 633, 0, 10]) # = Robert =
利用torch.cat组合的结果:
tensor([ 10, 633, 0, ..., 7214, 0, 4])
关于torch .narrow()函数:
torch.narrow(input, dim, start, length) → Tensor
返回一个新的张量,它是输入张量的缩小版。从iuput的第dim维度从start到start+length。返回的张量和输入张量共享相同的底层存储
import torch
x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
y = x.narrow(0, 0, 2)
print(y)
y = x.narrow(1, 1, 2)
print(y)
tensor([[1, 2, 3],
[4, 5, 6]])
tensor([[2, 3],
[5, 6],
[8, 9]])
即:
torch.narrow(x, 0, 0, 2) == x[0:0+2, :]
torch.narrow(x, 1, 2, 1) == x[:, 2:2+1]
关于view和t()(转置)和contiguous()(使tensor变量在内存中的存储变得连续):
import torch
x = torch.arange(12) # bsz = 5, batch = 2
print(x)
y = x.narrow(0, 0, 10)
print(y)
y = y.view(5, -1)
print(y)
print(y.t().contiguous())
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
tensor([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
tensor([[0, 2, 4, 6, 8],
[1, 3, 5, 7, 9]])
2. 产生输入和目标序列的函数
get_batch()函数为转换器模型生成输入和目标序列。 它将源数据细分为长度为bptt的块。 对于语言建模任务,模型需要以下单词作为Target。 例如,如果bptt值为 2,则i = 0时,我们将获得以下两个变量:
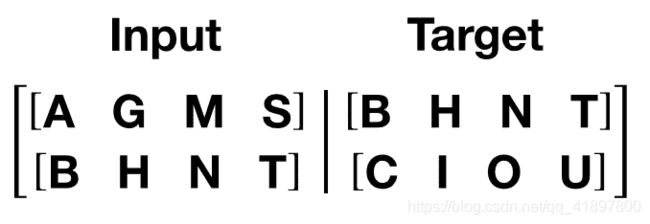
应该注意的是,这些块沿着维度 0,与Transformer模型中的S维度一致。 批量尺寸N沿尺寸 1
bptt = 2时:
x = torch.arange(24).reshape(6,4)
print(x)
data, target = get_batch(x, 0)
print(data)
print(target)
print(data.size())
print(target.size())
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]])
tensor([[0, 1, 2, 3],
[4, 5, 6, 7]])
tensor([ 4, 5, 6, 7, 8, 9, 10, 11])
torch.Size([2, 4])
torch.Size([8])
例如bptt = 35时:
data, target = get_batch(test_data, 0)
print(data.size())
print(target.size())
torch.Size([35, 10])
torch.Size([350])
3. 定义模型
3.1 Positional Encoding
此模块增加一些有关标记在序列中的相对或绝对位置的信息。 位置编码的尺寸与嵌入的尺寸相同,因此可以将两者相加。 在这里,我们使用不同频率的sine和cosine函数
关于arange()函数
import torch
x = torch.arange(0, 5, 2)
print(x)
tensor([0, 2, 4])
关于sin()函数:
import math
import torch
x = torch.arange(6) / 6
print(x)
x = torch.sin(x) # 弧度制(非角度)
# x = -math.log(10000.0) # -ln(10000)
print(x)
以及间隔:
x = torch.arange(9).reshape(3,3)
print(x)
print(x[:, 0::2])
tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
tensor([[0, 2],
[3, 5],
[6, 8]])
tensor([0.0000, 0.1667, 0.3333, 0.5000, 0.6667, 0.8333])
tensor([0.0000, 0.1659, 0.3272, 0.4794, 0.6184, 0.7402])
x = torch.arange(6).unsqueeze(1)
y = torch.arange(3)
print(x * y)
print(torch.sin(x * y))
tensor([[ 0, 0, 0],
[ 0, 1, 2],
[ 0, 2, 4],
[ 0, 3, 6],
[ 0, 4, 8],
[ 0, 5, 10]])
tensor([[ 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.8415, 0.9093],
[ 0.0000, 0.9093, -0.7568],
[ 0.0000, 0.1411, -0.2794],
[ 0.0000, -0.7568, 0.9894],
[ 0.0000, -0.9589, -0.5440]])
以及扩维再转置:
x = torch.arange(9).reshape(3,3)
x = x.unsqueeze(0).transpose(0, 1)
print(x)
tensor([[[0, 1, 2]],
[[3, 4, 5]],
[[6, 7, 8]]])
关于.register_buffer函数可见此,就是在内存中定一个常量,同时,模型保存和加载的时候可以写入和读出,一般情况下PyTorch将网络中的参数保存成orderedDict形式,参数包含两种,一种是模型中各种module含的参数,即nn.Parameter,当然可以在网络中定义其他的nn.Parameter参数,另一种就是buffer,前者每次optim.step会得到更新,而后者不会更新
3.2 Transformer Model
在本教程中,我们将在语言建模任务上训练nn.TransformerEncoder模型。 语言建模任务是为给定单词(或单词序列)遵循单词序列的可能性分配概率。 标记序列首先传递到嵌入层,然后传递到位置编码层以说明单词的顺序(有关更多详细信息,请参见下一段)。 nn.TransformerEncoder由多层nn.TransformerEncoderLayer组成。 与输入序列一起,还需要一个正方形的注意掩码,因为nn.TransformerEncoder中的自注意层仅允许出现在该序列中的较早位置。 对于语言建模任务,应屏蔽将来头寸上的所有标记。 为了获得实际的单词,将nn.TransformerEncoder模型的输出发送到最终的Linear层,然后是对数 Softmax 函数
掩码的作用可参考此博客,在transformer中, 掩码张量的主要作用在应用attention,有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的,因此,未来的信息可能被提前利用,所以,需要进行遮掩
关于TransformerEncoderLayer函数见此,输入包含:
- d_model – the number of expected features in the input (required).
- nhead – the number of heads in the multiheadattention models (required).
- dim_feedforward – the dimension of the feedforward network model (default=2048).
- dropout – the dropout value (default=0.1).
- activation – the activation function of intermediate layer, relu or gelu (default=relu).
关于.triu函数,官方文档见此,返回输入的矩阵(二维张量)或批量矩阵的上三角部分,结果张量出来的其他元素都设为0。矩阵的上三角部分被定义为对角线上和上面的元素。参数 diagonal 控制要考虑的对角线。如果 diagonal = 0,则保留主对角线上的所有元素。正值排除主对角线以上的对角线,同样,负值也排除主对角线以下的对角线,例如:
>>> b = torch.randn(4, 6)
>>> b
tensor([[ 0.5876, -0.0794, -1.8373, 0.6654, 0.2604, 1.5235],
[-0.2447, 0.9556, -1.2919, 1.3378, -0.1768, -1.0857],
[ 0.4333, 0.3146, 0.6576, -1.0432, 0.9348, -0.4410],
[-0.9888, 1.0679, -1.3337, -1.6556, 0.4798, 0.2830]])
>>> torch.triu(b, diagonal=1)
tensor([[ 0.0000, -0.0794, -1.8373, 0.6654, 0.2604, 1.5235],
[ 0.0000, 0.0000, -1.2919, 1.3378, -0.1768, -1.0857],
[ 0.0000, 0.0000, 0.0000, -1.0432, 0.9348, -0.4410],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.4798, 0.2830]])
>>> torch.triu(b, diagonal=-1)
tensor([[ 0.5876, -0.0794, -1.8373, 0.6654, 0.2604, 1.5235],
[-0.2447, 0.9556, -1.2919, 1.3378, -0.1768, -1.0857],
[ 0.0000, 0.3146, 0.6576, -1.0432, 0.9348, -0.4410],
[ 0.0000, 0.0000, -1.3337, -1.6556, 0.4798, 0.2830]])
关于.masked_fill()中文文档见此,用value填充 self tensor 中的元素:
sz = 5
x = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
x = x.float().masked_fill(x == 0, float('-inf')).masked_fill(x == 1, float(0.0))
print(x)
tensor([[0., -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf],
[0., 0., 0., -inf, -inf],
[0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0.]])
关于TransformerEncoder()官方文档见此,初始化输入参数:
- encoder_layer – an instance of the TransformerEncoderLayer() class (required).
- num_layers – the number of sub-encoder-layers in the encoder (required).
- norm – the layer normalization component (optional).
forward输入参数:
- src – the sequence to the encoder (required).
- mask – the mask for the src sequence (optional).
- src_key_padding_mask – the mask for the src keys per batch (optional).
具体运算参考nn.Transformer函数:
- src: (S, N, E)
- tgt: (T, N, E)
- src_mask: (S, S)
- tgt_mask: (T, T)
- memory_mask: (T, S)
- src_key_padding_mask: (N, S)
- tgt_key_padding_mask: (N, T)
- memory_key_padding_mask: (N, S)
其中S为源序列长度(source sequence length),T为目标序列长度(target sequence length),N为批次大小(batch size),E为特征数(feature number)
- output: (T, N, E)
注:由于变换器模型中的多头注意架构,变换器的输出序列长度与解码器的输入序列(即目标)长度相同
4. 运行模型
CrossEntropyLoss用于跟踪损失,SGD实现随机梯度下降方法作为优化器。 初始学习率设置为 5.0。 StepLR用于通过历时调整学习率。 在训练期间,我们使用nn.utils.clip_grad_norm_函数将所有梯度缩放在一起,以防止爆炸
关于torch.optim.lr_scheduler.StepLR函数,官方文档见此,每隔一个step_size epochs,将每个参数组的学习率按gamma衰减。请注意,这种衰减可以与其他来自这个调度器外部的学习率变化同时发生。当last_epoch=-1时,设置初始lr为lr,参数:
- optimizer (Optimizer) – Wrapped optimizer.
- step_size (int) – Period of learning rate decay.
- gamma (float) – Multiplicative factor of learning rate decay. Default: 0.1.
- last_epoch (int) – The index of last epoch. Default: -1.
- verbose (bool) – If True, prints a message to stdout for each update. Default: False.
关于enumerate函数:
for batch, i in enumerate(range(0, 32 - 1, 5)):
print(batch, i)
0 0
1 5
2 10
3 15
4 20
5 25
6 30
循环遍历。 如果验证损失是迄今为止迄今为止最好的,请保存模型。 在每个周期之后调整学习率
训练过程:
36718lines [00:01, 22182.58lines/s]
GPU is available!
epoch:1 200 / 2928 batches lr:5.00 0.04 s/batch, loss 8.22
E:\ProgramData\Anaconda3\lib\site-packages\torch\optim\lr_scheduler.py:369: UserWarning: To get the last learning rate computed by the scheduler, please use `get_last_lr()`.
warnings.warn("To get the last learning rate computed by the scheduler, "
epoch:1 400 / 2928 batches lr:5.00 0.04 s/batch, loss 6.89
epoch:1 600 / 2928 batches lr:5.00 0.04 s/batch, loss 6.45
epoch:1 800 / 2928 batches lr:5.00 0.04 s/batch, loss 6.31
epoch:1 1000 / 2928 batches lr:5.00 0.04 s/batch, loss 6.19
epoch:1 1200 / 2928 batches lr:5.00 0.04 s/batch, loss 6.15
epoch:1 1400 / 2928 batches lr:5.00 0.04 s/batch, loss 6.12
epoch:1 1600 / 2928 batches lr:5.00 0.04 s/batch, loss 6.10
epoch:1 1800 / 2928 batches lr:5.00 0.04 s/batch, loss 6.03
epoch:1 2000 / 2928 batches lr:5.00 0.04 s/batch, loss 6.02
epoch:1 2200 / 2928 batches lr:5.00 0.04 s/batch, loss 5.89
epoch:1 2400 / 2928 batches lr:5.00 0.04 s/batch, loss 5.97
epoch:1 2600 / 2928 batches lr:5.00 0.04 s/batch, loss 5.95
epoch:1 2800 / 2928 batches lr:5.00 0.04 s/batch, loss 5.88
-----------------------------------------------------------------------------------------
| end of epoch 1 | time: 110.37s | valid loss 5.82 | valid ppl 336.71
-----------------------------------------------------------------------------------------
epoch:2 200 / 2928 batches lr:4.51 0.04 s/batch, loss 5.86
epoch:2 400 / 2928 batches lr:4.51 0.04 s/batch, loss 5.85
epoch:2 600 / 2928 batches lr:4.51 0.04 s/batch, loss 5.66
epoch:2 800 / 2928 batches lr:4.51 0.04 s/batch, loss 5.70
epoch:2 1000 / 2928 batches lr:4.51 0.04 s/batch, loss 5.65
epoch:2 1200 / 2928 batches lr:4.51 0.04 s/batch, loss 5.68
epoch:2 1400 / 2928 batches lr:4.51 0.04 s/batch, loss 5.69
epoch:2 1600 / 2928 batches lr:4.51 0.04 s/batch, loss 5.71
epoch:2 1800 / 2928 batches lr:4.51 0.04 s/batch, loss 5.65
epoch:2 2000 / 2928 batches lr:4.51 0.04 s/batch, loss 5.67
epoch:2 2200 / 2928 batches lr:4.51 0.04 s/batch, loss 5.55
epoch:2 2400 / 2928 batches lr:4.51 0.04 s/batch, loss 5.64
epoch:2 2600 / 2928 batches lr:4.51 0.04 s/batch, loss 5.64
epoch:2 2800 / 2928 batches lr:4.51 0.04 s/batch, loss 5.59
-----------------------------------------------------------------------------------------
| end of epoch 2 | time: 109.94s | valid loss 5.66 | valid ppl 287.15
-----------------------------------------------------------------------------------------
epoch:3 200 / 2928 batches lr:4.29 0.04 s/batch, loss 5.60
epoch:3 400 / 2928 batches lr:4.29 0.04 s/batch, loss 5.62
epoch:3 600 / 2928 batches lr:4.29 0.04 s/batch, loss 5.43
epoch:3 800 / 2928 batches lr:4.29 0.04 s/batch, loss 5.48
epoch:3 1000 / 2928 batches lr:4.29 0.04 s/batch, loss 5.43
epoch:3 1200 / 2928 batches lr:4.29 0.04 s/batch, loss 5.47
epoch:3 1400 / 2928 batches lr:4.29 0.04 s/batch, loss 5.48
epoch:3 1600 / 2928 batches lr:4.29 0.04 s/batch, loss 5.52
epoch:3 1800 / 2928 batches lr:4.29 0.04 s/batch, loss 5.46
epoch:3 2000 / 2928 batches lr:4.29 0.04 s/batch, loss 5.48
epoch:3 2200 / 2928 batches lr:4.29 0.04 s/batch, loss 5.36
epoch:3 2400 / 2928 batches lr:4.29 0.04 s/batch, loss 5.46
epoch:3 2600 / 2928 batches lr:4.29 0.04 s/batch, loss 5.47
epoch:3 2800 / 2928 batches lr:4.29 0.04 s/batch, loss 5.41
-----------------------------------------------------------------------------------------
| end of epoch 3 | time: 110.10s | valid loss 5.58 | valid ppl 264.17
-----------------------------------------------------------------------------------------
评估模型:
=========================================================================================
| End of training | test loss 5.48 | test ppl 241.01
=========================================================================================
以下句子
In the decades since its release , The <unk> has cemented its reputation as a classic .
生成结果:
horizontal daly roads owen 75th infiltrate d grevillea ramsbury inevitable hen progressed dent beryllium securing tutorials avian
downs supervisors fear enforcing great anticipated grimsby granite 605 iny incidents great 62nd convinced milbrook 279 ferb
leaked pact 06 caretaker befriends zbarazh clarified kg boss condominium turnout proportionate 1717 whale felipe breaches etmaler
忘记加载模型了…… 结果应该如下:
the second , the first of and first , been a first for a <unk> . =
5. 全部代码
test_filepath = '... your path\\wikitext-2\\wiki.test.tokens'
valid_filepath = '... your path\\wikitext-2\\wiki.valid.tokens'
train_filepath = '... your path\\wikitext-2\\wiki.train.tokens'
from torchtext.data.utils import get_tokenizer
tokenizer = get_tokenizer('basic_english')
import io
from torchtext.vocab import build_vocab_from_iterator
vocab = build_vocab_from_iterator(map(tokenizer, iter(io.open(train_filepath, encoding="utf8"))))
import torch
def data_process(raw_text_iter):
data = [torch.tensor([vocab[token] for token in tokenizer(item)], dtype=torch.long) for item in raw_text_iter]
return torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))
train_data = data_process(iter(io.open(train_filepath, encoding="utf8")))
val_data = data_process(iter(io.open(valid_filepath, encoding="utf8")))
test_data = data_process(iter(io.open(test_filepath, encoding='utf-8')))
if torch.cuda.is_available():
device = torch.device("cuda")
print('GPU is available!')
def batchify(data, bsz): # 将数据集划分为bsz部分
n_batch = data.size()[0] // bsz
data = data.narrow(0, 0, n_batch * bsz) # 修剪掉任何额外的元素,不会干净地适合(剩余)。
data = data.view(bsz, -1).t().contiguous()
return data.to(device)
batch_size = 20
eval_batch_size = 10
train_data = batchify(train_data, batch_size)
val_data = batchify(val_data, eval_batch_size)
test_data = batchify(test_data,
eval_batch_size) # torch.Size([241859]) → torch.Size([241850]) → torch.Size([24185, 10])
bptt = 35
def get_batch(source, i):
seq_len = min(bptt, len(source) - 1 - i) # 35
data = source[i:i + seq_len] # 对于每一个batch,data为i到i+seq_len的数
target = source[i + 1:i + 1 + seq_len].reshape(-1) # # 对于每一个batch,data为i+1到i+seq_len+1的数
return data, target # 35 * 20, [700]
import math
import torch.nn as nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000): # ninp, dropout
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model) # 5000 * 200
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # [[0],[1],...[4999]] 5000 * 1
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(
10000.0) / d_model)) # e ^([0, 2,...,198] * -ln(10000)(-9.210340371976184) / 200) [1,0.912,...,(1.0965e-04)]
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1) # 5000 * 1 * 200, 最长5000的序列,每个词由1 * 200的矩阵代表着不同的时间
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size()[0], :] # torch.Size([35, 1, 200])
return self.dropout(x)
from torch.nn import TransformerEncoder, TransformerEncoderLayer
class TransformerModel(nn.Module):
def __init__(self, ntoken, ninp, nhead, nhid, nlayers,
dropout=0.5): # ntokens 词典大小,ninp = emsize 词嵌入维度 200, nhead 模型head数量 2, nhid 前向网络的维数 200, nlayers Encoder的层数 2, dropout=0.2
super(TransformerModel, self).__init__()
self.model_type = 'Transformer'
self.pos_encoder = PositionalEncoding(ninp, dropout) # emsize=200,dropout=0.2
encoder_layers = TransformerEncoderLayer(ninp, nhead, nhid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.encoder = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def forward(self, src, src_mask):
src = self.encoder(src) * math.sqrt(self.ninp) # 为什么要×根号emsize 35 * 20 * 200
src = self.pos_encoder(src) # 35 * 20 * 200
output = self.transformer_encoder(src, src_mask) # 35 * 20 * 200
output = self.decoder(output) # 35 * 20 * ntoken
return output
ntokens = len(vocab.stoi) # the size of vocabulary
emsize = 200 # embedding dimension
nhid = 200 # the dimension of the feedforward network model in nn.TransformerEncoder
nlayers = 2 # the number of nn.TransformerEncoderLayer in nn.TransformerEncoder
nhead = 2 # the number of heads in the multiheadattention models
dropout = 0.2 # the dropout value
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout).to(device)
criterion = nn.CrossEntropyLoss()
lr = 5.0 # learning rate
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
import time
def train():
model.train() # Turn on the train mode
total_loss = 0.
start_time = time.time()
src_mask = model.generate_square_subsequent_mask(bptt).to(device)
tmp = 'epoch:{} {} / {} batches lr:{:.2f} {:.2f} s/batch, loss {:.2f}'
for batch, i in enumerate(range(0, train_data.size()[0]-1, bptt)):
data, targets = get_batch(train_data, i)
optimizer.zero_grad()
if data.size()[0] != bptt: # 执行最后一个
src_mask = model.generate_square_subsequent_mask(data.size(0)).to(device)
output = model(data, src_mask) # 35 * 20 * ntoken
loss = criterion(output.view(-1, ntokens), targets) # 700 * ntoken, [700]
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
total_loss += loss.item()
log_interval = 200
if batch % log_interval == 0 and batch > 0:
cur_loss = total_loss / log_interval
total_loss = 0
elapsed = time.time() - start_time
print(tmp.format(epoch, batch, len(train_data) // bptt, scheduler.get_lr()[0], elapsed / log_interval, cur_loss))
start_time = time.time()
def evaluate(eval_model, data_source):
eval_model.eval() # Turn on the evaluation mode
total_loss = 0.
src_mask = model.generate_square_subsequent_mask(bptt).to(device)
with torch.no_grad():
for i in range(0, data_source.size(0) - 1, bptt):
data, targets = get_batch(data_source, i)
if data.size(0) != bptt:
src_mask = model.generate_square_subsequent_mask(data.size(0)).to(device)
output = eval_model(data, src_mask)
output_flat = output.view(-1, ntokens)
total_loss += len(data) * criterion(output_flat, targets).item()
return total_loss / (len(data_source) - 1)
if __name__ == '__main__':
# best_val_loss = float("inf")
# epochs = 3 # The number of epochs
# best_model = None
#
# for epoch in range(1, epochs + 1):
# epoch_start_time = time.time()
# train()
# val_loss = evaluate(model, val_data)
# print('-' * 89)
# print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | '
# 'valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),
# val_loss, math.exp(val_loss)))
# print('-' * 89)
#
# if val_loss < best_val_loss:
# best_val_loss = val_loss
# best_model = model
#
# scheduler.step()
#
# torch.save(best_model.state_dict(), '... your path\\model_Transformer.pth')
# 以下为测试部分1
model.load_state_dict(torch.load('... your path\\model_Transformer.pth'))
# test_loss = evaluate(model, test_data)
# print('=' * 89)
# print('| End of training | test loss {:5.2f} | test ppl {:8.2f}'.format(
# test_loss, math.exp(test_loss)))
# print('=' * 89)
# 以下为测试部分2
str = 'In the decades since its release , The has cemented its reputation as a classic . '
data = [torch.tensor([vocab[token] for token in tokenizer(item)], dtype=torch.long) for item in
str.strip(' ').split(' ')]
data = torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))
# tensor([ 7, 2, 2180, 153, 44, 321, 3, 2, 0, 51,
# 12271, 44, 2640, 15, 9, 2366, 4])
data = data.unsqueeze(1).to(device)
model.eval()
src_mask = model.generate_square_subsequent_mask(data.size()[0]).to(device)
output = model(data, src_mask) # torch.Size([17, 1, 28783])
output_flat = output.view(-1, ntokens) # 17 * 28783
max_index = output_flat.max(1)[1]
result = []
for item in max_index.data:
result.append(vocab.itos[item.item()])
print(' '.join(result))
小结
大致把nn.TransformerEncoder做了一遍,实际上大多数时间还是在数据集的处理上,关于PositionalEncoding具体为什么要这么生成还不太清楚,总之Transformer已高度模块化,这个示例也只是简单的语言任务的训练,关于其解码器还不会编写